Hadoop源码学习笔记(6)——从ls命令一路解剖
Hadoop源码学习笔记(6)
——从ls命令一路解剖
Hadoop几个模块的程序我们大致有了点了解,现在我们得细看一下这个程序是如何处理命令的。 我们就从原头开始,然后一步步追查。
我们先选中ls命令,这是一个列出分面式文件系统中的目录结构。传入一个查阅地址,如果没有则是根目录。启动NameNode和DataNode服务。然后在命令行中输入ls :

换成程序,如果写呢,我们新建一个ClientEnter类。之前章节中,我们就知道,在命令行中输入的dfs命令,指向到org.apache.hadoop.fs.FsShell,则这个类入口是一个main函数。所以先直接用,在clientEnter类的main函数中加入下面代码:
FsShell.main(new String[]{"-ls"});
然后执行,看到下面结果:
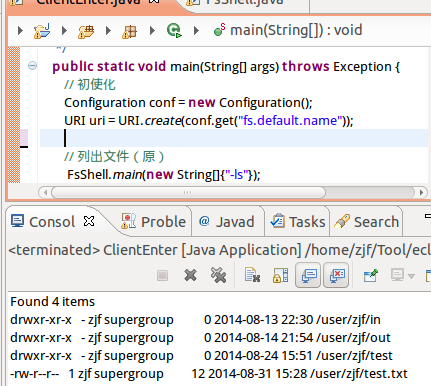
这个结果,与控制台中的是一样的,所以说调用正确。注意,这里多加了几行初使化用的,先写上,后面会用。
动刀解剖,我们进入FsShell的main函数中,看看里面是怎么实现的:
- public static void main(String argv[]) throws Exception {
- FsShell shell = new FsShell();
- int res;
- try {
- res = ToolRunner.run(shell, argv);
- } finally {
- shell.close();
- }
- System.exit(res);
- }
它这里,通过ToolRunner绕了一下,目的是把argv进行了下处理,但最终回到了FsShell的run函数中,进之:

发现,里面有大量的if else 条件都是cmd判断是否等于某个命令,于是找到ls命令,发现其调了FsShell下的ls函数,进之:
- private int ls(String srcf, boolean recursive) throws IOException {
- Path srcPath = new Path(srcf);
- FileSystem srcFs = srcPath.getFileSystem(this.getConf());
- FileStatus[] srcs = srcFs.globStatus(srcPath);
- if (srcs==null || srcs.length==0) {
- throw new FileNotFoundException("Cannot access " + srcf +
- ": No such file or directory.");
- }
- boolean printHeader = (srcs.length == 1) ? true: false;
- int numOfErrors = 0;
- for(int i=0; i<srcs.length; i++) {
- numOfErrors += ls(srcs[i], srcFs, recursive, printHeader);
- }
- return numOfErrors == 0 ? 0 : -1;
- }
这个ls函数行数不多,容易看清,参数是第一个是文件路径,第二个是递归。
然后前2~4行,就可以看到,获取到了文件状态,第13行,是打印显示查到的文件状态结果。这里就不进入看了。
于是提到出2~4行代码,加入到我们的测试程序中。同时把之前的调用注释掉:
- // 列出文件(原)
- //FsShell.main(new String[]{"-ls"});
- FileSystem srcFs = FileSystem.get(conf);
- FileStatus[] items = srcFs.listStatus(new Path("hdfs://localhost:9000/user/zjf"));
- for (int i = 0; i < items.length; i++)
- System.out.println( items[i].getPath().toUri().getPath());
小步快走,运行之,发现文件夹是对的,但打印内容少了,没错,因为我们没从FileStatus中全打出来。
这里可以看到,ls命令的核心是FileSystem中的listStatus函数了。
继续动刀。
观察FileSystem的listStatus函数,发现是个虚函数,同时FileSystem也是个一个抽象类,说明具体的listStatus实现,必然还在其它类中。于是监视srcFs类,发现其类型为DistributedFileSystem于是,把代码转换一下:
DistributedFileSystem srcFs = (DistributedFileSystem)FileSystem.get(conf);
运行程序,没有变化。说明路走对了。
继续,想抛弃这个FileSystem类呢,就行看看它如何在get方法中创建DistributedFileSystem这个类的,一级级查,发现,最终是在这里创建:
- private static FileSystem createFileSystem(URI uri, Configuration conf ) throws IOException {
- Class<?> clazz = conf.getClass("fs." + uri.getScheme() + ".impl", null);
- if (clazz == null) {
- throw new IOException("No FileSystem for scheme: " + uri.getScheme());
- }
- FileSystem fs = (FileSystem)ReflectionUtils.newInstance(clazz, conf);
- fs.initialize(uri, conf);
- return fs;
- }
这里应用了反射,可以看出,作者还是很牛的,这函数跟据传入的uri,的scheme(就是地址的前缀),来根据配置,创建相应的实现类,是一个工厂模式。
这里我们传入的uri是hdfs:// 所以查询参数:fs.hadfs.impl。于是到core-default.xml中查:
- <property>
- <name>fs.hdfs.impl</name>
- <value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
- <description>The FileSystem for hdfs: uris.</description>
- </property>
发现,此处配置文件,正是我们的DistributeFileSystem类。
然后看到,创建对象完后,就调用了initialize函数。于是我们把程序进一步改造:
- DistributedFileSystem srcFs = new DistributedFileSystem();
- srcFs.initialize(uri, conf);
- FileStatus[] items = srcFs.listStatus(new Path(
- ......
运行程序,保持正确结果。
此时,可以杀入DistributedFileSystem类的listStatus函数了。
- public FileStatus[] listStatus(Path p) throws IOException {
- FileStatus[] infos = dfs.listPaths(getPathName(p));
- if (infos == null) return null;
- FileStatus[] stats = new FileStatus[infos.length];
- for (int i = 0; i < infos.length; i++) {
- stats[i] = makeQualified(infos[i]);
- }
- return stats;
- }
进入后,发现主要由这个dfs对象访问,于是寻找dfs对象的创建:
this.dfs = new DFSClient(namenode, conf, statistics);
于是继续把我们的程序改造:
- Statistics statistics = new Statistics(uri.getScheme());
- InetSocketAddress namenode = NameNode.getAddress(uri.getAuthority());
- DFSClient dfs = new DFSClient(namenode, conf, statistics);
- FileStatus[] items = dfs.listPaths("/user/zjf");
- for (int i = 0; i < items.length; i++)
- System.out.println(items[i].getPath().toUri().getPath());
改造后,运行,结果与之前相同,说明路走对了。
继续前进,进入listPath函数,发现又是调用了ClientProtocol类的getListing函数。而这个ClientProtocol接口,好象有点熟悉了,在之前讲RPC调用时,这个是一个给客户端使用的接口,而具体的实现,在服务器端。
所以抛开DFSClient类,我们自己也可以创建这个RPC接口,然后自己调用。改造成如下:
- InetSocketAddress nameNodeAddr = NameNode.getAddress(uri.getAuthority());
- ClientProtocol namenode = (ClientProtocol)RPC.getProxy(ClientProtocol.class,
- ClientProtocol.versionID, nameNodeAddr, UnixUserGroupInformation.login(conf, true), conf,
- NetUtils.getSocketFactory(conf, ClientProtocol.class));
- FileStatus[] items = namenode.getListing("/user/zjf");
- for (int i = 0; i < items.length; i++)
- System.out.println(items[i].getPath().toUri().getPath());
此时,我们在Client这端已经走到了尽头,RPC调用getListing接口,具体实现是在nameNode服务器端了。
即然RPC在客户端调用的接口,具体是在服务器端实现。那么,我们如果直接创建服务器端的实现类,调用相应类的函数,不也能产出相同的结果么。
于是直接使用NameNode来创建实例,来调用:
- UserGroupInformation.setCurrentUser(UnixUserGroupInformation.login(conf, true));
- NameNode namenode = new NameNode(conf);
- FileStatus[] items = namenode.getListing("/user/zjf");
- for (int i = 0; i < items.length; i++)
- System.out.println(items[i].getPath().toUri().getPath());
运行该程序时,需要把之前的NameNode程序停止掉,因为我们不再需要这个服务,而是直接call这个服务中的方法了。
到目前为止,我们已经通过ls这个命令,从client端一杀到了namenode端。然后分析其它几个命令(delete,mkdir,getFileInfo)与ls相同。所以要想再深入看这些命令的处理,得在namenode中进一步研究。
namenode我们知道,主要存放的是文件目录信息,那利用上述这些命令,就可以进一步研究其目录的存储方式。这一块将在下一章中为进一步探讨。
Hadoop源码学习笔记(6)——从ls命令一路解剖的更多相关文章
- Hadoop源码学习笔记(1) ——第二季开始——找到Main函数及读一读Configure类
Hadoop源码学习笔记(1) ——找到Main函数及读一读Configure类 前面在第一季中,我们简单地研究了下Hadoop是什么,怎么用.在这开源的大牛作品的诱惑下,接下来我们要研究一下它是如何 ...
- Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构
Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构 之前我们简要的看过了DataNode的main函数以及整个类的大至,现在结合前面我们研究的线程和RPC,则可以进一步 ...
- Hadoop源码学习笔记(4) ——Socket到RPC调用
Hadoop源码学习笔记(4) ——Socket到RPC调用 Hadoop是一个分布式程序,分布在多台机器上运行,事必会涉及到网络编程.那这里如何让网络编程变得简单.透明的呢? 网络编程中,首先我们要 ...
- Hadoop源码学习笔记(3) ——初览DataNode及学习线程
Hadoop源码学习笔记(3) ——初览DataNode及学习线程 进入了main函数,我们走出了第一步,接下来看看再怎么走: public class DataNode extends Config ...
- Hadoop源码学习笔记(2) ——进入main函数打印包信息
Hadoop源码学习笔记(2) ——进入main函数打印包信息 找到了main函数,也建立了快速启动的方法,然后我们就进去看一看. 进入NameNode和DataNode的主函数后,发现形式差不多: ...
- Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍
最近在跟着一个大佬学习Hadoop底层源码及架构等知识点,觉得有必要记录下来这个学习过程.想到了这个废弃已久的blog账号,决定重新开始更新. 主要分以下几步来进行源码学习: 一.搭建源码阅读环境二. ...
- Hadoop源码学习笔记之NameNode启动场景流程四:rpc server初始化及启动
老规矩,还是分三步走,分别为源码调用分析.伪代码核心梳理.调用关系图解. 一.源码调用分析 根据上篇的梳理,直接从initialize()方法着手.源码如下,部分代码的功能以及说明,已经在注释阐述了. ...
- Hadoop源码学习笔记之NameNode启动场景流程二:http server启动源码剖析
NameNodeHttpServer启动源码剖析,这一部分主要按以下步骤进行: 一.源码调用分析 二.伪代码调用流程梳理 三.http server服务流程图解 第一步,源码调用分析 前一篇文章已经锁 ...
- Hadoop源码学习笔记之NameNode启动场景流程五:磁盘空间检查及安全模式检查
本篇内容关注NameNode启动之前,active状态和standby状态的一些后台服务及准备工作,即源码里的CommonServices.主要包括磁盘空间检查. 可用资源检查.安全模式等.依然分为三 ...
随机推荐
- GO学习笔记 - 基本数据类型
官方教程:https://tour.go-zh.org/basics/11 Go 的基本类型有Basic types bool string int int8 int16 int32 int64 ui ...
- logstash同步mongodb数据到elasticsearch
一.安装logstash 二.安装mongodb插件 cd D:\Software\ELK5.5.0\logstash-5.5.0\bin logstash-plugin install logsta ...
- Java_异常处理(Exception)
异常:Exception try{ //捕获异常 }catch{ //处理异常 } 异常处理机制: 1.在try块中,如果捕获了异常,那么剩余的代码都不会执行,会直接跳到catch中, 2.在try之 ...
- 2016级算法期末模拟练习赛-A.wuli51和京导的毕业旅行
1063 wuli51和京导的毕业旅行 思路 中等题,二分+贪心. 简化题意,将m+1个数字分成n份,ans为这n段中每段数字和的最大值,求ans最小值及其方案. 对于这种求最小的最大值,最常用的方法 ...
- (Lua) C++ 加入 Lua 環境擴充應用強度
Lua 在網上有非常多的介紹,就是一個小而巧的語言,可以放入嵌入式系統 也可以在一般的應用上非常強大,這邊主要記錄如何讓Lua加入C++裡頭應用 Lua source code 是以 C 語言下去編寫 ...
- pixi.js v5版本出了。
历尽千辛万苦,pixi.js v5版本出了. 请关注群 881784250, 会尽块出个微信小游戏版. pixi.js的每个函数,每个类都有测试用例的.出的版本都是很稳定的.
- C++默认实参
某些函数有这样一种形参,在函数的很多次调用中它们都被赋予一个相同的值,此时,我们把这个反复出现的值称为函数的默认实参.调用含有默认实参的函数时,可以包含该实参,也可以省略该实参. 例如定义一个函数sc ...
- Android开发不可或缺的十大网站及工具
1. Google 做开发前完全是小白,真心不知道有Google这东西,只晓得百度,遇到问题直接百度,不是黑百度,百度在娱乐八卦方面确实靠谱,但是技术方面查出来的东西基本千篇一律,有些答案甚至还会起到 ...
- nodejs(四) --- cluster模块详解
什么是cluster模块,为什么需要cluster模块? cluster在英文中有集.群的意思. nodejs默认是单进程的,但是对于多核的cpu来说, 单进程显然没有充分利用cpu,所以,node ...
- 浏览器缓存如何控制? && 在url框中回车、F5 和 Ctrl + F5的区别是什么?
第一部分: 浏览器缓存如何控制? 最近在做网站,但是不知道缓存是什么东西怎么能行! 如何实现HTTP缓存呢? 下面我们来一步一步的探寻实现机制把. 方案一: 无缓存 说明: 浏览器向服务器请求 ...