如何用C++封装一个简单的数据流操作类(附源码),从而用于网络上的数据传输和解析?
历史溯源
由于历史原因,我们目前看到的大部分的网络协议都是基于ASCII码这种纯文本方式,也就是基于字符串的命令行方式,比如HTTP、FTP、POP3、SMTP、Telnet等。早期操作系统UNIX(或DOS),用户操作界面就是控制台,控制台的输入输出方式就决定了用户只能通过敲击键盘的方式将协议命令输入到网络,这也就导致了回车换行"\r\n"会作为一次命令结束的标识。
比如HTTP协议,与主机建立连接后,输入"GET / HTTP/1.1\r\n"即可获取网站的主页。
比如email协议,早期的电子邮件协议只支持ASCII码这种纯文本传输,但随着全世界人民对物质文化生活的不断向往,这种落后的传输方式,已经无法满足世界人民对美好生活的追求,比如图像、视频、音频、Office文件如何在邮件中展现?不同国家(非英语国家)字符集该如何传输和展现?
换句话说,就是这种非ASCII的二进制富文本,该如何传输和呈现?
MIME的诞生
此时MIME标准诞生了,MIME的出现更多的是一种向下兼容的无奈,而不是革命。通过对二进制数据或非ASCII码数据进行base64或quoted-printable编码,来实现纯ASCII码的传输。显然这种方式会让你的邮件体变大,传输效率下降。尤其附件很多时,通过MIME的boundary来解析邮件的附件也是一笔额外的负担。
同时MIME的标准也被HTTP协议所采用,我们可以通过content-type指定传输的内容是什么类型,通过MIME的boundary来对Form-Data数据进行扩展,让我们Post数据时也能够在“表格”数据中插入文件,从而达到上传文件的效果。
显然这种方式不如二进制简洁,但却非常的直观,所见即所得,一眼就能看明白。但就传输效率上不如二进制方式。
又比如websocket协议虽然建立会话时采用的是HTTP协议,但后续的数据帧格式却是一个二进制格式。如下:
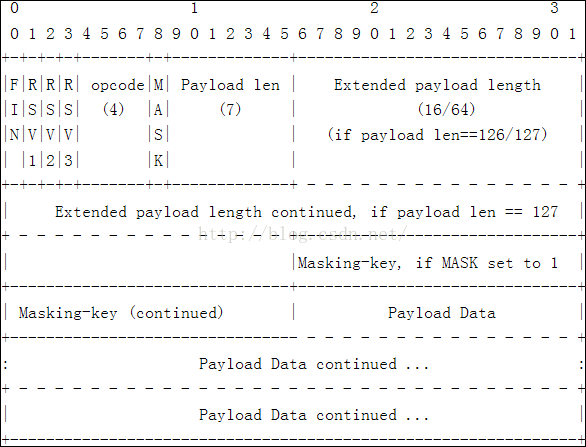
在这种格式下,为了表示每帧数据长度,就一定会有一个“数据长度”项,比如上面的payload len,当该值小于126时,直接表示数据区(payload data)长度;为126时用后面的2个字节表示数据区长度,为127时用后面的8个字节表示数据区长度。此时就涉及到了网络字节序和主机字节序的转换,如果数据区是一个二进制内容的话,我们就很难使用string的操作方式将整个数据报文拼接起来(可以用memcpy来拼接)。当然,我们这篇文章不是对websocket协议的讲解,而是通过该协议的数据区引出二进制数据流封装的必要性。如果是文本协议,各种开发语言对string的封装已经足够强大,已经没有封装的必要。除非你想重新改造字符串操作来提升效率或其它目的,比如我的前一篇文章:
为何写服务器程序需要自己管理内存,从改造std::string字符串操作说起。。。
话不多说,下面是一个简单的数据流的封装类CDataStream,非常简单。
.h头文件
#include <windows.h>
// 数据流
class CDataStream
{
public:
CDataStream(BOOL bNetworkOrder = FALSE);
virtual ~CDataStream();
// 关联一块stream
void Attach(const BYTE* pStream, int iStreamSize){
m_pStream = (BYTE*)pStream;
m_iStreamSize = iStreamSize;
m_iCurrPos = 0;
}
// 解除关联
void Detach(){
m_pStream = NULL;
m_iStreamSize = 0;
m_iCurrPos = 0;
}
void Reset(){
m_iCurrPos = 0;
}
// 获取流数据
const BYTE* GetStreamData(){
return m_pStream;
}
int GetStreamSize(){
return m_iCurrPos;
}
// 在当前位置上移动iDistance距离
int Offset(int iDistance);
// 移动到新位置
int MoveTo(int iNewPos);
void MoveToBegin(){
m_iCurrPos = 0;
}
void MoveToEnd(){
m_iCurrPos = m_iStreamSize;
}
// 读写字节
void WriteByte(BYTE byValue);
BYTE ReadByte();
// 读写WORD
void WriteWord(WORD wValue);
WORD ReadWord();
// 读写DWORD
void WriteDWord(DWORD dwValue);
DWORD ReadDWord();
// 读写int64
void WriteInt64(__int64 i64Value);
__int64 ReadInt64();
// 读写Float
void WriteFloat(float fValue);
float ReadFloat();
// 读写double
void WriteDouble(double dValue);
double ReadDouble();
// 读写数据流
void WriteData(unsigned char* pData, int iDataLen);
BYTE* ReadData(int iDataLen);
// 读写字符串
void WriteString(const char* pszValue);
const char* ReadString();
// =============运算符重载=============
CDataStream& operator<<(BYTE byValue) { WriteByte(byValue); return *this; }
CDataStream& operator<<(WORD wValue) { WriteWord(wValue); return *this; }
CDataStream& operator<<(DWORD dwValue) { WriteDWord(dwValue); return *this; }
CDataStream& operator<<(__int64 i64Value) { WriteInt64(i64Value); return *this; }
CDataStream& operator<<(float fValue) { WriteFloat(fValue); return *this; }
CDataStream& operator<<(double dValue) { WriteDouble(dValue); return *this; }
CDataStream& operator<<(const char* pszValue) { WriteString(pszValue); return *this; }
CDataStream& operator>>(BYTE& byValue) { byValue = ReadByte(); return *this; }
CDataStream& operator>>(WORD& wValue) { wValue = ReadWord(); return *this; }
CDataStream& operator>>(DWORD& dwValue) { dwValue = ReadDWord(); return *this; }
CDataStream& operator>>(__int64& i64Value) { i64Value = ReadInt64(); return *this; }
CDataStream& operator>>(float& fValue) { fValue = ReadFloat(); return *this; }
CDataStream& operator>>(double& dValue) { dValue = ReadDouble(); return *this; }
CDataStream& operator>>(const char*& pszValue) { pszValue = ReadString(); return *this; }
public:
// WORD值反序
static WORD Swap(WORD wValue){
WORD wRet = 0;
((BYTE*)&wRet)[0] = ((BYTE*)&wValue)[1];
((BYTE*)&wRet)[1] = ((BYTE*)&wValue)[0];
return wRet;
}
// DWORD反序
static DWORD Swap(DWORD dwValue){
DWORD dwRet = 0;
((BYTE*)&dwRet)[0] = ((BYTE*)&dwValue)[3];
((BYTE*)&dwRet)[1] = ((BYTE*)&dwValue)[2];
((BYTE*)&dwRet)[2] = ((BYTE*)&dwValue)[1];
((BYTE*)&dwRet)[3] = ((BYTE*)&dwValue)[0];
return dwRet;
}
// i64(long long)反序
static __int64 Swap(__int64 i64Value){
__int64 i64Ret = 0;
((BYTE*)&i64Ret)[0] = ((BYTE*)&i64Value)[7];
((BYTE*)&i64Ret)[1] = ((BYTE*)&i64Value)[6];
((BYTE*)&i64Ret)[2] = ((BYTE*)&i64Value)[5];
((BYTE*)&i64Ret)[3] = ((BYTE*)&i64Value)[4];
((BYTE*)&i64Ret)[4] = ((BYTE*)&i64Value)[3];
((BYTE*)&i64Ret)[5] = ((BYTE*)&i64Value)[2];
((BYTE*)&i64Ret)[6] = ((BYTE*)&i64Value)[1];
((BYTE*)&i64Ret)[7] = ((BYTE*)&i64Value)[0];
return i64Ret;
}
// 下面的函数也是将64位长整形反序,但比较难理解,不如上面的函数简单、粗暴和直观
// 即使你现在能整明白,下次未必能“见字如面”
static __int64 Swap64(__int64 i64Value)
{
return i64Value >> 56|
(i64Value & 0x00ff000000000000) >> 40 |
(i64Value & 0x0000ff0000000000) >> 24 |
(i64Value & 0x000000ff00000000) >> 8 |
(i64Value & 0x00000000ff000000) << 8 |
(i64Value & 0x0000000000ff0000) << 24 |
(i64Value & 0x000000000000ff00) << 40 |
i64Value << 56;
}
// 浮点型按照IEEE745标准不存在网络字节序和机器字节序,这里只是给出实现方法
// float反序
static float Swap(float fValue){
float fRet = fValue;
Swap((BYTE*)&fRet, sizeof(float));
return fRet;
}
// double反序
static double Swap(double dValue){
double dRet = dValue;
Swap((BYTE*)&dRet, sizeof(double));
return dRet;
}
// 内存数据反序
static void Swap(BYTE* pData, int iDataLen);
// 内存反序后返回新内存
static BYTE* SwapClone(BYTE* pData, int iDataLen);
protected:
BOOL m_bNetworkOrder; // 数据流是否为网络字节序,缺省为FALSE
BYTE *m_pStream; // stream缓存
int m_iStreamSize; // 缓存大小
int m_iCurrPos; // 当前数据位置
};
.cpp实现文件
#include "DataStream.h"
#include <assert.h>
#include <stdlib.h>
// 将一块内存反序
void CDataStream::Swap(BYTE* pData, int iDataLen)
{
if(NULL == pData || iDataLen <= 0)
return;
for(int i = 0 ; i < iDataLen / 2; i++)
{
BYTE temp = pData[i];
pData[i] = pData[iDataLen - i - 1];
pData[iDataLen - i - 1] = temp;
}
}
// 将一块内存反序后返回新内存
BYTE* CDataStream::SwapClone(BYTE* pData, int iDataLen)
{
if(NULL == pData || iDataLen <= 0)
return NULL;
BYTE* pSwap = (BYTE*)malloc(iDataLen);
int j = 0;
for(int i = iDataLen-1; i >= 0; i--)
{
pSwap[j] = pData[i];
j++;
}
return pSwap;
}
//////////////////////////////////////////////////////////////////////
// Construction/Destruction
//////////////////////////////////////////////////////////////////////
CDataStream::CDataStream(BOOL bNetworkOrder)
{
m_bNetworkOrder = bNetworkOrder;
m_pStream = NULL;
m_iStreamSize = 0;
m_iCurrPos = 0;
}
CDataStream::~CDataStream()
{
m_pStream = NULL;
m_iStreamSize = 0;
m_iCurrPos = 0;
}
// 在当前位置上移动iDistance距离
int CDataStream::Offset(int iDistance)
{
int iNewPos = m_iCurrPos+iDistance;
if(iNewPos < 0)
m_iCurrPos = 0;
else if(iNewPos > m_iStreamSize)
m_iCurrPos = m_iStreamSize;
else
m_iCurrPos = iNewPos;
return m_iCurrPos;
}
// 移动到新位置
int CDataStream::MoveTo(int iNewPos)
{
if(iNewPos < 0)
m_iCurrPos = 0;
else if(iNewPos > m_iStreamSize)
m_iCurrPos = m_iStreamSize;
else
m_iCurrPos = iNewPos;
return m_iCurrPos;
}
// 读写字节
void CDataStream::WriteByte(BYTE byValue)
{
assert(m_iCurrPos+1 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+1 > m_iStreamSize)
return;
*(m_pStream+m_iCurrPos) = byValue;
m_iCurrPos++;
}
BYTE CDataStream::ReadByte()
{
assert(m_iCurrPos+1 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+1 > m_iStreamSize)
return 0;
BYTE byValue = *(m_pStream+m_iCurrPos);
m_iCurrPos++;
return byValue;
}
// 读写WORD
void CDataStream::WriteWord(WORD wValue)
{
assert(m_iCurrPos+2 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+2 > m_iStreamSize)
return;
// 如果是网络字节流则反序
if(m_bNetworkOrder)
wValue = Swap(wValue);
*(WORD*)(m_pStream+m_iCurrPos) = wValue;
m_iCurrPos += 2;
}
WORD CDataStream::ReadWord()
{
assert(m_iCurrPos+2 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+2 > m_iStreamSize)
return 0;
WORD wValue = *(WORD*)(m_pStream+m_iCurrPos);
m_iCurrPos += 2;
// 如果是网络字节流则反序
if(m_bNetworkOrder)
wValue = Swap(wValue);
return wValue;
}
// 读写DWORD
void CDataStream::WriteDWord(DWORD dwValue)
{
assert(m_iCurrPos+4 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+4 > m_iStreamSize)
return;
// 如果是网络字节流则反序
if(m_bNetworkOrder)
dwValue = Swap(dwValue);
*(DWORD*)(m_pStream+m_iCurrPos) = dwValue;
m_iCurrPos += 4;
}
DWORD CDataStream::ReadDWord()
{
assert(m_iCurrPos+4 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+4 > m_iStreamSize)
return 0;
DWORD dwValue = *(DWORD*)(m_pStream+m_iCurrPos);
m_iCurrPos += 4;
// 如果是网络字节流则反序
if(m_bNetworkOrder)
dwValue = Swap(dwValue);
return dwValue;
}
// 读写int64
void CDataStream::WriteInt64(__int64 i64Value)
{
assert(m_iCurrPos+8 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+8 > m_iStreamSize)
return;
// 如果是网络字节流则反序
if(m_bNetworkOrder)
i64Value = Swap(i64Value);
*(__int64*)(m_pStream+m_iCurrPos) = i64Value;
m_iCurrPos += 8;
}
__int64 CDataStream::ReadInt64()
{
assert(m_iCurrPos+8 <= m_iStreamSize); // 越界断言
if(m_iCurrPos+8 > m_iStreamSize)
return 0;
__int64 i64Value = *(__int64*)(m_pStream+m_iCurrPos);
m_iCurrPos += 8;
// 如果是网络字节流则反序
if(m_bNetworkOrder)
i64Value = Swap(i64Value);
return i64Value;
}
// 读写float
void CDataStream::WriteFloat(float fValue)
{
int iFloatSize = sizeof(float);
assert(m_iCurrPos+iFloatSize <= m_iStreamSize);
if(m_iCurrPos+iFloatSize > m_iStreamSize)
return;
*(float*)(m_pStream+m_iCurrPos) = fValue;
m_iCurrPos += iFloatSize;
}
float CDataStream::ReadFloat()
{
int iFloatSize = sizeof(float);
assert(m_iCurrPos+iFloatSize <= m_iStreamSize);
if(m_iCurrPos+iFloatSize > m_iStreamSize)
return 0;
float fValue = *(float*)(m_pStream+m_iCurrPos);
m_iCurrPos += iFloatSize;
return fValue;
}
// 读写double
void CDataStream::WriteDouble(double dValue)
{
int iDoubleSize = sizeof(double);
assert(m_iCurrPos+iDoubleSize <= m_iStreamSize);
if(m_iCurrPos+iDoubleSize > m_iStreamSize)
return;
*(double*)(m_pStream+m_iCurrPos) = dValue;
m_iCurrPos += iDoubleSize;
}
double CDataStream::ReadDouble()
{
int iDoubleSize = sizeof(double);
assert(m_iCurrPos+iDoubleSize <= m_iStreamSize);
if(m_iCurrPos+iDoubleSize > m_iStreamSize)
return 0;
double dValue = *(double*)(m_pStream+m_iCurrPos);
m_iCurrPos += iDoubleSize;
return dValue;
}
// 读写数据流
void CDataStream::WriteData(unsigned char* pData, int iDataLen)
{
if(NULL == pData || iDataLen <= 0)
return;
assert(m_iCurrPos + iDataLen <= m_iStreamSize); // 越界断言
if(m_iCurrPos + iDataLen > m_iStreamSize)
return;
memcpy(m_pStream+m_iCurrPos, pData, iDataLen);
m_iCurrPos += iDataLen;
}
BYTE* CDataStream::ReadData(int iDataLen)
{
if(iDataLen <= 0 || m_iCurrPos >= m_iStreamSize)
return NULL;
assert(m_iCurrPos + iDataLen <= m_iStreamSize); // 越界断言
if(m_iCurrPos + iDataLen > m_iStreamSize)
return NULL;
BYTE* pData = m_pStream+m_iCurrPos;
m_iCurrPos += iDataLen;
return pData;
}
// 读写字符串
void CDataStream::WriteString(const char* pszValue)
{
if(NULL == pszValue)
return ;
int iStrLen = strlen(pszValue)+1; // 末尾0
assert(m_iCurrPos+iStrLen <= m_iStreamSize); // 越界断言
if(m_iCurrPos+iStrLen > m_iStreamSize)
return;
memcpy(m_pStream+m_iCurrPos, pszValue, iStrLen);
m_iCurrPos += iStrLen;
}
const char* CDataStream::ReadString()
{
if(m_iCurrPos >= m_iStreamSize)
return NULL;
int iCurrPos = m_iCurrPos;
char* psz = (char*)(m_pStream+m_iCurrPos); // 字符串位置
while(iCurrPos < m_iStreamSize)
{
if(!m_pStream[iCurrPos]) // 字符串最后一个字符为0
{
m_iCurrPos = iCurrPos;
break;
}
iCurrPos++;
}
// 判断是否合法
if(m_iCurrPos < m_iStreamSize)
{
m_iCurrPos++; // skip 0
return psz;
}
assert(FALSE); // 越界断言
return NULL;
}
感谢阅读!
如何用C++封装一个简单的数据流操作类(附源码),从而用于网络上的数据传输和解析?的更多相关文章
- 2.NetDh框架之简单高效的日志操作类(附源码和示例代码)
前言 NetDh框架适用于C/S.B/S的服务端框架,可用于项目开发和学习.目前包含以下四个模块 1.数据库操作层封装Dapper,支持多种数据库类型.多库实例,简单强大: 此部分具体说明可参考博客: ...
- Android UI开发: 横向ListView(HorizontalListView)及一个简单相册的完整实现 (附源码下载)
http://blog.csdn.net/yanzi1225627/article/details/21294553 原文
- 急急如律令!火速搭建一个C#即时通信系统!(附源码分享——高度可移植!)
(2016年3月更:由于后来了解到GGTalk开源即时通讯系统,因此直接采用了该资源用于项目开发,在此对作者表示由衷的感谢!) —————————————————————————————————— 人 ...
- 一文详解如何用 TensorFlow 实现基于 LSTM 的文本分类(附源码)
雷锋网按:本文作者陆池,原文载于作者个人博客,雷锋网已获授权. 引言 学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实例,这个星期就用 ...
- 教你用纯Java实现一个网页版的Xshell(附源码)
前言 最近由于项目需求,项目中需要实现一个WebSSH连接终端的功能,由于自己第一次做这类型功能,所以首先上了GitHub找了找有没有现成的轮子可以拿来直接用,当时看到了很多这方面的项目,例如:Gat ...
- Android Studio 一个完整的APP实例(附源码和数据库)
前言: 这是我独立做的第一个APP,是一个记账本APP. This is the first APP, I've ever done on my own. It's a accountbook APP ...
- 通过一个简单的数据库操作类了解PHP链式操作的实现
class Model{ public $table; //操作的表; private $opt; //查询的参数; private $pri; //表的主键; private $lastSql; / ...
- struts1实现简单的登录功能(附源码)
环境:MyEclipse 14 ...
- oracle常见为题汇总,以及一个简单数据连接操作工厂
本人软件环境:win8.1 64位操作系统,vs2013,安装好了与oracle数据库对应的客户端 连接oracle数据库.以及操作数据库 1.使用IIS建立网站,浏览网页时候,提示“ ...
随机推荐
- 后缀数组&manachar总结
洛谷题单 后缀数组 前置芝士 后缀数组 1 后缀数组 2 后缀数组 3 例题略解 P2463 [SDOI2008]Sandy的卡片 板子题... 然而我还是不会. 大概做法就是先把所有的串差分后拼成一 ...
- 「csp-s模拟测试(9.18)」Set·Read·Race
昨天考试考得有点迷??? 一看内存限制,T1 64MB T2 16MB 当场懵比......... T1 set 考场打的背包问题和随机化,其实能randA掉,但不小心数组开小了????(长记性!!! ...
- 「模拟8.29」chinese(性质)·physics·chemistry(概率期望)
T1 chinese 根据他的问题i*f[i]我们容易联想到,答案其实是每种方案中每个点的贡献为1的加和 我们可以转变问题,每个点在所有方案的贡献 进而其实询问就是1-k的取值,有多少中方案再取个和 ...
- noip2007 总结
统计数字 原题 某次科研调查时得到了n个自然数,每个数均不超过1500000000(1.5*10^9).已知不相同的数不超过10000个,现在需要统计这些自然数各自出现的次数,并按照自然数从小到大的顺 ...
- Pytest学习笔记3-fixture
前言 个人认为,fixture是pytest最精髓的地方,也是学习pytest必会的知识点. fixture用途 用于执行测试前后的初始化操作,比如打开浏览器.准备测试数据.清除之前的测试数据等等 用 ...
- Mysql优化(出自官方文档) - 第六篇
Mysql优化(出自官方文档) - 第六篇 目录 Mysql优化(出自官方文档) - 第六篇 Optimizing Subqueries, Derived Tables, View Reference ...
- 痛并快乐的YOLO初体验
1.前言 最近因为需要研究视频的物体识别和行为识别,上网了解了一下,YOLO是目前实时视频物体识别的应用最广泛的算法. 因此,作为小白的我,也准备体验一下YOLO算法的效果. 先上网了解了一下YOLO ...
- Jenkins用户权限管理-Role-based Authorization Strategy插件
02-Jenkins用户权限管理-Role-based Authorization Strategy插件 在jenkins的使用过程中,需要给用户分配只管理特定项目的权限来保证项目相关人员只能管理对应 ...
- 04 jumpserver资产管理
4.资产管理: (1)管理用户: 管理用户是资产(被控服务器)上的 root,或拥有 NOPASSWD: ALL sudo 权限的用户, JumpServer 使用该用户来 `推送系统用户`.`获取资 ...
- @EnableDiscoveryClient与Nacos自动注册
前一阵看到有篇博客说cloud从Edgware版本开始,可以不加@EnableDiscoveryClient注解,只要配置好注册中心的相关配置即可自动开启服务注册功能,比较好奇其中的原理,研究了一番特 ...