词法分析器Lexer
词法分析
In computer science, lexical analysis, lexing or tokenization is the process of converting a sequence of characters (such as in a computer program or web page) into a sequence of tokens (strings with an assigned and thus identified meaning).
在计算机科学中,词法分析,lexing或标记化是将一系列字符(例如在计算机程序或网页中)转换成一系列标记(具有指定且因此标识的含义的字符串)的过程。
编码目标
给定一个源代码文件,能够将其转化为词法记号流。
比如规定int的词法记号为30,输出就是<30, int>;数字的词法记号为11,则输入123,输出为<11, 123>。
约定
把程序中的词法单元分为四类:标识符(分为关键字和一般标识符)、数字、特殊字符、空白(空格、Tab、回车换行等)
程序流程图
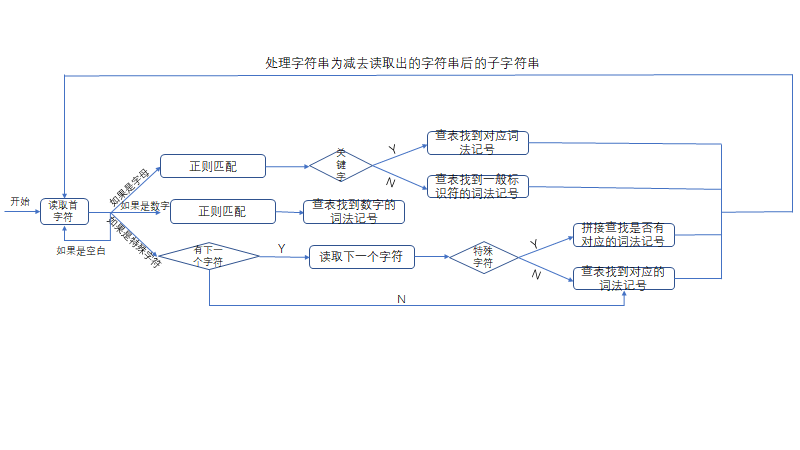
对于运算符等符号,这里只考虑两个字符的组合情况,不考虑三个字符组成的运算符。之所以要在读到特殊字符之后在往后读一个字符是因为有可能在表中存在类似>=和>的运算符,要保证最长字符匹配。
关键代码
首字符类型判断
public static String getCharType(String str) {
String regex_Letter = "[a-zA-Z]";
String regex_Number = "[0-9]";
String regex_Blank = "\\s";
Pattern pattern;
pattern = Pattern.compile(regex_Letter);
Matcher matcher = pattern.matcher(str);
if (matcher.find())
return "LETTER";
pattern = Pattern.compile(regex_Number);
matcher = pattern.matcher(str);
if (matcher.find())
return "NUMBER";
pattern = Pattern.compile(regex_Blank);
matcher = pattern.matcher(str);
if (matcher.find())
return "BLANK";
return "SPECIAL";
}
如果首字符为字母
case "LETTER":
pattern = Pattern.compile(regex_ID);
matcher = pattern.matcher(srcCode);
if (matcher.lookingAt()) {
String result = matcher.group();
if (LexicalToken.isKeyWord(result)) {
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
} else {
int token = lextok.getToken("ID");
System.out.printf("<%d,%s> ", token, result);
}
}
srcCode = srcCode.substring(matcher.end());
break;
如果首字符是数字
case "NUMBER":
pattern = Pattern.compile(regex_NUM);
matcher = pattern.matcher(srcCode);
if (matcher.lookingAt()) {
String result = matcher.group();
int token = lextok.getToken("NUM");
System.out.printf("<%d,%s> ", token, result);
}
srcCode = srcCode.substring(matcher.end());
break;
如果首字符是空格
case "BLANK":
srcCode = srcCode.substring(1);
break;
如果首字符是特殊符号
case "SPECIAL":
if (srcCode.length() > 1) {
String secondChar = srcCode.substring(1, 2);
String result;
LinkedHashMap tokenMap = lextok.getLexicalTokenMap();
Set set = tokenMap.keySet();
result = firstChar + secondChar;
if (getCharType(secondChar).equals("SPECIAL") && set.contains(result)) {
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
srcCode = srcCode.substring(2);
}else {
result = firstChar;
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
srcCode = srcCode.substring(1);
}
} else { // 字符串中只有一个字符时
int token = lextok.getToken(srcCode);
System.out.printf("<%d,%s> ", token, srcCode);
srcCode = srcCode.substring(1);
}
break;
源码地址:https://github.com/Liyzy/Lexer
开发环境:IJ idea 2018.2
词法分析器Lexer的更多相关文章
- atitit.词法分析原理 词法分析器 (Lexer)
atitit.词法分析原理 词法分析器 (Lexer) 1. 词法分析(英语:lexical analysis)1 2. :实现词法分析程序的常用途径:自动生成,手工生成.[1] 2 2.1. 词法分 ...
- 词法分析器Antlr
一.我们都知道编程语言在执行之前需要先进行编译,这样就可以把代码转换成机器识别的语言,这个过程就是编译. 那么它是怎么编译的呢? Java在JVM虚拟机中进行编译,javascript在Js引擎中编译 ...
- 02.从0实现一个JVM语言之词法分析器-Lexer-03月02日更新
从0实现JVM语言之词法分析器-Lexer 本次有较大幅度更新, 老读者如果对前面的一些bug, 错误有疑问可以复盘或者留言. 源码github仓库, 如果这个系列文章对你有帮助, 希望获得你的一个s ...
- B-index、bitmap-index、text-index使用场景详解
索引的种类:B-tree索引.Bitmap索引.TEXT index1. B-tree索引介绍: B-tree 是一种常见的数据结构,也称多路搜索树,并不是二叉树.B-tree 结构可以显著减少定位 ...
- oracle全文检索
全文检索 oracle对使用几十万以上的数据进行like模糊查询速度极差,包括 like 'AAA%' ,like '%AAA',like '%AAA%',like '%A%A%'的那些模糊查询.网上 ...
- Lex和Yacc入门
Lex和Yacc入门 标签: lexyacc 2013-07-21 23:02 584人阅读 评论(0) 收藏 举报 分类: Linux(132) 原文地址:http://coanor.blog ...
- Lex+YACC详解
1. 简介 只要你在Unix环境中写过程序,你必定会邂逅神秘的Lex&YACC,就如GNU/Linux用户所熟知的Flex&Bison,这里的Flex就是由Vern Paxon实现的一 ...
- oracle的全文索引
1.查看oracle的字符集 SQL> select userenv('language') from dual; USERENV('LANGUAGE') ------------------- ...
- Oracle建立全文索引详解
Oracle建立全文索引详解1.全文检索和普通检索的区别 不使用Oracle text功能,当然也有很多方法可以在Oracle数据库中搜索文本,比如INSTR函数和LIKE操作: SELECT *FR ...
随机推荐
- linux下RabbitMQ相关命令
1. 关闭与启动 ① 到指定目录:cd/etc/init.d ② 停止:rabbitmq-server stop ③ 启动:rabbitmq-server start ④ 查看是否停止/启动成功:ps ...
- 【Kafka源码】Kafka启动过程
一般来说,我们是通过命令来启动kafka,但是命令的本质还是调用代码中的main方法,所以,我们重点看下启动类Kafka.源码下下来之后,我们也可以通过直接运行Kafka.scala中的main方法( ...
- redis有序集合类型sort set
redis的数据类型之-有序集合 sort set和set类型一样,也是string类型元素的集合,也没有重复的元素,不同的是sort set每个元素都会关联一个权,通过权值可以有序的获取集合中的元素 ...
- javascript004_ECMA5数组新特性
•对于ECMAscript5这个版本的Array新特性补充: –位置方法:indexOf lastIndexOf –迭代方法:every filter forEach some ...
- Ubuntu14.04下Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
不多说,直接上干货! 写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentO ...
- jstl fmt标签的使用
所有标签 fmt:requestEncoding fmt:setLocale fmt:timeZone fmt:setTimeZone fmt:bundle fmt:setBundle fmt:mes ...
- JavaScript数据结构-10.字典
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Spring AMQP
Spring AMQP 是基于 Spring 框架的AMQP消息解决方案,提供模板化的发送和接收消息的抽象层,提供基于消息驱动的 POJO的消息监听等,很大方便我们使用RabbitMQ程序的相关开发. ...
- mysql经典查询
建立数据库 1.建立一个数据库 create database work; 2.进入数据库work use work; 3.数据库默认编码可能不支持中文,可以在这里设置下 set names gbk; ...
- Java时间的使用
JAVA处理日期时间常用方法: 1.java.util.Calendar Calendar 类是一个抽象类,它为特定瞬间与一组诸如 YEAR.MONTH.DAY_OF_MONTH.HOUR 等 日历字 ...