浴谷八连测R6题解(收获颇丰.jpg)
这场的题都让我收获颇丰啊QWQ 感谢van♂老师
T1 喵喵喵!当时以为经典题只能那么做, 思维定势了...
因为DP本质是通过一些条件和答案互相递推的一个过程, 实际上就是把条件和答案分配在DP的状态和结果中, 所以当条件数值非常大, 而答案比较小的时候, 完全可以将答案放在DP数组的状态中,用来递推条件, 如果这个条件合法, 那么表明这个答案是可行的。
在这题里面, 答案不会超过b串的长度, 而a串的长度可以非常长, 所以可以设f[i][j]为b串中前i个字符, 匹配了j为在a串中的最前位置是什么, 用序列自动机处理出nxt[i][x]为a串第i位的下一个x字符的位置,就很好转移了。
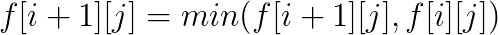
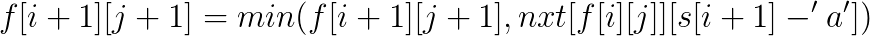
#include<iostream>
#include<cstring>
#include<cstdlib>
#include<cstdio>
#include<algorithm>
#define ll long long
using namespace std;
const int maxn=,inf=1e9;
int n1, n2, ans;
int f[maxn][maxn], last[], nxt[][];
char s1[], s2[maxn];
void read(int &k)
{
int f=;k=;char c=getchar();
while(c<''||c>'')c=='-'&&(f=-),c=getchar();
while(c<=''&&c>='')k=k*+c-'',c=getchar();
k*=f;
}
inline int max(int a, int b){return a>b?a:b;}
inline int min(int a, int b){return a<b?a:b;}
int main()
{
scanf("%s", s1+); scanf("%s", s2+);
int n1=strlen(s1+), n2=strlen(s2+);
memset(f,,sizeof(f)); f[][]=;
for(int i=;i<;i++) last[i]=inf;
for(int i=n1;i>=;i--)
{
for(int j=;j<;j++) nxt[i][j]=last[j];
if(i) last[s1[i]-'a']=i;
}
for(int i=;i<=n2;i++)
for(int j=;j<=i;j++)
if(f[i][j]<=n1)
{
f[i+][j]=min(f[i+][j], f[i][j]);
f[i+][j+]=min(f[i+][j+], nxt[f[i][j]][s2[i+]-'a']);
ans=max(ans, j);
}
printf("%d\n", ans);
return ;
}
T2 也是道非常好的DP...
可以发现一个点至少被一个区间覆盖, 至多被两个区间覆盖,且区间必须相互覆盖, 因为是树不是森林。考虑区间覆盖的样子, 实际上是一些大区间下面覆盖着一些小区间, 所以可以考虑分类来转移。
先预处理出第i个位置的下一个左端点大于i的区间nxt[i], 设f[i][j]为前i个区间, 选择的区间最右端点为j的方案数, 如果当前区间左端点在j或j左边才可转移, 若当前区间为大区间(a[i].r>=j), 则有
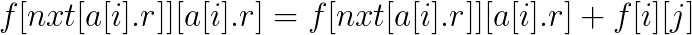
若当前区间为小区间(a[i].r<j), 则有
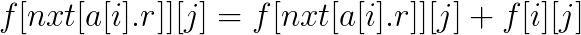
注意刷表法如果是用i这个位置更新答案的话最后的答案应该为f[n+1][]。
喵啊, 真的喵喵
#include<iostream>
#include<cstring>
#include<cstdlib>
#include<cstdio>
#include<cmath>
#include<algorithm>
#define MOD(x) ((x)>=mod?(x)-mod:(x))
using namespace std;
const int maxn=, mod=1e9+;
struct poi{int l,r;}a[maxn];
int n, ans;
int f[maxn][], nxt[];
inline void read(int &k)
{
int f=; k=; char c=getchar();
while(c<'' || c>'') c=='-'&&(f=-), c=getchar();
while(c<='' && c>='') k=k*+c-'', c=getchar();
k*=f;
}
bool cmp(poi a, poi b){return a.l<b.l;}
int main()
{
read(n);
for(int i=;i<=n;i++) read(a[i].l), read(a[i].r);
sort(a+, a++n, cmp);
for(int i=, j=;i<=;nxt[i++]=j)
while(j<=n && a[j].l<=i) j++;
a[n+].r=n+;
for(int i=;i<=n;i++) f[i+][a[i].r]=;
for(int i=;i<=n;i++)
for(int j=;j<=;j++)
{
f[i+][j]+=f[i][j]; f[i+][j]=MOD(f[i+][j]);
if(a[i].l<=j)
{
if(a[i].r<j) f[nxt[a[i].r]][j]+=f[i][j], f[nxt[a[i].r]][j]=MOD(f[nxt[a[i].r]][j]);
else f[nxt[j]][a[i].r]+=f[i][j], f[nxt[j]][a[i].r]=MOD(f[nxt[j]][a[i].r]);
}
}
for(int i=;i<=;i++) ans=MOD(ans+f[n+][i]);
printf("%d\n", ans);
return ;
}
T3 也喵喵喵...第一次见到这种姿势!
分阈值分块做!设一个阈值B, 分公差x<B和>=B两种情况
如果公差>=B, 可以直接暴力修改。因为当公差较大的时候, 修改复杂度会非常小, 这时候可以用O(n/B)修改, O(sqrt(n))查询的分块来做, 如果B定为sqrt(n),那肯定是可以承受的复杂度。
如果公差<B, 先说说80分的做法。
80分算法1:直接记录首项为y, 公差为x的被加了多少, 我们知道这些标记之后, 完全可以用数学方法O(1)算出区间[l, r]种这个标记出现了几次, 下面会提到怎么计算。这样的话修改O(1), 因为最多有B^2种标记, 所以查询是O(B^2)的。考虑平衡一下<B和>=B的情况, 应该尽量让它们相等, 即n/B=B^2, 所以将B定为n^(1/3), 复杂度为O(n^(5/3))的, 可以通过80分的数据。
80分算法2:可以发现一个公差为y的标记, 无论首项是多少, 在区间[l,r]最多只有两种取值, 因为考虑首项+1, 最多会有一个数被移出去, 而在接下来的移动中, 下一个数被移出去之前必定有一个新的从前面加入。考虑使用树状数组来维护区间和这时候我们用前面提到的数学方法来计算这些区间,具体方法下面再细说...将B定为sqrt(n)这样复杂度为O(nsqrtnlogn)
100分做法...
发现我们前两种做法的修改复杂度都较低, 而主要复杂度在查询上, 可以考虑提高修改复杂度使得查询复杂度降低, 有什么做法是修改复杂度高而查询复杂度低的呢?对了, 前缀和!tag[x][y]表示公差为x, 首项y~x的标记和, 这样每次修改的复杂度为O(B), 查询的时候枚举公差, 用数学方法O(1)算出这个公差的答案, 复杂度O(B), 考虑上<B时的常数比较大, 所以将B定为sqrt(n/5)就可以过了...现在终于来说说所谓的数学方法...考虑80分算法1所提到的一个区间中同个公差的标记只有2种, 而取值较小的那种用r/i和(l-1)/i相减就可以求得了, 这个还是很好推的。思考一下什么时候取值会变大,就是当新的一个数进入区间开始, 到下一个数离开区间结束, 中间这一段会比另一个取值多1, 而新的一个数进入区间就是首项为x+k*i和l重合开始, 末项y+k*i和r重合结束, 也就是首项在[l%i, r%i]的时候。所以我们只需要加上所有首项的答案, 最后再加上一次首项在[l%i, r%i]这一段的答案就好了。即tag[i][i]*(r/i-(l-1)/i)+tag[i][r]-tag[i][l-1]即为答案。
#include<iostream>
#include<cstring>
#include<cstdlib>
#include<cstdio>
#include<cmath>
#include<algorithm>
#define MOD(x) ((x)>=mod?(x)-mod:(x))
using namespace std;
const int maxn=, mod=1e9+;
int n, m, ty, x, y, z, blo;
int tag[][maxn], a[maxn], s[maxn], bl[maxn];
inline void read(int &k)
{
int f=; k=; char c=getchar();
while(c<'' || c>'') c=='-'&&(f=-), c=getchar();
while(c<='' && c>='') k=k*+c-'', c=getchar();
k*=f;
}
void update(int x, int y, int z)
{
if(x>=blo)
for(int i=y;i<=n;i+=x) a[i]+=z, a[i]=MOD(a[i]), s[bl[i]]+=z, s[bl[i]]=MOD(s[bl[i]]);
else
for(int i=y;i<=x;i++) tag[x][i]+=z, tag[x][i]=MOD(tag[x][i]);
}
inline int min(int a, int b){return a<b?a:b;}
inline int query(int l, int r)
{
int up=min(bl[l]*blo, r), ans=;
for(int i=l;i<=up;i++) ans+=a[i], ans=MOD(ans);
if(bl[l]!=bl[r])
for(int i=(bl[r]-)*blo+;i<=r;i++) ans+=a[i], ans=MOD(ans);
for(int i=bl[l]+;i<=bl[r]-;i++) ans+=s[i], ans=MOD(ans);
for(int i=;i<=blo;i++)
{
int x=r/i-(l-)/i;
ans=(ans+1ll*x*tag[i][i]+tag[i][r%i]-tag[i][(l-)%i]+mod)%mod;
}
return ans;
}
int main()
{
read(n); read(m); blo=sqrt(n/);
for(int i=;i<=n;i++) bl[i]=(i-)/blo+;
for(int i=;i<=n;i++) read(a[i]);
for(int i=;i<=n;i++) s[bl[i]]+=a[i], s[bl[i]]=MOD(s[bl[i]]);
for(int i=;i<=m;i++)
{
read(ty); read(x); read(y);
if(ty==) read(z), update(x, y, z);
else printf("%d\n", query(x, y));
}
}
浴谷八连测R6题解(收获颇丰.jpg)的更多相关文章
- 洛谷10月月赛R2·浴谷八连测R3题解
早上打一半就回家了... T1傻逼题不说了...而且我的写法比题解要傻逼很多T T T2可以发现,我们强制最大值所在的块是以左上为边界的倒三角,然后旋转4次就可以遍历所有的情况.所以二分极差,把最大值 ...
- 浴谷八连测R4题解
一开始出了点bug能看见排行榜,于是我看见我半个小时就A掉了前两题,信心场QAQ T1字符串题就不说了qwq #include<iostream> #include<cstring& ...
- 洛谷八连测R5题解
woc居然忘了早上有八连测T T 还好明早还有一场...今天的题除了T3都挺NOIP的... T1只需要按横坐标第一关键字,纵坐标第二关键字排序一个一个取就好了... #include<iost ...
- 洛谷八连测R6
本次测试暴0!!!还有两周就要考试啦!!! 看题目时觉得难度不大,就直接写正解,没有参照数据,导致测出的结果和预想有较大差距. 不过得到经验,不管题目难易(除了D1T1)都要参照数据一部分一部分写,那 ...
- 洛谷八连测R4
1.逃避 https://www.luogu.org/problemnew/show/T14561 注意: 1.输入时需要用EOF判断,否则会TLE. 2.用flag判断字符是不是每一句首字母. 3. ...
- 从头捋了一遍 Java 代理机制,收获颇丰
尽人事,听天命.博主东南大学硕士在读,热爱健身和篮球,乐于分享技术相关的所见所得,关注公众号 @ 飞天小牛肉,第一时间获取文章更新,成长的路上我们一起进步 本文已收录于 「CS-Wiki」Gitee ...
- 误入 GitHub 游戏区,意外地收获颇丰
这天中午,我和往常一样就着美食视频吃完午饭,然后起身泡了一杯"高沫". 我闻着茶香享受着午后的阳光,慵懒地坐在工位上习惯性的打开 GitHub 游荡,酝酿着睡意. 误打误撞,我来到 ...
- 一位前辈的博客,收获颇丰,包括Android、Java、linux、前端、大数据、网络安全等等
https://www.cnblogs.com/lr393993507/ 魔流剑
- 洛谷P2832 行路难 分析+题解代码【玄学最短路】
洛谷P2832 行路难 分析+题解代码[玄学最短路] 题目背景: 小X来到了山区,领略山林之乐.在他乐以忘忧之时,他突然发现,开学迫在眉睫 题目描述: 山区有n座山.山之间有m条羊肠小道,每条连接两座 ...
随机推荐
- Java普通编程和Web网络编程准备工作
一.工具下载 链接:https://pan.baidu.com/s/1geOdq3h 密码:pzl5 二.Java普通编程 解压下载的资料,并按readme.txt安装jdk和Eclipse. 三.J ...
- JUC——TimeUnit工具类(二)
TimeUnit工具类 在java.util.concurrent开发包里面提供有一个TimeUnit类,这个类单独看它的描述是一个时间单元类.该类是一个枚举类,这也是juc开包里面唯一的一个枚举类. ...
- Unity —— 通过鼠标点击控制物体移动
//ClickMove - - 通过鼠标点击控制物体移动 using System.Collections; using System.Collections.Generic; using Unity ...
- Halcon如何保存仿射变换矩阵
这里我们通过序列化来实现的,如下图,写到硬盘的HomMat2D_1内容和从硬盘里HomMat2D_2读出的内容一致,源代码在图片下方. Halcon源代码: hom_mat2d_identity (H ...
- 【RL系列】蒙特卡罗方法——Soap Bubble
“肥皂泡”问题来源于Reinforcement Learning: An Introduction(2017). Exercise 5.2,大致的描述如下: 用一个铁丝首尾相连组成闭合曲线,浸入肥皂泡 ...
- spark-local-运行异常-Could not locate executable null\bin\winutils.exe in the Hadoop binaries
windows下-local模式-运行spark: 1.下载winutils的windows版本 GitHub上,有人提供了winutils的windows的版本,项目地址是:https://gith ...
- Github二次学习
作者声明:本博客中所写的文章,都是博主自学过程的笔记,参考了很多的学习资料,学习资料和笔记会注明出处,所有的内容都以交流学习为主.有不正确的地方,欢迎批评指正. 本节课视频内容:https://www ...
- loadrunner11--基础使用
每次开启电脑都需要破解一次Lr,汉化版的有问题,建议使用英文版的.我测试的环境是Windows7+IE8+LR11.(在Windows10上试过,谷歌和IE11都不能正常运行),以下我会具体来操作,最 ...
- Alpha发布用户使用报告
此作业要求参见:[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2325] 组名:可以低头,但没必要 组长:付佳 组员:张俊余 李文涛 孙 ...
- 软工第十二周个人PSP
11.30--12.6本周例行报告 1.PSP(personal software process )个人软件过程. C(类别) C(内容) ST(开始时间) ET(结束时间) INT(间隔时间) Δ ...