【RL系列】从蒙特卡罗方法步入真正的强化学习
蒙特卡罗方法给我的感觉是和Reinforcement Learning: An Introduction的第二章中Bandit问题的解法比较相似,两者皆是通过大量的实验然后估计每个状态动作的平均收益。不过两者的区别也是显而易见,Bandit问题比较简单,状态1->动作1->状态1,这个状态转移过程始终是自我更新的过程,而且是一一对应的关系。蒙特卡罗方法所解决的问题就要复杂一些,通常来说,其状态转移过程可能为,状态1->动作1->状态2->动作1->状态3。Sutten书中是这样描述两者的区别:
The main difference is that now there are multiple states, each acting like a different bandit problem (like an associative-search or contextual bandit) and that the different bandit problems are interrelated.
这里说的很好,应用蒙特卡罗方法的问题中的每一个状态下的其中一个动作之后的状态转移过程都像是许多个不同的Bandit问题。还有一个很明显的区别是,蒙特卡罗问题大都有一个或几个明确的目标状态,达到目标状态后,才能计算当前收益,中间过程通常来说并没有自己的状态或动作收益,但对于Bandit问题来说是没有这个中间过程的。
什么是中间过程?简单来说就是从起始状态到达目标状态中间所经历的状态动作集合。在蒙特卡罗方法中,中间过程不获得任何奖励,但是中间过程的状态动作价值可以由目标状态奖励进行估计。这个估计的原则也很简单,可以描述为:某状态动作价值可以估计为经过该状态到达目标所获得的奖励之和除以经过该状态的次数。对于某个中间过程的状态动作价值估计实际上就是许多个不同的Bandit问题中的一个。在上一篇文章中提到了在解决Soap Bubble问题中,蒙特卡罗方法的优势,即可以快速收敛某一个状态或某几个状态的价值估计。上一篇文章中的算法只关注起始状态的价值收敛而完全忽略中间过程,但当使用蒙特卡罗方法估计所有状态价值时,对中间过程不进行任何处理的方法就太低效了。所以下面我们尝试将中间状态价值估计应用到之前的算法中,看一看完整的蒙特卡罗方法进行价值估计的算法流程,还是以Soap Bubble为例(什么是Soap Bubble问题,可以参考上一篇博文【RL系列】蒙特卡罗方法——Soap Bubble):
- 投影闭合曲线到x-y平面
- 开始迭代,随机选择起始点(x, y)
- 随机选择动作开始游走
- 判断是否碰到边界,如碰到边界,记录边界高度值$ H_b $,并记录中间经过的每一个状态,写成状态集合$S$。未碰到则继续游走。
- 设状态state属于状态集合$ S $,用公式更新状态state的价值总和$ V(\mathrm{state}) $与经过状态state的次数$ C(\mathrm{state}) $:$$ V(\mathrm{state}) = V(\mathrm{state}) + H_b \\ C(\mathrm{state}) = C(\mathrm{state}) + 1$$
- 回到第三步重新开始迭代。经过大量次数的实验后,停止循环过程。
- 任何一点(任何一个状态)的高度值的估计可以计算估计为((x, y) = state):$$ H(state) = \frac{V(state)}{C(state)} $$
这个加入中间过程估计的逻辑还是很简单的,因为蒙特卡罗方法有一条非常重要的性质,“每一个状态的估计都是独立的,不依赖于其它状态的! ”,所以你可以把中间过程某个状态的估计看成是该状态作为起始状态的估计。迭代开始之初对起始状态的随机选择也十分重要,随机选择是为了保证每个装填都有作为起始状态的机会,也是为了增加每一个状态被访问的机会,这种策略叫做Exploring Starts,当其同时运用到动作选择时,才是完整的Monte Carlo ES算法(这个算法也是Monte Carlo经典问题BlackJack的求解基础!)。
直接给出该算法的计算结果:
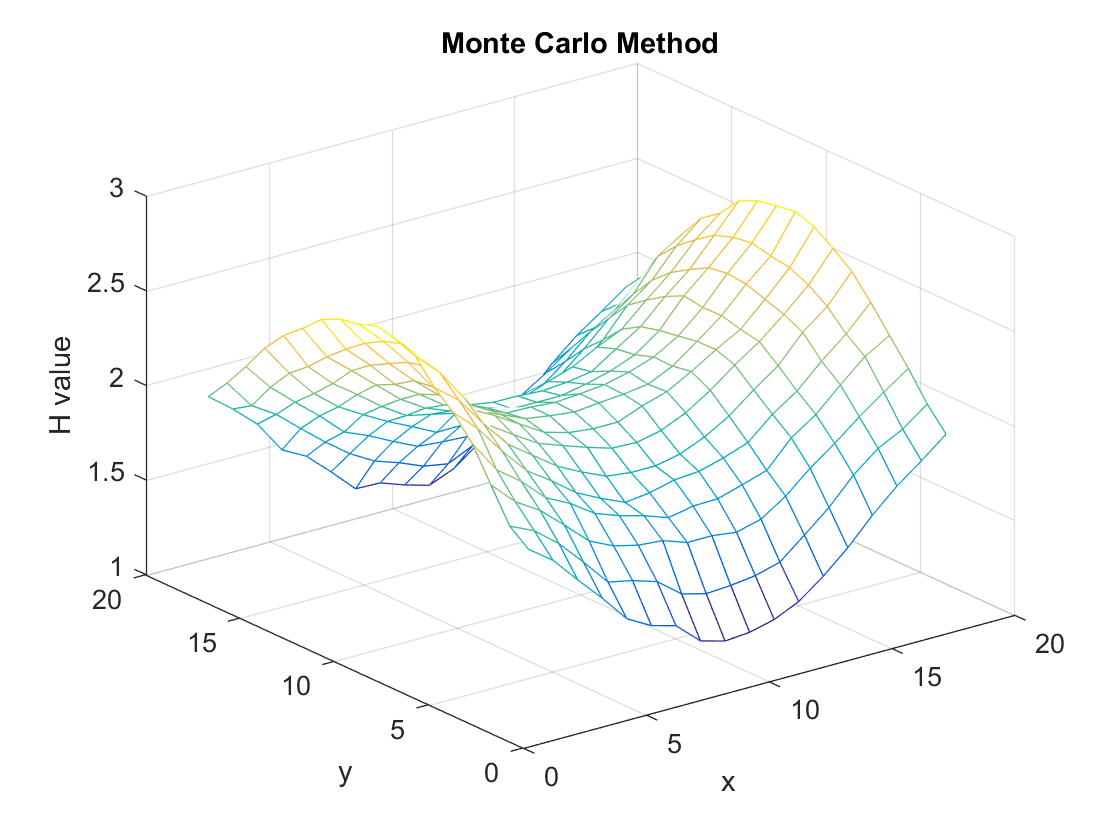
经过10000次迭代,效果还是不错的,但相比于大约250次迭代就可以计算出更加精确值的Iteration Method来说还是效率较低的。Iteration Method的本质就是Dynamic Programming,在强化学习中相对应就是马尔可夫决策——一种建立在模型,状态与状态之间关系的算法。Monte Carlo最大的优势在于,不需要模型,只靠探索+总结就可以寻找到最优策略,这比马尔可夫决策更加的趋近于人类的决策行为,真正的人工智能之强化学习是从这里开始的。
【RL系列】从蒙特卡罗方法步入真正的强化学习的更多相关文章
- 【RL系列】蒙特卡罗方法——Soap Bubble
“肥皂泡”问题来源于Reinforcement Learning: An Introduction(2017). Exercise 5.2,大致的描述如下: 用一个铁丝首尾相连组成闭合曲线,浸入肥皂泡 ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习读书笔记 - 09 - on-policy预测的近似方法
强化学习读书笔记 - 09 - on-policy预测的近似方法 参照 Reinforcement Learning: An Introduction, Richard S. Sutton and A ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习读书笔记 - 11 - off-policy的近似方法
强化学习读书笔记 - 11 - off-policy的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton and ...
- 强化学习读书笔记 - 10 - on-policy控制的近似方法
强化学习读书笔记 - 10 - on-policy控制的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton an ...
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- 【RL系列】Multi-Armed Bandit笔记——UCB策略与Gradient策略
本篇主要是为了记录UCB策略与Gradient策略在解决Multi-Armed Bandit问题时的实现方法,涉及理论部分较少,所以请先阅读Reinforcement Learning: An Int ...
随机推荐
- Apache 各启动方式的差别
apachectl 调用 $httpd -k 1. kill - TERM `cat /usr/local/apache/logs/http.pid` 2. /bin/httpd -k stop/s ...
- 闲来无事做了一个项目,内有redis,EasyUI样式简单应用,七层分页查询,API跨域。
<link href="~/jquery-easyui-1.5.3/themes/default/easyui.css" rel="stylesheet" ...
- php无限极分类处理
/** * 无限极分类处理(通过递归方式实现) * @param $section 原始数据Array * @param $html 界面显示前缀,比如 |- * @param $spear 分级中所 ...
- [jQuery]常用正则表达式
验证网址:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$电子 ...
- 【PTA 天梯赛】L3-002 特殊堆栈(二分)
堆栈是一种经典的后进先出的线性结构,相关的操作主要有“入栈”(在堆栈顶插入一个元素)和“出栈”(将栈顶元素返回并从堆栈中删除).本题要求你实现另一个附加的操作:“取中值”——即返回所有堆栈中元素键值的 ...
- Angularjs中的超时处理
关键代码: // 定义一个定时器, 设置5s为请求超时时间 var timer = $timeout(function () { console.log('登录超时!'); // 模拟提示信息 },5 ...
- 解决在 win10 下 vs2017 中创建 MFC 程序拖放文件接收不到 WM_DROPFILES 消息问题
解决方案 这个问题是由于 win10 的安全机制搞的鬼,即使以管理员权限运行也不行,因为它会把 WM_DROPFILES 消息过滤掉,那怎么办呢?只需在窗口初始化 OnInitDialog() 里添加 ...
- Linux CentOS Python开发环境搭建教程
CentOS安装Python 1.CentOS已经自带安装了2.x版本,先尝试python命令检查已安装的版本.如果你使用rpm.yum或deb命令安装过,请使用相对命令查询. 2.复制安装文件链 ...
- parted 命令学习
背景:fdisk命令是针对MBR分区进行操作,MBR分区因为自身设计原因,不能处理大于2TB的硬盘,并且只能有4个分区.针对大于2TB的硬盘,需要采用GPT分区,使用parted命令进行操作 part ...
- 最短寻道优先算法(SSTF)——磁盘调度管理
原创 最近操作系统实习,敲了实现最短寻道优先(SSTF)——磁盘调度管理的代码. 题目阐述如下: 设计五:磁盘调度管理 设计目的: 加深对请求磁盘调度管理实现原理的理解,掌握磁盘调度算法. 设计内容: ...