在线博客转PDF电子书 | JS爬虫初探
最近在看一位大佬写的源码解析博客,平时上下班用手机看不太得劲,但是平板又没有网卡,所以就想搞个离线pdf版,方便通勤时间学习阅读。
所以,问题来了: 怎么把在线网页内容转成pdf?
这位大佬的博客是用gitbook写的,我先上网搜了下工具,发现大多是将自己本地gitbook转pdf,只有一个开源工具是用python爬取的在线gitbook,但是一看issues,中文乱码、空白页、看不到图等等问题都没解决,遂放弃……
经过我不懈的搜索,终于找到了一个可以直接把网页保存成pdf工具:phantomjs。
phantomjs是一个无界面的,可脚本编程的 WebKit 浏览器引擎,也就是俗称的“无头浏览器”,常用于爬取网页信息。
下载地址:https://phantomjs.org/download.html
我用的是win系统,下载后在bin目录下找到.exe文件,然后新建如下js脚本:
// html2pdf.js
var page = require('webpage').create();
var system = require('system');
if (system.args.length === 1) {
console.log('Usage: loadspeed.js <some URL>');
//这行代码很重要。凡是结束必须调用。否则phantomjs不会停止
phantom.exit();
}
page.settings.loadImages = true; //加载图片
page.settings.resourceTimeout = 30000;//超过10秒放弃加载
//截图设置,
//page.viewportSize = {
// width: 1000,
// height: 3000
//};
var address = system.args[1];
var name = system.args[2];
page.open(address, function (status) {
function checkReadyState() {//等待加载完成将页面生成pdf
setTimeout(function () {
var readyState = page.evaluate(function () {
return document.readyState;
});
if ("complete" === readyState) {
page.paperSize = { width: '297mm', height: '500mm', orientation: 'portrait', border: '1cm' };
var timestamp = Date.parse(new Date());
var pdfname = name;
var outpathstr = "C:/Users/Desktop/pdfs/" + pdfname + ".pdf"; // 输出路径
page.render(outpathstr);
console.log("生成成功");
console.log("$" + outpathstr + "$");
phantom.exit();
} else {
checkReadyState();
}
}, 1000);
}
checkReadyState();
});
控制台cd进入bin目录,命令行执行:
phantomjs html2pdf.js http://xxx.xx.xxx(博客所在地址)
即可将该网页转成一个pdf。
这时候问题又来了:
- phantomjs不能自动截取下一页;
- 每一个网页都只能生成一个pdf,最后还要找工具把所有pdf合并成一个;
- 保存的实际上是网页的截图,对于侧边栏、顶部栏、底部等我不需要的内容也会保存到页面中,不能很好地适配。
思考和观察得出解决办法:
- 这个博客的网址除了域名统一外并没有其他规律,只能手动维护一个url列表,然后通过脚本遍历来解决第 1 个问题;
- pdf合并工具网上有现成的,第 2 个问题也能解决;
- phantomjs是可以对dom进行操作的,但是有个问题,页面里如果有异步请求的资源,比如图片,就需要延迟截图时间,否则会出现很多空白区域,具体解决办法可以参见这篇博客:使用phantomjs操作DOM并对页面进行截图需要注意的几个问题。
问题虽然是能解决,但是过于麻烦,而且这个dom操作并不能在截图的时候去掉多余内容。
经过上面一系列骚操作,我受到了启发,从而有了一个全新的思路:
通过dom操作,把整个博客的内容都爬到一个html文件中,再把这个html文件转成pdf。
话不多说,直接开撸。
为了避开浏览器同源网络策略,我基于之前搭建的node+express本地服务,并引入插件cheerio(用于dom操作)、html-pdf(用于将网页转成pdf)来实现。
首先,观察需要爬取的dom元素的特点:
我需要爬取的内容如图所示
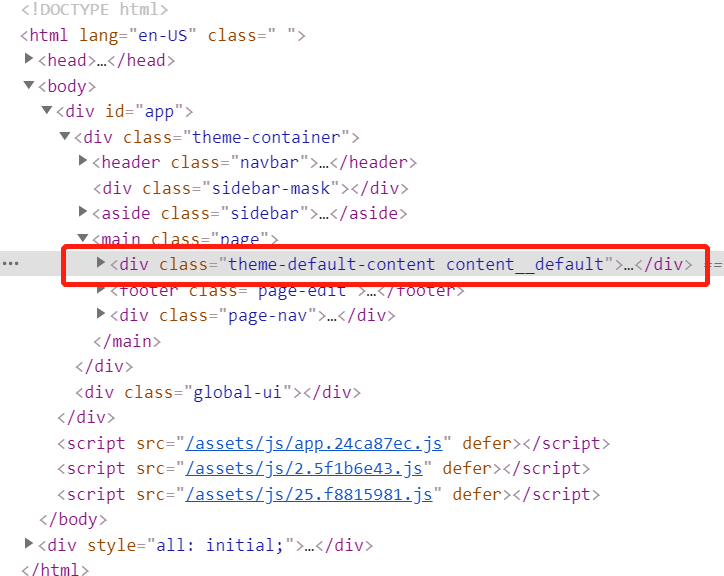
这部分的内容可以通过.theme-default-content样式获取到:
https.get(url, function (res) {
var str = "";
//绑定方法,获取网页数据
res.on("data", function (chunk) {
str += chunk;
})
//数据获取完毕
res.on("end", function () {
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".theme-default-content");
var main = "";
if (arr && arr.length > 0) {
main = arr[0]
}
})
通过这段代码得到的main就是我们要获取的主体dom。
其次,观察图片资源的url:
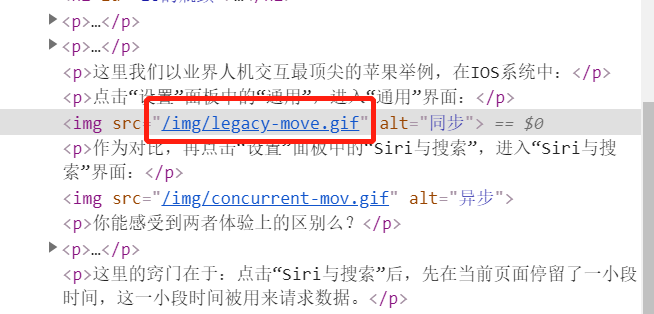
这里用的是相对路径,所以需要对图片路径进行处理:
// 将上面得到的main转为字符串便于处理
main = $.html(main)
// 对图片路径进行补全
main = main.replace(/src=\"\/img/g, "src=\"" + prefixUrl + "/img")
观察下一页的url地址,都是在一个样式名为next的span标签内:
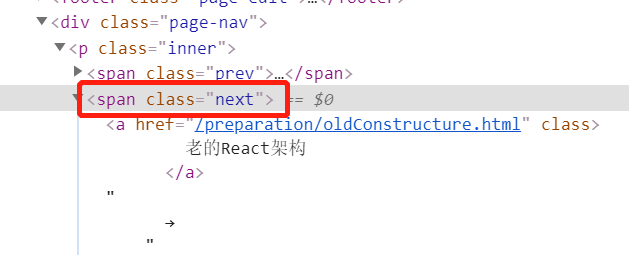
获取下一页内容的代码如下:
var $ = cheerio.load(str);
var arr = $(".next");
var nextData = "";
if (arr && arr.length > 0) {
nextData = arr[0]
if (nextData && nextData.children && nextData.children[0] && nextData.children[0].attribs) {
// 下一页地址:prefixUrl + nextData.children[0].attribs.href
} else {
// 没有下一页
}
}
最后还需要把html转成pdf:
function htmlTopdf() {
var html = fs.readFileSync(path.resolve(__dirname, htmlFileName), 'utf8');
var options = { format: 'A4' };
pdf.create(html, options).toFile(path.resolve(__dirname, pdfFileName), function (err, res) {
if (err) return console.log("error message", err);
console.log(res);
});
}
总结一下实现思路:
- 通过dom操作抓取到主体内容,并对其中的图片等资源进行处理,然后保存到html文件中;
- 找到下一页的url,将下一页的主体内容继续拼到html文件后;
- 最后将html转成pdf保存。
上面的代码不是通用的,但是如果要抓取其他网页的话,思路基本都是这三步。
Demo已开源:https://github.com/youzouzou/node-crawler/blob/main/routes/index.js
npm install后打开http://localhost:3009/ 即可生成pdf。
在线博客转PDF电子书 | JS爬虫初探的更多相关文章
- MVC5+EF6+AutoMapper+Bootstrap打造在线博客(1.0)
目的:MVC5+EF6开发一个高并发.分布式的在线博客,等开发完成以后再用.net core,mysql重新开发,部署到linux系统上,这一系列就算完结,经验不足,大家一起讨论进步,源代码下载QQ群 ...
- 我博客上的围棋js程序
作为一个围棋爱好者,就决定在博客里加个围棋js程序.于是,申请了博客的js权限,美化美化我的博客. 好在js的语法像C系的,看了看,写个程序应该还是可以的. 围棋里,设计好基本的数据结构: //a是1 ...
- github page 和 hexo 搭建在线博客
目录: 安装node.js与git 常用git命令 安装hexo 配置hexo hexo发布到github 1.安装node.js和git工具 https://nodejs.org/en/ 直接下载安 ...
- [技术博客]JSCover+selenium获得js代码覆盖率
本文档讲解了我们是如何使用JSCover来获得Selenium的测试样例的js代码文件的执行覆盖率的. 事实上网上有挺多博客讲这玩意儿了,不过完全按照网上已有的教程去弄的的话,并无法满足我们的需要. ...
- MVC5+EF6+AutoMapper+Bootstrap打造在线博客(1.1)
DAL层的三个Model类: 字典表:CFDict 用户表:CFUser 用户爱好表:CFUserHobby(关联cfuser表和cfdict表) CFUser表和CFUserHobby表是一对多关系 ...
- Node.js 爬虫初探
前言 在学习慕课网视频和Cnode新手入门接触到爬虫,说是爬虫初探,其实并没有用到爬虫相关第三方类库,主要用了node.js基础模块http.网页分析工具cherrio. 使用http直接获取url路 ...
- beta阶段学习博客(一) js交互
js交互 js交互的三种方法
- Django_博客项目 引入外部js文件内含模板语法无法正确获取值得说明和处理
问题描述 : 项目中若存在对一段js代码复用多次的时候, 通常将此段代码移动到一个单独的静态文件中在被使用的地方利用 script 标签的 src 属性进行外部调用 但是如果此文件中存在使用 HTML ...
- typecho博客组插件:openSug.js百度搜索框下拉提示免费代码
Typecho候选搜索增强插件:安装openSug插件即可获得带有“搜索框提示”功能的搜索框,让Typecho搜索更便捷! 支持百度.谷歌.雅虎.Yandex.360好搜.UC神马.酷狗.优酷.淘 ...
随机推荐
- 使用DevExpress的GridControl实现多层级或无穷级的嵌套列表展示
在我早期的随笔<在GridControl表格控件中实现多层级主从表数据的展示>中介绍过GridControl实现二级.三级的层级列表展示,主要的逻辑就是构建GridLevelNode并添加 ...
- 02 CTF WEB 知识梳理
1. 工具集 基础工具 Burpsuit, Python, FireFox(Hackbar, FoxyProxy, User-Agent Swither .etc) Burpsuit 代理工具,攻击w ...
- markerdown基础
标题 用#+空格 字体 加粗两边两个** 斜体两边* 斜体加粗三个* 引用 '>' 分割线 三个---或者三个*** 图片 ![截图]() 超链接 点击跳转到文章 []+() 列表 1 + 点+ ...
- 安装centos7提示 please make your choice from above
分别输入"1" "2" "q" "yes",如上图 释义如下:
- xsos:一个在Linux上阅读SOSReport的工具
xsos:一个在Linux上阅读SOSReport的工具 时间 2019-05-23 14:36:29 51CTO 原文 http://os.51cto.com/art/201905/596889 ...
- Canal和Otter介绍和使用
Canal Canal原理 原理相对比较简单: canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议 mysql master收 ...
- 创建第一个django工程
一.环境搭建 使用anaconda + pycharm的环境. 1.创建虚拟环境并安装django1.8的包 # 创建虚拟环境 conda create -n django python=3.6 # ...
- STM32的引脚的配置
http://blog.csdn.net/u010592722/article/details/45746079
- Java中单列集合List排序的真实应用场景
一.需求描述 最近产品应客户要求提出了一个新的需求,有一个列表查询需要按照其中的多列进行排序. 二.需求分析 由于数据总量不多,可以全部查询出来,因此我就考虑使用集合工具类Collections.so ...
- 利用js判断文件是否为utf-8编码
常规方案 使用FileReader以utf-8格式读取文件,根据文件内容是否包含乱码字符�,来判断文件是否为utf-8. 如果存在�,即文件编码非utf-8,反之为utf-8. 代码如下: const ...