【翻译】MongoDB指南/CRUD操作(四)
【原文地址】https://docs.mongodb.com/manual/
CRUD操作(四)
1 查询方案(Query Plans)
MongoDB 查询优化程序处理查询并且针对给定可利用的索引选择最有效的查询方案。然后每次执行查询时,查询系统使用此查询方案。
查询优化程序仅缓存可能有多种切实可行的方案的查询计划。
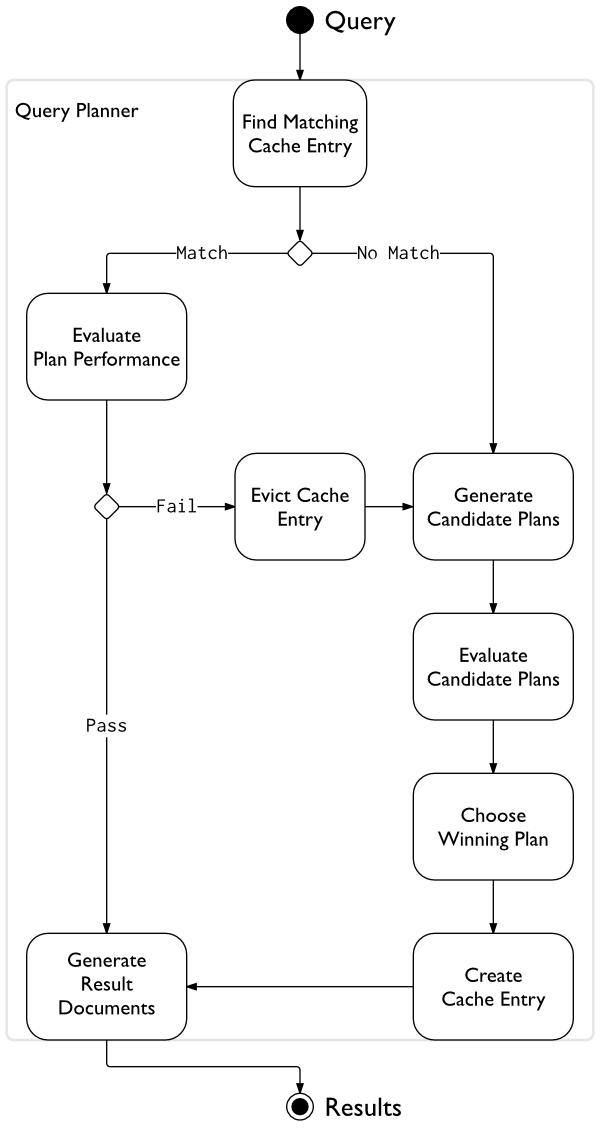
对于每一个查询,查询规划者在查询方案高速缓存中搜索适合查询形式的查询方案。如果没有匹配的查询方案,查询规划者生成几个备选方案并在一个实验周期内做出评估。查询规划者选择获胜的方案,创建包含获胜方案的高速缓存条目,并使用它获得查询结果文档。
如果匹配条目存在,查询规划者基于匹配条目生成一个方案,通过重新规划方案机制评估此方案的性能。这个机制会根据此查询方案的性能做出通过或否决的决定并保持或者剔除此查询方案。如果此方案被剔除,那么查询计划会使用一般规划进程选择一个新方案并缓存它。查询规划者执行这个方案并返回查询结果。
下面这个图说明了查询规划者的处理逻辑:
你可以使用db.collection.explain()或者cursor.explain()方法查看给定查询的查询方案。这些信息有助于定出索引策略。
db.collection.explain() 提供了其他操作的执行信息,例如db.collection.update()操作。
查询方案高速缓存刷新
像索引或者删除集合这样的目录操作会刷新查询方案高速缓存。
如果mongod 重启或者关闭,查询高速缓存会被刷新。
2.6版本中,MongoDB 提供了查询缓存方法来查看和修改缓存的查询计划。PlanCache.clear()方法会刷新整个查询高速缓存。
使用PlanCache.clearPlansByQuery()可清空指定的查询计划缓存。
索引过滤器
2.6版本中新增。
索引过滤器决定了由优化程序评估出的索引中哪些供查询模型使用。一个查询模型由查询、排序、投影规范的组合构成。如果一个给定的查询模型中存在索引过滤器,优化程序只考虑索引过滤器中指定的那些索引。
当查询模型中存在索引过滤器时,MongoDB 忽略hint()方法。为了查看是否在查询模型中使用了索引过滤器,查看执行db.collection.explain() 或
cursor.explain()方法返回文档中的字段indexFilterSet 。
索引过滤器仅作用于优化程序评估出的那些索引;对于一个给定的索引模型,优化程序可能仍会扫描那一集合作为获胜的方案。
索引过滤器存在于服务器执行操作的过程中并且关机后不会被保留。MongoDB 也提供了手动移除过滤器的命令。
因为索引过滤器优先于优化程序的预期行为和hint() 方法,所以谨慎地使用索引过滤器。
2 查询优化(Query Optimization)
通过减少读操作处理的数据量,索引改进了读操作的效率。这简化了MongoDB中与查询有关的工作。
2.1 创建索引以支持读操作
如果你的应用查询集合中的特定字段或一系列字段,那么被查询字段上的索引或者一系列被查询字段上的联合索引(compound index)能够防止查询过程中对整个集合进行扫描。
例子
一个应用查询集合inventory 中的字段type ,字段type的值是由用户驱动的。
var typeValue = <someUserInput>;
db.inventory.find( { type: typeValue } );
为了提高性能,集合inventory 中的字段type上创建升序或降序索引。在mongo shell中可使用db.collection.createIndex()方法创建索引。
db.inventory.createIndex( { type: 1 } )
索引能够阻止扫描整个inventory集合。
为了分析查询性能,请看查询性能分析这一节。
另外,为了优化读操作,索引支持排序操作和考虑更有效的存储利用。
对于单字段索引,选择升序还是降序排序是不重要的。而对于复合索引是重要的。
2.2查询选择性
查询选择性涉及到了查询谓词怎样排除或过滤掉集合中的文档。查询选择性能够决定查询是否有效的利用索引或根本不使用索引。
更具选择性的查询匹配到的文档比例更小。例如_id 字段的相等匹配条件具有很高的选择性,因为它最多能匹配到一个文档。
选择性越低的查询匹配到的文档比例越大。选择性低的查询不能有效地利用索引甚至不能利用索引。
例如,不相等操作符$nin 和$ne不是更具选择性的,因为它们通常匹配到了已索引的大部分数据。结果,在很多情况下,使用$nin 或$ne操作符查询已索引的数据没有必须扫描集合中所有文档效率高。
正则表达式的选择性取决于表达式本身。
2.3覆盖查询
覆盖查询是这样一种查询,使用一个索引就可以满足查询需求并且不必检查任何文档。当同时满足下面两个条件时,一个索引就能满足查询需要:
- 查询使用的所有字段都是一个索引的一部分。
- 查询返回结果文档中的所有字段都具有相同的索引。
例如,集合inventory 中的字段type 和item具有下面的索引:
db.inventory.createIndex( { type: 1, item: 1 } )
索引会覆盖下面的操作,查询type 和item,并只返回item。
db.inventory.find(
{ type: "food", item:/^c/ },
{ item: 1, _id: 0 }
)
对于指定索引用于覆盖查询,投影器文档必须明确指定_id: 0 以便从结果集中排除_id字段,因为上面创建的索引不包含_id字段。
性能
因为索引包含了查询所需全部字段,所以使用一个索引MongoDB就能即匹配查询条件又可以返回所需结果。
仅查询那个索引比查询那个索引之外的文档要快得多。索引键通常都比目录文档要小的多,索引键通常在内存中或连续地存储于磁盘上。
限制
索引字段上的限制
如果出现下面的情况,一个索引就不能够覆盖一个查询:
集合中有一个文档包含一个数组类型的字段。如果有一个字段是数组,那么这个索引就变成了多键值索引(multi-key index)并且其不支持覆盖查询。
查询谓词中的字段或者投影器返回字段是嵌入式文档字段。例如,下面的集合users :
{ _id: 1, user: { login: "tester" } }
集合有下面的索引:
{ "user.login": 1 }
因为{ "user.login": 1 }为嵌入式文档字段上的索引,所以不能覆盖查询。
db.users.find(
{ "user.login": "tester" }, { "user.login": 1, _id: 0 }
)
上面这个查询仍然可以使用{ "user.login": 1 }索引来找到匹配的文档,但是它会检测并获取检索所需文档。
分片集合上的限制
当运行一个mongos ,索引不能覆盖分片集合上的查询,如果索引不包含片键,但对_id索引有如下例外:如果查询分片集合仅仅指定关于_id字段的查询条件并且仅返回_id字段,那么运行一个mongos ,即使_id字段不是片键,_id索引也能覆盖查询。
3.0版本的变化:之前的版本运行一个mongos,一个索引不能覆盖一个分片集合上的查询。
解释
为了确定一个查询是否是覆盖查询,可使用db.collection.explain() 或explain() 方法,并查看返回结果(results)。
2.4 评估当前操作的性能
使用数据库分析器评估当前操作的性能
MongoDB 提供了数据库分析器来展现每一个操作的特性。使用数据库分析器加载当前运行缓慢的查询或者写操作。例如,你可以利用这些信息决定创建何种索引。
使用db.currentOp()评估mongod操作
db.currentOp() 方法给出一个关于运行在mongod实例上的操作的性能报告。
使用explain 评估查询性能
cursor.explain() 和db.collection.explain()方法返回查询执行的信息,例如MongoDB 选出的完成查询和执行统计的索引。你可以选择
queryPlanner 模式, executionStats 模式, 或allPlansExecution 模式来执行上述两个方法以控制返回的信息量。
例如:
在mongo shell中,使用cursor.explain() 和 查询条件{ a: 1 }在集合records中查找文档:
db.records.find( { a: 1 } ).explain("executionStats")
2.5 优化查询性能
创建索引支持查询
为普通查询创建索引。如果一个查询检索多个字段,那么创建复合索引(compound index)。扫描索引比扫描集合更快。索引结构比文档引用小,文档引用按一定的顺序存储。
例子
如果有一个集合posts包含博客,并经常检索author_name字段且此字段需排序,那么可通过创建author_name字段上的索引来提高性能:
db.posts.createIndex( { author_name : 1 } )
例子
如果经常检索timestamp 字段且此字段需排序,那么可通过创建timestamp 字段上的索引来提高性能:
创建索引:
db.posts.createIndex( { timestamp : 1 } )
优化查询:
db.posts.find().sort( { timestamp : -1 } )
因为MongoDB 能按升序或降序读取索引,所以单一键值索引方向无关紧要。
索引支持查询、更新操作和聚合管道(aggregation pipeline)的某些阶段。
索引键值是BinData 类型的数据,如果满足下面的条件这样的键值会更高效地存储在索引中:
- 二进制子类型值为0-7 或128-135。
- 字节数组的长度是0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 12, 14, 16, 20, 24, 或32。
限制返回查询结果数据量以减少网络需求
MongoDB 游标返回成组的文档。如果你知道想要的结果的数量,可以使用limit() 方法来减少对网络资源的需求。
这常常和排序操作一起用。例如,需要返回10个结果,执行如下命令:
db.posts.find().sort( { timestamp : -1 } ).limit(10)
使用投影器仅返回必要的数据
当你只需要文档字段的子集时,仅返回需要的字段可获得更好的性能:
例如,在你的查询中你只需要timestamp, title, author, 和abstract 字段,执行下面的命令:
Db.posts.find
(
{},
{ timestamp : 1 , title : 1 , author : 1 , abstract : 1}
).sort( { timestamp : -1 })
使用$hint选择一个特定的索引
大多数情况下,查询优化器会为指定操作选择最优的索引。然而可使用hint()方法强制MongoDB 使用指定索引。使用hint() 支持性能测试,或者用于必须选择一个字段的查询,或者用于必须选择被包含在几个索引中的字段的查询。
使用增量操作符来执行服务端的操作
使用MongoDB 的$inc操作符来增加或者减小文档中的值。增量操作符在服务器端增加字段值,一个可替代的方案是,选择一个文档并在客户端修改它,然后将整个文档写入服务器。
$inc 还能够帮助防止竞态条件,竞态条件能导致当两个应用实例同时查询一个文档时,手动地修改一个字段然后同时将文档写入服务器。
2.6 写操作性能
2.6.1 索引
插入,更新,或者删除操作完成以后,MongoDB 必须更新每一个和集合有关的索引,除数据本身以外。因此对于写操作的性能来讲,集合中的每一个索引都增加了大量的开销。一般来讲,索引使读操作性能有所提高,这对插入操作的性能损害是值得的。然而为了提高写操作的性能,创建索引和评估已存在的索引以确保查询可以利用这些索引时要慎重。
对于插入和更新非索引字段,稀疏索引(sparse indexes)比非稀疏索引开销小。对于非稀疏索引,不会改变记录大小的更新操作有更小的索引开销。
2.6.2 文档规模变大和MMAPv1存储引擎
某些更新操作会使文档变大;例如,向文档中添加一个字段。
对于MMAPv1 存储引擎,如果更新操作使得一个文档超过了当前已分配的大小,那么为了保存文档,MongoDB 会重新定位文档使其获得足够的连续磁盘空间。需要重定位的更新比不需要重定位的更新更耗时,特别是对于有索引的集合。如果集合有索引,MongoDB 必须更新所有索引条目。因此,对于有大量索引的集合而言,这个动作影响了写操作的吞吐量。
3.0.0版本的变化:默认地MongoDB 使用2的幂次大小配额策略来自动地为MMAPv1存储引擎填充。2的幂次大小配额策略确保MongoDB为文档分配的存储空间大小为2的幂,这有助于确保MongoDB 能够有效地重用由删除文档或者重定位文档所释放的空间,同时减少许多情况下重新分配空间的发生。
尽管 2的幂次大小配额策略减少了重新分配空间的发生,但并没有消除为文档重新分配空间。
2.6.3存储性能
硬件
存储系统的容量对MongoDB 写操作的性能产生了一些重要的物理限制。与驱动器存储系统有关的许多独特因素影响了写操作性能,包括随机访问模式,磁盘高速缓存,磁盘预读和RAID配置。
对于随机任务负载,固态硬盘(SSDs)的性能比机械硬盘(HDDs)的性能好100倍以上。
日志
为了在事故发生时提供持久性,MongoDB 采用预写日志策略将日志写入磁盘。MongoDB 首先将内存变化写入磁盘日志文件。如果在将变更写入磁盘数据文件之前,MongoDB应该终止或遇到错误,MongoDB能够使用日志文件来执行写操作将变更数据写入磁盘。
日志提供的持久性保障通常比额外的写操作带来的性能损耗重要,考虑下面的日志和性能之间的相互影响:
- 如果日志和数据文件在同一块设备上,数据文件和日志可能不得不为获得有限数量的可用I/O资源而竞争。把日志移到单独的设备上可能会增加写操作的能力。
- 如果应用指定的write concerns包含j选项,mongod 会减少日志写入之间的持续时间,这在整体上增加了写操作的负担。
- 日志写操作之间的持续时间可以通过运行时选项commitIntervalMs来配置。减少日志写操作之间的持续时间会增加写操作的次数,这会限制MongoDB写操作的能力。增加日志写操作之间的持续时间会减少总的写操作的次数,但也加大了发生错误时没有记录写操作的机会
2.7解释结果
3.0版本中的变化
MongoDB 提供db.collection.explain()方法,cursor.explain()方法,explain命令来获得关于查询方案和查询方案执行状态的信息。解释结果将查询方案展现为一颗阶段树。每一阶段将结果(例如文档或索引键)传递给父节点。叶节点使用集合或索引。内部节点操作来自子节点的文档或索引键。根节点是MongoDB提供的结果集中的最终阶段。
每个阶段都是操作的描述;例如:
- 扫描集合COLLSCAN
- 扫描索引键IXSCAN
- 检索文档FETCH
- 合并分片结果SHARD_MERGE
2.7.1解释输出
下面展示了由explain 操作返回的一系列关键字段。
注
- 所列字段并不是全部,但这意味着高亮字段的变化来自早期版本。
- 不同版本间的输出格式有变化。
queryPlanner
queryPlanner信息清晰地说明了查询优化程序所选择的方案。
对于非分片集合,explain 返回的信息如下:
{
"queryPlanner" : {
"plannerVersion" : <int>,
"namespace" : <string>,
"indexFilterSet" : <boolean>,
"parsedQuery" : {
...
},
"winningPlan" : {
"stage" : <STAGE1>,
...
"inputStage" : {
"stage" : <STAGE2>,
...
"inputStage" : {
...
}
}
},
"rejectedPlans" : [
<candidate plan 1>,
...
]
}
explain.queryPlanner
包含了关于查询优化程序所选择的方案信息。
explain.queryPlanner.namespace
一个字符串,指明查询运行在其中的命名空间(例如,<database>.<collection>)。
explain.queryPlanner.indexFilterSet
一个布尔值,指明MongoDB 是否为查询模型使用索引过滤器。
explain.queryPlanner.winningPlan
一个文档,清晰地说明了查询优化程序所选择的方案。MongoDB 以阶段树的形式展示这个方案。例如,一个阶段有一个inputStage,或者这个阶段有多个子阶段,那么这个阶段有多个inputStage。
explain.queryPlanner.winningPlan.stage
一个字符串,表示阶段的名称。
每个阶段包含了各自的具体信息。例如,IXSCAN 阶段包含了索引界限以及索引扫描数据。如果一个阶段有一个或多个子阶段,那么这个阶段将会有一个或多个inputStage。
explain.queryPlanner.winningPlan.inputStage
描述子阶段的文档,这个子阶段为它的父节点提供文档和索引键。如果父阶段只有一个子阶段,那么此字段就存在。
explain.queryPlanner.winningPlan.inputStages
描述多个子阶段的文档数组。这些子阶段为它们的父节点提供文档和索引键。如果父阶段有多个子阶段,那么此字段存在。例如,对于$or表达式或索引交叉策略来说,阶段有多个输入源。
explain.queryPlanner.rejectedPlans
被查询优化程序考虑的和拒绝的备选方案构成的数组。如果没有其他的备选方案,那么这个集合是空的。
对于分片集合,获胜方案包括分片数组,这个数组包含每一个可访问分片的方案信息。
executionStats
返回的executionStats 信息详细描述了获胜方案的执行情况。
为了使executionStats 存在于结果中,必须以executionStats 或allPlansExecution模式来运行explain 命令。
为了包含在方案筛选阶段捕获的部分运行数据,必须使用allPlansExecution模式。
对于非分片集合,explain 返回下列信息:
"executionStats" : {
"executionSuccess" : <boolean>,
"nReturned" : <int>,
"executionTimeMillis" : <int>,
"totalKeysExamined" : <int>,
"totalDocsExamined" : <int>,
"executionStages" : {
"stage" : <STAGE1>
"nReturned" : <int>,
"executionTimeMillisEstimate" : <int>,
"works" : <int>,
"advanced" : <int>,
"needTime" : <int>,
"needYield" : <int>,
"isEOF" : <boolean>,
...
"inputStage" : {
"stage" : <STAGE2>,
...
"nReturned" : <int>,
"executionTimeMillisEstimate" : <int>,
"keysExamined" : <int>,
"docsExamined" : <int>,
...
"inputStage" : {
...
}
}
},
"allPlansExecution" : [
{ <partial executionStats1> },
{ <partial executionStats2> },
...
]
}
explain.executionStats
包含统计数据,描述了按获胜方案实施的完整的查询操作执行情况。对于写操作来说,完整的查询操作执行情况涉及到了可能已经执行了的修改操作,但并没有将修改应用到数据库。
explain.executionStats.nReturned
匹配查询条件的文档的数量。nReturned对应n,n为MongoDB早期版本中的cursor.explain()方法返回字段。
explain.executionStats.executionTimeMillis
筛选查询方案和执行查询所需的以毫秒为单位的时间总和。executionTimeMillis 对应millis ,millis 为MongoDB早期版本中的
cursor.explain()方法返回字段。
explain.executionStats.totalKeysExamined
被扫描的索引条目数量。totalKeysExamined 对应nscanned ,nscanned 为MongoDB早期版本中的cursor.explain()方法返回字段。
explain.executionStats.totalDocsExamined
被扫描的文档数量。totalDocsExamined 对应nscannedObjects ,nscannedObjects 为MongoDB早期版本中的cursor.explain()方法返回字段。
explain.executionStats.executionStages
用阶段树表示的获胜方案的完整执行过程的详细描述。
例如,一个阶段可以有一个或多个inputStage。
explain.executionStats.executionStages.works
表示查询执行阶段涉及的工作单元数量。查询执行将一份工作分配到多个小的单元中。一个工作单元由审查一个索引键,获取集合中的一个文档,对一个文档使用一个投影器,或由完成一块内部记账构成。
explain.executionStats.executionStages.advanced
返回的中间结果的数量或由本阶段到它的父阶段的距离。
explain.executionStats.executionStages.needTime
不通过中间结果到达父阶段的工作周期数。例如,一个索引扫描阶段可能需要一个工作周期探寻到索引中的一个新位置而不是返回索引键;这个工作周期被计入explain.executionStats.executionStages.needTime中而不是explain.executionStats.executionStages.advanced中。
explain.executionStats.executionStages.needYield
存储层所需的查询系统退出自身锁的次数。
explain.executionStats.executionStages.isEOF
指示执行阶段是否已到达流结尾处。
- 如果是true 或1,表示执行阶段已到达流末尾。
- 如果是false 或0,此阶段可能仍有结果要返回。例如,考虑带有如下限制的查询:执行的多个阶段包含LIMIT阶段,此LIMIT阶段含有
IXSCAN的input stage阶段。如果查询不仅返回指定的限量,LIMIT 阶段会报告isEOF: 1,但LIMIT 阶段下层的IXSCAN 阶段会报告isEOF: 0。
explain.executionStats.executionStages.inputStage.keysExamined
对于扫描索引的查询执行阶段,keysExamined是在索引扫描过程中检测到的界内或界外的键值总数。如果索引扫描包含一段连续的键值,仅界内的键值需要被检测。如果索引扫描包含几段连续的键值,索引扫描过程可能会检测界外键值,为了从一段的末尾调到下一段的开始。
考虑下面的例子,有一个索引字段x,集合中包含100个文档,其中x为从1到100。
db.keys.find( { x : { $in : [ 3, 4, 50, 74, 75, 90 ] } } ).explain( "executionStats" )
查询将扫描键3和4,然后将会扫描键5,检测到5在界外,然后跳到下一个键50。
继续这个过程,查询扫描键3, 4, 5, 50, 51, 74, 75, 76, 90, 和91。键5, 51, 76, and 91是界外键,它们仍会被检测。keysExamined 值为10。
explain.executionStats.executionStages.inputStage.docsExamined
指明查询执行阶段扫描的文档数量。
目前适用于COLLSCAN 阶段和在集合中检索文档的阶段(例如FETCH)。
explain.executionStats.allPlansExecution
在方案选择阶段关于获胜方案和被拒绝方案的部分执行信息。这个字段仅存在于以allPlansExecution 模式执行的explain命令的返回结果中。
serverInfo
对于非分片集合,explain 返回下列信息:
"serverInfo" : {
"host" : <string>,
"port" : <int>,
"version" : <string>,
"gitVersion" : <string>
}
2.7.2分片集合
对于分片集合,explain 返回核心查询方案和每一个可访问分片的服务器信息,信息被保存在shards 字段中。
{
"queryPlanner" : {
...
"winningPlan" : {
...
"shards" : [
{
"shardName" : <shard>,
<queryPlanner information for shard>,
<serverInfo for shard>
},
...
],
},
},
"executionStats" : {
...
"executionStages" : {
...
"shards" : [
{
"shardName" : <shard>,
<executionStats for shard>
},
...
]
},
"allPlansExecution" : [
{
"shardName" : <string>,
"allPlans" : [ ... ]
},
...
]
}}
explain.queryPlanner.winningPlan.shards
每一个可用分片的包含了queryPlanner和serverInfo的文档数组。
explain.executionStats.executionStages.shards
每一个可用分片的包含了executionStats 的文档数组。
2.7.3兼容性变化
3.0版本的变化
explain 结果的样式和字段与老版本不同。下面列举了一些关键的不同点:
集合扫描与索引的使用
如果查询方案规划者选择扫描一个集合,那么解释结果包含一个COLLSCAN 阶段。
如果查询方案规划者选择一个索引,解释结果包含一个IXSCAN 阶段。这个阶段包含一些信息,例如索引键模式,遍历的方向,索引界限。
MongoDB以前的版本中,cursor.explain() 返回字段cursor,其值为:
- 集合扫描中的BasicCursor。
- 索引扫描中的BtreeCursor <index name> [<direction>]。
覆盖查询
当一个索引覆盖一个查询时,MongoDB能够仅利用这个索引键(许多个键)匹配查询条件并返回结果。例如,MongoDB不需要检测来自集合中的文档而返回结果。
当一个索引覆盖一个查询时,解释结果包含了IXSCAN阶段,这个阶段不是由FETCH阶段衍生的,并且在executionStats中,
totalDocsExamined的值为0。
MongoDB以前的版本中,cursor.explain()返回indexOnly字段,指明这个索引是否覆盖一个查询。
索引交叉
对于索引交叉方案,结果会包含AND_SORTED阶段或者AND_HASH阶段和详细描述索引的inputStages数组。
{
"stage" : "AND_SORTED",
"inputStages" : [
{
"stage" : "IXSCAN",
...
},
{
"stage" : "IXSCAN",
...
}
]}
MongoDB之前的版本中, cursor.explain()返回cursor字段,cursor字段的值为索引交叉复平面的值。
$or 表达式
如果MongoDB 为$or表达式使用索引,那么结果将会包含OR阶段,连同详细,描述索引的inputStages数组。
{
"stage" : "OR",
"inputStages" : [
{
"stage" : "IXSCAN",
...
},
{
"stage" : "IXSCAN",
...
},
...
]}
MongoDB以前的版本中,cursor.explain()返回的结果中clauses数组详细描述了索引。
Sort阶段
如果MongoDB能够使用索引扫描来获得所需的排序顺序,那么结果不会包含SORT阶段。否则MongoDB不使用索引扫描来获得所需的排序顺序,那么结果将包含SORT阶段。
MongoDB以前的版本中,cursor.explain()返回的结果中scanAndOrder字段指明MongoDB是否使用索引扫描来获得所需的排序顺序。
2.8分析查询性能
cursor.explain("executionStats") 和db.collection.explain("executionStats")提供了关于查询性能的统计信息。这些数据对于测量是否以及如何使用索引是有帮助的。
db.collection.explain()提供了其他操作的执行信息,例如,db.collection.update()。
2.8.1 评估一个查询的性能
考虑集合inventory:
{ "_id" : 1, "item" : "f1", type: "food", quantity: 500 }
{ "_id" : 2, "item" : "f2", type: "food", quantity: 100 }
{ "_id" : 3, "item" : "p1", type: "paper", quantity: 200 }
{ "_id" : 4, "item" : "p2", type: "paper", quantity: 150 }
{ "_id" : 5, "item" : "f3", type: "food", quantity: 300 }
{ "_id" : 6, "item" : "t1", type: "toys", quantity: 500 }
{ "_id" : 7, "item" : "a1", type: "apparel", quantity: 250 }
{ "_id" : 8, "item" : "a2", type: "apparel", quantity: 400 }
{ "_id" : 9, "item" : "t2", type: "toys", quantity: 50 }
{ "_id" : 10, "item" : "f4", type: "food", quantity: 75 }
不使用索引的查询
查询集合中的文档,查询条件为quantity值在100到200之间。
db.inventory.find( { quantity: { $gte: 100, $lte: 200 } } )
返回结果为:
{ "_id" : 2, "item" : "f2", "type" : "food", "quantity" : 100 }
{ "_id" : 3, "item" : "p1", "type" : "paper", "quantity" : 200 }
{ "_id" : 4, "item" : "p2", "type" : "paper", "quantity" : 150 }
使用explain("executionStats")来查看所使用的查询方案:
db.inventory.find(
{ quantity: { $gte: 100, $lte: 200 } }).explain("executionStats")
explain()返回结果为:
{
"queryPlanner" : {
"plannerVersion" : 1,
...
"winningPlan" : {
"stage" : "COLLSCAN",
...
}
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 3,
"executionTimeMillis" : 0,
"totalKeysExamined" : 0,
"totalDocsExamined" : 10,
"executionStages" : {
"stage" : "COLLSCAN",
...
},
...
},
...}
- queryPlanner.winningPlan.stage值为COLLSCAN,表明使用集合扫描。
- executionStats.nReturned值为3,表明查询得到3个文档。
- executionStats.totalDocsExamined值为10,表明MongoDB不得不扫描10个文档来获得3个文档。
检测的文档数与查询匹配到的文档数的不同指示,为了提高查询性能,使用索引可能会有效果。
使用索引的查询
为quantity字段添加索引:
db.inventory.createIndex( { quantity: 1 } )
使用explain("executionStats")来查看所使用的查询方案:
db.inventory.find(
{ quantity: { $gte: 100, $lte: 200 } }).explain("executionStats")
explain()返回结果为:
{
"queryPlanner" : {
"plannerVersion" : 1,
...
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"quantity" : 1
},
...
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 3,
"executionTimeMillis" : 0,
"totalKeysExamined" : 3,
"totalDocsExamined" : 3,
"executionStages" : {
...
},
...
},
...}
- queryPlanner.winningPlan.inputStage.stage的值为IXSCAN,表明使用索引。
- executionStats.nReturned值为3,表明查询得到3个文档。
- executionStats.totalKeysExamined值为3,表明MongoDB扫描了3个索引条目。
- executionStats.totalDocsExamined值为3,表明MongoDB扫描了3个文档。
当使用索引时,查询扫描了3个索引条目和3个文档并且返回3个文档。不用索引时,查询返回3个匹配到的文档且扫描了整个集合,即10个文档。
2.8.2 比较索引性能
为了手工测试使用了不止一个索引的查询性能,可以与 explain()方法一起使用hint()方法。
考虑下面的查询:
db.inventory.find( { quantity: { $gte: 100, $lte: 300 }, type: "food" } )
查询返回值为:
{ "_id" : 2, "item" : "f2", "type" : "food", "quantity" : 100 }
{ "_id" : 5, "item" : "f3", "type" : "food", "quantity" : 300 }
为了支持查询,添加复合索引。有了复合索引,字段的顺序是有意义的。
例如,增加下面两个复合索引。
第一个索引使quantity处在第一位,type排在第二位。第二个索引使type处在第一位,quantity排在第二位。
db.inventory.createIndex( { quantity: 1, type: 1 } )
db.inventory.createIndex( { type: 1, quantity: 1 } )
评估第一个索引的效果:
db.inventory.find(
{ quantity: { $gte: 100, $lte: 300 }, type: "food" }).hint({ quantity: 1, type: 1 }).explain("executionStats")
explain()返回的结果为:
{
"queryPlanner" : {
...
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"quantity" : 1,
"type" : 1
},
...
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 0,
"totalKeysExamined" : 5,
"totalDocsExamined" : 2,
"executionStages" : {
...
}
},
...}
扫描了5个索引键(executionStats.totalKeysExamined) 返回2个文档(executionStats.nReturned)。
评估第二个索引的效果:
db.inventory.find(
{ quantity: { $gte: 100, $lte: 300 }, type: "food" }).hint({ type: 1, quantity: 1 }).explain("executionStats")
explain()返回的结果为:
{
"queryPlanner" : {
...
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"type" : 1,
"quantity" : 1
},
...
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 0,
"totalKeysExamined" : 2,
"totalDocsExamined" : 2,
"executionStages" : {
...
}
},
...}
扫描了2个索引键(executionStats.totalKeysExamined) 返回2个文档(executionStats.nReturned)。
对于这个例子,复合索引{ type: 1, quantity: 1 }比{ quantity: 1, type: 1 }更高效。
2.9 Tailable游标
默认地,当客户端遍历完结果集后,MongoDB会自动地关闭游标。对于固定集合,可使用Tailable游标保持游标打开,当客户端遍历完最初的结果集后。从概念上讲,Tailable游标等价于带有-f选项的Unix tail命令(例如使用follow模式)。客户端向集合中插入新文档后,tailable 游标仍然会继续检索文档。
在固定集合上使用tailable游标且有高写通量,索引不是切实可行的。例如,MongoDB使用tailable游标追踪副本集主成员的oplog。
注:
如果查询已索引字段,不要使用tailable游标,要使用regular游标。保持追踪查询返回的索引字段的最终值。为了查询新添加的文档,在查询准则中使用索引字段的最终值,例子如下:
db.<collection>.find( { indexedField: { $gt: <lastvalue> } } )
考虑如下关于tailable游标的行为:
- tailable游标不会使用索引来返回自然排序的多个文档。
- 因为tailable游标不使用索引,对于查询来说,最初的扫描代价较高。但是,初次耗尽游标以后,随后的对新添加文档的检索并不需要付出高昂的代价。
- tailable游标可能已经消亡或者失效,如果满足下面条件之一:
- 未匹配到查询结果。
- 游标返回集合末尾处的文档,随后应用程序删除了该文档。
一个消亡的游标id值为0。
-----------------------------------------------------------------------------------------
转载与引用请注明出处。
时间仓促,水平有限,如有不当之处,欢迎指正。
【翻译】MongoDB指南/CRUD操作(四)的更多相关文章
- 【翻译】MongoDB指南/CRUD操作(三)
[原文地址]https://docs.mongodb.com/manual/ CRUD操作(三) 主要内容: 原子性和事务(Atomicity and Transactions),读隔离.一致性和新近 ...
- 【翻译】MongoDB指南/CRUD操作(二)
[原文地址]https://docs.mongodb.com/manual/ MongoDB CRUD操作(二) 主要内容: 更新文档,删除文档,批量写操作,SQL与MongoDB映射图,读隔离(读关 ...
- 【翻译】MongoDB指南/CRUD操作(一)
[原文地址]https://docs.mongodb.com/manual/ MongoDB CRUD操作(一) 主要内容:CRUD操作简介,插入文档,查询文档. CRUD操作包括创建.读取.更新和删 ...
- MongoDB的CRUD操作
1. 前言 在上一篇文章中,我们介绍了MongoDB.现在,我们来看下如何在MongoDB中进行常规的CRUD操作.毕竟,作为一个存储系统,它的基本功能就是对数据进行增删改查操作. MongoDB中的 ...
- Mongodb系列- CRUD操作介绍
---恢复内容开始--- 一 Create 操作 在MongoDB中,插入操作的目标是一个集合. MongoDB中的所有写入操作在单个文档的层次上都是原子的. For examples, see In ...
- MongoDB的CRUD操作(java Util )
1.保存插入操作: public static synchronized String insert(DBObject record) { DBCollection col = MongoDB.get ...
- 实例讲解Springboot整合MongoDB进行CRUD操作的两种方式
1 简介 Springboot是最简单的使用Spring的方式,而MongoDB是最流行的NoSQL数据库.两者在分布式.微服务架构中使用率极高,本文将用实例介绍如何在Springboot中整合Mon ...
- Spring Data MongoDB 一:入门篇(环境搭建、简单的CRUD操作)
一.简介 Spring Data MongoDB 项目提供与MongoDB文档数据库的集成.Spring Data MongoDB POJO的关键功能区域为中心的模型与MongoDB的DBColle ...
- mongodb学习(四)CRUD操作
CRUD操作: 1. 插入操作: 直接使用 insert可执行单个操作,也可以执行批量操作 书上的batchInsert会报错.似乎被废弃了. db.foo.insert({"bar&quo ...
随机推荐
- 如何一步一步用DDD设计一个电商网站(十)—— 一个完整的购物车
阅读目录 前言 回顾 梳理 实现 结语 一.前言 之前的文章中已经涉及到了购买商品加入购物车,购物车内购物项的金额计算等功能.本篇准备把剩下的购物车的基本概念一次处理完. 二.回顾 在动手之前我对之 ...
- X86和X86_64和X64有什么区别?
x86是指intel的开发的一种32位指令集,从386开始时代开始的,一直沿用至今,是一种cisc指令集,所有intel早期的cpu,amd早期的cpu都支持这种指令集,ntel官方文档里面称为&qu ...
- JQuery easyUI DataGrid 创建复杂列表头(译)
» Create column groups in DataGrid The easyui DataGrid has ability to group columns, as the followin ...
- IIC驱动移植在linux3.14.78上的实现和在linux2.6.29上实现对比(deep dive)
首先说明下为什么写这篇文章,网上有许多博客也是介绍I2C驱动在linux上移植的实现,但是笔者认为他们相当一部分没有分清所写的驱动时的驱动模型,是基于device tree, 还是基于传统的Platf ...
- Aaron Stannard谈Akka.NET 1.1
Akka.NET 1.1近日发布,带来新特性和性能提升.InfoQ采访了Akka.net维护者Aaron Stannard,了解更多有关Akka.Streams和Akka.Cluster的信息.Aar ...
- Mysql存储引擎及选择方法
0x00 Mysql数据库常用存储引擎 Mysql数据库是一款开源的数据库,支持多种存储引擎的选择,比如目前最常用的存储引擎有:MyISAM,InnoDB,Memory等. MyISAM存储引擎 My ...
- $ORACLE_HOME变量值末尾多“/”惹的祸
之前一直误以为$ORACLE_HOME变量的路径中末尾多写一个"/"不会有影响. 今天做实验时碰到一个情景,发现并不是这样. 环境:OEL 5.7 + Oracle 10.2.0. ...
- 玩转Vim 编辑器
一:VIM快速入门 1.vim模式介绍 以下介绍内容来自维基百科Vim 从vi演生出来的Vim具有多种模式,这种独特的设计容易使初学者产生混淆.几乎所有的编辑器都会有插入和执行命令两种模式,并且大多数 ...
- J a v a 的“多重继承”
接口只是比抽象类“更纯”的一种形式.它的用途并不止那些.由于接口根本没有具体的实施细节——也就是说,没有与存储空间与“接口”关联在一起——所以没有任何办法可以防止多个接口合并到一起.这一点是至关重要的 ...
- C#反序列化XML异常:在 XML文档(0, 0)中有一个错误“缺少根元素”
Q: 在反序列化 Xml 字符串为 Xml 对象时,抛出如下异常. 即在 XML文档(0, 0)中有一个错误:缺少根元素. A: 首先看下代码: StringBuilder sb = new Stri ...