Zookeeper(三) Zookeeper原理与应用
一、zookeeper原理解析
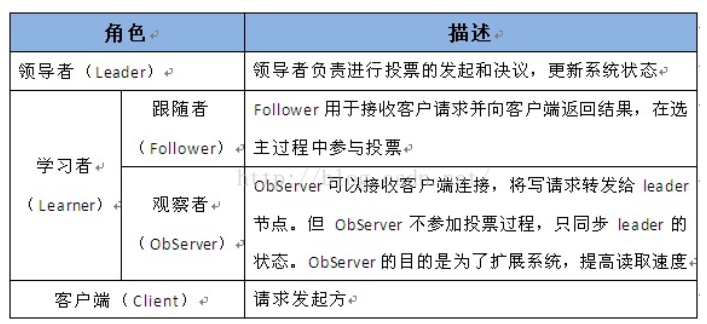
1、进群角色描述

2、Paxos 算法概述( ZAB 协议) 分布式一致性算法

3、Zookeeper 的选主(恢复模式)
以一个简单的例子来说明整个选举的过程.
假设有五台服务器组成的 zookeeper 集群,它们的 id 从 1-5,同时它们都是最新启动的,也就是 没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生 什么.
(1) 服务器 1 启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举 状态一直是 LOOKING 状态
(2)服务器 2 启动,它与最开始启动的服务器 1 进行通信,互相交换自己的选举结果,由于两者 都没有历史数据,所以 id 值较大的服务器 2 胜出,但是由于没有达到超过半数以上的服务器都 同意选举它(这个例子中的半数以上是 3),所以服务器 1,2 还是继续保持 LOOKING 状态.
(3) 服务器 3 启动,根据前面的理论分析,服务器 3 成为服务器 1,2,3 中的老大,而与上面不同的 是,此时有三台服务器选举了它,所以它成为了这次选举的 leader.
(4) 服务器 4 启动,根据前面的分析,理论上服务器 4 应该是服务器 1,2,3,4 中最大的,但是由于 前面已经有半数以上的服务器选举了服务器 3,所以它只能接收当小弟的命了.
(5) 服务器 5 启动,同 4 一样,当小弟. (如果干掉ID3,怎么重新选举 id最大的那台也就是5id)
总结: zookeeper server 的三种工作状态
LOOKING:当前 Server 不知道 leader 是谁,正在搜寻,正在选举
LEADING:当前 Server 即为选举出来的 leader,负责协调事务
FOLLOWING: leader 已经选举出来,当前 Server 与之同步,服从 leader 的命令
4、非全新集群的选举机制(数据恢复)
那么,初始化的时候,是按照上述的说明进行选举的,但是当 zookeeper 运行了一段时间之 后,有机器 down 掉,重新选举时,选举过程就相对复杂了。
需要加入数据 version、 server id 和逻辑时钟。
数据 version:数据新的 version 就大,数据每次更新都会更新 version。
Leader id:就是我们配置的 myid 中的值,每个机器一个。
逻辑时钟:这个值从 0 开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么 这个值应该是一致的 ; 逻辑时钟值越大,说明这一次选举 leader 的进程更新.
选举的标准就变成:
(1)逻辑时钟小的选举结果被忽略,重新投票
(2)统一逻辑时钟后,数据 id 大的胜出
(3)数据 id 相同的情况下, leader id 大的胜出
根据这个规则选出 leader。
二、zookeeper应用案例
1、服务器上下线动态感知
需求:某分布式系统中,主节点可以有多台,可以动态上下线。 任意一台客户端都能实时感知 到主节点服务器的上下线
设计思路:
(1) 设计服务器端存入服务器上线,下线的信息,比如都写入到 servers 节点下
(2)设计客户端监听该 servers 节点,获取该服务器集群的在线服务器列表
(3)服务器一上线,就往 zookeeper 文件系统中的一个统一的节点比如 servers 下写入一个临 时节 点,记录下服务器的信息(思考,该节点最好采用什么类型的节点?)
(4) 服务器一下线,则删除 servers 节点下的该服务器的信息,则客户端因为监听了该节点的数据变化,所以将第一时间得知服务器的在线状态
实现:
服务器端
package com.ghgj.zookeeper.mydemo;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
/**
* 用来模拟服务器的动态上线下线
* 总体思路就是服务器上线就上 zookeeper 集群创建一个临时节点,然后监听了该数据节
点的个数变化的客户端都收到通知
* 下线,则该临时节点自动删除,监听了该数据节点的个数变化的客户端也都收到通知
*/
public class DistributeServer {
private static final String connectStr = "hadoop02:2181,hadoop03:2181,hadoop04:2181";
private static final int sessionTimeout = 4000;
private static final String PARENT_NODE = "/server";
static ZooKeeper zk = null;
public static void main(String[] args) throws Exception {
DistributeServer distributeServer = new DistributeServer();
distributeServer.getZookeeperConnect();
distributeServer.registeServer("hadoop03");
Thread.sleep(Long.MAX_VALUE);
}
/**
* 拿到 zookeeper 进群的链接
*/
public void getZookeeperConnect() throws Exception {
zk = new ZooKeeper(connectStr, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
/**
* 服务器上线就注册,掉线就自动删除,所以创建的是临时顺序节点
*/
public void registeServer(String hostname) throws Exception{
Stat exists = zk.exists(PARENT_NODE, false);
if(exists == null){
zk.create(PARENT_NODE,"server_parent_node".getBytes(),Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
zk.create(PARENT_NODE+"/"+hostname, hostname.getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostname+" is online, start working......");
}
}
客户端
package com.ghgj.zookeeper.mydemo;
import java.util.ArrayList;
import java.util.List;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
/**
* 用来模拟用户端的操作:连上 zookeeper 进群,实时获取服务器动态上下线的节点信息
* 总体思路就是每次该 server 节点下有增加或者减少节点数,我就打印出来该 server 节点
下的所有节点
*/
public class DistributeClient {
private static final String connectStr = "hadoop02:2181,hadoop03:2181,hadoop04:2181";
private static final int sessionTimeout = 4000;
private static final String PARENT_NODE = "/server";
static ZooKeeper zk = null;
public static void main(String[] args) throws Exception {
DistributeClient dc = new DistributeClient();
dc.getZookeeperConnect();
Thread.sleep(Long.MAX_VALUE);
}
/**
* 拿到 zookeeper 进群的链接
*/
public void getZookeeperConnect() throws Exception {
zk = new ZooKeeper(connectStr, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
try {
// 获取父节点 server 节点下所有子节点,即是所有正上线服务的服
务器节点
List<String> children = zk.getChildren(PARENT_NODE, true);
List<String> servers = new ArrayList<String>();
for(String child: children){
// 取出每个节点的数据,放入到 list 里
String server = new String(zk.getData(PARENT_NODE+"/"+child,
false, null), "UTF-8");
servers.add(server);
}
// 打印 list 里面的元素
System.out.println(servers);
} catch (Exception e) {
e.printStackTrace();
}
}
});
System.out.println("Client is online, start Working......");
}
}
2、分布式共享锁
需求:在我们自己的分布式业务系统中,可能会存在某种资源,需要被整个系统的各台服务器共享 访问,但是只允许一台服务器同时访问
设计思路:
(1) 设计多个客户端同时访问同一个数据
(2)为了同一时间只能允许一个客户端上去访问,所以各个客户端去 zookeeper 集群的一个 znode 节点去注册一个临时节点,定下规则,每次都是编号最小的客户端才能去访问
(3)多个客户端同时监听该节点,每次当有子节点被删除时,就都收到通知,然后判断自己 的编号是不是最小的,最小的就去执行访问,不是最小的就继续监听。
代码实现:
package com.ghgj.zookeeper.mydemo;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
/**
* 需求:多个客户端,需要同时访问同一个资源,但同时只允许一个客户端进行访问。
* 设计思路:多个客户端都去父 znode 下写入一个子 znode,能写入成功的去执行访问,
写入不成功的等待
*/
public class MyDistributeLock {
private static final String connectStr = "hadoop02:2181,hadoop03:2181,hadoop04:2181";
private static final int sessionTimeout = 4000;
private static final String PARENT_NODE = "/parent_locks";
private static final String SUB_NODE = "/sub_client";
static ZooKeeper zk = null;
private static String currentPath = "";
public static void main(String[] args) throws Exception {
MyDistributeLock mdc = new MyDistributeLock();
// 1、拿到 zookeeper 链接
mdc.getZookeeperConnect();
// 2、查看父节点是否存在,不存在则创建
Stat exists = zk.exists(PARENT_NODE, false);
if(exists == null){
zk.create(PARENT_NODE, PARENT_NODE.getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
// 3、监听父节点
zk.getChildren(PARENT_NODE, true);
// 4、往父节点下注册节点,注册临时节点,好处就是,当宕机或者断开链接时该
节点自动删除
currentPath = zk.create(PARENT_NODE+SUB_NODE, SUB_NODE.getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 5、关闭 zk 链接
Thread.sleep(Long.MAX_VALUE);
zk.close();
}
/**
* 拿到 zookeeper 集群的链接
*/
public void getZookeeperConnect() throws Exception {
zk = new ZooKeeper(connectStr, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 匹配看是不是子节点变化,并且监听的路径也要对
if(event.getType() == EventType.NodeChildrenChanged &&
event.getPath().equals(PARENT_NODE)){
try {
// 获取父节点的所有子节点, 并继续监听
List<String> childrenNodes = zk.getChildren(PARENT_NODE, true);
// 匹配当前创建的 znode 是不是最小的 znode
Collections.sort(childrenNodes);
if((PARENT_NODE+"/"+childrenNodes.get(0)).equals(currentPath)){
// 处理业务
handleBusiness(currentPath);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
}
public void handleBusiness(String create) throws Exception{
System.out.println(create+" is working......");
Thread.sleep(new Random().nextInt(4000));
zk.delete(currentPath, -1);
System.out.println(create+" is done ......");
currentPath = zk.create(PARENT_NODE+SUB_NODE, SUB_NODE.getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
}
补充:监听机制案例
package com.ghgj.zkapi; import java.io.IOException;
import java.util.List; import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.ZooDefs.Ids; public class ZKAPIDEMOWatcher { // 获取zookeeper连接时所需要的服务器连接信息,格式为主机名:端口号
private static final String ConnectString = "hadoop02:2181"; // 请求了解的会话超时时长
private static final int SessionTimeout = 5000; private static ZooKeeper zk = null;
static Watcher w = null;
static Watcher watcher = null; public static void main(String[] args) throws Exception { watcher = new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getPath() + "\t-----" + event.getType());
List<String> children;
try {
if (event.getPath().equals("/spark") && event.getType() == EventType.NodeChildrenChanged) {
// zk.setData("/spark", "spark-sql".getBytes(), -1);
System.out.println("数据更改成功 ~~~~~~~~~~~~~~~~~~");
children = zk.getChildren("/spark", watcher);
}
if (event.getPath().equals("/spark") && event.getType() == EventType.NodeDataChanged) {
// zk.setData("/spark", "spark-sql".getBytes(), -1);
System.out.println("数据更改成功 ¥##########");
zk.getData("/spark", watcher, null);
}
if (event.getPath().equals("/mx") && event.getType() == EventType.NodeChildrenChanged) {
// zk.setData("/mx", "spark-sql".getBytes(), -1);
System.out.println("数据更改成功 ---------");
children = zk.getChildren("/mx", watcher);
} } catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
}; zk = new ZooKeeper(ConnectString, SessionTimeout, watcher); zk.getData("/spark", true, null);
zk.getChildren("/spark", true);
zk.getChildren("/mx", true);
zk.exists("/spark", true); 自定义循环自定义
w = new Watcher() {
@Override
public void process(WatchedEvent event) {
try {
zk.getData("/hive", w, null);
System.out.println("hive shuju bianhua ");
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}; zk.getData("/hive", w, null); // zk.setData(path, data, version); // 表示给znode /ghgj 的数据变化事件加了监听
// 第二个参数使用true还是false的意义就是是否使用拿zookeeper链接时指定的监听器
// zk.getData("/ghgj", true, null);
// zk.setData("/ghgj", "hadoophdfs2".getBytes(), -1); /*
* zk.getData("/sqoop", new Watcher(){
*
* @Override public void process(WatchedEvent event) {
* System.out.println("**************");
* System.out.println(event.getPath()+"\t"+event.getType()); } }, null);
*/
// zk.setData("/sqoop", "hadoophdfs3".getBytes(), -1); //
// NodeDataChanged
// zk.delete("/sqoop", -1); // NodeDeleted
// zk.create("/sqoop/s1", "s1".getBytes(), Ids.OPEN_ACL_UNSAFE,
// CreateMode.PERSISTENT); // zk.exists("/hivehive", new Watcher(){
// @Override
// public void process(WatchedEvent event) {
// System.out.println("**************");
// System.out.println(event.getPath()+"\t"+event.getType());
// }
// }); // create方法
// zk.create("/hivehive", "hivehive".getBytes(), Ids.OPEN_ACL_UNSAFE,
// CreateMode.PERSISTENT);
// zk.delete("/hivehive", -1);
// zk.setData("/hivehive", "hadoop".getBytes(), -1); // 需求:有一个父节点叫做/spark,数据是spark,当父节点/spark下有三个子节点,
// 那么就把该父节点的数据改成spark-sql
// zk.create("/spark", "spark".getBytes(), Ids.OPEN_ACL_UNSAFE,
// CreateMode.PERSISTENT); /*
* zk.getChildren("/spark", new Watcher() {
*
* @Override public void process(WatchedEvent event) { try {
* List<String> children = zk.getChildren("/spark", true);
* if(children.size() == 3){
*
* } zk.setData("/spark", "spark-sql".getBytes(), -1);
* System.out.println("数据更改成功"); } catch (KeeperException |
* InterruptedException e) { e.printStackTrace(); } } });
*/ Thread.sleep(Long.MAX_VALUE); zk.close();
}
}
Zookeeper(三) Zookeeper原理与应用的更多相关文章
- zookeeper初识之原理
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper是hadoop的一个子项目 ...
- zookeeper[2] zookeeper原理(转)
转自:http://cailin.iteye.com/blog/2014486 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现 ...
- zookeeper使用跟原理
zookeeper使用和原理 zookeeper介绍zookeeper是一个为分布式应用提供一致性服务的软件,它是开源的Hadoop项目中的一个子项目,并且根据google发表的<The Chu ...
- zookeeper应用与原理学习总结
一.什么是zookeeper Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群 ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- 我读《从Paxos到zookeeper分布式一致性原理与实践》
从年后拿到这本书开始阅读,到准备系统分析师考试之前,终于读完了一遍,对Zookeeper有了一个全面的认识,整本书从理论到应用再到细节的阐述,内容安排从逻辑性和实用性上都是很优秀的,对全面认识Zook ...
- Zookeeper选举算法原理
Zookeeper选举算法原理 Leader选举 Leader选举是保证分布式数据一致性的关键所在.当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举. (1) 服 ...
- ZooKeeper(3)-内部原理
一. 节点类型 二. Stat结构体 1)czxid-创建节点的事务zxid 每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID. 事务ID是ZooKee ...
- zookeeper概念与原理
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. 1 Zookeeper的基本概念 1.1 角色 ...
随机推荐
- vbox虚拟机扩容(CentOS 7.2)
Preface My virtual machine was simply created by vagrant in default mode without anything about th ...
- Http协议工作特点和工作原理笔记
工作特点: (1)B/S结构(Browser/Server,浏览器/服务器模式) (2)无状态 (3)简单快速.可使用超文本传输协议.灵活运行传输各种类型 工作原理: 客户端发送请求浏览器 -> ...
- jenkens其实是代码上传工具
Jenkins 持续集成使用教程 用 jenkins 有什么好处 通过规范化来完成,简单,繁琐,浪费时间的重复工作 规范化工作,以免出现低级错误 实现随时随地任何人一键构建 ...... 安装 jen ...
- 在进行分布式框架搭建的过程中,出现问题advised by org.springframework.transaction.interceptor.TransactionInterceptor.invoke(org.aopalliance.intercept.MethodInvocation)?
今天在进行宜立方商城,进行文件配置的时间,遇到如下的问题,问题是:advised by org.springframework.transaction.interceptor.TransactionI ...
- 在Windows2008下添加iscsi存储出现磁盘Offine(The disk is offine because of policy set by an adminstrator)的解决方法
打开CMD命令行输入如下命令: DISKPART.EXE DISKPART> san SAN Policy : Offline Shared DISKPART> san policy=On ...
- Ubuntu系统下在PyCharm里用virtualenv集成TensorFlow
我的系统环境 Ubuntu 18.04 Python3.6 PyCharm 2018.3.2 community(免费版) Java 1.8 安装前准备 由于众所周知的原因,安装中需要下载大量包,尽量 ...
- ExpressJS基础概念及简单Server架设
NodeJS Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境.Node.js 使用了一个事件驱动.非阻塞式 I/O 的模型,使其轻量又高效.Node.js 的包 ...
- Web全景图的原理及实现
全景图的基本原理 全景图是一种广角图.通过全景播放器可以让观看者身临其境地进入到全景图所记录的场景中去.比如像是这个.这种看起来很高大上的效果其实背后的原理并不复杂. 通常标准的全景图是一张2:1的图 ...
- Android 中调用本地命令
Android 中调用本地命令 通常来说,在 Android 中调用本地的命令的话,一般有以下 3 种情况: 调用下也就得了,不管输出的信息,比如:echo Hello World.通常来说,这种命令 ...
- 软件工程 speedsnail 第二次冲刺10
20150527 完成任务:蜗牛碰到线后速度方向的调整:已经基本实现多方向的反射: 遇到问题: 问题1 反射角的问题 解决1 利用tan()三角函数 明日任务: 大总结.找到新问题.布置下一次冲刺方案