python重拾第五天-常用模块学习
本节大纲:
- 模块介绍
- time &datetime模块
- random
- os
- sys
- shutil
- json & picle
- shelve
- xml处理
- yaml处理
- configparser
- hashlib
- subprocess
- logging模块
- re正则表达式
模块
用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
包,用来从逻辑上组织模块的,本质就是一个目录(必须带有一个__init__.py文件)。
模块分为三种:
- 自定义模块
- 内置标准模块(又称标准库)
- 开源模块
自定义模块
定义模块
其实就是以.py结尾python文件,文件名例如为test.py,那么模块名就是test。
模块的导入
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。导入模块有一下几种方法:
import module
from module.xx.xx import xx
from module.xx.xx import xx as rename
from module.xx.xx import *
导入模块其实就是告诉Python解释器去解释那个py文件
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
import test 相当于在当前引入模块的文件下定义了一个变量
test='test.py的所有代码' from test import name 相当于在当前引入模块的文件下拿到test模块里面name变量和值
name='test.py的name值'
如果文件需要多处使用到模块,那么使用form导入效率更高一些,因为import会重复的导入
# import module_test
from module_test import test def logger():
test()
print('in the logger') def search():
test()
print('in the search')
那么问题来了,导入模块时是根据那个路径作为基准来进行的呢?即:sys.path
import sys
print sys.path
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append('路径') 添加。
通过os模块可以获取各种目录,例如:


import sys
import os pre_path = os.path.abspath('__file__')
sys.path.append(pre_path)
开源模块
下载安装
yum
pip
apt-get
方式一
下载源码
解压源码
进入目录
编译源码 python setup.py build
安装源码 python setup.py install
方式二
注:在使用源码安装时,需要使用到gcc编译和python开发环境,所以,需要先执行:
yum install gcc
yum install python-devel
或
apt-get python-dev
安装成功后,模块会自动安装到 sys.path 中的某个目录中。
导入模块
同自定义模块中导入的方式
内置模块
time & datetime模块
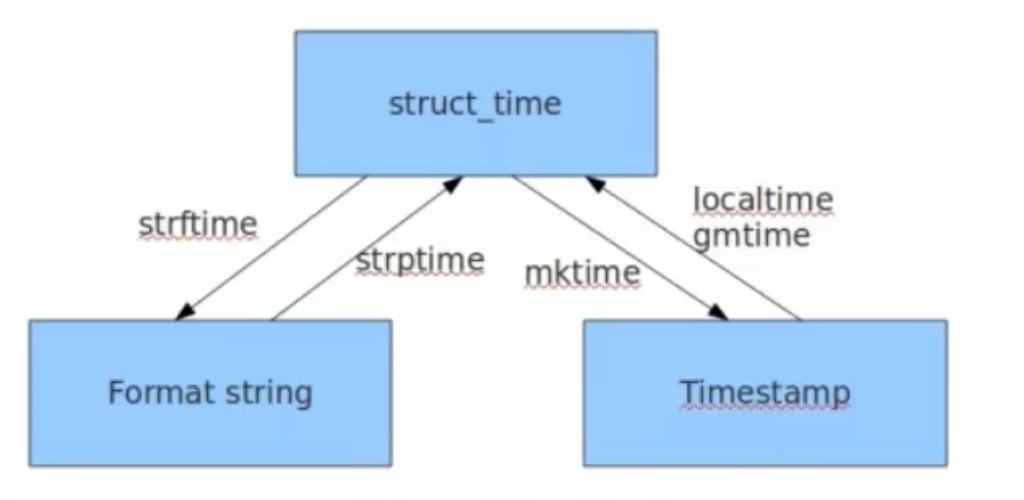
time模块的方法可以通过help(time)查看,在里面的方法可以help(time.localtime)。分为时间戳,结构化时间(元祖),格式化时间字符串,这三种转化关系为
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
# 时间戳
print(time.time()) # 1531982635.617672 时间戳 1970年开始计数的 # 结构化时间,按照服务器的时区utc+8
print(time.localtime()) # time.struct_time(tm_year=2018, tm_mon=7, tm_mday=19, tm_hour=14, tm_min=56, tm_sec=14, tm_wday=3, tm_yday=200, tm_isdst=0) # 结构化时间,utc时间,可以对比上面时间差
print(time.gmtime()) # time.struct_time(tm_year=2018, tm_mon=7, tm_mday=19, tm_hour=6, tm_min=50, tm_sec=15, tm_wday=3, tm_yday=200, tm_isdst=0)
time_obj = time.gmtime()
print(time_obj.tm_year,time_obj.tm_mon) # 2018 7 注意下day的值,周一是0,而且是utc时间 # 时间戳转换成struct_time格式
print(time.gmtime(time.time()-86400)) # time.struct_time(tm_year=2018, tm_mon=7, tm_mday=18, tm_hour=6, tm_min=53, tm_sec=37, tm_wday=2, tm_yday=199, tm_isdst=0) # 结构化时间转成时间戳
time_obj = time.gmtime()
print(time.mktime(time_obj)) # 1531954699.0 # 结构化时间转成格式化字符串
tm = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())
print(tm) # 2018-07-19 15:02:11 # 格式化字符串转成结构化时间
tm = time.strptime('2018-07-19','%Y-%m-%d')
print(tm) # time.struct_time(tm_year=2018, tm_mon=7, tm_mday=19, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=200, tm_isdst=-1)
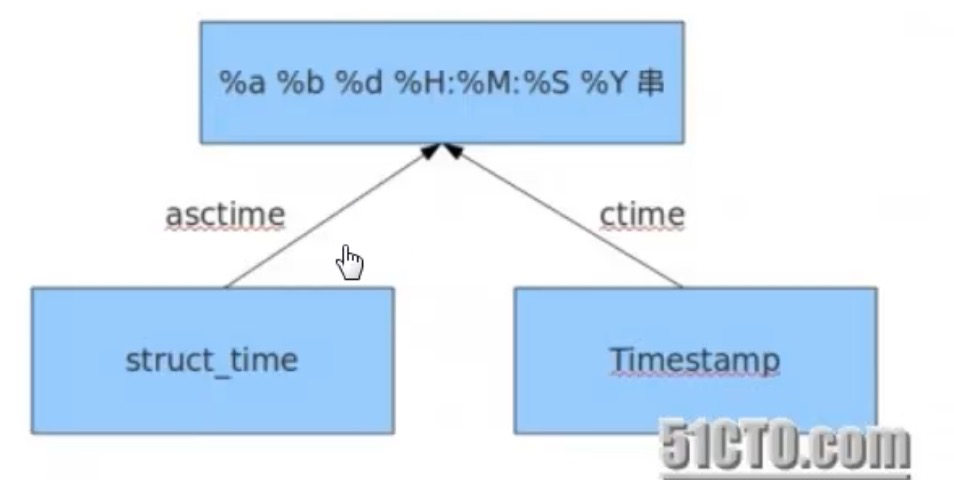
# 结果都是Sat Dec 26 18:23:06 2020
print(time.asctime())
print(time.ctime())
print(time.asctime(time.localtime()))
print(time.ctime(time.time()))
datetime相关
# 与日期相关在date方法里面
print(datetime.date)
# 与时间相关在time方法里面
print(datetime.time)
# 与时期时间相关在datetime里面
print(datetime.datetime) # 当前时间
print(datetime.datetime.now())
# 时间戳直接转成格式化时间字符串
print(datetime.date.fromtimestamp(time.time()))
print(datetime.datetime.fromtimestamp(time.time()))
# 时间加减
print(datetime.datetime.now() + datetime.timedelta(3)) # 3天后时间
print(datetime.datetime.now() + datetime.timedelta(-3)) # 3天前时间
print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 3小时后
print(datetime.datetime.now() + datetime.timedelta(hours=-3)) # 3小时前
# 时间替换
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2)) #时间替换
random模块
随机数
import random
print(random.random()) 0-1之间的小数
print(random.randint(1,2)) 1,2随机
print(random.randrange(1,10,2)) 有布长1,3,5,7,9
生成随机数
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)
os模块
提供对操作系统进行调用的接口
os.walk() 显示目录下所有文件和子目录以元祖的形式返回,第一个是目录,第二个是文件夹,第三个是文件
open(r'tmp\inner\file',w) 创建文件
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 可以先记录当前文件目录
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.') 没什么用
os.pardir 获取当前目录的父目录字符串名:('..') 没什么用
os.makedirs('dirname1/dirname2') 可生成多层递归目录 dirname1如果存在就在下面创建,不存在都创建,如果都存在就报错,可通过
修改里面exist_ok=ok来解决这个报错
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推,
但是若目录不为空,首先你要先删除文件,不然报错
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command) 运行shell命令,获取执行结果
print(ret.read()) 这样读取出来popen的结果
os.environ 获取系统环境变量 os.path 括号内pathn就是文件夹和文件
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path)返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
print(os.path.join(os.getcwd(),'filename'))
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小 # 注意:os.stat('path/filename') 获取文件/目录信息 的结构说明
stat 结构:
st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
sys模块
与python解释器交互的接口
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称 如果执行 python3 test.py liqianlong 18
那么在test.py中的print(sys.argv)
0 是程序文件本身名称,1 是 liqianlong,2 是18 进度条实例
import sys
import time def view_bar(num,total):
rate = float(num) / total
rate_num = int(rate * 100)
r = '\r%s>%d%%' % ('='*num,rate_num)
# \r回到当前行的首部位
sys.stdout.write(r) # 相对比print,就是没有换行符
sys.stdout.flush() # 输出清空 if __name__ == '__main__':
print( '\r%s>%d%%' % ('=',50))
print( '\r%s>%d%%' % ('=',100))
for i in range(1,101):
time.sleep(0.3)
view_bar(i,100)
shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中,可以部分内容
f1 = open('src.txt','r',encoding='utf-8')
f2 = open('dsc.txt','w',encoding='utf-8')
shutil.copyfileobj(f1,f2,length=16*1024) 不加length,就是将文件内容拷贝到另一个文件中了
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('src.txt','dsc.txt')
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('src.txt','dsc.xt')
shutil.copystat(src, dst)
拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('src.txt','dsc.txt')
shutil.copy(src, dst)
拷贝文件和权限
shutil.copy('src.txt','dsc.txt')
shutil.copy2(src, dst)
拷贝文件和状态信息
shutil.copy2('src.txt','dsc.txt')
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件
shutil.copytree('dir1','dir2')
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
shutil.rmtree('dir1')
shutil.move(src, dst)
递归的去移动文件
shutil.move('src.txt','dir1')
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录 import shutil
ret = shutil.make_archive("wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test') #将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录
import shutil
ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
import zipfile
z = zipfile.ZipFile('yasuo.zip','w')
z.write('lala')
z.write('haha')
z.close()
z = zipfile.ZipFile('yazuo.zip','r')
z.extractall()
z.close()
zipfile
import tarfile # 压缩
tar = tarfile.open('yasuo.tar','w')
tar.add('1.txt', arcname='1.txt') # arcname 存档中备用名,可不用设
tar.add('2.txt', arcname='2.txt')
tar.close() # 解压
tar = tarfile.open('your.tar','r')
tar.extractall() # 可设置解压地址,咱们写的都是相对的
tar.close()
tarfile
json&pickle模块
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
import json
info = {'name':'alex','age':22,}
# 序列化二种方式
f = open("test.text","w+")
f.write(json.dumps(info)) # 如果字典中有函数的内存地址,是会报错的,只能是一些简单数据字典,字符串,列表,因为是所有语言通用交互
f.close()
f = open("test.text","w+")
json.dump(info,f)
f.close()
# 反序列化二种方式
f = open("test.text","r")
data = json.loads(f.read())
f.close()
f = open("test.text","r")
data = json.load(f)
f.close()
pickle与json用法相同,只不过是python语言自己识别,要注意的是文件是wb,rb
shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式,是在pickle更上一层的封装
import shelve
d = shelve.open('shelve_test') # 打开一个文件
class Test(object):
def __init__(self,n):
self.n = n
t = Test(123)
l = ["liqianlong","rain","test"]
dic = {"liqianlong":18}
d["l"] = l # 持久化列表
d["t"] = t # 持久化类
d["dic"] = dic # 持久化字典
d.close()
d = shelve.open('shelve_test') # 打开一个文件
d.get('l')
d.get('dic')
for i in d.items():
print(i)
xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
读操作
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest")
root = tree.getroot()
print(root.tag) # 主节点data
# 遍历xml文档
for child in root: # 子节点country
print(child.tag, child.attrib)
for i in child:# country下的子节点
print(i.tag, i.text, i.attrib) # 节点名称,文本,属性
# 通过iter过滤节点
for node in root.iter('year'):
print(node.tag, node.text)
# 还可以通过findall查找节点
for country in root.findall('country'):
rank = int(country.find('rank').text)
print(rank)
改,删操作
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
# 修改文本,属性
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated_by", "liqianlong")
tree.write("xmltest.xml")
# 删除节点
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
创建
import xml.etree.ElementTree as ET
new_xml = ET.Element("PersoninfoList") # 主节点
personinfo = ET.SubElement(new_xml, "personinfo", attrib={"enrolled": "yes"})
name = ET.SubElement(personinfo, "name",attrib={"username":"yes"})
name.text = "liqianlong"
age = ET.SubElement(personinfo, "age", attrib={"password": "yes"})
age.text = '18'
sex = ET.SubElement(personinfo, "sex")
personinfo2 = ET.SubElement(new_xml, "personinfo", attrib={"enrolled": "yes"})
name = ET.SubElement(personinfo2, "name")
name.text = "我是第二个人信息"
age = ET.SubElement(personinfo2, "age")
age.text = '19'
et = ET.ElementTree(new_xml) # 生成文档对象
et.write("test.xml", encoding="utf-8", xml_declaration=True) # 创建文件
ET.dump(new_xml) # 打印生成的格式
'''
<?xml version='1.0' encoding='utf-8'?>
<PersoninfoList>
<personinfo enrolled="yes">
<name username="yes">liqianlong</name>
<age password="yes">18</age>
<sex />
</personinfo>
<personinfo enrolled="yes">
<name>我是第二个人信息</name>
<age>19</age>
</personinfo>
</PersoninfoList>
'''
PyYAML模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
ConfigParser模块
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。
来看一个好多软件的常见文档格式如下
[DEFAULT]
compressionlevel = 9
compression = yes
serveraliveinterval = 45
forwardx11 = yes [bitbucket.org]
user = hg [topsecret.server.com]
host port = 50022
forwardx11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['DEFAULT']['ForwardX11'] = 'yes'
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022'
topsecret['ForwardX11'] = 'no'
with open('example.ini', 'w') as configfile:
config.write(configfile)
增删改查
import configparser conf = configparser.ConfigParser()
conf.read("example.ini") # 默认字段信息
print(conf.defaults()) # OrderedDict([('compressionlevel', '9'), ('compression', 'yes'), ('serveraliveinterval', '45'), ('forwardx11', 'yes')]) # 节点标题信息
print(conf.sections()) # ['bitbucket.org', 'topsecret.server.com'] # 节点标题添加
conf.has_section('liqianlong')
conf.add_section('liqianlong')
conf.write(open('example.ini', "w")) # 节点字段添加
conf.set('liqianlong','age','18')
conf.write(open('example.ini', "w")) # 节点字段信息,包括了默认的字段是一个列表
print(conf.options('bitbucket.org')) # ['user', 'compressionlevel', 'compression', 'serveraliveinterval', 'forwardx11']
print(conf.items('bitbucket.org')) # [('compressionlevel', '9'), ('compression', 'yes'), ('serveraliveinterval', '45'), ('forwardx11', 'yes'), ('user', 'hg')] # 节点某个字段查询
print(conf['bitbucket.org']['user'])
print(conf.get('bitbucket.org','user'))
print(conf.getint('bitbucket.org','user')) # 转int # 节点某个字段修改
conf['bitbucket.org']['user']='liqianlong'
conf.write(open('example.ini', "w")) # 节点删除
sec = conf.remove_section('bitbucket.org')
conf.write(open('example.ini', "w")) # 这里也可写一个新文件 # 节点删除某个字段
conf.remove_option('bitbucket.org','user')
conf.write(open('example.ini', "w"))
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest()) #2进制格式hash
print(m.hexdigest()) #16进制格式hash m2 = hashlib.md5()
m2.update(b"HelloIt's me")
print(m2.hexdigest()) #与上面结果一样 # ######## md5 ######## hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest()) # 中文情况
hash = hashlib.md5()
hash.update("天王盖地虎".encode(encoding="utf-8")) #encode之后就是byte类型了
print(hash.hexdigest())
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
import hmac
h = hmac.new(b"this must is ass","msg中文".encode(encoding="utf-8"))
print(h.hexdigest())
更多关于md5,sha1,sha256等介绍的文章看这里https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
Subprocess模块
#!/usr/bin/env python
#_*_coding:utf-8_*_ #linux 上调用python脚本
#os.system输出命令结果到屏幕,返回命令执行状态
#os.popen("dir") 返回内存对象,需要单独去取一下
#os.popen("dir").read() 保存命令的执行结果输出,但是不返回执行状态
# #py 2.7 from only linxu 2.7....
#commands = = == = commands.getstatusoutput("dir") 返回执行状态和结果
#print(res[0]) (res[1]) #subprocess python 3.5 ___run
import subprocess
# subprocess.run(["df","-h"])
# subprocess.run(["df","-h","|","grep","sda1"]) 命令执行会报错,因为加上管道符他解决不了
# subprocess.run(["df -h | grep sda1",shell=True]) 不需要python解析这个字符串,传给linux自己去解析 #os.system = = = subprocess.call("df -h",shell=True)输出命令结果到屏幕,返回命令执行状态
#subprocess.checkcall("df -h",shell=True)如果报错就抛出异常,也是返回状态
#subprocess.getstatusoutput("df -h",shell=True)返回执行状态和结果 ==== commands.getstatusoutput("dir")
#subprocess.getoutput("df -h",shell=True)返回结果= = =os.popen("dir")
# #subprocess.Popen("ifconfig|grep 192",shell=True,subprocess.PIPE) pipe 管道意思
#res.stdout.read() 标准输出
#subprocess.Popen("dddd",shell=True,subprocess.PIPE,stderr=subprocess.PIPE)
#res.stderr.read() 标准错误
#subprocess.Popen("sleep30:echo 'hello'",shell=True,subprocess.PIPE,stderr=subprocess.PIPE)
#print(res.poll()) 这个是返回执行的状态,执行完了返回0没有执行返回None
#print(res.wait()) 等待返回结果 #terminate()杀掉所启动的进程
#subprocess.Popen("sleep30:echo 'hello'",shell=True,subprocess.PIPE,stderr=subprocess.PIPE)
#res.terminate()
#res.stdout.read() 是没有结果的,因为在上一个命令进程杀掉了 #communicate()等待任务结束 忘了他吧
#subprocess.Popen(['python3'],shell=True,subprocess.PIPE,stderr=subprocess.PIPE,stdin=subprocess.PIPE)
#res.stdin.write(b"print(1)")
#res.stdin.write(b"print(2)")
#res.communicate() #cwd新启动的shell环境默认在哪个地方
#subprocess.Popen(['pwd'],shell=True,subprocess.PIPE,cwd="/tmp")
#res.stdout.read() #subprocess 交互输入密码
#subprocess.Popen("sudo apt-get install vim",shell=True) 环境乱了
#echo "pwd" | sudo -S apt-get install vim -S从标准输入读取密码
#subprocess.Popen("echo 'pwd' | sudo -S apt-get install vim ",shell=True) 通过python可以
这个模块欠着吧。。。。
logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,下面我们看一下怎么用。
最简单用法
import logging
logging.warning("user [liqianlong] attempted wrong password more than 3 times")
logging.critical("server is down")
#输出,这是直接输出在终端上
WARNING:root:user [liqianlong] attempted wrong password more than 3 times
CRITICAL:root:server is down
看一下这几个日志级别分别代表什么意思
| Level | When it’s used |
|---|---|
DEBUG |
Detailed information, typically of interest only when diagnosing problems. |
INFO |
Confirmation that things are working as expected. |
WARNING |
An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. |
ERROR |
Due to a more serious problem, the software has not been able to perform some function. |
CRITICAL |
A serious error, indicating that the program itself may be unable to continue running. |
如果想把日志写到文件里,也很简单
import logging logging.basicConfig(filename='example.log',level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
logging.basicConfig(filename='example.log',level=logging.INFO)
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.') #文件中显示
12/12/2010 11:46:36 AM is when this event was logged.
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识了
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
import logging # create logger
logger = logging.getLogger('log模块') # 一般是指某个程序或者模块
logger.setLevel(logging.DEBUG) # create console handler and set level to debug
ch = logging.StreamHandler() # 默认是 sys.stderr,也可以指定文件对象
ch.setLevel(logging.DEBUG) # create file handler and set level to warning
fh = logging.FileHandler("access.log") # 给一个文件
fh.setLevel(logging.WARNING) # create formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 定义日志格式 # add formatter to ch and fh 给handler添加格式
ch.setFormatter(formatter)
fh.setFormatter(formatter) # add ch and fh to logger 给logger添加handler
logger.addHandler(ch)
logger.addHandler(fh) # 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message') # 日志先进入logger级别过滤,然后通过handler对象负责发送相关的信息到指定目的地
re模块
常用正则表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
实例:
match开头匹配,group拿到匹配值
>>> re.match('abc','abc123')
<_sre.SRE_Match object; span=(0, 3), match='abc'>
>>> re.match('abc','abc123').group()
'abc'
>>> re.match('abc','babc123').group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group' search从头匹配,group拿到匹配值,但是只拿到第一次匹配成功后就停止了,不会再进行匹配
>>> re.search('abc','babc123')
<_sre.SRE_Match object; span=(1, 4), match='abc'>
>>> re.search('abc','babc123').group()
'abc'
>>> re.search('abc','babc123abc').group()
'abc' findall从头匹配,没有group方法,匹配所有,返回列表
>>> re.findall('abc','babc123abc')
['abc', 'abc'] split以什么分割,返回列表
>>> re.split('\d','babc123abc')
['babc', '', '', 'abc']
>>> re.split('\d+','babc123abc')
['babc', 'abc'] sub替换,将匹配到的替换
>>> re.sub('\d+','N','babc123abc')
'babcNabc'
>>> re.sub('\d','N','babc123abc')
'babcNNNabc' 有名分组
>>> re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict()
{'province': '3714', 'city': '81', 'birthday': '1993'}
>>> re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").group('province')
'3714'
反斜杠的困扰
匹配反斜杠,这里要注意的是比如匹配的字符串是一个\,那么你要改成\\
>>> re.search('\\\\','abc\\abc')
<_sre.SRE_Match object; span=(3, 4), match='\\'>
>>> re.search(r'\\','abc\\abc')
<_sre.SRE_Match object; span=(3, 4), match='\\'>
关于正则 https://www.cnblogs.com/jokerbj/p/7327849.html
关于re https://www.cnblogs.com/jokerbj/p/7327894.html
collections¶miko模块
参考 https://www.cnblogs.com/jokerbj/p/7327903.html
本节作业
开发一个简单的python计算器
- 实现加减乘除及拓号优先级解析
- 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式(不能调用eval等类似功能偷懒实现),运算后得出结果,结果必须与真实的计算器所得出的结果一致
import re
import functools def minus_operator_handler(formula):
'''处理一些特殊的减号运算'''
minus_operators = re.split("-",formula)
calc_list= re.findall("[0-9]",formula)
if minus_operators[0] == '': #第一值肯定是负号
calc_list[0] = '-%s' % calc_list[0]
res = functools.reduce(lambda x,y:float(x) - float(y), calc_list)
print("\033[33;1m减号[%s]处理结果:\033[0m" % formula, res )
return res def remove_duplicates(formula):
formula = formula.replace("++","+")
formula = formula.replace("+-","-")
formula = formula.replace("-+","-")
formula = formula.replace("--","+")
formula = formula.replace("- -","+")
return formula
def compute_mutiply_and_dividend(formula):
'''算乘除,传进来的是字符串噢'''
operators = re.findall("[*/]", formula )
calc_list = re.split("[*/]", formula )
res = None
for index,i in enumerate(calc_list):
if res:
if operators[index-1] == "*":
res *= float(i)
elif operators[index-1] == "/":
res /= float(i)
else:
res = float(i) print("\033[31;1m[%s]运算结果=\033[0m" %formula, res )
return res
def handle_minus_in_list(operator_list,calc_list):
'''有的时候把算术符和值分开后,会出现这种情况 ['-', '-', '-'] [' ', '14969037.996825399 ', ' ', '12.0/ 10.0 ']
这需要把第2个列表中的空格都变成负号并与其后面的值拼起来,恶心死了
'''
for index,i in enumerate(calc_list):
if i == '': #它其实是代表负号,改成负号
calc_list[index+1] = i + calc_list[index+1].strip()
def handle_special_occactions(plus_and_minus_operators,multiply_and_dividend):
'''有时会出现这种情况 , ['-', '-'] ['1 ', ' 2 * ', '14969036.7968254'],2*...后面这段实际是 2*-14969036.7968254,需要特别处理下,太恶心了'''
for index,i in enumerate(multiply_and_dividend):
i = i.strip()
if i.endswith("*") or i.endswith("/"):
multiply_and_dividend[index] = multiply_and_dividend[index] + plus_and_minus_operators[index] + multiply_and_dividend[index+1]
del multiply_and_dividend[index+1]
del plus_and_minus_operators[index]
return plus_and_minus_operators,multiply_and_dividend
def compute(formula):
'''这里计算是的不带括号的公式''' formula = formula.strip("()") #去除外面包的拓号
formula = remove_duplicates(formula) #去除外重复的+-号
plus_and_minus_operators = re.findall("[+-]", formula)
multiply_and_dividend = re.split("[+-]", formula) #取出乘除公式
if len(multiply_and_dividend[0].strip()) == 0:#代表这肯定是个减号
multiply_and_dividend[1] = plus_and_minus_operators[0] + multiply_and_dividend[1]
del multiply_and_dividend[0]
del plus_and_minus_operators[0] plus_and_minus_operators,multiply_and_dividend=handle_special_occactions(plus_and_minus_operators,multiply_and_dividend)
for index,i in enumerate(multiply_and_dividend):
if re.search("[*/]" ,i):
sub_res = compute_mutiply_and_dividend(i)
multiply_and_dividend[index] = sub_res #开始运算+,-
print(multiply_and_dividend, plus_and_minus_operators)
total_res = None
for index,item in enumerate(multiply_and_dividend):
if total_res: #代表不是第一次循环
if plus_and_minus_operators[index-1] == '+':
total_res += float(item)
elif plus_and_minus_operators[index-1] == '-':
total_res -= float(item)
else:
total_res = float(item)
print("\033[32;1m[%s]运算结果:\033[0m" %formula,total_res)
return total_res def calc(formula):
'''计算程序主入口, 主要逻辑是先计算拓号里的值,算出来后再算乘除,再算加减'''
parenthesise_flag = True
calc_res = None #初始化运算结果为None,还没开始运算呢,当然为None啦
while parenthesise_flag:
m = re.search("\([^()]*\)", formula) #找到最里层的拓号
if m:
#print("先算拓号里的值:",m.group())
sub_res = compute(m.group())
formula = formula.replace(m.group(),str(sub_res))
else:
print('\033[41;1m----没拓号了...---\033[0m') print('\n\n\033[42;1m最终结果:\033[0m',compute(formula))
parenthesise_flag = False #代表公式里的拓号已经都被剥除啦 if __name__ == '__main__': #res = calc("1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )")
res = calc("1 - 2 * ( (60-30 +(-9-2-5-2*3-5/3-40*4/2-3/5+6*3) * (-9-2-5-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )")
python重拾第五天-常用模块学习的更多相关文章
- Day5 - Python基础5 常用模块学习
Python 之路 Day5 - 常用模块学习 本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shel ...
- python【第五篇】常用模块学习
一.主要内容 模块介绍 time &datetime模块 random os sys shutil json & pickle shelve xml处理 yaml处理 configpa ...
- python(五)常用模块学习
版权声明:本文为原创文章,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明. https://blog.csdn.net/fgf00/article/details/52357 ...
- Python之常用模块学习(二)
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
- Python 之路 Day5 - 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- Python常用模块学习
1.模块介绍 2.time & datetime模块 3.random 4.os 5.sys 6.shutil 7.json&pickle 8.shelve 9.xml处理 10.ya ...
- Python函数篇(6)-常用模块及简单的案列
1.模块 函数的优点之一,就是可以使用函数将代码块与主程序分离,通过给函数指定一个描述性的名称,并将函数存储在被称为模块的独立文件中,再将模块导入主程序中,通过import语句允许在当前运行的程序 ...
- Python基础(正则、序列化、常用模块和面向对象)-day06
写在前面 上课第六天,打卡: 天地不仁,以万物为刍狗: 一.正则 - 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法: - 在线正则工具:http://tool ...
- Python基础5 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- 人生苦短之我用Python篇(深浅拷贝、常用模块、内置函数)
深浅拷贝 有时候,尤其是当你在处理可变对象时,你可能想要复制一个对象,然后对其做出一些改变而不希望影响原来的对象.这就是Python的copy所发挥作用的地方. 定义了当对你的类的实例调用copy.c ...
随机推荐
- 优秀的 Modbus 主站(主机、客户端)仿真器、串口调试工具
目录 优秀的 Modbus 主站(主机.客户端)仿真器.串口调试工具 主要功能 软件截图 优秀的 Modbus 主站(主机.客户端)仿真器.串口调试工具 modbus master,modbus,串口 ...
- C语言程序设计-笔记8-结构
C语言程序设计-笔记8-结构 例9-1 输出平均分最高的学生信息.根据学生的基本信息包括学号.姓名.三门课程成绩以及个人平均成绩.输入n个学生的成绩信息,计算并输出平均分最高的学生信息. #incl ...
- web3.js:使用eth包
原文在这里 简介 web3-eth包提供了一套强大的功能,可以与以太坊区块链和智能合约进行交互.在本教程中,我们将指导您如何使用web3.js版本4的web3-eth包的基础知识.我们将在整个示例中使 ...
- wpf 无法从流中加载光标
使用wpf 加载图片光标时,无论是用光标文件的绝对路径还是使用uri资源的方式都不得行,及报无法从文件中加载光标或无法从流中加载光标.这中情况,就很有可能是光标cur文件不是标准的光标文件.比如你是通 ...
- golang http client 长连接vs短连接基准测试
package main import ( "io/ioutil" "net/http" "strings" "testing&q ...
- 二叉树的遍历(BFS、DFS)
二叉树的遍历(BFS.DFS) 本文分为以下部分: BFS(广度优先搜索) DFS(深度优先搜索) 先序遍历 中序遍历 后序遍历 总结 BFS(广度优先搜索) 广度优先搜索[^1](英语:Breadt ...
- .NET桌面程序混合开发之二:在原生WinFrom程序中使用WebView2
本文将介绍如何在WinForms中嵌入WebView2,并讲到WebView2的主要特征.点击了解更多WebView2的API. 1. 准备 Visual Studio 2017 及以上版本 WebV ...
- 通过 InnoSetup 美化安装界面
InnoSetup 的美化相应的帖子也比较多,但是代码不是很全...所以我专门出了这篇文章来记录下这个美化过程.废话不多说,先上个成果: 前端er们可以直接下载 vue-nw-seed 这个分支,一键 ...
- 最好的在线PDF转换工具服务
工作中有时候会碰到需要转换PDF文件的情况,现在网上就要很多免费的在线工具,可以进行PDF文件的转换,下面就来介绍一些可以直接在浏览器中将文档.电子表格.和图片转换为PDF或者互相转换的服务工具. ...
- 《最新出炉》系列入门篇-Python+Playwright自动化测试-49-Route类拦截修改请求-下篇
1.简介 在日常工作和学习中,自动化测试的时候:在加载页面时,可能页面出现很多不是很重要或者不是我们所关注的,这个时候我们就可以选择不加载这些内容,以提高页面加载速度,节省资源.例如:可能页面上图片比 ...