SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行(转)
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法。但是这样做实现起来非常复杂,而在SqlServer2005中我们有了PIVOT/UNPIVOT函数可以快速实现行转列和列转行的操作。
PIVOT函数,行转列
PIVOT函数的格式如下
PIVOT(<聚合函数>([聚合列值]) FOR [行转列前的列名] IN([行转列后的列名1],[行转列后的列名2],[行转列后的列名3],.......[行转列后的列名N]))
- <聚合函数>就是我们使用的SUM,COUNT,AVG等Sql聚合函数,也就是行转列后计算列的聚合方式。
- [聚合列值]要进行聚合的列名
- [行转列前的列名]这个就是需要将行转换为列的列名。
- [行转列后的列名]这里需要声明将行的值转换为列后的列名,因为转换后的列名其实就是转换前行的值,所以上面格式中的[行转列后的列名1],[行转列后的列名2],[行转列后的列名3],......[行转列后的列名N]其实就是[行转列前的列名]每一行的值。
下面我们来看一个例子有一张表名为[ShoppingCart]有三列[Week],[TotalPrice],[GroupId],数据和表结构如下所示:

CREATE TABLE [dbo].[ShoppingCart](
[Week] [int] NOT NULL,
[TotalPrice] [decimal](18, 0) NOT NULL,
[GroupId] [int] NULL
) ON [PRIMARY] GO ALTER TABLE [dbo].[ShoppingCart] ADD DEFAULT ((0)) FOR [TotalPrice]
GO INSERT [dbo].[ShoppingCart] ([Week], [TotalPrice], [GroupId]) VALUES (1, CAST(10 AS Decimal(18, 0)), 1)
GO
INSERT [dbo].[ShoppingCart] ([Week], [TotalPrice], [GroupId]) VALUES (2, CAST(20 AS Decimal(18, 0)), 1)
GO
INSERT [dbo].[ShoppingCart] ([Week], [TotalPrice], [GroupId]) VALUES (3, CAST(30 AS Decimal(18, 0)), 1)
GO
INSERT [dbo].[ShoppingCart] ([Week], [TotalPrice], [GroupId]) VALUES (4, CAST(40 AS Decimal(18, 0)), 1)
GO
INSERT [dbo].[ShoppingCart] ([Week], [TotalPrice], [GroupId]) VALUES (5, CAST(50 AS Decimal(18, 0)), 1)
GO
INSERT [dbo].[ShoppingCart] ([Week], [TotalPrice], [GroupId]) VALUES (6, CAST(60 AS Decimal(18, 0)), 1)
GO
INSERT [dbo].[ShoppingCart] ([Week], [TotalPrice], [GroupId]) VALUES (7, CAST(70 AS Decimal(18, 0)), 1)
GO

现在我们是用PIVOT函数将列[WEEK]的行值转换为列,并使用聚合函数Count(TotalPrice)来统计每一个Week列在转换前有多少行数据,语句如下所示:
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
查询结果如下:

我们可以看到PIVOT函数成功地将[ShoppingCart]表列[Week]的行值转换为了七列,并且每一列统计转换前的行数为1,这符合我们的预期结果。那么根据我们前面定义的PIVOT函数转换格式,在本例中我们有如下公式对应值:
- <聚合函数>本例中为Count
- [聚合列值]本例中为[TotalPrice],统计了行转列前的行数
- [行转列前的列名]本例中为[Week]
- [行转列后的列名]本例中为[1],[2],[3],[4],[5],[6],[7]七个列,因为行转列前[ShoppingCart]表的[Week]列有七个值1,2,3,4,5,6,7,所以这里声明转换后的列名也为七个,对应这七个值分别为[1],[2],[3],[4],[5],[6],[7],PIVOT函数会将[ShoppingCart]表中[Week]列的值分别和[1],[2],[3],[4],[5],[6],[7]这七列的列名进行匹配,然后计算<聚合函数>(本例中为count(TotalPrice))得出转换后的列值。
另外如果我们在[行转列后的列名]中只声明了部分值,那么PIVOT函数只会针对这些部分值做行转列,而那些没有被声明为列的行值会在行转列后被忽略掉。例如我们下面的语句声明了只对表ShoppingCart中[Week]列的1,2,3三个值做行转列,但是实际上表ShoppingCart中列[Week]有1,2,3,4,5,6,7这7个值,那么剩下的4到7就会被PIVOT函数忽略掉,如下所示:
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3])) AS T
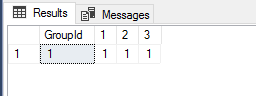
我们可以看到查询结果中PIVOT函数只针对表ShoppingCart中列[Week]的1,2,3三个值做了行转列,而4到7被忽略了。
需要注意的是PIVOT函数的查询结果中多了一列GroupId,这是因为PIVOT函数只用到了[ShoppingCart]表中的列[Week]和[TotalPrice],[ShoppingCart]表中还有一列[GroupId],PIVOT函数没有用到,所以PIVOT函数默认将[ShoppingCart]表中没有用到的列当做了Group By来处理,用来作为行转列后每一行数据分行的依据,又由于列[GroupId]在[ShoppingCart]表中全为值1,所以最后PIVOT函数在行转列后只有一行[GroupId]为1的数据,如果我们将[ShoppingCart]表列[GroupId]的值从只有1变成有1和2两种值,如下所示:

然后再执行PIVOT查询:
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
会得到如下结果:
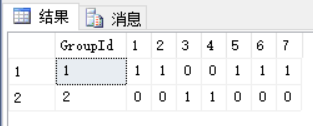
我们看到这一次我们用PIVOT函数做行转列后得到了两行值,可以看到转换后列[3]和[4]在[GroupId]为2的这一行上为1,这就是因为我们将[ShoppingCart]表中[Week]为3和4的两行改成了[GroupId]为2后,[GroupId]有了两个值1和2,所以PIVOT函数行转列后就有两行值。
知道了PIVOT函数的用法之后,我们来看看PIVOT函数的几种错误用法:
在PIVOT函数的使用中有一点需要注意,那就是[行转列后的列名]必须是[行转列前的列名]的值,PIVOT函数才能成功执行,比如如下所示如果我们将[行转列后的列名]声明了一个和[行转列前的列名]值毫不相干的数字1000,那么PIVOT函数执行后1000是没有任何数据的为0:
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7],[1000])) AS T
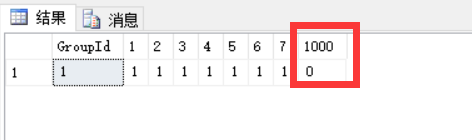
这是因为[ShoppingCart]表中列[Week]没有值1000,所以用PIVOT函数将列[Week]行转列后列[1000]的值就为0。
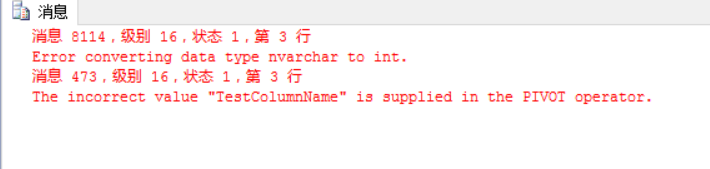
如果将PIVOT函数中[行转列后的列名]声明为了[行转列前的列名]完全不同的数据类型,还会导致PIVOT函数报错,例如下面我们在[行转列后的列名]中声明了一个列名为字符串[TestColumnName],但是由于[行转列前的列名]Week是Int类型,从而无法将字符串TestColumnName转换为Int类型,所以PIVOT函数报错了:
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7],[TestColumnName])) AS T
UNPIVOT函数,列转行
UNPIVOT函数的格式如下:
UNPIVOT([转换为行的列值在转换后对应的列名] for [转换为行的列名在转换后对应的列名] in ([转换为行的列1],[转换为行的列2],[转换为行的列3],...[转换为行的列N]))
- [转换为行的列值在转换后对应的列名]这个是进行列转行的列其数据值在转换为行后的列名称
- [转换为行的列名在转换后对应的列名]这个是进行列转行的列其列名在转换为行后的列名称
- [转换为行的列]这个是声明哪些列要进行列转行
如下所示,列转行前为:
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T

现在使用UNPIVOT函数将上面结果的列[1],[2],[3],[4],[5],[6],[7]转换为行值,如下所示:
with PIVOT_Table as
(
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
) select * from PIVOT_Table UNPIVOT([RowCount] for [Week] in ([1],[2],[3],[4],[5],[6],[7])) as T
 、
、
可以看到[1],[2],[3],[4],[5],[6],[7]这七列在UNPIVOT函数执行后其值变为了列[RowCount],列转行前的列名称在转换后变为了列[Week],同样套用UNPIVOT函数格式我们可以得到如下结果:
- [转换为行的列值在转换后对应的列名]在本例中为[RowCount]
- [转换为行的列名在转换后对应的列名]在本例中为[Week]
- [转换为行的列]这个是声明哪些列要进行列转行,在本例中为[1],[2],[3],[4],[5],[6],[7]这七列
需要注意如果列转行前有两行值:
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T

那么UNPIVOT函数转换后应该为14行(列转行前的行数2 X 需要进行列转行的列数7 = 14)数据:
with PIVOT_Table as
(
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
) select * from PIVOT_Table UNPIVOT([RowCount] for [Week] in ([1],[2],[3],[4],[5],[6],[7])) as T
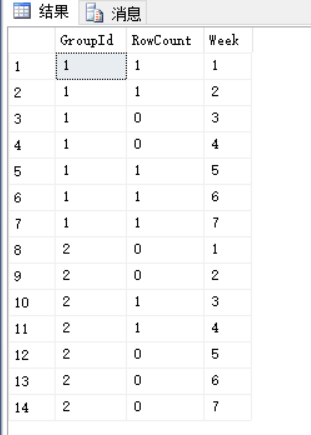
此外需要注意UNPIVOT函数不会对列转行中没有用到的列作Group By处理,也不会对列传行后的值做聚合运算,这一点是和PIVOT函数不同的。比如现在如果我们有下面一个查询:
with PIVOT_Table as
(
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
union all
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
) select * from PIVOT_Table
起查询结果为:
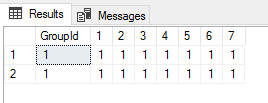
我们可以看到查询结果中有两行GroupId为1的数据,现在我们再用UNPIVOT函数对这个查询的列[1]到[7]做列转行运算,其中没有用到列GroupId:
with PIVOT_Table as
(
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
union all
select *
from ShoppingCart as C
PIVOT(count(TotalPrice) FOR [Week] IN([1],[2],[3],[4],[5],[6],[7])) AS T
) select * from PIVOT_Table UNPIVOT([RowCount] for [Week] in ([1],[2],[3],[4],[5],[6],[7])) as T
结果如下所示:
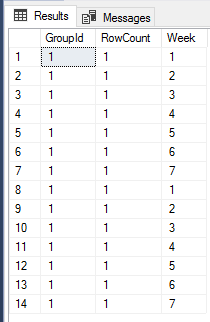
我们可以看到结果出现了14行数据(列转行前的行数2 X 需要进行列转行的列数7 = 14),所以我们可以看到虽然我们在UNPIVOT函数中没有用到列GroupId,并且在列转行前GroupId列有两行相同的值1,但是UNPIVOT函数在列转行后仍然生成了14行数据,而不是7行数据,因此并没有对GroupId列做Group By处理来合并相同的值,这一点和前面的PIVOT函数是不同的。
转载来源 https://www.cnblogs.com/OpenCoder/p/6668882.html
SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行(转)的更多相关文章
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
- SqlServer 行转列,列转行 以及PIVOT函数快速实现行转列,UNPIVOT实现列转行
一 .列转行 创建所需的数据 CREATE TABLE [StudentScores]( [UserName] NVARCHAR(20), --学生姓名 [Subject] NVARCHAR(3 ...
- [MSSQL]採用pivot函数实现动态行转列
环境要求:2005+ 在日常需求中常常会有行转列的事情需求处理.假设不是动态的行,那么我们能够採取case when 罗列处理. 在sql 2005曾经处理动态行或列的时候,通常採用拼接字符串的方法处 ...
- PIVOT函数与UNPIVOT函数的运用
PIVOT用于将行转为列,完整语法如下: TABLE_SOURCE PIVOT( 聚合函数(value_column) FOR pivot_column IN(<column_list>) ...
- Oracle行转列,pivot函数和unpivot函数
pivot函数:行转列函数: 语法:pivot(任一聚合函数 for 需专列的值所在列名 in (需转为列名的值)):unpivot函数:列转行函数: 语法:unpivot(新增值所在列的列名 for ...
- Oracle行转列(使用pivot函数)
在日常使用中,经常遇到这样的情况,需要将数据库中行转化成列显示,如 转化为 这个时候,我们就需要使用pivot函数 百度后,参考网址http://www.2cto.com/database/20150 ...
- mssql sqlserver 不固定行转列数据(动态列)
转自:http://www.maomao365.com/?p=5471 摘要: 下文主要讲述动态行列转换语句,列名会根据行数据的不同, 动态的发生变化 ------------------------ ...
- SQL SERVER pivot(行转列),unpivot(列转行)
[pivot]行转列:多行变一列 假设学生成绩表Score1 Name Subject Score 小张 语文 88 小花 数学 89 小张 数学 90 Name 语文 数学 小花 null 89 小 ...
- sqlserver数据库安全函数、配置函数、游标函数、行级函数、排名函数、元数据函数、系统统计函数 、文本和图像函数--收藏着有用
行级函数:下列行集函数将返回一个可用于代替 Transact-SQL 语句中表引用的对象. CONTAINSTABLE 返回具有零行.一行或多行的表,这些行的列中包含的基于字符类型的数据是单个词语和短 ...
随机推荐
- Invalidate()函数
Invalidate( ) :使整个窗口客户区无效, 并进行更新显示的函数 介绍 void Invalidate( BOOL bErase = TRUE ); 参数: bErase 决定了是否要在WM ...
- JavaScript入门第4天
闭包:子函数可以使用父函数的局部变量 <html> <head> <title>闭包 </title> <script> function ...
- go-study
package (包) 一个目录下面所有的.go文件的包名必须相同. 包名一般和目录名相同(是约定, 不是强制), 包名都小写 main包是一个特殊的包名, 在main包中, 必须包含func mai ...
- swift - 之TabBarController的用法
TabBarController的使用,下面记录两种写法,代码如下: TabBarItem系统自带图标样式(System)介绍: Custom:自定义方式,配合Selected Image来自定义图标 ...
- Mac普通用户修改了/etc/sudoers文件的解决办法
1.开启 Root 账户 打开“系统偏好设置”,进入“用户与群组”面板,记得把面板左下角的小锁打开,然后选择面板里的“登录选项”.在面板右边你会看到“网络账户服务 器”,点击它旁边的“加入…”按钮,再 ...
- oracle启动报ORA-03113;
[案例] 在重启数据库过程中: SQL> startup ORACLE instance started. Total System Global Area 1.0489E+10 bytes F ...
- 【渗透测试学习平台】 web for pentester -4.目录遍历
Example 1 http://192.168.106.154/dirtrav/example1.php?file=../../../../../../../etc/passwd Example 2 ...
- ReactiveCocoa - iOS开发的新框架
本文转载至 http://www.infoq.com/cn/articles/reactivecocoa-ios-new-develop-framework ReactiveCocoa(其简称为RAC ...
- iOS-代码修改Info.plist文件
解决办法: 1.首先系统的Info.Plist文件是只读文件 并不能 写入.目前我个人是没有办法存入,官方属性 可以看到是readOnly 2.那么我们 就想代码修改Info.Plist文件怎么办呢, ...
- GROW
经理今天介绍了一下,GROW,就给他放上来了: 有一个辅导的方法 叫做 GROW (G:goal:R:reality:O:option:W:will)这个辅导方法是这样的,客观地给自己或者别人提问 ...