第二次作业——个人项目实战(sudoku)
# 第二次作业——个人项目实战(sudoku)
一、作业要求地址
二、Github项目地址
三、PSP表格估计耗时
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 1080 | 1150 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 340 |
| · Design Spec | · 生成设计文档 | --- | --- |
| · Design Review | · 设计复审 (和同事审核设计文档) | --- | --- |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 120 | 60 |
| · Design | · 具体设计 | 240 | 300 |
| · Coding | · 具体编码 | 180 | 230 |
| · Code Review | · 代码复审 | 120 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 210 | 230 |
| · Test Report | · 测试报告 | 120 | 150 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1350 | 1420 |
解题思路
刚开始拿到题目的感觉,大概就是懵吧。一开始我连数独是什么都不知道,认真看了一下题目,再结合百度,我发现数独就是我小时玩的一个填写数字的手机游戏,想到这我一下子来了兴趣,突然有机会可以重温这个游戏了。那么要怎么实现数独呢?我还是还是不知道,只知道要满足 每一行、每一列、每一个粗线宫(3*3)内的数字均含1-9,不重复,这个条件。
于是我开始思考要怎样才能使得生成的9×9盘面上的数字满足这个条件呢,首先我是想按顺序将数字一个一个填入来判断。而数字的选择采用随机生成的办法,如果这个数字与之前填入的数字发生冲突,我们就随机生成另外一个数字来填写,直到找到能够填入这个位置的数字。
但是,很快我发现,这个方法有很严重的问题。我们在前面找到了满足条件的数字,然后填写进去,但是不能保证这样的填写方法是合理的。比方说一共81个格子,现在我们填写了60个,可是发现第61个格子1到9的数字试过去都不满足条件,这该如何是好啊?
突然我想起了当时我玩游戏的经历。我记得当时我玩这个手机数独游戏的时候,经常发现有哪个格子填不了数字了,就看看之前自己填写的数字,是不是有符合条件的其他数字,然后把它改成另外符合条件的数字。想到这我就豁然开朗了,当我们碰到数字填不下去的时候,可以回头更改前面的数字。
但是在代码的实现上基础薄弱的我就头疼了,于是我就开始上网查找资料。很快我发现网络上解决数独问题的方法比较多的有两种,一种是搜索法,还有一种是回溯法。因为时间紧迫我看了看搜索法的实现方法,发现没有理解,但让我惊喜的是,回溯发的思想与我的想法不谋而合。于是我决定用回溯法来解决这次的问题。
接下来我就开始了漫长的理解回溯法的旅程,我看了网上几篇比较具有代表性的博客,在纸上涂涂画画,总算大致理解了回溯法。接下来就是码代码的过程了!
写代码的过程对我来说非常的困难,也耗费了很多时间,期间我碰到了几个问题,并想办法解决,在下面的设计实践过程级代码说明中都将提及。
设计'实现'过程
在代码的组织上,我是打算用4个函数来解决,分别是pro_sudoku,judge,init,以及use_n。
这四个函数的用途分别是:
pro_sudoku:产生数独,我将数独的输出也包含在这个函数里了。
judge: 判断每次读入的数字是否符合要求
init:初始化数独。由于我发现其他班级的作业对输出数独的首数字有要求,所以我也抱着试试看的心态尝试了一下。按照要求我的输出数独的第一个数字应该是2,于是我将数独的第一行第一个数字填写上2后,第二到第八个数字随机填写上1,3,4,5,6,7,8,9,这8个数字。具体的随机填写的方法是问同学的知道的,用了srand函数,随机洒下种子,再用random_shuffle来对第二到第八位的数字进行随机抖动这样我们的数独就初始化完毕啦
use_n:将我们输入的N传输到类中,同时调用init和pro_sudoku函数。
函数的关系:
函数间的关系很简单,就是main函数读入并判断输入是否正确,随即调用sudo类中的use_n函数,并控制将结果输出到文件。在use_n函数里,我们成功传入合法的N,并调用init和pro_sudoku函数。init函数主要用于初始化数独为pro_sudoku函数做准备,而judge就是在我们产生数独的过程中一次次地判断填入的数字是否符合要求。这几个函数互相配合,完成了整个程序。
我只分了一个类,将这四个函数都放在了sudo类里,主函数进行对输入输出的处理。但写完后我发现这样的处理方式看起来很不合理,因为时间关系我就先提交了原有的代码,还未做出修改。
在这里简述一下我觉得比较好的分类方式:将函数的输入及输出部分分别放在一个Scan和Print类中(类似大一时做的计算器的要求),然后将产生数独的部分放在一个Sudo类中,这样整个程序更加清晰也方便后续若有输入输出要求改变时的修改。
代码说明
前面按函数来说明,在阐述函数关系时我按照整个程序的运行流程来阐述,那代码说明部分我也同样按照这个流程吧~
- 这是主函数中按照题目要求判断输入是否符合要求部分的代码
int main(int argv, char *argc[]) //用命令行输入
{
string s = argc[2];
int N=0;
int len = s.length();
for (int i = 0; i < len; ++i) //判断输入是否符合要求
{
if (s[i] > '9' || s[i] < '0')
{
cout << "输入格式不正确,请输入整数\n";
return 0;
}
else
{
N = N * 10 + s[i] - '0';
}
}
}
2.在use_n中的代码
void Sudo::use_n(int N)
{
target = N; //将N传入类中
init();
pro_sudoku(1, 0, 1);
}
3.init中的代码
void Sudo::init()
{
srand((unsigned)time(NULL)); //播撒随机数种子
sudoku[0][0] = 2; //按照Z班的要求,尝试固定数独第一个数字,并将其定义为2
sudoku[0][1] = 1;
for (int i = 2; i<9; i++)
{
sudoku[0][i] = i+1; //将数独的第一行第2到8的格子依次填入1,3,4,5,6,7,8,9;
}
random_shuffle(&(sudoku[0][1]), &(sudoku[0][8])); //将数独的第一行第2到8的格子进行随机抖动完成数独的初始化
}
4.pro_sudoku中回溯法的关键代码,在前面已经介绍过回溯发的基本思想,在这里就不赘述了,这里代码中有个很关键的部分,就是选择填入格子中的数字。一开始我是采用随机产生1~9中任意数字,但是这样的话有可能一直无法产生你所需要的数字,而导致耗费时间。于是我进行了改进,从1开始按顺序产生数字如1,2,3,4.....一次填写进数独。但这样又有一个问题,由于我们初始化的数独的第一行的为随机数,但当数量增大时很有可能出现第一行相同的问题,这样每次都从1开始填写会导致最后输出的数独相同,于是!我又做出了改进。我给函数加了一个参数,让它变成了这个样子 void Sudo::pro_sudoku(int i, int j, int t) 接下来在下面代码里的注释1和注释2中我们可以看到,这样改动后,我们可以让数独每次填写的数字不但有序,还随机,成功解决了以上的耗费时间和输出数独雷同这两个问题。
for (int k = 1; k<9; k++)
{
int n = (t++) % 9 + 1; //1
if (judge(i, j, n))
{
sudoku[i][j] = n;
pro_sudoku(i, j + 1, t); //2
sudoku[i][j] = 0;
}
}
测试运行
代码写完我就迫不及待的运行了一下,将输入设置为3,然后成功输出了。

接下来我又尝试了100 ,1000,都成功了。于是开始进行性能分析。
这次我输入100,000
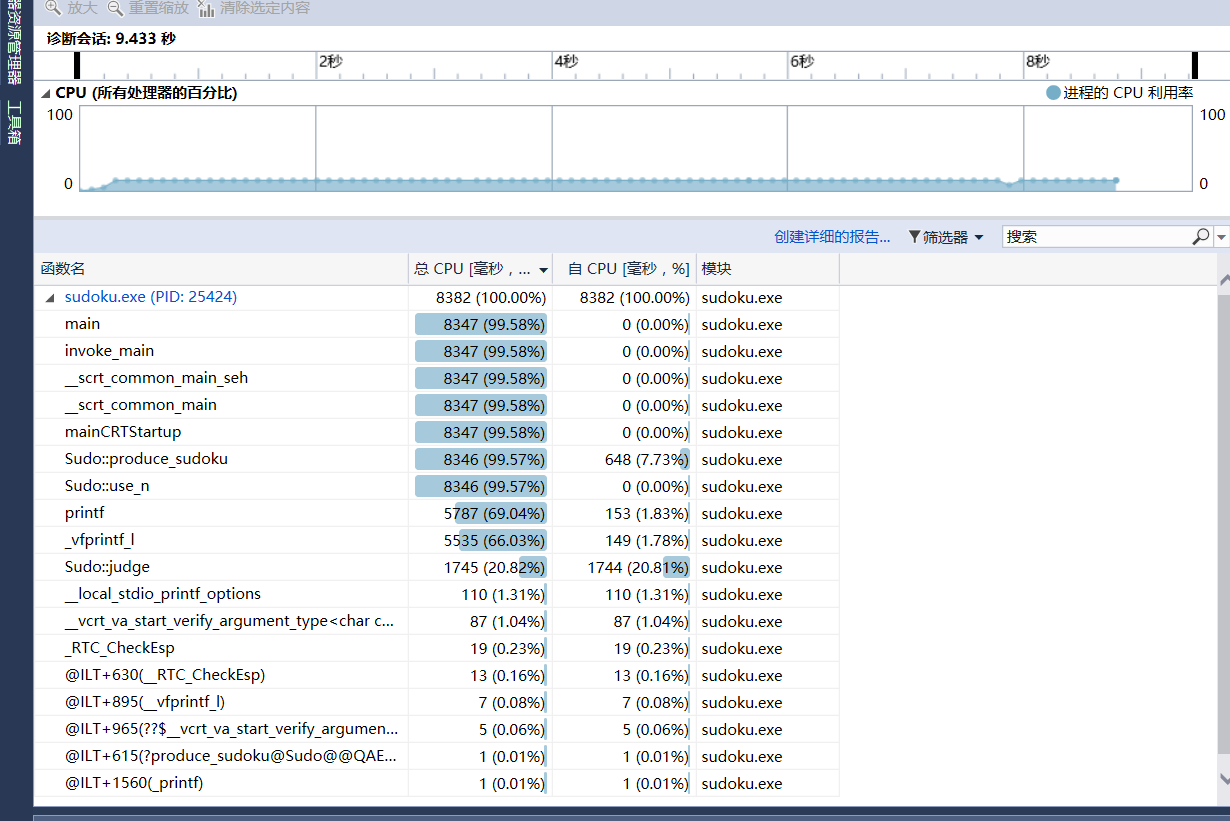
可以发现在图中print函数占用了很大的时长。这时同学提醒我用putchar会节省很多时间,我马上修改了代码,将输出部分改成了如下所示:
if (i == 9 && j == 0)
{
for (int k = 0; k<9; k++)
{
for (int l = 0; l<9; l++)
{
putchar(sudoku[k][l]+'0');
putchar(' ');
}
putchar('\n');
}
putchar('\n');
if (--target<= 0)
{
exit(0);
}
}
再进行一次性能分析,依旧输入100,000

没想到从9秒多变成了5秒多!
在好奇心的驱使下,我又试了好几次数据,下面是我1000,000输入时的运行时间42.11s,
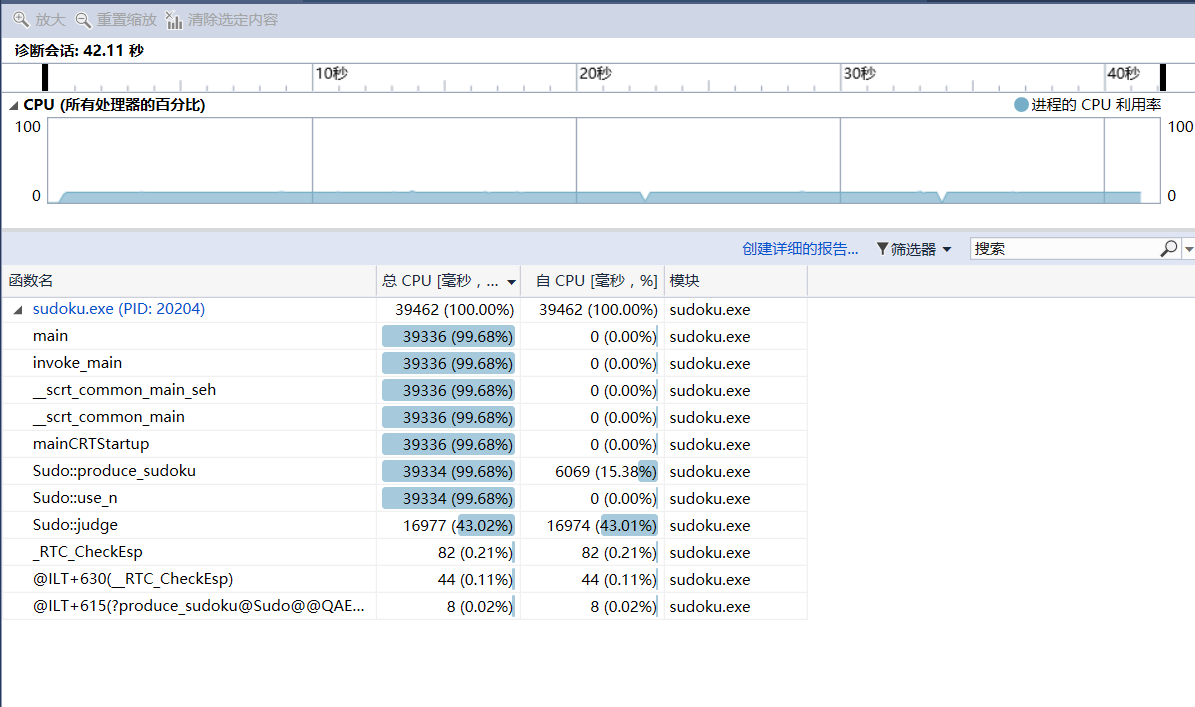
总结
这次的软工实践作业是9月4号布置的,但拖延症的我没有马上开始,一直拖到了8号才开始思考数独的事情。第二天构建之法到了后也认真阅读了前三章的内容,其中很多内容我看后有很大的收获和很深的感触,有时间我会在本博文中补充阅读笔记。当然对于测试单元那一块的内容,我没有理解,知道在软工中这是很重要的一部分,就像文中说的,没有单元测试的开发都只是玩玩。所以接下来希望通过课程和与老师同学的交流,能更加深刻的理解块知识。看完构筑之法后我就开始了摸索这次个人项目的道路,期间碰到了很多问题,尤其发现大一下学习的C++知识以及遗忘的差不多了,很久没有使用的Git用起来也十分生疏。在这过程中深刻的体会到自己有很多的缺漏,希望接下来能够花更多的时间在这门课程上。
由于最近刚开学周有很多事情要处理,所以没有花很多时间在这次作业中,附加题没有时间尝试我就直接放弃了。但我知道不管什么都不是借口,我会尽快调整自己,将更多的时间和精力放在学习上,放在更有意义的事情上。
看到了差距就更要努力~
(有时间博客我会不断完善补充的,最近比较忙,也许会在作业截止时间之后,不为评分,对的起自己~)
第二次作业——个人项目实战(sudoku)的更多相关文章
- 第二次作业——个人项目实战(Sudoku)
Github:Sudoku 项目相关要求 利用程序随机构造出N个已解答的数独棋盘 . 输入 数独棋盘题目个数N 输出 随机生成N个 不重复 的 已解答完毕的 数独棋盘,并输出到sudoku.txt中, ...
- 《Blue Flke团队》第二次作业通讯录项目开题报告
Just_Do_IT! N:8A:8B:7C:6D:8总分:37 Miracle-House N:8A:6B:7C:6D:8总分:35 Spring_Four N:7A:7B:8C:8D: ...
- Solr集群、KI分词、项目实战
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器.同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善 ...
- 软工实践作业2:个人项目实战之Sudoku
Github:Sudoku 项目相关要求 项目需求 利用程序随机构造出N个已解答的数独棋盘 . 输入 数独棋盘题目个数N(0<N<=1000000). 输出 随机生成N个不重复的已解答完毕 ...
- 【无私分享:ASP.NET CORE 项目实战(第二章)】添加EF上下文对象,添加接口、实现类以及无处不在的依赖注入(DI)
目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 上一章,我们介绍了安装和新建控制器.视图,这一章我们来创建个数据模型,并且添加接口和实现类. 添加EF上下文对象 按照我们以前 ...
- 《Coderxiaoban团队》第二次作业:团队项目选题报告
<Coderxiaoban团队>第二次作业:团队项目选题报告 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 实验六 团队作业2:团队项目选题 团队名称 Co ...
- 《AlwaysRun!团队》第二次作业:团队项目选题报告
第二次作业:团队项目选题报告 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblog ...
- 【精编重制版】JavaWeb 入门级项目实战 -- 文章发布系统 (第二节)
说明 本教程是,原文章发布系统教程的精编重制版,会包含每一节的源码,以及修正之前的一些错误.因为之前的教程只做到了评论模块,很多地方还不完美,因此重制版会修复之前的一些谬误和阐述不清的地方,而且,后期 ...
- 软件工程基础团队第二次作业(团队项目-需求分析&系统设计)成绩汇总
一.作业题目 团队第二次作业:需求分析&系统设计 二.具体要求 1.作业任务 任务一:组长组织项目组开展需求调研工作(可采取需求调查.问卷.分析已有软件.网上资料等方法).概要设计.详细设计. ...
随机推荐
- Redis的特性以及优势(附官网)
NoSQL:一类新出现的数据库(not only sql) 泛指非关系型的数据库 不支持SQL语法 存储结构跟传统关系型数据库中的那种关系表完全不同,nosql中存储的数据都是KV形式 NoSQL的世 ...
- 一步一步学习大数据:Hadoop 生态系统与场景
Hadoop概要 到底是业务推动了技术的发展,还是技术推动了业务的发展,这个话题放在什么时候都会惹来一些争议. 随着互联网以及物联网的蓬勃发展,我们进入了大数据时代.IDC预测,到2020年,全球会有 ...
- 解决「matplotlib 图例中文乱码」问题
在学习用 matplotlib 画图时遇到了中文显示乱码的问题,在网上找了很多需要修改配置的方法,个人还是喜欢在代码里修改. 解决方法如下: 在第2.3行代码中加上所示代码即可. import mat ...
- spark 例子wordcount topk
spark 例子wordcount topk 例子描述: [单词计算wordcount ] [词频排序topk] 单词计算在代码方便很简单,基本大体就三个步骤 拆分字符串 以需要进行记数的单位为K,自 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- Hibernate学习笔记四
1 整合log4j(了解) l slf4j 核心jar : slf4j-api-1.6.1.jar .slf4j是日志框架,将其他优秀的日志第三方进行整合. l 整合导入jar包 log4j 核心包 ...
- SSM-CRUD入门项目——删除
删除 分析 可以进行单个删除,直接点击每条记录后的删除按钮 批量删除,通过勾选checkbox框进行选择删除 单个删除: 通过发送DELETE请求的URL:/emp/{id} 这次我们先从contro ...
- 资源很多,你却不会使用——以不变应万变才是自学Java的正确方法
鄙人乐于寻找学习方法,在这里提出自己的见解,希望可以帮助想玩好Java而又感觉很难上手的同学对Java不再恐惧 现状 我们的同学们除了某月,某婷等等大神以外,想必仍然存在着一大批同学根本没有摸索到学习 ...
- django使用流程
1.安装django包 (命令行)>pip install django # conda install django 2.安装成功后,可以新建django项目 1(命令行)>django ...
- Drupal views 学习之初识
1. 简介 用过Yii框架的同学,应该都会用到过GridView和ListView组件.可以很方便的用网格或列表展示内容. 例如淘宝: 网格显示 列表显示 2. 使用view可以方便的配出类似上面的展 ...