Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1705.03122
Motivation:
- Compared to recurrent layers, convolutions create representations for fixed size contexts, however, the effective context size of the network can easily be made larger by stacking several layers on top of each other. This allows to precisely control the maximum length of dependencies to be modeled. Convolutional networks do not depend on the computations of the previous time step and therefore allow parallelization over every element in a sequence. This contrasts with RNNs which maintain a hidden state of the entire past that prevents parallel computation within a sequence.
- Multi-layer convolutional neural networks create hierarchical representations over the input sequence in which nearby input elements interact at lower layers while distant elements interact at higher layers. Hierarchical structure provides a shorter path to capture long-range dependencies compared to the chain structure modeled by recurrent networks. Inputs to a convolutional network are fed through a constant number of kernels and non-linearities, whereas recurrent networks apply up to n operations and non-linearities to the first word and only a single set of operations to the last word. Fixing the number of nonlinearities applied to the inputs also eases learning.
Innotation:
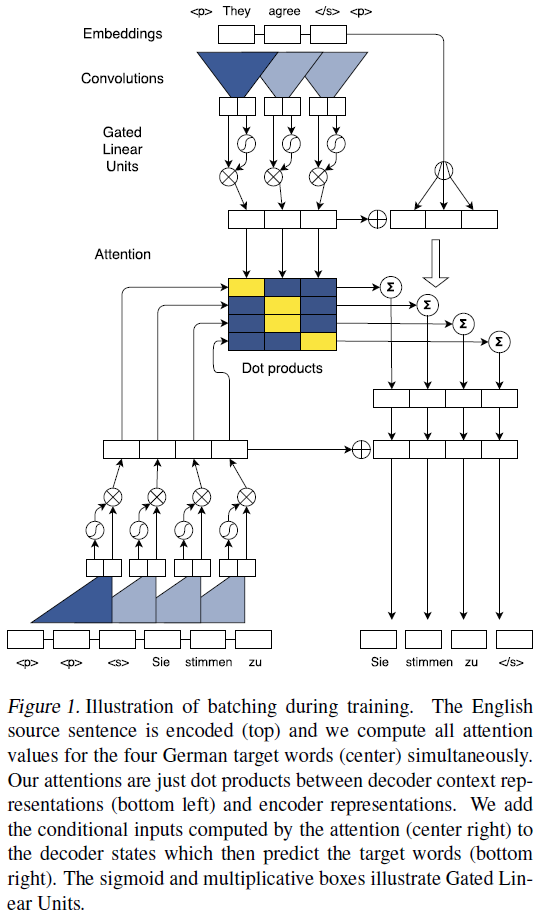
- An architecture for Seq2Seq modeling based entirely on convolutional neural networks. Both encoder and decoder networks share a simple block structure that computes intermediate states based on a fixed number of input elements. Each block contains a one dimensional convolution followed by a non-linearity. For a decoder network with a single block and kernel width k, each resulting state hi1 contains information over k input elements. Stacking several blocks on top of each other increases the number of input elements represented in a state. ( Stacking is similar to the pooling process. )
- Position Embeddings: Input elements x = (x1, . . . , xm) embedded in distributional space as w = (w1, . . . , wm), where wj ∈ Rf is a column in an embedding matrix D ∈ RV×f. The authors also equip the model with a sense of order by embedding the absolute position of input elements p = (p1, . . . , pm) where pj ∈ Rf. Both are combined to obtain input element representations e = (w1+p1, . . . , wm+pm). Position embeddings are useful in the architecture since they give the model a sense of which portion of the sequence in the input or output it is currently dealing with.
- The authors introduce a separate attention mechanism for each decoder layer.
Improvement:
- The model is equipped with gated linear units ( Language modeling with gated linear units - Dauphin et al., arXiv 2016 ) and residual connections ( Deep Residual Learning for Image Recognition - He et al., CVPR 2015a ).
- The authors choose gated linear units as non-linearity which implement a simple gating mechanism over the output of the convolution Y = [A B] ∈ R2d: v([A B]) = A ⓧ σ(B), where A, B ∈ Rd are the inputs to the non-linearity, ⓧ is the point-wise multiplication and the output v([A B]) ∈ Rd is half the size of Y. The gates σ(B) control which inputs A of the current context are relevant. And GLUs perform better than tanh in the context of language modelling.
- To enable deep convolutional networks, authors add residual connections from the input of each convolution to the output of the block. hil = v( Wl [hi−k/2l−1, . . . , hi+k/2l−1] + bwl ) + hil−1
- For encoder networks authors ensure that the output of the convolutional layers matches the input length by padding the input at each layer. However, for decoder networks they have to take care that no future information is available to the decoder. Specifically, we pad the input by k − 1 elements on both the left and right side by zero vectors, and then remove k elements from the end of the convolution output.
General Points:
- Sequence to sequence modeling has been synonymous with recurrent neural network based encoder-decoder architectures. The encoder RNN processes an input sequence x = (x1, . . . , xm) of m elements and returns state representations z = (z1, . . . , zm). The decoder RNN takes z and generates the output sequence y = (y1, . . . , yn) left to right, one element at a time. To generate output yi+1, the decoder computes a new hidden state hi+1 based on the previous state hi, an embedding gi of the previous target language word yi, as well as a conditional input ci derived from the encoder output z. Models without attention consider only the final encoder state zm by setting ci = zm for all i, or simply initialize the first decoder state with zm, in which case ci is not used. Architectures with attention compute ci as a weighted sum of (z1, . . . , zm) at each time step. The weights of the sum are referred to as attention scores and allow the network to focus on different parts of the input sequence as it generates the output sequences. Attention scores are computed by essentially comparing each encoder state zj to a combination of the previous decoder state hi and the last prediction yi; the result is normalized to be a distribution over input elements.
Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★的更多相关文章
- Paper Reading - Convolutional Image Captioning ( CVPR 2018 )
Link of the Paper: https://arxiv.org/abs/1711.09151 Motivation: LSTM units are complex and inherentl ...
- [paper reading] C-MIL: Continuation Multiple Instance Learning for Weakly Supervised Object Detection CVPR2019
MIL陷入局部最优,检测到局部,无法完整的检测到物体.将instance划分为空间相关和类别相关的子集.在这些子集中定义一系列平滑的损失近似代替原损失函数,优化这些平滑损失. C-MIL learns ...
- Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1706.03762 Motivation: The inherently sequential nature of ...
- Convolutional Sequence to Sequence Learning 论文笔记
目录 简介 模型结构 Position Embeddings GLU or GRU Convolutional Block Structure Multi-step Attention Normali ...
- PP: Sequence to sequence learning with neural networks
From google institution; 1. Before this, DNN cannot be used to map sequences to sequences. In this p ...
- 【论文阅读】Sequence to Sequence Learning with Neural Network
Sequence to Sequence Learning with NN <基于神经网络的序列到序列学习>原文google scholar下载. @author: Ilya Sutske ...
- Mol Cell Proteomics. | Prediction of LC-MS/MS properties of peptides from sequence by deep learning (通过深度学习技术根据肽段序列预测其LC-MS/MS谱特征) (解读人:梅占龙)
通过深度学习技术根据肽段序列预测其LC-MS/MS谱特征 解读人:梅占龙 质谱平台 文献名:Prediction of LC-MS/MS properties of peptides from se ...
- Paper Read: Convolutional Image Captioning
Convolutional Image Captioning 2018-11-04 20:42:07 Paper: http://openaccess.thecvf.com/content_cvpr_ ...
- A neural chatbot using sequence to sequence model with attentional decoder. This is a fully functional chatbot.
原项目链接:https://github.com/chiphuyen/stanford-tensorflow-tutorials/tree/master/assignments/chatbot 一个使 ...
随机推荐
- Node 192.168.248.12:7001 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
[root@node00 src]# ./redis-trib.rb add-node --slave --master-id4f6424e47a2275d2b7696bfbf8588e8c4c3a5 ...
- mint-ui 企业微信PC端内置浏览器 Picker 无法滚动
处理 在主JS代码之上附加以下代码 : <script> if (~navigator.userAgent.toLowerCase().indexOf('windowswechat')) ...
- 国产开源JavaWeb应用程序框架——XWAF(1)
XWAF是一个基于java反射和Servlet 技术的国产开源Web应用程序框架.其英文全称为“eXtensible Web Application Framework”,意即“可扩展的网络应用程序框 ...
- koa2学习笔记01 - 创建项目 —— koa生成器一键生成koa项目
前言 从17年开始尝试学习搭建个人网站开始,就开始学习摸索node了,至今差不多快两年了. 说起来现在都9102年了,所以最近打算整体设计重构一下网站,索性node后台也重写一遍. 重温一下node, ...
- $.trim() 去除空格方法 (验证使用)
- $.ajax(),$.get(),$.post()的区别,以及一些参数注意规则
$.ajax()方法和$.get(),$.post()方法的对比 $.ajax()方法是最完整的写法,可以完成所有的ajax请求(包含get类型和post类型) $.get()和$.post()都是简 ...
- vue-cli 项目安装失败 tunneling socket could not be established, cause=connect ECONNREFUSED
1.安装vue-cli npm install vue-cli -g 2.初始化项目 vue init webpack project 此时报错:vue-cli · Failed to downloa ...
- redis应用场景:实现简单计数器-防止刷单
redis应用场景:实现计数器-防止刷单 最近由于双11要来临,公司需要在接口请求上,做一下并发限制的处理,或者做一个防止刷单的安全拦截:比如:一个接口请求,限制每秒请求总数为200次,超过200次就 ...
- 树莓派3B+学习笔记:7、挂载exfat格式U盘
树莓派的官方系统,默认不支持exfat格式U盘挂载. 插入exfat格式U盘会出现以下错误提示: 安装exfat-fuse后可以正常识别,需要在命令行执行以下命令,按“y”键回车确认: sudo ap ...
- 什么是PHP7中的孤儿进程与僵尸进程
什么是PHP7中的孤儿进程与僵尸进程 基本概念 我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程.子进程的结束和父进程的运行是一个异步过程,即父进程永远无法 ...