浪潮计算平台之AI方向——AI_Station开发环境的使用总结
概览:

1. 开发环境
使用默认的设置,不改挂载路径:

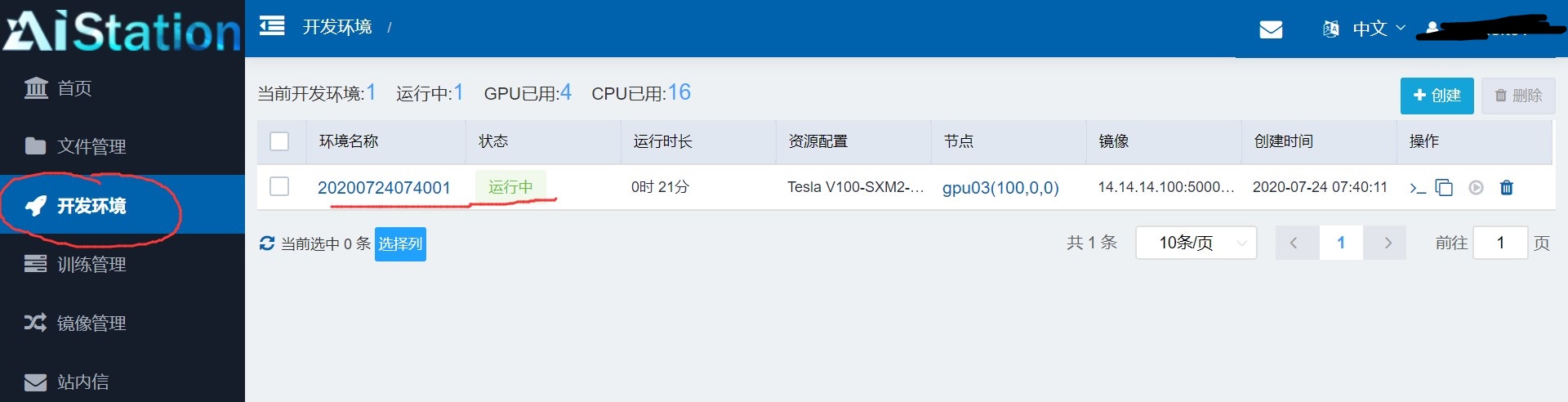



可以看到在容器内对挂载的目录进行文件操作是可以真实记录到实际的文件目录内的。

对挂载路径的另一种设置:
不使用默认的设置,手动更改挂载路径:
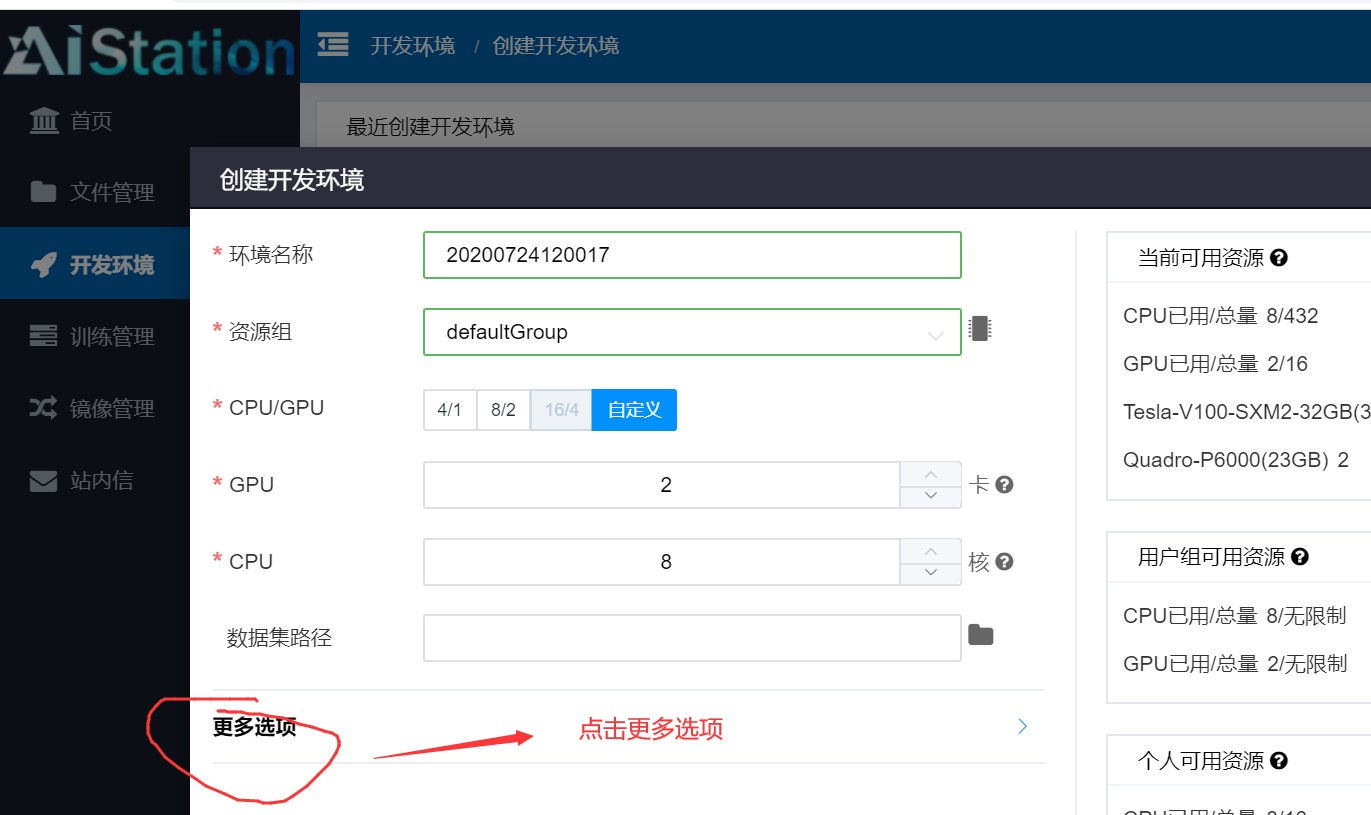

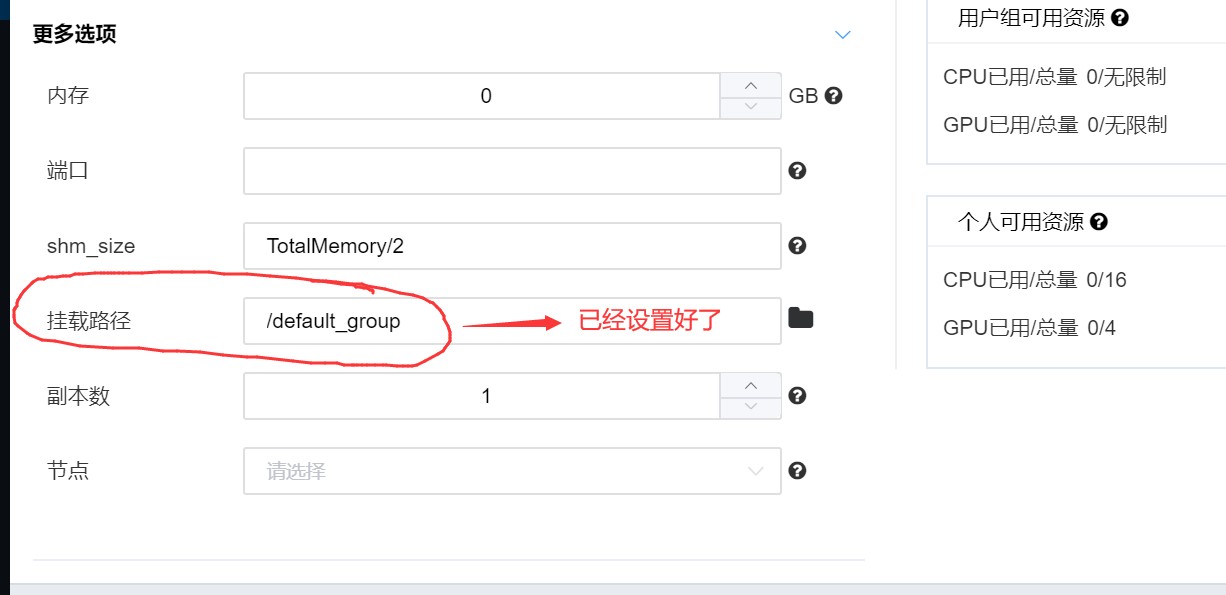


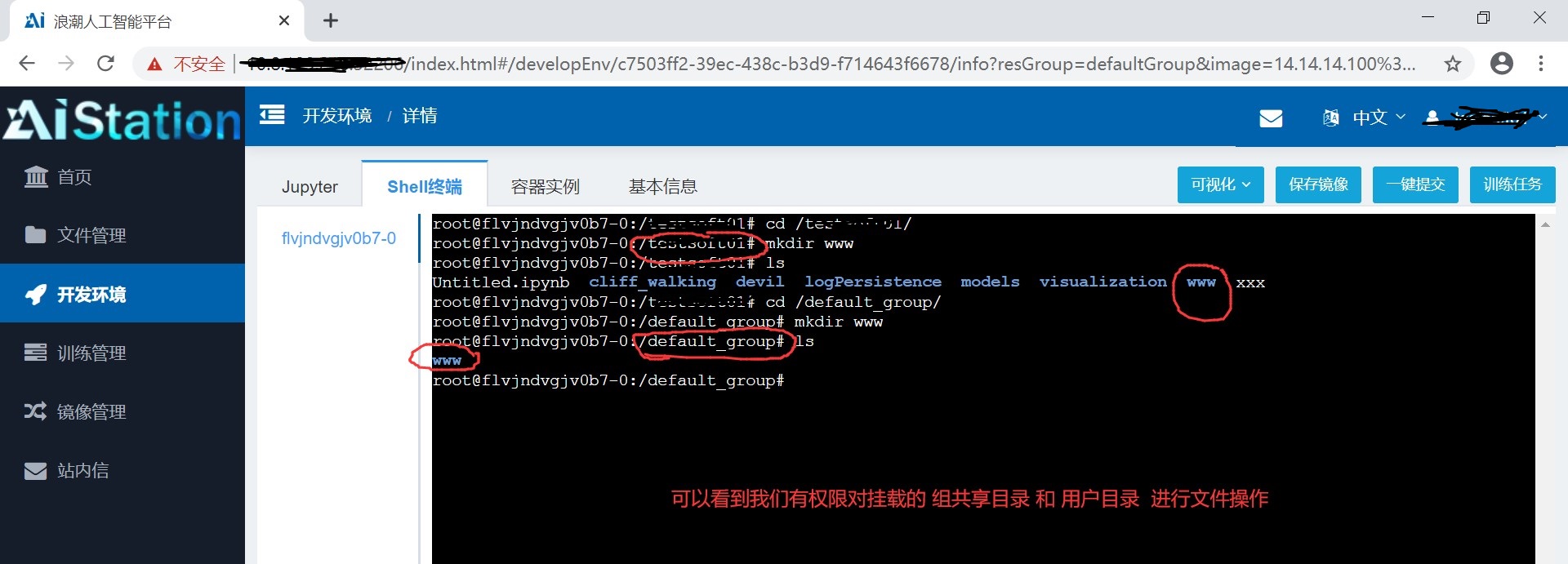
在用户文件目录和组共享目录中可以看到容器内对其进行的操作:


挂载到容器里的文件目录都是可以在容器里面进行文件操作的,这时的操作会实时的体现在用户的文件管理上。比如我们将default_group文件目录挂载在容器上,新建两个目录aaa和bbb, 都是可以的,而我们在web管理界面上是没有权限对 default_group文件目录进行操作的。
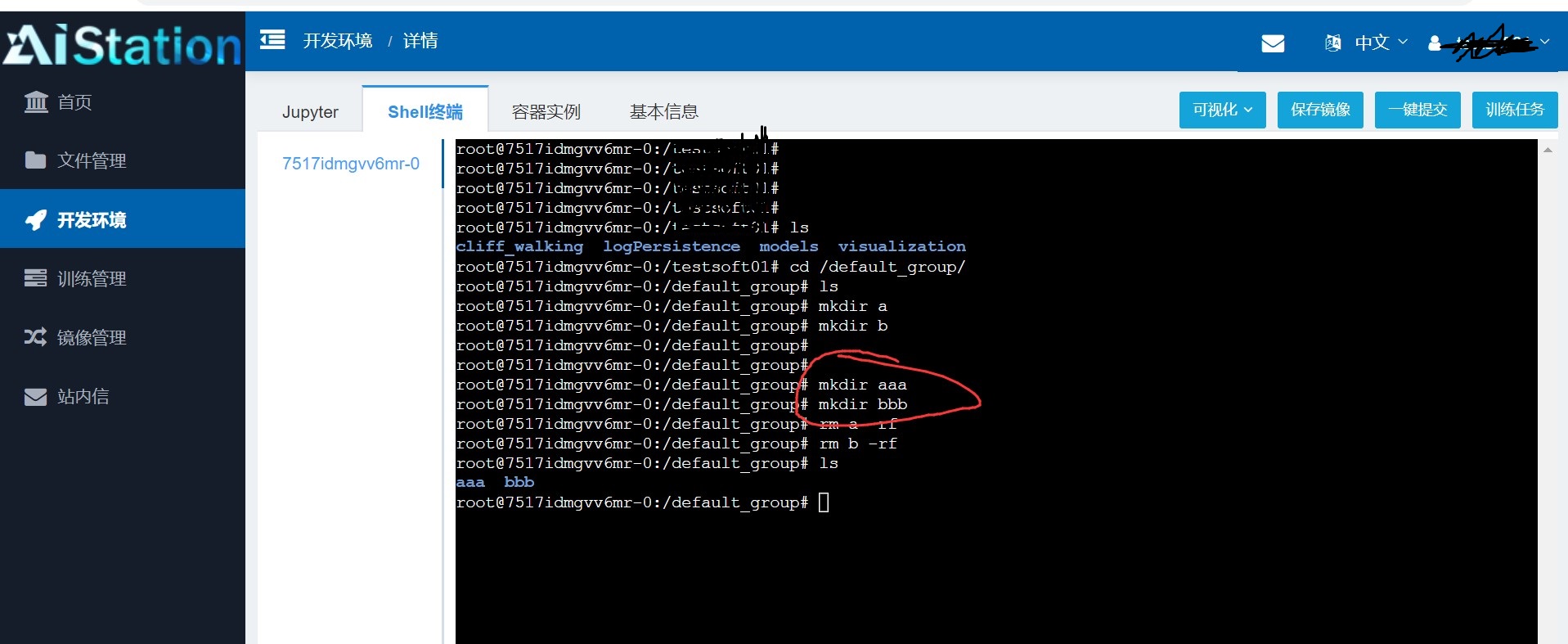
如下,可以发现成功对 default_groupt文件目录进行操作。
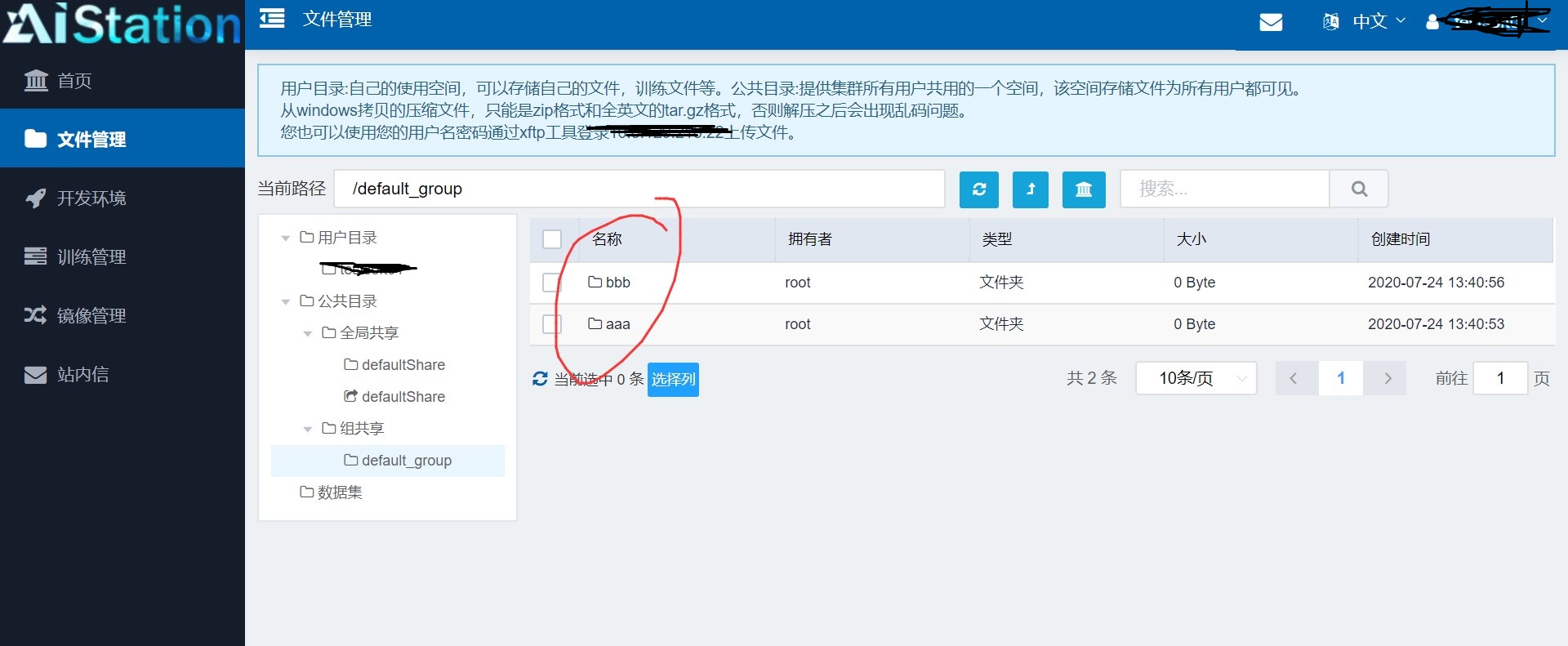
可以说在设置容器的时候选择的挂载目录是可以在容器里面对其内的文件进行完全操作的,我们可以远程上传或下载文件、代码、数据集等到挂载文件中,这样我们在容器里面也是可以完全进行操作的,这样方便我们在计算的时候使用一些平台上没有原生给出的资源。
在对容器进行设置的时候我们可以看到有一个选项是数据集路径,数据路径可以指定为文件管理目录下的一个目录,但是这里不推荐指定用户的文件目录,这里就是 /xxxxxx , 该路径默认是挂载到容器里面的,如果再将该路径作为数据集目录挂载到容器里面容易产生错误,因此在设置数据集路径时候选择不是用户文件目录的路径。如下,将默认挂载的/xxxxxx路径同时设置为数据集目录则显示报错,提示缓存数据拉取错误。

注:平台给出挂载目录的目的就是为了提供一个路径使容器和外界文件能够得到交互,是一个双向的过程,而数据集路径的设置是一个单方向的设置,其目的就是多个用户可以共享一些共同使用的文件,这样可以减少磁盘空间的浪费和数据多次重复上传的问题,这里面就要求这个数据集路径的内容是只读的,每个用户对容器设置数据集路径后只是从平台管理数据的磁盘上复制这个路径的内容到计算磁盘上,可以说容器里面看到的数据集路径里面的内容是原文件的影子,我们对其总任何更改也不会影响到原始数据。
挂载目录和数据集目录示意图:

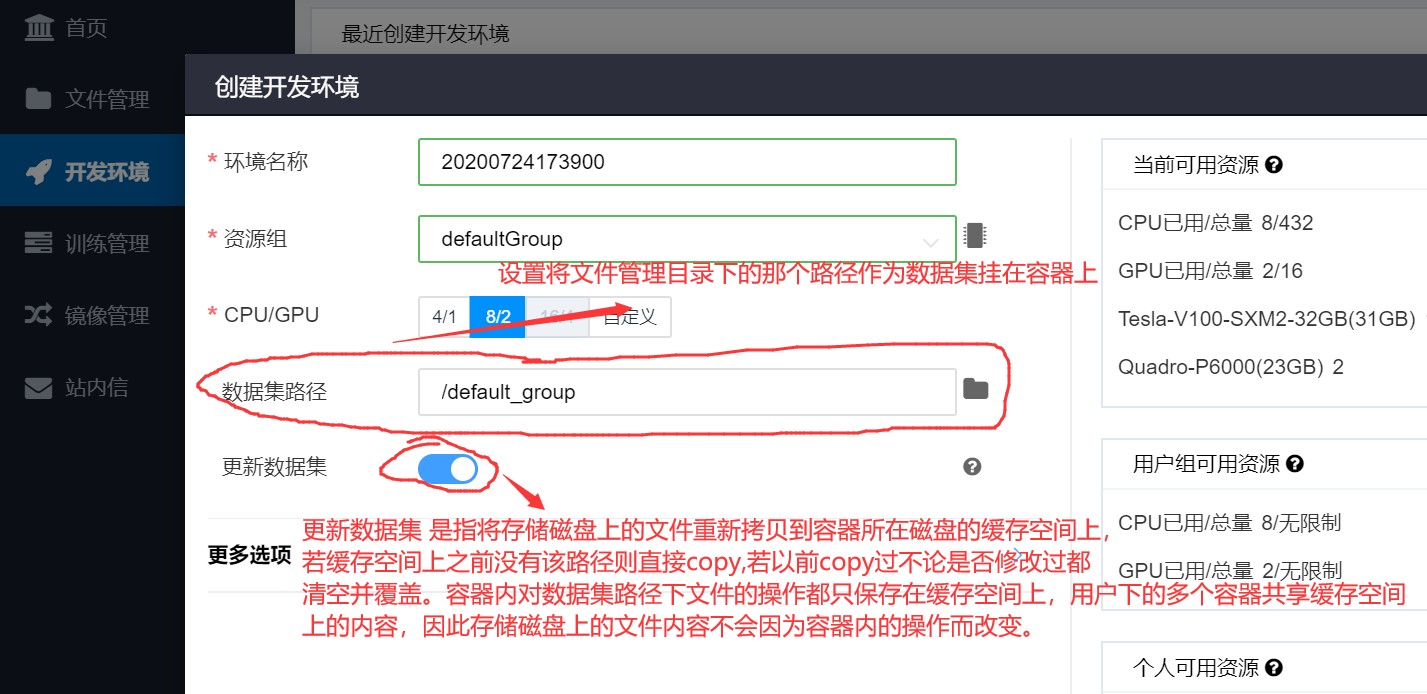
如:将存储磁盘上的 /default_group作为数据集路径挂载容器a上,并在容器a上做修改,建立文件 /default_group/x , /default_group/xx , /default_group/xxx 。在存储磁盘上建立目录 /default_group/aaa , /default_group/bbb ,将 /default_group/aaa 作为容器b的数据集,将/default_group/bbb 作为容器c的数据集,此时在容器b上建立目录 /default_group/aaa/x, /default_group/aaa/xx, /default_group/aaa/xxx ,此时在容器c上建立目录 /default_group/bbb/1, /default_group/aaa/2, /default_group/aaa/3 。然后在容器d上建立数据集路径 若为 /default_group 那么容器d的/default_group 和容器a是同一文件,如果建立容器d的时候没有选择更新,那么容器d上/default_goup下也是x,xx,xxx文件,如果选择更新那么容器a和容器d的/default_group目录下内容会和存储磁盘目录下保持一致,也就是/default_group/aaa , /default_group/bbb ,并且aaa和bbb下面是空的。
1.1 运算中断问题:
开发环境下有Jupter和Shell两种模式,其中Jupter下分为:Notebook、Control和Terminal。
Notebook适合开发和最终展示,Termianl适合做运算,Shell适合做文件操作。
1.1.1 Shell终端下:
开发环境下运行的代码只要用户退出(包括网络突然中断)就会自动终止。

注意:只要网络不中断和用户不退出(页面不能刷新和退出)的情况下运算是不会中断的,这一点和SSH登录远程主机进行运算一样。
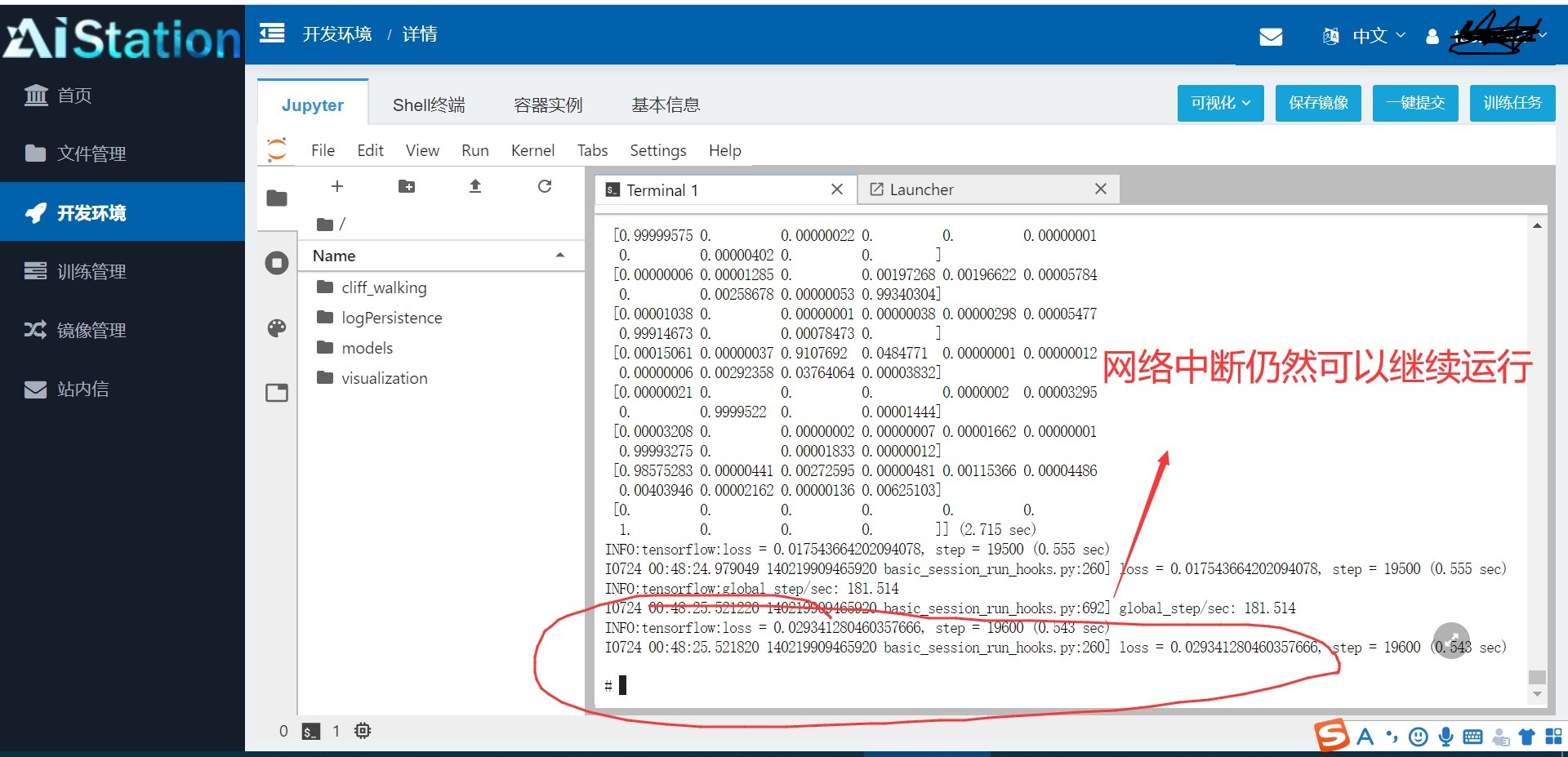
1.1.2 Jupyter下的Terminal:
Jupyter下的Terminal不会因为网络中断或者用户退出而导致运算中断。


1.1.3 Jupyter下的Notebook 和 Control :
可以看到Notebook和Control的当前目录都是容器所挂载的目录,即根目录下的和账户名相同的目录,这里是 “ /xxxxxx ” 。


这里有一点需要注意:Notebook和Control在网络断开或用户退出时,正在运行运算的计算也将被中断,同时Control不会保存开发的记录,而Notebook回保存开发的记录:
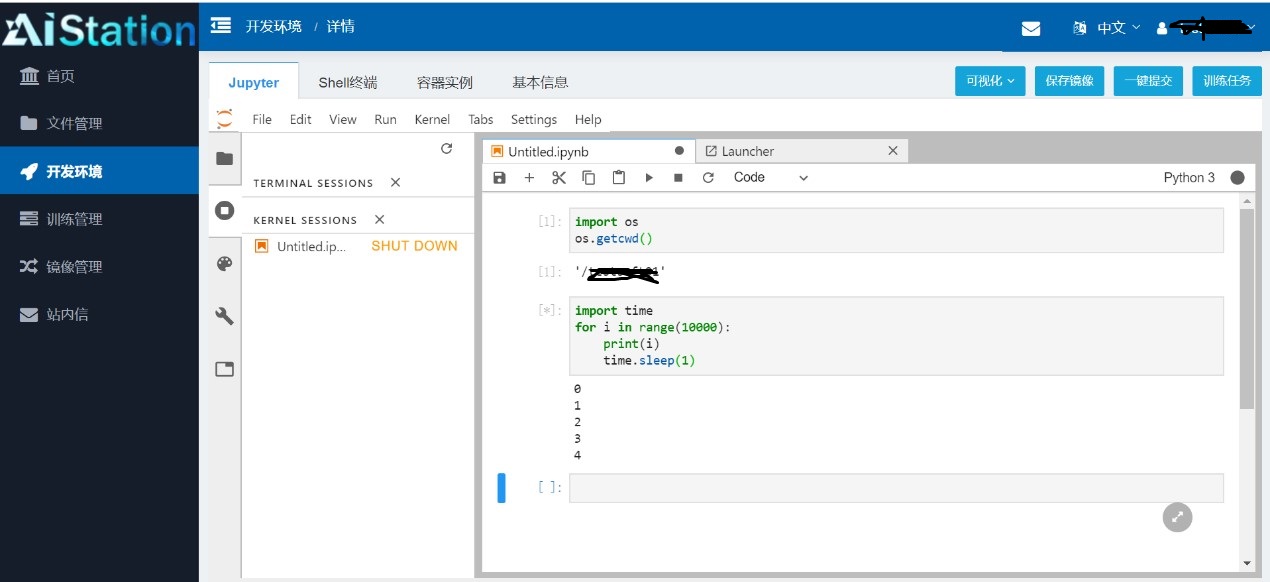
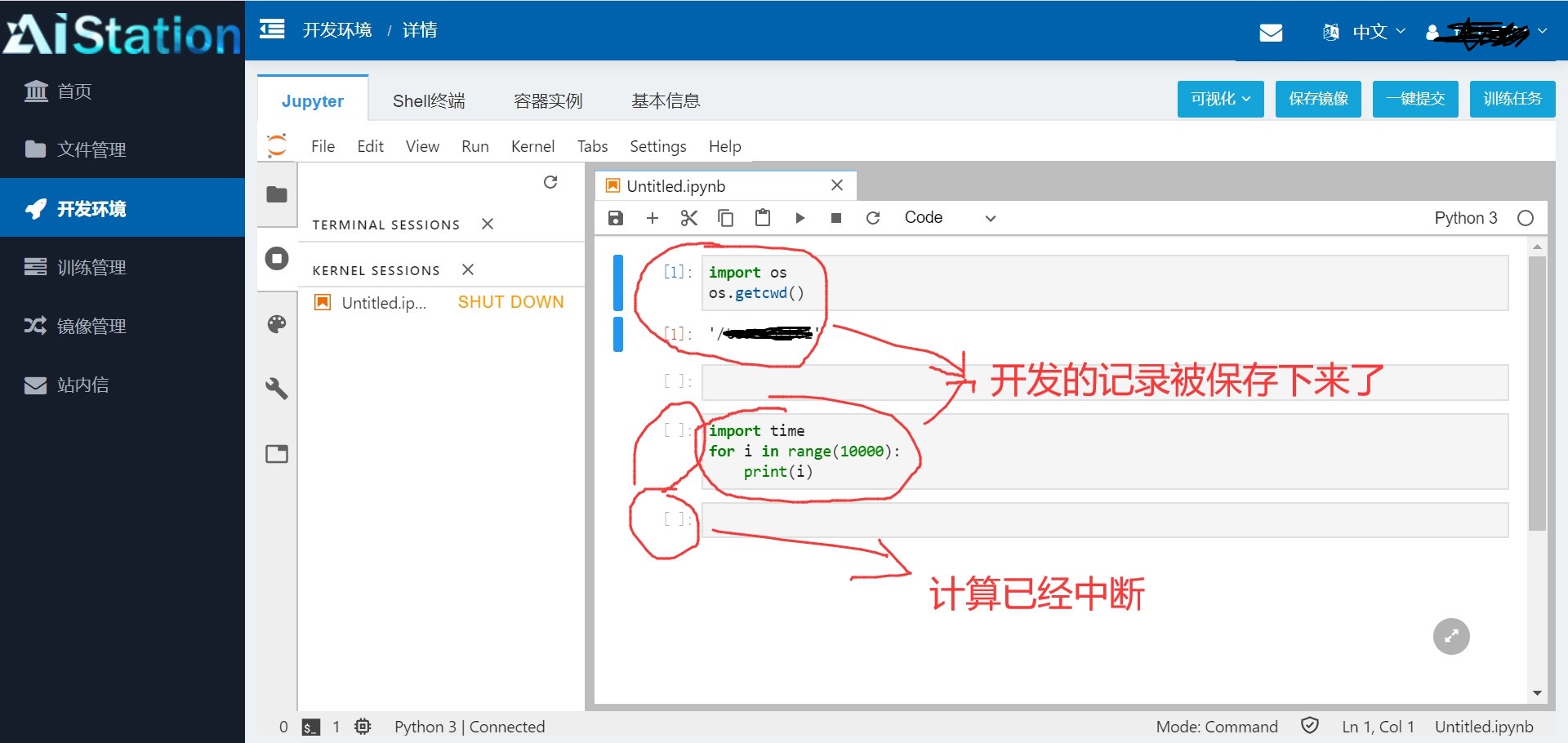
Control:


开发环境是为开发设计的,不过由于这个中断问题所以更适合做测试,开发环境下唯一可以不被外界原因中断的只有Teminal ,因此Teminal下适合做最终运算,但是Teminal下不能尽量历史输入的查询因此不是很适合做文件操作。Notebook能够保存开发记录并能做到图片展示等可视化功能,开发使用OK,但是由于会被外界中断所以不适合做最终的运算操作。Shell下面更适合做数据文件操作,如文件的创建、重命名、删除等功能,由于不能进行图片展示,不能保存开发记录,能够被外界中断,因此不适合开发和运算,更适合做数据文件操作。
1.2运行效率对比:
第一组(非科学计算类,效率影响主要为CPU和内存性能):
运行代码:(https://gitee.com/devilmaycry812839668/cliff_walking)(设置实验次数1000)

个人电脑运行(4.8G主频,i7-10700k CPU单核心, 2666频率内存)平均时间为511.5秒。
AI_Station平台(单核心CPU)平均运行时间为558.8秒。
平台与个人电脑的运算效率比可以到达91.5%。(对于大型计算平台来讲效率已经非常高了)
第二组(科学计算类,效率影响主要为CPU(浮点型矢量计算)和内存性能):

个人电脑运行(4.8G主频,i7-10700k CPU 物理核心为8并开启超线程, 2666频率内存)运行时间为488.77秒。
AI_Station平台(16核心CPU)平均运行时间为881.11秒。
平台与个人电脑的运算效率比可以到达55.47%。
考虑可能有内存IO的影响,于是测试内存性能(空间申请测试):
大数据块:

个人主机时间:110.66秒。
平台运行时间:151.96秒。
平台与个人电脑的运算效率比可以到达72.82%。
小数据块:

个人主机时间:80.38秒。
平台运行时间:80.09秒。
平台与个人电脑的运算效率比可以到达 100.36%。
使用空间内存较小的对象进行科学计算:

个人主机时间:35.66秒。
平台运行时间:80.17秒。
平台与个人电脑的运算效率比可以到达 44.48%。
1.3 使用ftp工具上传文件:


1.4 使用SSH工具远程登入容器:
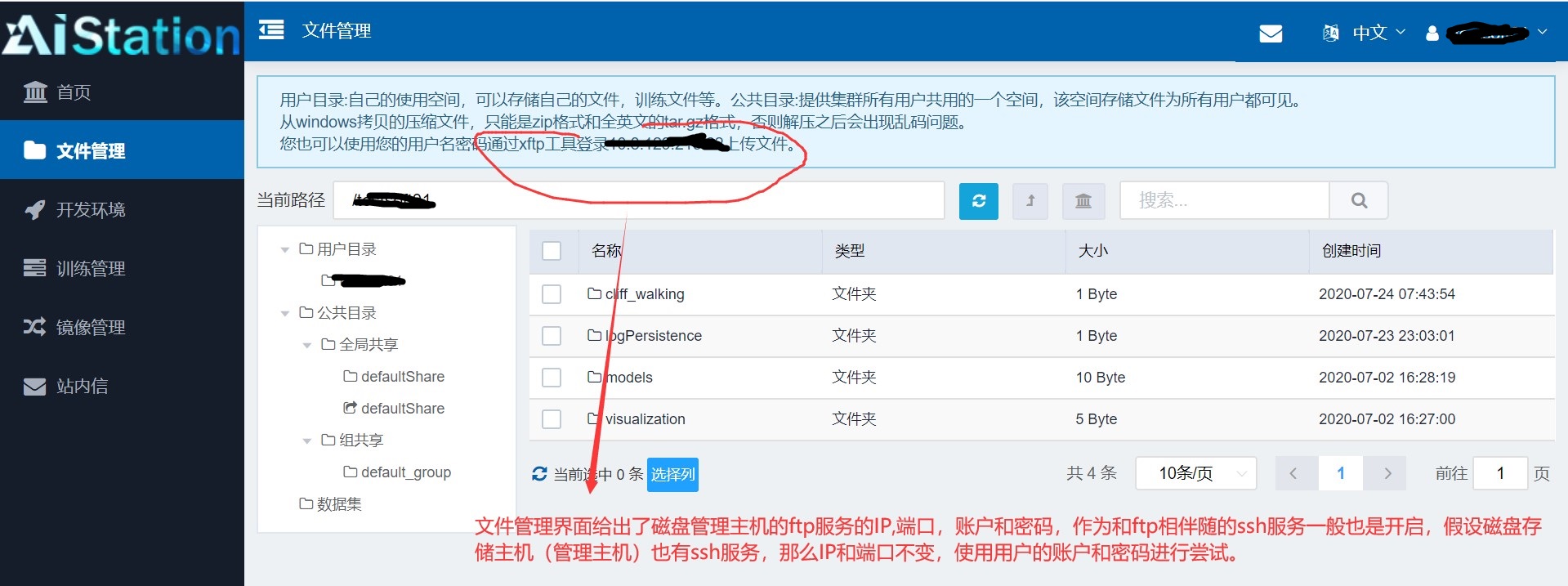
可以看到我们能够成功的登入到磁盘存储主机(管理主机)上,这时我们进入的是物理主机。

可以看到 我们的用户文件目录在物理机上实际为 /home/inspurfs/user-fs/xxxxxx, 同时应该也存在另一个账户为xxx 。虽然我们可以登录到管理主机的物理实体上,都是由于我们的账户权限太低并没有什么可以操作的权限,除了在自己的用户文件路径下增删改一些文件。
我们现在有两个容器在运行:

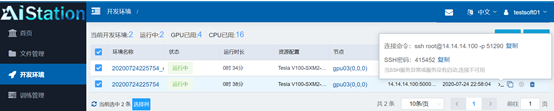
这两个容器的IP并不是校园网IP,而是私有IP, 那我们能否通过已经登入的管理主机跳转进容器系统内呢?
使用ifconfig命令查看网络配置,在众多网卡中发现有一个网卡配置IP为14.14.14.100,这说明容器所运行在的主机(计算节点)正是这台磁盘存储主机(也是管理主机)。

Ping一下:

发现此时网络包没有经过一跳路由的损失直接到达目的地,即64跳,说明容器其实运行在这个物理主机的同网段主机上,说明此时我们可以在这台主机上通过ssh跳转到正在这台主机运行的容器里面,并且本主机物理网卡IP正好是14.14.14.100,这说明容器的IP或者说入口就是这个物理主机上。发现可以成功登入到两个容器系统里面:


并且两个容器也是可以相互跳转到的:
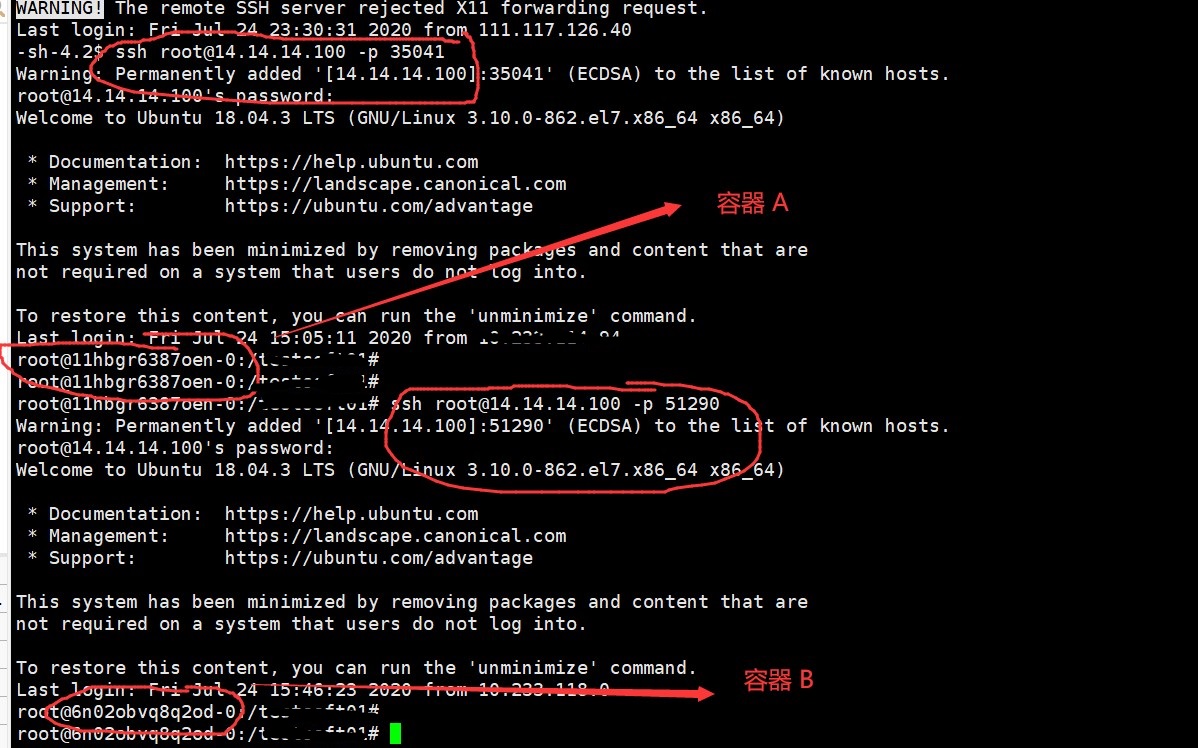
1.5 计算节点的物理配置:
登录物理主机:

可以发现物理主机上的内存总量为321G,现已用21G。

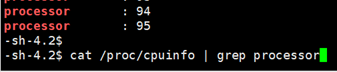
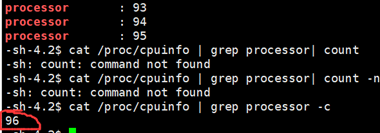
可以看到物理实体主机上CPU核心数为30个核心,这里应该是实体物理CPU数不为一的原因,查看CPU信息又显示有96个CPU:
查看主机的域名解析:

可以看到该实体主机IP为14.14.14.100,同时它还连接五个GPU主机分别为gpu01,02,03,04,05 ,IP为14.14.14.1, 14.14.14.2,14.14.14.3,14.14.14.4,14.14.14.5。
也就是说这里的AI_station其实是有五台实体电脑的,一个管理电脑负责内外的文件传输和数据存储功能,其它的五台GPU主机是提供GPU计算服务的。
通过网络ping和IP设置知道物理本主机和五个GPU主机是同网段互联的:

注:虽然登录docker的IP正好是提供存储服务和管理的主机,但是有可能docker是个集群,这台电脑只是负责调度和一部分计算服务的,docker是否是运行在这台主机上还不能下决定。
在docker内申请300G内存:

Docker监控:

14.14.14.100物理主机内存:

可以看到物理主机14.14.14.100上内存使用只有21GB,也就是说docker所申请的物理内存并不是在这个物理主机上,而是课程有集群在其他主机上申请的。
如果我们在这个物理主机上申请大量内存,此时该物理主机内存情况:

直接对物理主机进行内存申请测试:

个人主机(4.8G主频,i7-10700k CPU 单核心, 2666频率内存)运行时间:78.09秒。
14.14.14.100物理主机运行时间:393.39秒。
Docker容器内运行时间:94.59秒。
可以容易的看到不论管理节点(14.14.14.100,物理实体主机)还是docker系统在CPU和内存方面的效率都不是很高,慢的情况下是个人主机的50%性能,快的话也就是80%到90%多,但是这个计算平台的总资源很高,如果进行支持集群计算的话可以获得较高加速比,当然这需要你本身任务支持集群计算,还有你还得会做这样的code改写,平台总资源:

但是如果你的任务不支持集群计算或者你本身不会改写code和使用平台那么只使用平台上的单机CPU计算性能确实不及个人主机。当然这还和平台的CPU配置有关,这里的平台使用的是性价比较高的服务器CPU至强系列,Intel Xeon Platinum 8168拥有至强二十四核心48线程。

一般服务器平台会有两个CPU实体,那么一个实体CPU有24个物理核心按照超线程的方式会显示为48核心,两个物理CPU实体就是显示为96核心,正好符合:
2. 训练管理
注意事项:1.提交的代码中不要有中文字符,因为docker镜像中很可能没有设置UTF-8字符集。

2.提交的python代码中主文件不要有#!/usr/bin/python或#!/usr/bin/env python
这样的外部解释器路径的指定,因为镜像系统中很有可能没有这个路径,即时有也很可能你没有权限调用,于是就会报错。如下:

在设置训练管理时需要注意选择启动文件时最好重新手动指定一下,不然通过历史访问有可能选择的是缓存中的文件,如果这个路径文件被修改过就会报错无法预知的错误。
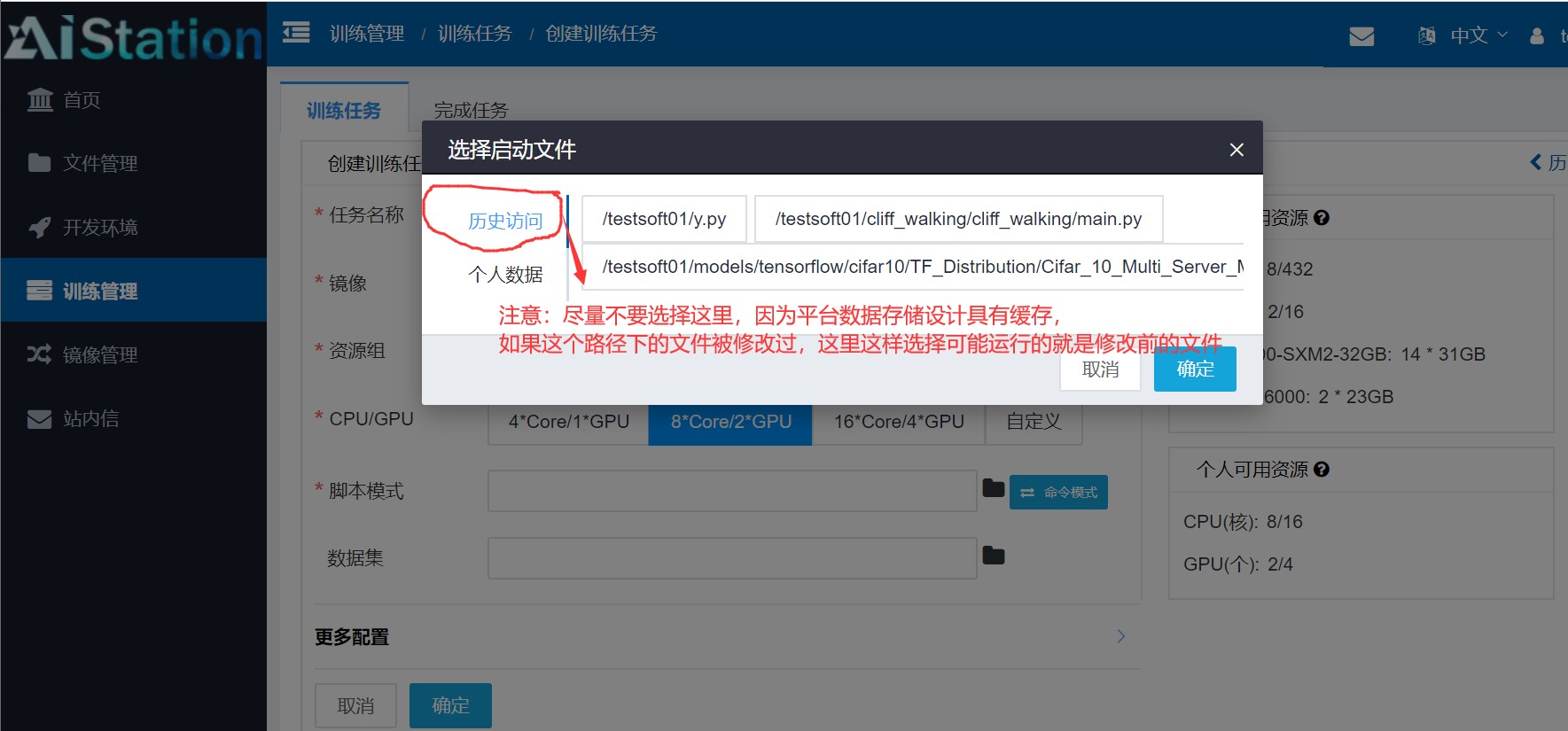
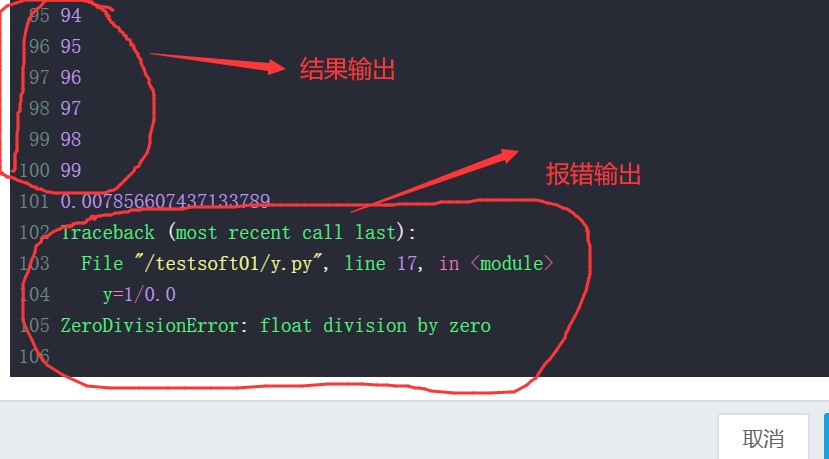
使用训练管理时相当于把计算任务托管给平台,这时如果是长时间运行的任务你不必一直守着web端,都是也有不好的地方,那就是你不像开发环境选项那样可以在容器里面进行设置,托管给系统的环境是默认的镜像,没有一点的改变,如果你的镜像中没有设置UTF-8,如果再开发环境中你可以手动的设置一下,但在这种托管的训练管理中是无法手动设置的。

保存的运行结果:

浪潮计算平台之AI方向——AI_Station开发环境的使用总结的更多相关文章
- Eclipse平台下配置Go语言开发环境(Win7)
<Go语言编程>中写到:“从功能和易用性等方面考虑, Eclipse+GoEclipse.LiteIDE这两个环境在所有IDE里面是表现最好的”,所以笔者打算采用Eclipse+GoEcl ...
- windows平台CodeBlocks MinGW C++11开发环境搭建
前言: 本文是以单独下载codeblock编辑器跟MinGW编译器这种方式进行安装,下载带MinGW编译器的codeblocks版本安装配置方式跟这个类似. 一: 下载并安装MinGW 这个参考我写的 ...
- Windows平台cocos2d-x 3.0 android开发环境
cocos2d-x升级到3.0后变化不小,除了API的变化(主要是函数和类名称变化,以及使用了C++11的不少特性.function/bind, lamda, std::thread-),创建和编译p ...
- 兔起鹘落全端涵盖,Go lang1.18入门精炼教程,由白丁入鸿儒,全平台(Sublime 4)Go lang开发环境搭建EP00
Go lang,为并发而生的静态语言,源于C语言又不拘泥于性能,高效却不流于古板,Python灵活,略输性能,Java严谨,稍逊风骚.君不见各大厂牌均纷纷使用Go lang对自己的高并发业务进行重构, ...
- Python科学计算(二)windows下开发环境搭建(当用pip安装出现Unable to find vcvarsall.bat)
用于科学计算Python语言真的是amazing! 方法一:直接安装集成好的软件 刚开始使用numpy.scipy这些模块的时候,图个方便直接使用了一个叫做Enthought的软件.Enthought ...
- Andriod学习笔记3:Mac 平台下搭建 CLion 集成开发环境
1. 安装Xcode 通过App store或者下载安装Xcode. 安装完成之后,最好启动一下Xcode,否则可能会报"Error:The C compiler "/usr/bi ...
- 配置linux平台下基于vim的开发环境
一.vim的基本配置 1.配置文件的位置在目录 /etc/ 下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,对所有用户都有效.而在每个用户的主目录($HOME)下,都可以自己建立私有的 ...
- 在Windows平台搭建轻巧的Python开发环境——面向工程和科研的扩展包配置
首先,下载最新版本的Python. 为什么强调最新版本呢,因为新版本的漏洞通常会少得多,而且反映了未来的趋势. 既然要学,何不起点高一点? 官方下载地址:https://www.python.org/ ...
- cocos2d-x 2.1.4学习笔记01:windows平台搭建cocos2d-x开发环境
cocos2d-x的大致开发流程是,首先使用win32版进行代码编写并完成游戏,然后将代码迁移到对应的开发环境上进行交叉编译完成游戏打包,如iphone上是mac+xcode,android是ecli ...
- 「C语言」在Windows平台搭建C语言开发环境的多种方式
新接触C语言,如何在Windows下进行C语言开发环境的搭建值得思考并整理. 以下多种开发方式择一即可(DEV C++无须环境准备). 注:本文知识来源于 Windows 平台搭建C语言集成开发环境 ...
随机推荐
- kettle从入门到精通 第六十七课 ETL之kettle 再谈kettle阻塞,阻塞多个分支的多个步骤
场景:ETL沟通交流群内有小伙伴反馈,如何多个分支处理完毕之后记录下同步结果呢?或者是调用后续步骤.存储过程.三方接口等. 解决:使用步骤Blocking step进行阻塞处理即可. 1. 如下流程图 ...
- vits-simple-api搭建
根据vits-simple-api中文文档指南自行搭建后端 以下步骤均在windows平台cpu推理搭建为例 选择你的vits模型(注意是vits!不是So-Vits Bert Vits2 Gpt V ...
- python allure将生成报告和打开报告写到命令文件,并默认使用谷歌打开
背景: 使用python + pytest +allure,执行测试用例,并生成测试报告: allure报告要从收集的xml.json等文件,生成报告,不能直接点击报告的index.html,打开的报 ...
- 用pm2命令管理你的node项目
文章目录 前言 安装 运行项目 pm2的命令 前言 我在服务器上运行node项目,使用命令nohup npm start &,结果关闭终端之后,进程就会停止,看来nohup也不是万能的后台运行 ...
- 【vue】利用输入框搜索过滤来选择列表
方法1 <div id="app"> <input type="text" @input="handleInput()" ...
- 构建3D虚拟世界,有哪些3D建模方式?
"沉浸.3D世界.虚拟社交.虚拟购物",人们畅想通过AR/VR以及其他互联网技术,把现实世界的楼房街道.天气温度.人际关系等投射到虚拟世界,拥有一个网络分身. 但目前来看,要想实现 ...
- QT学习:08 QString
--- title: framework-cpp-qt-08-QString EntryName: framework-cpp-qt-08-QString date: 2020-04-16 15:36 ...
- windows服务开发demo
0.写在前面 windows7开始,windows服务运行在session 0, 用户程序都运行在session x (x >= 1) 而session之间是有隔离的,实践发现是无法在服务中直接 ...
- SQL Server大量插入 Java
在Java中向数据库执行大量插入操作,通常需要考虑性能和效率.对于大量数据的插入,有几种方法可以提高性能,比如使用批处理(Batch Insert).JDBC的批处理API.或者使用SQL Serve ...
- 1.1 第一个hello程序
还记得在每一个编程平台上的第一个程序都是hello world,现在就以这个程序为载体,先浅聊一下计算机系统吧. 1.预处理阶段,预处理器cpp根据字符#开头的命令修改原始的程序,并把头文件里的内容直 ...