爬取知乎热榜标题和连接 (python,requests,xpath)
用python爬取知乎的热榜,获取标题和链接。
环境和方法:ubantu16.04、python3、requests、xpath
1.用浏览器打开知乎,并登录
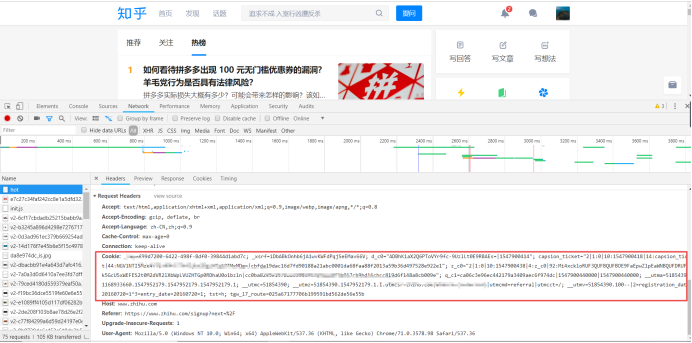
2.获取cookie和User—Agent
3.上代码
import requests
from lxml import etree def get_html(url):
headers={
'Cookie':'你的Cookie',
#'Host':'www.zhihu.com',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
} r=requests.get(url,headers=headers) if r.status_code==200:
deal_content(r.text) def deal_content(r):
html = etree.HTML(r)
title_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/h2')
link_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/@href')
for i in range(0,len(title_list)):
print(title_list[i].text)
print(link_list[i])
with open("zhihu.txt",'a') as f:
f.write(title_list[i].text+'\n')
f.write('\t链接为:'+link_list[i]+'\n')
f.write('*'*50+'\n') def main():
url='https://www.zhihu.com/hot'
get_html(url) main()
4.爬取结果

爬取知乎热榜标题和连接 (python,requests,xpath)的更多相关文章
- python抓取知乎热榜
知乎热榜讨论话题,https://www.zhihu.com/hot,本文用python抓取下来分析 #!/usr/bin/python # -*- coding: UTF-8 -*- from ur ...
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # 爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # URL https://www.zhihu.co ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
随机推荐
- Exchange2016 & Skype for business集成之二 OWA集成IM
Microsoft Outlook Web App 和IM集成部署或升级Exchange server 2016与Skype for business 2015后使用原来2013版本方法集成OWA网页 ...
- SharePoint问题杂集——要创建计时器作业,必须运行SVC
问题场景:在SharePoint2010服务器上使用PowerShell部署解决方案时,遇到问题: 解决办法是进入控制面板----管理工具----服务,找到SharePoint 2010 Admini ...
- December 14th 2016 Week 51st Wednesday
Everything has its time and that time must be watched. 万物皆有时,时来不可失. Everything has its time, and I r ...
- Python2.7 - IMOOC - 2
第三章 Python变量和数据类型 3-1.数据类型 在Python中,能够直接处理的数据类型有以下几种: 整数 Python可以处理任意大小的整数,当然包括负整数,表示方法和数学上的写法一模一样,十 ...
- java构造方法-this关键字的用法
public class constructor { public static void main(String[] args) { // TODO Auto-generated method st ...
- ZooKeeper学习之路 (六)ZooKeeper API的简单使用(二)级联删除与创建
编程思维训练 1.级联查看某节点下所有节点及节点值 2.删除一个节点,不管有有没有任何子节点 3.级联创建任意节点 4.清空子节点 ZKTest.java public class ZKTest { ...
- flutter 配置环境
1. 下载java SDK https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html c ...
- [转载] MySQL 注入攻击与防御
MySQL 注入攻击与防御 2017-04-21 16:19:3454921次阅读0 作者:rootclay 预估稿费:500RMB 投稿方式:发送邮件至linwei#360.cn,或登陆网页 ...
- C#回调实现的一般过程
C#回调实现的一般过程 C#的方法回调机制,是建立在委托基础之上的,下面给出它的典型实现过程. (一) 定义.声明回调 Delegate void DoSomeCallBack(type para); ...
- Linux开启路由的方法
Linux开启路由的命令很简单,只需要一条命令即可: [root@localhost ~]# echo 1 > /proc/sys/net/ipv4/ip_forward 这个只是临时修改,如果 ...