python处理文本文件
在测试任务过程中都或多或少遇到自己处理文本文件的情况。
举个栗子:
客户端测试从异常日志中收集有用信息。
后端测试需要创建各种规则的压力的词表。
...
这里给大家分享一个使用python脚本处理文本的一些小技巧,分三步
学会创建文本文件。
学会读取已有的文本文件。
学会处理读取文件后的内容
创建文本文件
脚本创建文件和人工创建步骤一样,打开新文件,写入内容,保存并关闭文件
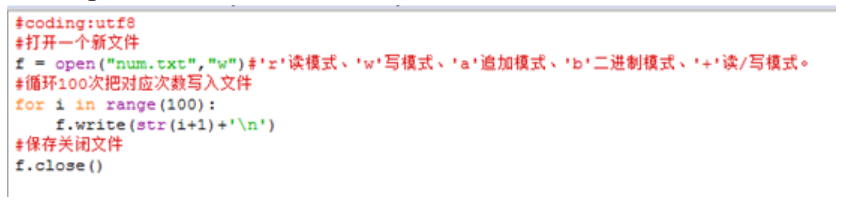
Case1:创建一个文件名为num.txt,内容是1~100数字分别每行一个
Code1:
#coding:utf-8
知识要点:
1.首行coding声明字符编码
根据涉及到的字符可以是gbk、utf8、cp936等等
2.open函数
包含两个参数,第一个参数为文件名。
第二个参数为模式,模式中常用的有只读“r”、写“w”、追加“a”。
r:只读模式常用于使用文本中内容,但不需要编辑内容时使用。
w:写模式常用于新增或编辑内容时使用。
a:追加模式跟写模式类似,不同点在于对同一文件追加模式会在文件内容尾部,续写,而写模式会清空内容重新写。
3.write和close函数
write传入的字符串内容即可。
close打开文件后一定要记得关闭保存。
读取已有的文本文件
Case2:读取文件(如图)内容,并打印。
Code2:

输出:

知识要点:
1.readline函数
每次读取一行,返回字符串。
2.read函数
读取整个文件,返回字符串。
3.readlines函数
读取整个文件,返回数组(数组的每个元素为每一行内容)。
处理读取文件后的内容
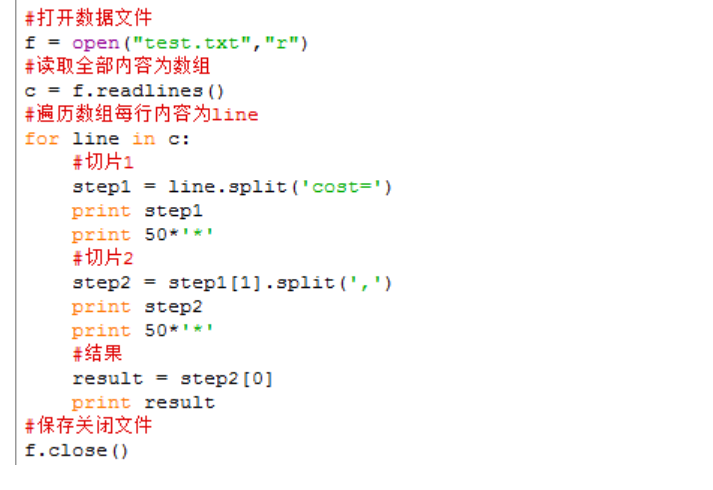
Case3:读取文件(如图)中内容cost的值。


Code3:
输出:

知识要点:
Split()函数
Step1:用字符串“cost=”切片原内容后的数组。
['[Sogou-Observer,', '29,ret=1,reqtype=dzz_activityperson,LocalQuery=0,PipeLine_Enter_LocalQueryTaskDZZ=1,Cost_Local=8,Reply=22,PipeLine_Enter_ReplyTask=29,parity=dzz_activityperson0000013CD91D0B011830401141DB4,id=web,Owner=OP]\n']
Step2:用step1第二个元素(cost=之后的内容),使用“,”切片获取数组
['29', 'ret=1','reqtype=dzz_activityperson', 'LocalQuery=0','PipeLine_Enter_LocalQueryTaskDZZ=1', 'Cost_Local=8', 'Reply=22','PipeLine_Enter_ReplyTask=29', 'parity=dzz_activityperson0000013CD91D0B011830401141DB4', 'id=web', 'Owner=OP]\n']
Step3:用step2第一个元素,即cost值作为结果。
29
python处理文本文件的更多相关文章
- Python中文本文件读写操作的编码问题
Python中文本文件读写的编码问题 编码(encode): 我们输入的任何字符想要以文件(如.txt)的形式保存在计算机的硬盘上, 必须先经按照一定的规则编成计算机认识的二进制后,才能存在电脑硬盘上 ...
- python读取文本文件
1. 读取文本文件 代码: f = open('test.txt', 'r') print f.read() f.seek(0) print f.read(14) f.seek(0) print f. ...
- python 读写文本文件
本人最近新学python ,用到文本文件的读取,经过一番研究,从网上查找资料,经过测试,总结了一下读取文本文件的方法. 1.在读取文本文件的时无非有两种方法: a.f=open('filename', ...
- Python 批处理文本文件、进行查找
去年换了一部手机,老手机终于光荣退休了,但是里面的便签里还存有很多文字记录,这个手机还不能备份到云,只能将每个便签保留为一个个的文本文件,我想要把所有的文本文件归到一个文本文件中,手动操作太麻烦了,刚 ...
- python 实现文本文件中的数字按序排序(位操作,低内存占用)
文本文件内容 ./txt 3241155299893344 处理代码: import sys a = bytearray(b'') for i in range(100): a.append(or ...
- python读取文本文件数据
本文要点刚要: (一)读文本文件格式的数据函数:read_csv,read_table 1.读不同分隔符的文本文件,用参数sep 2.读无字段名(表头)的文本文件 ,用参数names 3.为文本文件制 ...
- python 写文本文件出现乱码
最近工作中想完善一下监控日志,同事说客户突然说我们最近几天推送的数据只有几家,赶紧看预警,应推4700多家,实推3400多家,用户可能是看错了,但我记得当时项目验收上线时,这个来源的推送数据肯定是可以 ...
- python 查询文本文件的层次
I/O系统有一系列的层次构建而成 下面是操作一个文本文件的例子来查看这种层次 >>> f = open('sample.txt','w') >>> f <_i ...
- python解析文本文件演示样例
目的:查找文本中还有Sum/Avg的行中低三个竖线后第一个浮点数 思路:先使用python读取文本中一行,然后切割字符串.查找含有Sum/Avgkeyword的行.取出想要的结果 文本局部: .... ...
随机推荐
- C语言高速入门系列(八)
C语言高速入门系列(八) C语言位运算与文件 本章引言: 在不知不觉中我们的C高速入门系列已经慢慢地接近尾声了,而在这一节中,我们会对 C语言中的位运算和文件进行解析,相信这两章对于一些人来说是陌生的 ...
- 【Unity笔记】常见集合类System.Collections
ArrayList:长度可变数组,不限定类型 ArrayList al = new ArrayList(); ↓ List:替代ArrayList,限定类型 List list = new List& ...
- C语言 · 报时助手
基础练习 报时助手 时间限制:1.0s 内存限制:512.0MB 锦囊1 判断,字符串输出. 锦囊2 按要求输出,判断特殊情况. 问题描述 给定当前的时间,请用英文的读法 ...
- 解决javaWEB 下载文件中文名称乱码问题
response.setContentType("application/x-msdownload;"); response.setCharacterEncoding(" ...
- CMake使用入门
一.开胃菜 hello目录下的文件结构: ├── CMakeLists.txt ├── hello.c ├── hello.h └── main.c C代码见下节. 最简单的cmake配置文件: pr ...
- 动态标绘演示系统1.0(for OpenLayers3)
实现OpenLayers3(http://openlayers.org)版本号的动态标绘API.眼下1.0版本号,仅支持简单符号绘制. 在线体验地址:http://gispace.duapp.com/ ...
- Jenkins+ Xcode+ 蒲公英 实现IOS自动化打包和分发
Jenkins+ Xcode+ 蒲公英 实现IOS自动化打包和分发 直接入正题: Screen Shot 2015-09-18 at 16.56.20.png Mac上安装Jekins jekins下 ...
- DBA不可不知的操作系统内核参数
背景 操作系统为了适应更多的硬件环境,许多初始的设置值,宽容度都很高. 如果不经调整,这些值可能无法适应HPC,或者硬件稍好些的环境. 无法发挥更好的硬件性能,甚至可能影响某些应用软件的使用,特别是数 ...
- 支付宝前端开源框架Alice(解决各个浏览器的样式不一致的问题)
/**************** 网址:https://github.com/sofish/Alice /****************** @charset "utf-8& ...
- php 添加数据库的几种方法
最简单的 <?php $con = mysql_connect("localhost","root","root"); if (!$c ...