(数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一、简介
接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文章中我们只介绍了如何利用urllib、requests这样的请求库来将我们的程序模拟成一个请求网络服务的一端,来直接取得设置好的url地址中朴素的网页内容,再利用BeautifulSoup或pyspider这样的解析库来对获取的网页内容进行解析,在初级篇中我们也只了解到如何爬取静态网页,那是网络爬虫中最简单的部分,事实上,现在但凡有价值的网站都或多或少存在着自己的一套反爬机制,例如利用JS脚本来控制网页中部分内容的请求和显示,使得最原始的直接修改静态目标页面url地址来更改页面的方式失效,这一部分,我在(数据科学学习手札47)基于Python的网络数据采集实战(2)中爬取马蜂窝景点页面下蜂蜂点评区域用户评论内容的时候,也详细介绍过,但之前我在所有爬虫相关的文章中介绍的内容,都离不开这样的一个过程:
整理url规则(静态页面直接访问,JS控制的动态页面通过浏览器的开发者工具来找到真实网址和参数)
|
伪装浏览器
|
利用urllib.urlopen()或requests.get()对目标url发起访问
|
获得返回的网页原始内容
|
利用BeautifulSoup或PySpider对网页原始内容进行解析
|
结合观察到的CSS标签属性等信息,利用BeautifulSoup对象的findAll()方法提取需要的内容,利用正则表达式来完成精确提取
|
存入数据库
而本文将要介绍的一种新的网络数据采集工具就不再是伪装成浏览器端,而是基于自动化测试工具selenium来结合对应浏览器的驱动程序,开辟真实的、显性的浏览器窗口,来完成一系列动作,以应对更加动态灵活的网页;
二、selenium
2.1 介绍
selenium也是一个用于Web应用程序测试的工具。selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite、Chrome等。这个工具的主要功能是测试与浏览器的兼容性,但由于其能够真实模拟浏览器,模拟网页点击、下拉、拖拽元素等行为的功能,使得其在网络数据采集上开辟出一片天地;
2.2 环境搭建
要想基于Python(这里我们说的是Python3,Python2,就让它在历史的长河里隐退吧。。。)来使用selenium创建爬虫程序,我们需要:
1.安装selenium包,直接pip安装即可
2.下载浏览器(废话-_-!),以及对应的驱动程序,本文选择使用的浏览器为Chrome,需要下载chromedriver.exe,这里提供一个收录所有版本chromedriver.exe资源的地址:
http://npm.taobao.org/mirrors/chromedriver/
需要注意的是,要下载与你的浏览器版本兼容的资源,这里给一个建议:将你的Chrome浏览器更新到最新版本,再到上述地址中下载发布时间最新的chromedriver.exe;在下载完毕后,将chromedriver.exe放到你的Python根目录下,和python.exe放在一起,譬如我就将其放在我的anaconda环境下的对应位置:
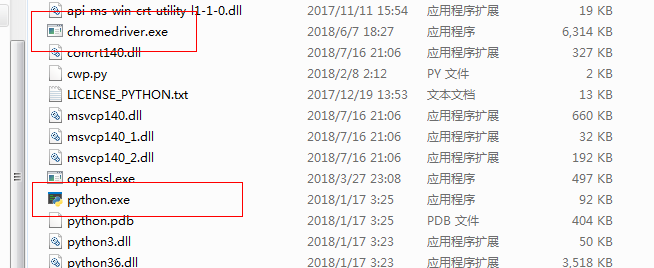
3.测试一下~
在完成上述操作之后,我们要检验一下我们的环境有没有正确搭建完成,在你的Python编辑器中,写下如下语句:
from selenium import webdriver '''创建一个新的Chrome浏览器窗体'''
browser = webdriver.Chrome() '''在browser对应的浏览器中访问百度首页'''
browser.get('http://www.baidu.com')
如果在执行上述语句之后,顺利地打开了Chrome浏览器并访问到我们设置的网页,则selenium+Chrome的开发环境配置完成;
2.3 利用selenium进行网络数据采集的基本流程
在本文的一开始我们总结了之前进行网络数据采集的基本流程,下面我们以类似的形式介绍一下selenium进行网络数据采集的基本流程:
创建浏览器(可能涉及对浏览器一些设置的预配置,如不需要采集图片时设置禁止加载图片以提升访问速度)
|
利用.get()方法直接打开指定url地址
|
利用.page_source()方法获取当前主窗口(浏览器中可能同时打开多个网页窗口,这时需要利用页面句柄来指定我们关注的主窗口网页)页面对应的网页内容
|
利用BeautifulSoup或pyspider等解析库对指定的网页内容进行解析
|
结合观察到的CSS标签属性等信息,利用BeautifulSoup对象的findAll()方法提取需要的内容,利用正则表达式来完成精确提取
|
存入数据库
可以看出,利用selenium来进行网络数据采集与之前的方法最大的不同点在于对目标网页发起请求的过程,在使用selenium时,我们无需再伪装浏览器,且有了非常丰富的浏览器动作可以设置,譬如说之前我们需要对页面进行翻页操作,主要是通过修改url中对应控制页面值的参数来完成,所以在遇到JS控制的动态网页时,可以不需要去费心寻找控制对应资源翻页的真实url地址,只需要在selenium中,通过其内置的丰富的定位方法对页面中的翻页按钮进行定位 ,再通过对定位到的元素运用.click(),即可实现真实的翻页操作,下面我们根据上述过程中列出的selenium部分,涉及到的常用方法进行介绍以及举例说明:
三、selenium常用操作
3.1 浏览器配置部分
在调出一个真实的浏览器对象之前,我们可以结合实际需要对浏览器的设置进行参数配置,这在selenium中是通过对应浏览器的XXXOptions类来设置的,例如本文只介绍Chrome浏览器,则我们通过ChromeOptions类中的方法来实现浏览器预配置,下面我们来了解一下ChromeOptions类:
ChromeOptions:
ChromeOptions是一个在selenium创建Chrome浏览器之前,对该浏览器对象进行预配置的类,其主要功能有添加Chrome启动参数、修改Chrome设置、添加扩展应用等,如:
1.禁止网页中图片加载
from selenium import webdriver '''创建一个新的Chrome浏览器窗体,通过add_experimental_option()方法来设置禁止图片加载'''
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=chrome_options) '''在browser对应的浏览器中,以禁止图片加载的方式访问百度首页'''
browser.get('http://www.baidu.com') '''查看当前浏览器中已设置的参数'''
chrome_options.experimental_options
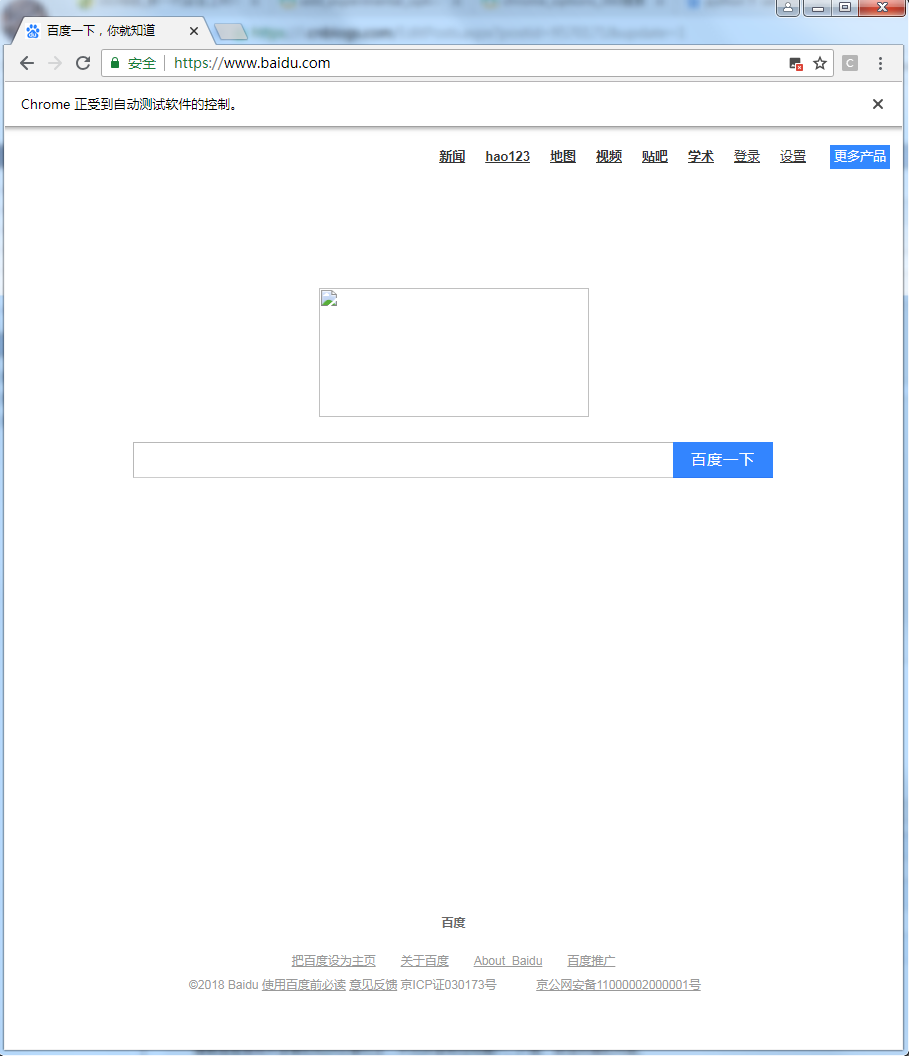

可以看出,在进行如上设置后,我们访问的网页中所有图片都没有加载,这在不需要采集图片资源的任务中,对于提升访问速度有着重要意义;
2.设置代理IP
有些时候,在面对一些对访问频率有所限制的网站时,一旦我们爬取频率过高,就会导致我们本机的IP地址遭受短暂的封禁,这时我们可以通过收集一些IP代理来建立我们的代理池,关于这一点我们会在之后单独开一篇博客来详细介绍,下面简单演示一下如何为我们的Chrome()浏览器对象设置IP代理:
from selenium import webdriver '''设置代理IP'''
IP = '106.75.9.39:8080' '''为Chrome浏览器配置chrome_options选项'''
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://{}'.format(IP)) '''将配置好的chrome_options选项传入新的Chrome浏览器对象中'''
browser = webdriver.Chrome(chrome_options=chrome_options)
'''尝试访问百度首页'''
browser.get('http://www.baidu.com')
但是如果你不是付费购买的高速IP代理,而是从网上所谓的免费IP代理网站扒下来的一些IP地址,那么上述设置之后打开的浏览器中不一定能在正常时间内显示目标网页(原因你懂的);
另一种思路:
除了使用ChromeOptions()中的方法来设置,还有一种简单直接粗暴的方法,我们可以直接访问对应当前浏览器设置页面的地址:chrome://settings/content:
from selenium import webdriver browser = webdriver.Chrome() '''直接访问设置页面'''
browser.get('chrome://settings/content')
接着再使用自己编写的模拟点击规则,即可完成对应的设置内容,这里便不再多说;
3.2 浏览器运行时的实用方法
经过了3.1中介绍的方式,对浏览器进行预配置,并成功打开对应的浏览器之后,selenium中还存在着非常丰富的浏览器方法,下面我们就其中实用且常用的一些方法和类内的变量进行介绍:
假设我们构造了一个叫做browser的浏览器对象,可以使用的方法如下:
browser.get(url):在浏览器主窗口中打开url指定的网页;
browser.title:获得当前浏览器中主页面的网页标题:
from selenium import webdriver browser = webdriver.Chrome() '''直接访问设置页面'''
browser.get('https://hao.360.cn/?wd_xp1') '''打印网页标题'''
print(browser.title)

browser.current_url:返回当前主页面url地址
browser.page_source:获取当前主界面的页面内容,相当于requests.get(url).content
browser.close():关闭当前主页面对应的网页
browser.quit():直接关闭当前浏览器
browser.maximize_window():将浏览器窗口大小最大化
browser.fullscreen_window():将浏览器窗口全屏化
browser.back():控制当前主页面进行后退操作(前提是它有上一页面)
browser.forward():控制当前主页面进行前进操作(前提是它有下一页面)
browser.refresh():控制当前主页面进行刷新操作
browser.set_page_load_timeout(time_to_wait):为当前浏览器设置一个最大页面加载耗时容忍阈值,单位秒,类似urllib.urlopen()中的timeout参数,即当加载某个界面时,持续time_to_wait秒还未加载完成时,程序会报错,我们可以利用错误处理机制捕捉这个错误,此方法适用于长时间采样中某个界面访问超时假死的情况
browser.set_window_size(width, height, windowHandle='current'):用于调节浏览器界面长宽大小
关于主页面:
这里要额外介绍一下,我们在前面一大段中提到过很多次主页面这个概念,是因为在selenium控制浏览器时,无论浏览器中开了多少个网页,都只将唯一一个网页视为主页面,相应的很多webdriver()方法也都是以该主页面为对象,下面是一个示例,我们以马蜂窝地方游记页面为例:
from selenium import webdriver browser = webdriver.Chrome() '''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
打开目标页面如下:

这里我们手动点开一篇游记(模拟点击的方法下文会介绍),浏览器随即跳转到一个新的页面:
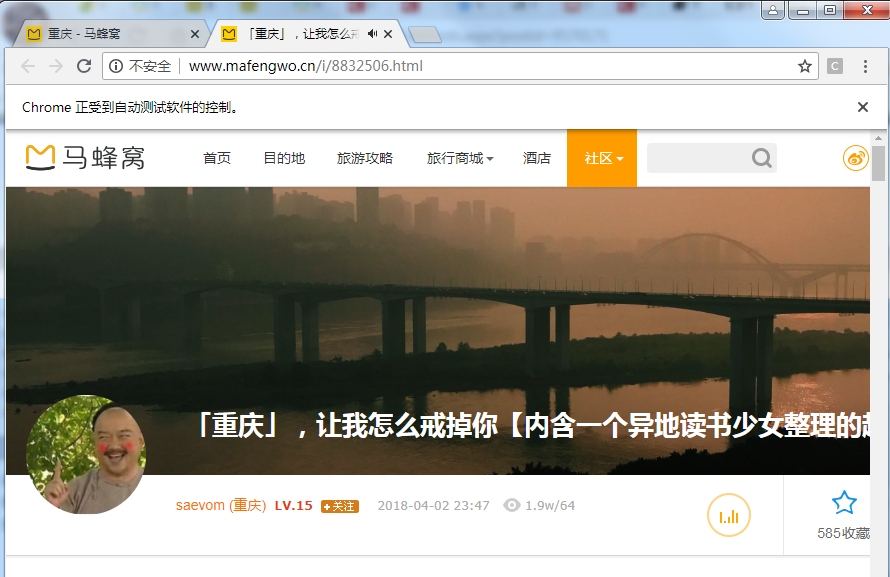
这时我们运行下列代码:
'''打印网页标题'''
print(browser.title)

可以看到,虽然在我们的视角里,通过点击,进入到一个新的界面,但当我们利用对应方法获取当前页面标题时,仍然是以之前的页面作为对象,这就涉及到我们之前提到的主页面的问题,当在原始页面中,因为点击事件而跳转到另一个页面(这里指的是新开一个窗口显示新界面,而不是在原来的窗口覆盖掉原页面),浏览器中的主页面依旧是锁定在原始页面中,即get()方法跳转到的网页,这种情况我们就需要用到网页的句柄来唯一标识每一个网页;
在selenium中,关于获取网页句柄,有以下两个方法:
browser.current_window_handle:获取主页面的句柄,以上面马蜂窝的为例:
'''打印主页面句柄'''
print(browser.current_window_handle)

browser.window_handles:获取当前浏览器中所有页面的句柄,按照打开的时间顺序:
'''打印当前浏览器下所有页面的句柄'''
print(browser.window_handles)

既然句柄相当于网页的身份证,那么我们可以基于句柄切换当前的主网页到其他网页之上,延续上面的例子,此时的主网页是.get()方法打开的网页,之前打印browser.title也是指向的该网页,现在我们利用browser.switch_to.window(handle)方法,将主网页转到最近打开的网页中,并打印当前主网页的标题:
'''切换主网页至最近打开的网页'''
browser.switch_to.window(browser.window_handles[-1]) '''打印当前主网页的网页标题'''
print(browser.title)

可以看到,使用主网页切换方法后,我们的主网页转到指定的网页中,这在对特殊的网页跳转方式下新开的网页内容的采集很受用;
3.3 页面元素定位
在介绍selenium的精髓——模拟浏览器行为之前,我们需要知道如何对网页内的元素进行定位,譬如说我们要想定位到网页中的翻页按钮,就需要对翻页按钮所在的位置进行定位,这里的定位不是指在屏幕的平面坐标上进行定位,而是基于网页自身的CSS结构,其实selenium中对网页元素进行定位的方式非常多,但是通过我大量的实践,其中很多方法效果并不尽如人意,唯有其中基于xpath的定位方法十分方便,定位非常准确方便,因此本文不会浪费你的时间介绍其他效果不太好的方法,直接介绍基于xpath的定位方法,我们先了解一下什么是xpath:
关于xpath:
xpath是一门在xml文档中查找信息的语言,只是为了在selenium中定位网页元素的话,我们只需要掌握xpath路径表达式即可;
xpath使用路径表达式来识别xml文档中的节点或节点集,我们先从一个示例出发来对xpath路径表达式有一个认识:
还是以马蜂窝游记页面为例:
from selenium import webdriver browser = webdriver.Chrome() '''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
通过浏览器的开发者工具,我们找到“下一页”按钮元素在CSS结构中所在的位置:
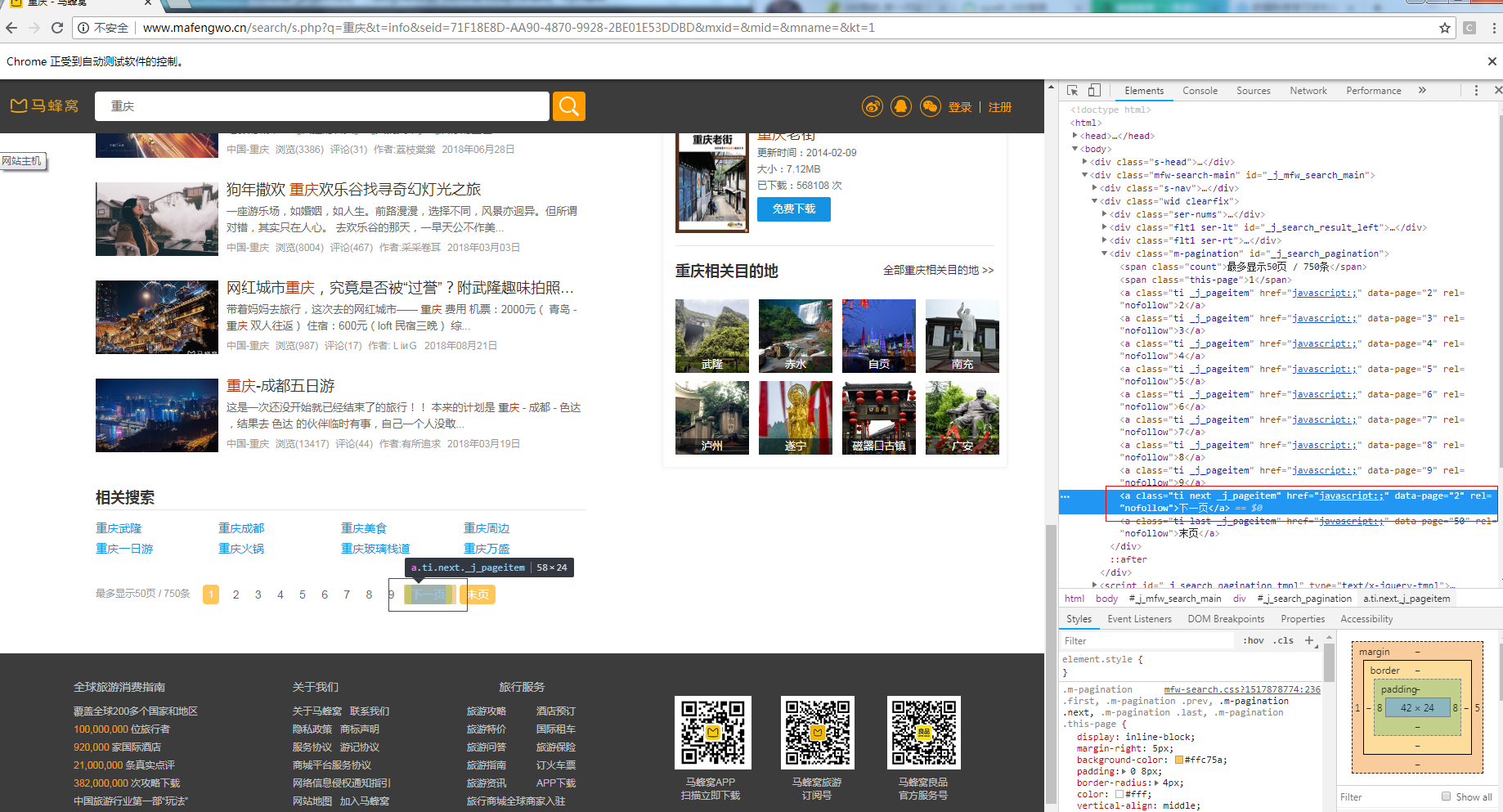
先把该元素完整的xpath路径表达式写出来:
//div/div/a[@class='ti next _j_pageitem']
接着我们使用基于xpath的定位方法,定位按钮的位置并模拟点击:
'''定位翻页按钮的位置并保存在新变量中'''
ChagePageElement = browser.find_element_by_xpath("//div/div/a[@class='ti next _j_pageitem']") '''对按钮位置变量使用click方法进行模拟点击'''
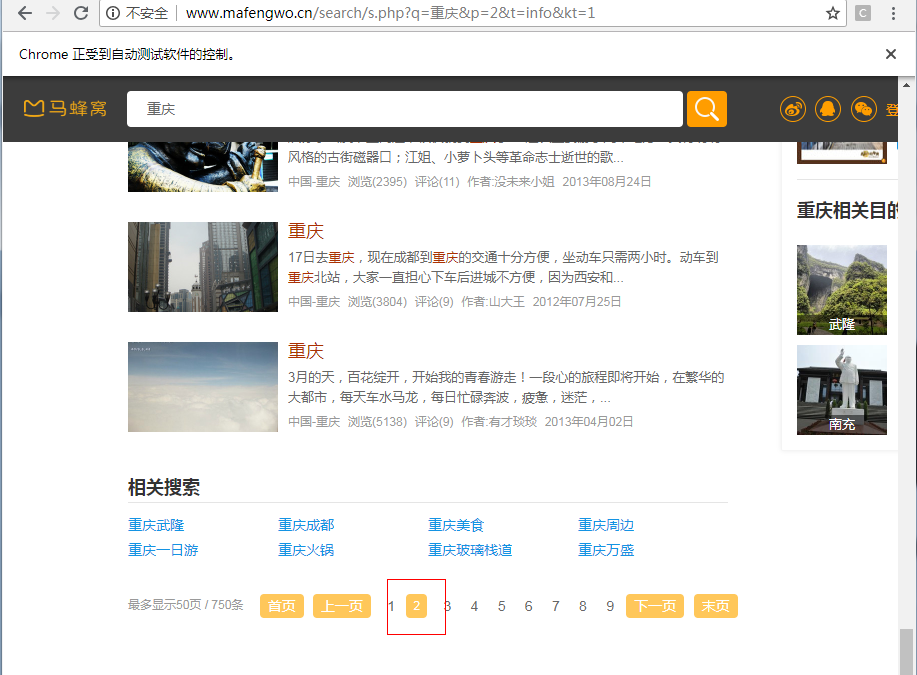
ChagePageElement.click()
上述代码运行之后,我们的浏览器执行了对翻页按钮的模拟点击,实现了翻页:
现在我们来介绍一下xpath路径表达式中的一些基本知识:
nodename:标明一个结点的标签名称
/:父节点与子节点之间的分隔符
//:代表父节点与下属某个节点之间若干个中间节点
[]:指定最末端结点的属性
@:在[]中指定属性名称和对应的属性值
在xpath路径表达式中还有很多其他内容,但在selenium中进行基本的元素定位了解到上面这些规则就可以了,所以我们上面的例子中的规则,表示的就是定位
若干节点-<div>
... ...
<div>
... ...
<a class='ti next _j_pageitem'></a>
... ...
<div>
... ...
</div>
利用这样的方式,基于browser.find_element_by_xpath()和browser.find_elements_by_xpath(),我们就可以找到页面中单个独特元素或多个同类型元素,再使用.click()方法即可完成对页面内任意元素的模拟点击;
3.4 基础的浏览器动作模拟
除了上面一小节介绍的使用元素.click()控制点击动作以外,selenium还支持丰富多样的其他常见动作,因为本文是我介绍selenium的上篇,下面只介绍两个常用的动作,更复杂的组合动作放在之后的文章中介绍:
模拟网页下滑:
很多时候我们会遇到这样的动态加载的网页,如光点壁纸的各个壁纸板块,这里以风景板块为例http://pic.adesk.com/cate/landscape:

这个网页的特点是,大多数情况下没有翻页按钮,而是需要用户将页面滑到底部之后,才会自动加载下一页的内容,并且这种机制持续固定几次后,会参杂一个必须点击才可以进行翻页操作的按钮,我们可以在selenium中使用browser.execute_script()方法来传入JavaScript脚本来执行浏览器动作,进而实现下滑功能;
对应下滑到底的JavaScript脚本为'window.scrollTo(0, document.body.scrollHeight)',我们用下面这段代码来实现持续下滑,并及时捕捉翻页按钮进行点击(利用错误处理机制来实现):
from selenium import webdriver
import time browser = webdriver.Chrome() '''访问光点壁纸风景板块页面'''
browser.get('http://pic.adesk.com/cate/landscape') '''这里尝试的时候不要循环太多次,快速加载图片比较吃网速和内存'''
for i in range(1, 20):
'''这里使用一个错误处理机制,
如果有定位到加载下一页按钮就进行
点击下一页动作,否则继续每隔1秒,下滑到底'''
try:
'''定位加载下一页按钮'''
LoadMoreElement = browser.find_element_by_xpath("//div/div[@class='loadmore']")
LoadMoreElement.click() except Exception as e:
'''浏览器执行下滑动作'''
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
模拟输入:
有些时候,我们需要对界面中出现的输入框,即标签为<input></input>代表的对象进行模拟输入操作,这时候我们只需要对输入框对应的网页对象进行定位,然后使用browser.send_keys(输入内容)来往输入框中添加文本信息即可,下面是一个简单的例子,我们从百度首页出发,模拟了点击登陆-点击注册-在用户名输入框中输入指定的文本内容,这样一个简单的过程:
from selenium import webdriver browser = webdriver.Chrome() '''访问百度首页'''
browser.get('http://www.baidu.com') '''对页面右上角的登陆超链接进行定位,这里因为同名超链接有两个,
所以使用find_elements_by_xpath来捕获一个元素列表,再对其中
我们指定的对象执行点击操作'''
LoginElement = browser.find_elements_by_xpath("//a[@name='tj_login']")
'''对指定元素进行点击操作'''
LoginElement[1].click() '''这段while语句是为了防止信息块没加载完成导致出错'''
while True:
try:
'''捕获弹出的信息块中的注册按钮元素'''
SignUpElement = browser.find_elements_by_xpath("//a[@class='pass-reglink pass-link']")
'''点击弹出的信息块中的注册超链接'''
SignUpElement[0].click()
break
except Exception as e:
pass '''将主网页切换至新弹出的注册页面中以便对其页面内元素进行定位'''
browser.switch_to.window(browser.window_handles[-1]) while True:
try:
'''对用户名称输入框对应元素进行定位'''
InputElement = browser.find_element_by_xpath("//input[@name='userName']")
'''模拟输入指定的文本信息'''
InputElement.send_keys('Keras')
break
except Exception as e:
pass
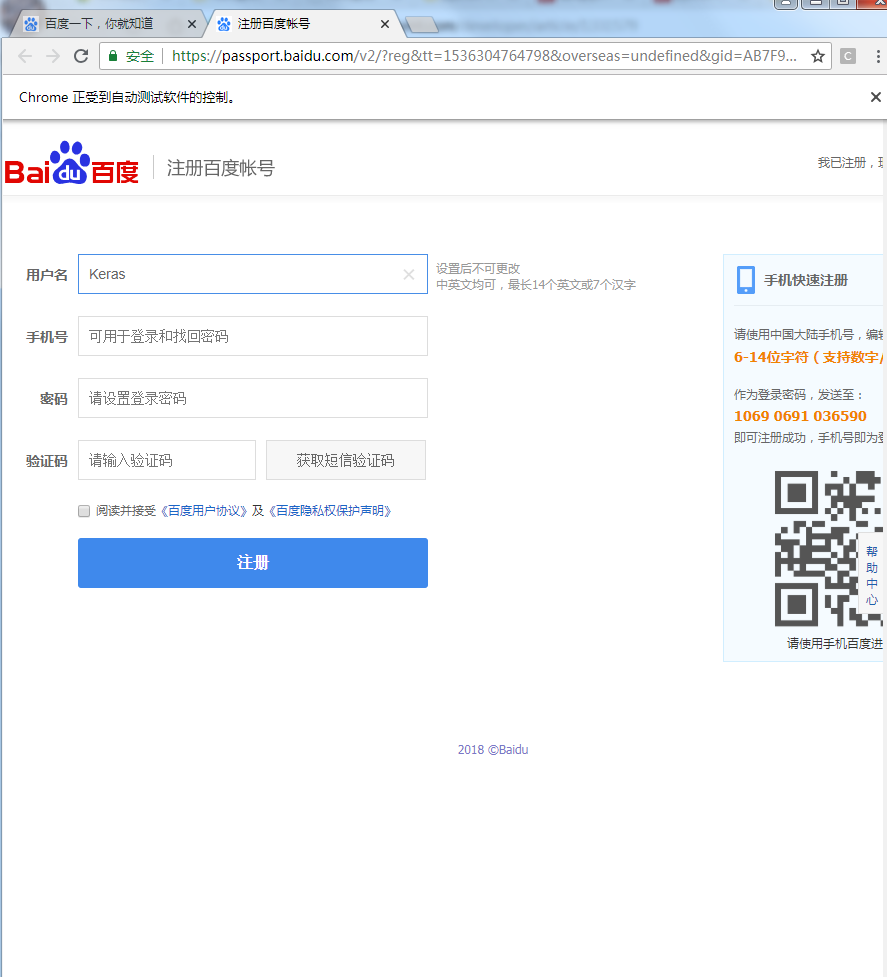
以上就是关于selenium进行网络数据采集的上篇内容,其余的内容我会挤出时间继续整理介绍,敬请关注,如有笔误,望指出。
(数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)的更多相关文章
- (数据科学学习手札114)Python+Dash快速web应用开发——上传下载篇
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札04)Python与R在自定义函数上的异同
自编函数是几乎每一种编程语言的基础功能,有些时候我们需要解决的问题可能没有完全一致的包中的函数来进行解决,这个时候自编函数就成了一样利器,而Python与R在这方面也有着一定的差别,下面举例说明: P ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札85)Python+Kepler.gl轻松制作酷炫路径动画
本文示例代码.数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl相信很多人都听说过,作为 ...
- (数据科学学习手札110)Python+Dash快速web应用开发——静态部件篇(下)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札136)Python中基于joblib实现极简并行计算加速
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在日常使用Python进行各种数据计算 ...
- (数据科学学习手札108)Python+Dash快速web应用开发——静态部件篇(上)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札118)Python+Dash快速web应用开发——特殊部件篇
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
随机推荐
- Python学习---Python数据类型1206
1.1. 字符串格式化 字符格式化输出 占位符 %s s = string %d d = digit 整数 %f f = float 浮点数,约等于小数 #version: python3.2 ...
- ZT --- extern "C"用法详解 2010-08-21 19:14:12
extern "C"用法详解 2010-08-21 19:14:12 分类: C/C++ 1.前言: 时常在cpp的代码之中看到这样的代码: #ifdef __cplusplus ...
- [DBSDFZOJ 多校联训] 就
就 背景描述 一排 N 个数, 第 i 个数是 Ai , 你要找出 K 个不相邻的数, 使得他们的和最大. 请求出这个最大和. 输入格式 第一行两个整数 N 和 K. 接下来一行 N 个整数, 第 i ...
- 四种Timer的区别和用法
1.System.Threading.Timer 线程计时器 1.最底层.轻量级的计时器.基于线程池实现的,工作在辅助线程. 2.它并不是内在线程安全的,并且使用起来比其他计时器更麻烦.此计时器通常不 ...
- Java 运算符(引用和对象)
1. 算数运算符 就是+.-.*./.%.++.--这些,没什么好说的,稍微强调下自加,自减: 前缀自增自减法(++i,--i): 先进行自增或者自减运算,再进行表达式运算. 后缀自增自减法(i++, ...
- 翻译-QPKG开发工具快速开始指南
QPKG开发工具快速开始指南 指导你编译你自己的QPKG软件包 目录 什么是QDK 下载QDK 安装QDK 编译你自己的QPKG软件包 搭建QPKG编译环境 配置QPKG 定制QPKG程序 向QPKG ...
- Linux系统下常用的磁盘管理命令——du / df / fdisk / mount / xxd
之前使用虚拟机体验Linux操作系统的使用,一般使用默认的磁盘分区设置,也很少涉及磁盘管理操作,且总有删除重装作为后盾.在安装Ubuntu双系统后,在使用过程中遇到了磁盘分区不合理导致的/boot分区 ...
- tomcat多实例.md
多tomcat实例 环境说明 操作系统:CentOS 6.6 JDK: # ll /usr/local/java lrwxrwxrwx 1 root root 22 Feb 27 17:43 /usr ...
- mean函数一个神代码
cs231n上的一个代码,能求出准确率: print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) ) >>> a = np.arra ...
- Golang 单元测试和性能测试
开发程序其中很重要的一点是测试,我们如何保证代码的质量,如何保证每个函数是可运行,运行结果是正确的,又如何保证写出来的代码性能是好的,我们知道单元测试的重点在于发现程序设计或实现的逻辑错误,使问题及早 ...