《REBEL Relation Extraction By End-to-end Language generation》阅读笔记
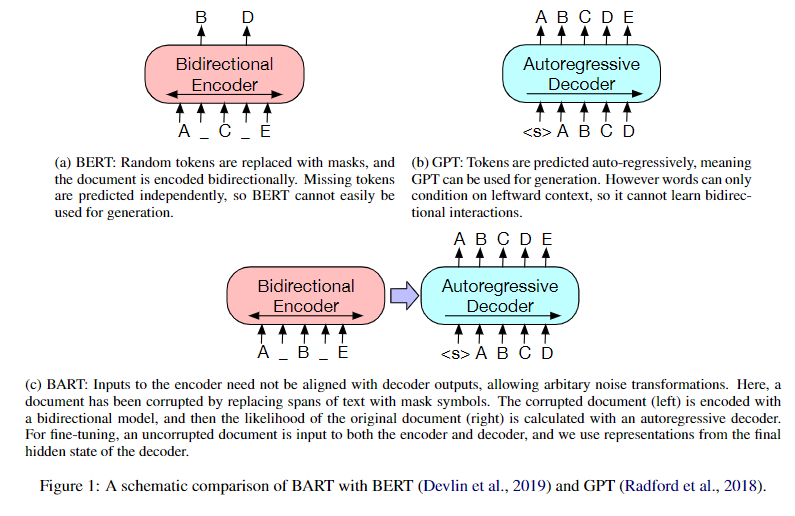
- BERT模型是仅使用Transformer-Encoder结构的预训练语言模型(具备双向语言理解能力的却不具备做生成任务的能力)。
- GPT模型是仅使用Transformer-Decoder结构的预训练语言模型(拥有自回归特性的却不能更好地从双向理解语言)。
- BART模型是使用Transformer模型整体结构的预训练语言模型(在自然语言理解任务上表现没有下降,并且在自然语言生成任务上有明显的提高)。
- 从给定的文本中提取实体之间的语义关系,把非结构化原始文本转换为结构化数据,组成关系三元组(ei,rij,ej),这些数据可用于一系列下游任务和应用程序,例如知识库的构建等。
- 使用命名实体识别(NER)从文中抽取实体。
- 使用关系分类(RC)判断提取的实体之间是否存在关系。
- 识别哪些实体真正共享一个关系可能会成为瓶颈,因为这需要额外的步骤,例如负抽样和注释等。
- 通常比较复杂,有一些专注于任务的元素,需要根据关系或实体类型的数量进行适应。
- 不够灵活,无法处理不同性质的文本(句子级别与文档级别)或领域。
- 通常需要很长的训练时间,以便对新数据进行微调。
- RC(Relation Classification):从给定上下文中两个实体之间进行关系分类。
- RE(Relation Extraction ):从原始文本中提取实体之间关系三元组,没有给定实体,也称为端到端关系提取。
- 流水线技术(pipeline):早期的工作利用CNN、LSTM挖掘语义关系,并对给定的实体进行关系分类。 目前已有工作开始使用transformer模型。
- 早期的端到端方法:对输入文本中所有单词对进行分类,使用表格表示或表格填充,将任务转化为填充一个表格(关系)的格子,其中行和列是输入中的单词。
- 利用联合训练的流水线技术:联合训练NER和RC,比如Eberts and Ulges (2021)使用了一个流水线方法(文档级RE),联合训练了一个多任务模型,利用共指消解在实体级别而不是提及级别进行操作。
- 它们通常假设每个实体对之间最多有一种关系类型,而且多分类方法不考虑其他的预测。例如,它们可能预测同一个头实体有两个“出生日期”,或者预测一些不兼容的关系。此外,它们需要推断所有可能的实体对,这可能会变得计算代价昂贵。
- Zhang等人(2020)指出,将三元组转换为文本序列需要一个线性化的过程,而这个过程可能是有些随意的,比如按照字母顺序。Zeng等人(2019)对这个问题进行了研究,他们使用了强化学习来确定三元组的抽取顺序。
- 由于在训练过程中,预测总是依赖于正确的输出,seq2seq方法会受到暴露偏差的影响。Zhang等人(2020)提出了一个树解码的方法,可以缓解这个问题,同时仍然保持了seq2seq方法的自回归性质。
- 使用BART-large(Lewis et al., 2020)作为基础模型,将关系抽取和分类视为一个生成任务,输出输入文本中存在的每个三元组。
- 输入:编码器接收输入数据序列,即数据集中的文本。
- 输出:解码器产生输出数据序列,即线性化的三元组。
- 预训练模型:BART。
- 损失函数:Cross-Entropy。
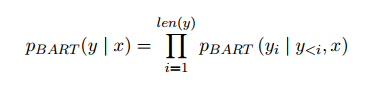
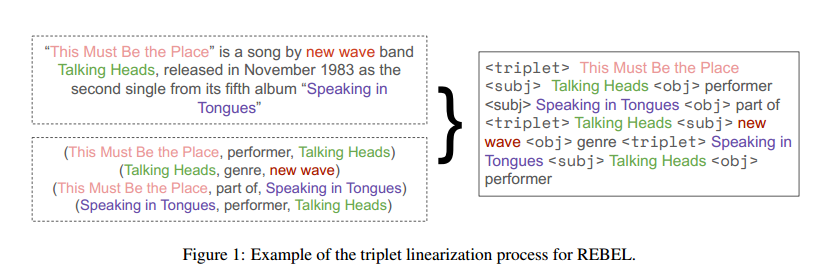
- <triplet>标记了一个新的三元组的开始,后面跟着一个新的头实体。
- <subj>标记了头实体的结束和尾实体的开始。
- <obj>标记了尾实体的结束和头实体与尾实体之间关系的开始。

《REBEL Relation Extraction By End-to-end Language generation》阅读笔记的更多相关文章
- 阅读《RobHess的SIFT源码分析:综述》笔记
今天总算是机缘巧合的找到了照样一篇纲要性质的文章. 如是能早一些找到就好了.不过“在你认为为时已晚的时候,其实还为时未晚”倒是也能聊以自慰,不过不能经常这样迷惑自己,毕竟我需要开始跑了! 就照着这个大 ...
- RobHess的SIFT源码分析:imgfeatures.h和imgfeatures.c文件
SIFT源码分析系列文章的索引在这里:RobHess的SIFT源码分析:综述 imgfeatures.h中有SIFT特征点结构struct feature的定义,除此之外还有一些特征点的导入导出以及特 ...
- RobHess的SIFT源码分析:综述
最初的目的是想做全景图像拼接,一开始找了OpenCV中自带的全景拼接的样例,用的是Stitcher类,可以很方便的实现全景拼接,而且效果很好,但是不利于做深入研究. 使用OpenCV中自带的Stitc ...
- 阅读《RobHess的SIFT源码分析:综述》笔记2
今天开始磕代码部分. part1: 1. sift特征提取. img1_Feat = cvCloneImage(img1);//复制图1,深拷贝,用来画特征点 img2_Feat = cvCloneI ...
- element-ui button组件 radio组件源码分析整理笔记(一)
Button组件 button.vue <template> <button class="el-button" @click="handleClick ...
- element-ui 组件源码分析整理笔记目录
element-ui button组件 radio组件源码分析整理笔记(一) element-ui switch组件源码分析整理笔记(二) element-ui inputNumber.Card .B ...
- element-ui Carousel 走马灯源码分析整理笔记(十一)
Carousel 走马灯源码分析整理笔记,这篇写的不详细,后面有空补充 main.vue <template> <!--走马灯的最外层包裹div--> <div clas ...
- STL源码分析读书笔记--第二章--空间配置器(allocator)
声明:侯捷先生的STL源码剖析第二章个人感觉讲得蛮乱的,而且跟第三章有关,建议看完第三章再看第二章,网上有人上传了一篇读书笔记,觉得这个读书笔记的内容和编排还不错,我的这篇总结基本就延续了该读书笔记的 ...
- element-ui MessageBox组件源码分析整理笔记(十二)
MessageBox组件源码,有添加部分注释 main.vue <template> <transition name="msgbox-fade"> < ...
- element-ui switch组件源码分析整理笔记(二)
源码如下: <template> <div class="el-switch" :class="{ 'is-disabled': switchDisab ...
随机推荐
- 老问题了:idea中使用maven archetype新建项目时卡住
背景 作为一个后端Java打工人,idea就是最重要的打饭工具.创建项目,熟悉吧,但是,这么多年下来,因为idea换了版本,电脑换了等等,我还是时不时遇到根据maven archetype新建mave ...
- Deno 中使用 @typescript/vfs 生成 DTS 文件
背景 前段时间开源的 STC 工具,这是一个将 OpenApi 规范的 Swagger/Apifox 文档转换成代码的工具.可以在上一篇(<OpenApi(Swagger)快速转换成 TypeS ...
- 完美解决Content type ‘multipart/form-data;boundary=----------0467042;charset=UTF-8‘ not supported问题
一.前言 今天在做文件上传功能出现了该问题,该接口如下: @PostMapping("/upload") public Boolean upload(@RequestParam ...
- 在Godot 3.X中添加触屏摇杆
开源项目地址:https://github.com/shinneider/godot_touchJoyPad 效果图: 下载项目 方法一 直接从godot assets lib下载 如图,直接下载自动 ...
- CodeForces 1332D Walk on Matrix
题意 \(Bob\)想解决一个问题:一个\(n\cdot m\)的矩阵,从\((1,1)\)出发,只能走右和下,问从\((1,1)\)到\((n,m)\)的最大\(\&\)和 他的算法如下(\ ...
- PDF 补丁丁 1.0 正式版
经过了一年多的测试和完善,PDF 补丁丁发布第一个开放源代码的正式版本了. PDF 补丁丁也是国内首先开放源代码.带有修改和阅读PDF的功能的 PDF 处理程序之一. 源代码网址:https://gi ...
- springboot项目自动关闭进程重启脚本
话不多说,先上脚本 kill -15 $(netstat -nlp | grep :9095 | awk '{print $7}' | awk -F"/" '{ print $1 ...
- 解决Promise的多并发问题
提起控制并发,大家应该不陌生,我们可以先来看看多并发,再去聊聊为什么要去控制它 多并发一般是指多个异步操作同时进行,而运行的环境中资源是有限的,短时间内过多的并发,会对所运行的环境造成很大的压力,比如 ...
- 在 Net7.0环境下测试了 Assembly.Load、Assmebly.LoadFile和Assembly.LoadFrom的区别
一.简介 很长时间没有关注一些C#技术细节了,主要在研究微服务.容器.云原生.编批等高大上的主题了,最近在写一些框架的时候,遇到了一些和在 Net Framework 框架下不一样的情况,当然了,我今 ...
- 「codeforces - 1394C」Boboniu and String
link. 注意到 BN-string 长成什么样根本不重要,我们把它表述为 BN-pair \((x, y)\) 即可,两个 BN-strings 相似的充要条件即两者分别映射得到的 BN-pair ...