Causal Inference
A(A) --> Y(Y)
L(L) -->A(A) --> Y(Y)
L --> Y
这里对常用的causal effect的估计方法做一个总结, 需要注意的是, 在参数模型的情况下\(\theta L\) 表示\(\theta^TL\)当二者为向量的时候.
为了方便, 我们常常使用\(\sum\), 这并非要求该项必须是离散的, 除了\(A\)大部分可以等价于\(\int\).
默认情况下, (条件)可交换性(exchangeability), 一致性(consistency) 以及 正性(positivity) 都是满足的, 特别的情况为注明.
其中, time-varying的条件可交换性定义为:
\]
如果是静态的, \(g\)换成\(\bar{a}\).
Censoring 是数据缺失的情况, 对其的处理可以理解为对多个treatments的情况的处理.
Standardization
非参数情况
\]
\mathbb{E}[Y^a] = \mathbb{E}_{L} \mathbb{E}_{Y^a}[Y^a|L]
=\mathbb{E}_{L} \mathbb{E}_{Y}[Y|A=a, L].
\]
具体地, 为
\sum_l \mathbb{E}[Y|A=a, L=l] \mathrm{Pr}[L=l],
\]
所以该式必须满足正性, 即
\]
否则\(\mathbb{E}[Y|A=a, L=l]\)无定义.
Censoring
\]
参数模型
标准化处理的参数模型, 就是估计
\]
比如:
\]
接下来用(S, S+)的公式就可以了(一般是直接用S, 根据大数定律弄的).
Time-varying
静态
{}& \sum_{\bar{l}_K} \mathbb{E}[Y|\bar{A}_K=\bar{a}_K, \bar{L}_K=\bar{l}_K] \prod_{k=0}^K f(l_k|\bar{a}_{k-1}, \bar{l}_{k-1}) \\
=& \sum_{\bar{l}_K} \mathbb{E}[Y|\bar{A}_{K-1}=\bar{a}_{K-1}, \bar{L}_K=\bar{l}_K] \prod_{k=0}^K f(l_k|\bar{a}_{k-1}, \bar{l}_{k-1}) \\
=& \sum_{\bar{l}_K} \mathbb{E}[Y,\bar{A}_{K-1}=\bar{a}_{K-1}, \bar{L}_K=\bar{l}_K] \prod_{k=0}^{K-1} f(l_k|\bar{a}_{k-1}, \bar{l}_{k-1}) \cdot f(\bar{a}_{k-1}, \bar{l}_{k-1}) \\
=& \sum_{\bar{l}_K} \mathbb{E}[Y|\bar{A}_{K-1}=\bar{a}_{K-1}, \bar{L}_K=\bar{l}_{K-1}] \prod_{k=0}^{K-1} f(l_k|\bar{a}_{k-1}, \bar{l}_{k-1})\\
=& \cdots \\
=& \mathbb{E}[Y^{\bar{a}}].
\end{array}
\]
至于动态的, 书上给出了一个公式, 但是我感觉不是很对, 这里推导一下试试:
{}& \mathbb{E}[Y^g] \\
=& \mathbb{E}_{\bar{a}\sim g} \mathbb{E}_Y [Y^{\bar{a}}] \\
=&\sum_{\bar{a}\sim g} \sum_{\bar{l}} \mathbb{E}[Y^{\bar{a}}|\bar{A}=\bar{a}, L=\bar{l}] \cdot f(\bar{A}, \bar{L}), \\
\end{array}
\]
其中
\]
这里, \(f^{int}\)表示每一步\(g\)的根据前面历史选择\(A_k\)的概率.
IP weighting
无参数
\]
倘若\(A\)为连续变量, \(f\)为对应的条件密度函数, 则(非零的部分是零测集)
\]
当正性不成立的时候, 即存在\(l\), \(\mathrm{Pr}[L=l] > 0\), 但是\(f(A=0|L=l) = 0\), 此时
\mathbb{E}[\frac{I(A=a)Y}{f(A|L)}]
&= \mathbb{E}_{L \in Q(a)} \{\mathbb{E}[Y^a|L=l]\cdot \mathbb{E}_{A}[\frac{I(A=a)}{f(A|L)}|L]\} \\
&= \mathbb{E}_{L \in Q(a)} \{\mathbb{E}[Y^a|L=l]\} \\
&= \mathbb{E}[Y^a|L\in Q(a)]\mathrm{Pr}[L\in Q(a)]. \\
\end{array}
\]
Censoring
\]
参数模型
定义
\]
需要说明的是
\mathbb{E}[Y^a] = \frac{\mathbb{E}[I(A=a)W^AY]}{\mathbb{E}[I(A=a)W^A]}.
\]
注: 实际上分母为1.
特别的, 可以定义
\]
\mathbb{E}[Y^a] = \frac{\mathbb{E}[I(A=a)SW^AY]}{\mathbb{E}[I(A=a)SW^A]}.
\]
注: 此时分母为\(f(A)\). 在估计中, (IP+)更为稳定.
显然, 在参数模型中, 我们常常需要建模:
\]
并得到
\]
此时再进一步假设
\]
比如
\]
通过\(\widehat{W}\)或者\(\widehat{SW}\)得到\(\mathbb{E}[Y^a]\)的近似值:
\quad \mathrm{or} \quad
\frac{\sum_i I(A=a)SW_iY_i}{\sum_i I(A=a)SW_i}.
\]
通过最小二乘法来估计参数\(\theta_0, \theta_1\).
注: 一般情况下(\(A\)低维的情况), \(f(A)\)可以通过无参数估计估计, 否则也需要建模估计.
IP weighting 有一种特别好的思路, 主要到, 经过weighting之后, 相当于我们重新选择了\(A\), 此时\(A\)和\(L\)无关, 在这个伪造的人群中, 我们有
\]
注: 证明只需要用到\(A \amalg L\).
注: 在这种可建模的情况下, 正性并不重要, 而且似乎即使\(A\)是连续变量, 上述的估计方式也是奏效的, 但是说实话我无法理解.
censoring
如果由censoring的情况出现, 只需要考虑
SW^{AC} = SW^A \cdot SW^C, \\
\]
其中
SW^C = f(C|A) / f(C|A, L).
\]
条件下 V
如何用IP weighting 估计
\]
只需考虑
SW^A = f(A|V) / f(A, V, L\setminus V).
\]
分别利用(IP, IP+)即可.
注: 此时二者分母均不为1, 故不可用最普通的IP weighting的公式.
Time-varying
此时
SW^{\bar{A}} = \prod_{k=0}^K \frac{f(A_k|\bar{A}_{k-1})}{f(A_k|\bar{A}_{k-1}, \bar{L}_k)}. \\
\]
剩下的就是利用类似(IP, IP+)的公式计算.
在这种情况下, 同样有条件下V, 但是, 特别的是, \(V\)必须是baseline variables, 即
\]
注: 没看到其用于动态策略的是说明.
G-estimation
非参数模型
非参数模型可以看成是参数模型的一种特例.
参数模型
这个方法主要是用于估计
-\mathbb{E}[Y^{a'}|L].
\]
假设
\]
则
-\mathbb{E}[Y^{a=0}|L] = \beta_1 a + \beta_3 aV.
\]
假设 rank preserving 成立, 则有
\Rightarrow Y^{a=0} = Y - \psi_0 a - \psi_1 a V,
\]
并定义\(H(\psi^{\dagger}):= Y^{a=0}\).
注意到, 条件可交换性
\]
意味着
= \mathrm{Pr}[A=1|L].
\]
假设我们用一个逻辑斯蒂回归对其进行建模:
\mathrm{Pr}[A=1|Y^{a=0}, L]
= \theta_0 + \theta_1 Y^{a=0} + \theta_2 Y^{a=0}V + \theta_3 L.
\]
则根据条件可交换性的性质, \(\theta_1, \theta_2\)都应该是0, 现在\(H(\psi^{\dagger})=Y^{a=0}\), 则
\mathrm{Pr}[A=1|H(\psi^{\dagger}), L]
= \theta_0 + \theta_1 H(\psi^{\dagger})+ \theta_2 H(\psi^{\dagger})V + \theta_3 L.
\]
给定\(\psi_0, \psi_1\), 我们可以估计出一组\(\theta_0, \cdots, \theta_3\), 什么样的\(\psi_0, \psi_1\)是好的, 就是让估计的参数\(\theta_1, \theta_2\)接近0.
所以 G-estimation 常用网格法来估计.
不过应对高维问题的时候就比较捉襟见肘了.
在特殊的情况下, 我们可以有显示的表达式.
Time-varying
类似.
\]
=Y^{\bar{A}_{k+1}, \underline{0}_{k}} + A_k \gamma_k (\bar{A}_{k-1}, \bar{l}_k ;\beta).
\]
\]
通过下式来估计:
\]
Propensity Scores
该方法仅能应用于二元情形, 即\(A \in \{0, 1\}\).
当\(L\)是一个高维向量的时候, 一般的无参数模型就派不上用场了, 尽管我们可以通过参数模型来建模, 但是带来的结果是估计结果的方差会比较大.
我们记\(\pi(L) = \mathrm{Pr}[A|L]\), 并证明:
\]
不妨假设\(\pi(L) =s \Leftrightarrow L \in \{l_i\}\), 则
\mathrm{Pr}[Y^a|\pi(L)=s]
&= \mathrm{Pr} [Y^a|L \in \{l_i\}] \\
&= \frac{\sum_i\mathrm{Pr}[Y^a,L=l_i]}{\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[L=l_i]}{\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\mathrm{Pr}[A=a|L=l] \cdot \sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[L=l_i]}{\mathrm{Pr}[A=a|L=l]\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[A=a, L=l_i]}{\sum_i \mathrm{Pr} [A=a, L=l_i]}\\
&= \frac{\sum_i\mathrm{Pr}[Y, A=a, L=l_i]}{\sum_i \mathrm{Pr} [A=a, L=l_i]}\\
&= \frac{\mathrm{Pr}[Y, A=a, \pi(L)=s]}{\mathrm{Pr} [A=a, \pi(L)]}\\
&= \mathrm{Pr} [Y|A=a, \pi(L)=s].
\end{array}
\]
注意: \(\pi(l_i) = \pi(l_j) = \pi(l) = s\).
可见, 上述推导仅在\(A\)为二元变量是成立, 否则
\mathrm{Pr}[A=a'|l] = \mathrm{Pr}[A=a'|l'].
\]
也就无法保证上面的推导证明对于所有的\(A=a\)成立.
此时, 我们可以扩展causal graph为:
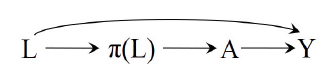
故, 我们可以通过\(\pi(L)\)来block以保证条件可交换性.
剩下的工作就是利用前面的方法了.
Instrumental Variables
Z(Z)-->T(T) -->Y(Y)
U(U)-->T(T)
U(U)-->Y(Y)
instrumental variables 满足:
- Z 对 T 有 causal effect;
- Z 到 Y 的 causal effect 均通过 T, 即 T 是 Z 到 Y 所有 direct path 上的mediator;
- Z 和 Y 之间不存在backdoor path.
Binary Linear Setting
CAG图如上图所示.
\]
\mathbb{E}[Y|Z=1] - \mathbb{E}[Y|Z=0]
=&\mathbb{E}[\delta T + \alpha U|Z=1] - \mathbb{E}[\delta T +\alpha U|Z=0] \\
=&\delta \mathbb{E}[[T|Z=1]-[T|Z=0]] + \alpha \mathbb{E}[[U|Z=1]-[ U|Z=0]] \\
=&\delta \mathbb{E}[[T|Z=1]-[T|Z=0]]
\end{array}
\]
故
\]
注: 在此CAG图中, \(U \amalg Z\).
Continuous Linear Setting
依旧是如上的CAG图.
\mathrm{Cov}(Y, Z) =
& \mathbb{E}[YZ] - \mathbb{E}[Y]\mathbb{E}[Z] \\
=& \delta (\mathbb{E}[TZ] - \mathbb{E}[T]\mathbb{E}[Z]) + \alpha
(\mathbb{E}[UZ] - \mathbb{E}[U]\mathbb{E}[Z]) \\
=& \delta \mathrm{Cov}(T, Z) + \alpha \mathrm{Cov}(U,Z)\\
=& \delta \mathrm{Cov}(T, Z)
\end{array}
\]
故
\]
注: 依然用到了\(U \amalg Z\).
Nonparametric Identification
仅考虑单个的二元变量\(T \in \{0, 1\}\), 有如下几种情况:
- Compliers: \(T^{z=1}=1, T^{z=0}=0\).
- Always-takers: \(T^{z=1}=1, T^{z=0}=1\).
- Never-takers: \(T^{z=1}=0, T^{z=0}=0\).
- Defiers: \(T^{z=1}=0, T^{z=0}=1\).
当我们所考虑的群体中仅包括前三种类型的时候, 显然有:
\]
这是我们需要的单调性假设.
此时:
\frac{\mathbb{E}[Y|Z=1]-\mathbb{E}[Y|Z=0]}{\mathbb{E}[T|Z=1]-\mathbb{E}[T|Z=0]}.
\]
即, 在compliers (遵照医嘱的) 的人群中, 可以计算出其causal effect.
证明在[2]的p93.
Difference in Difference
difference in difference 同样是处理存在unobservable变量时的一种有效的处理方法.
我们可以把\(Y^a\)拆成俩个阶段:
- \(t=0\), 此时决定\(A\), 但是并没有落实\(A\);
- \(t=1\), 实行\(A\).
凭借下面的假设:
1.
\]
- \(A=1\), \(A=0\)两个群体若都不施加治疗, 则结果一致:
=\mathbb{E}[Y_1^0 - Y_0^0|A=0],
\]
- 治疗前的状态一致:
\]
注: 上面的第二条假设可能不容易满足.
则:
=(\mathbb{E}[Y_1|A=1]-\mathbb{E}[Y_0|A=1])
-(\mathbb{E}[Y_1|A=0]-\mathbb{E}[Y_0|A=0]).
\]
Doubly Robust Estimator
未完待续
Instrumental variable estimation
未完待续
Stratification
未完待续
Matching
未完待续
Causal Inference的更多相关文章
- Targeted Learning R Packages for Causal Inference and Machine Learning(转)
Targeted learning methods build machine-learning-based estimators of parameters defined as features ...
- 【统计】Causal Inference
[统计]Causal Inference 原文传送门 http://www.stat.cmu.edu/~larry/=sml/Causation.pdf 过程 一.Prediction 和 causa ...
- 因果推理综述——《A Survey on Causal Inference》一文的总结和梳理
因果推理 本文档是对<A Survey on Causal Inference>一文的总结和梳理. 论文地址 简介 关联与因果 先有的鸡,还是先有的蛋?这里研究的是因果关系,因果关系与普通 ...
- Chapter 6 Graphical Representation of Causal Effects
目录 6.1 Causal diagrams 6.2 Causal diagrams and marginal independence 6.3 Causal diagrams and conditi ...
- Chapter 1 A Definition of Causal Effect
目录 1.1 Individual casual effects 1.2 Average casual effects 1.5 Causation versus association Hern\(\ ...
- 近年Recsys论文
2015年~2017年SIGIR,SIGKDD,ICML三大会议的Recsys论文: [转载请注明出处:https://www.cnblogs.com/shenxiaolin/p/8321722.ht ...
- 因果推理的春天-实用HTE(Heterogeneous Treatment Effects)论文github收藏
一直以来机器学习希望解决的一个问题就是'what if',也就是决策指导: 如果我给用户发优惠券用户会留下来么? 如果患者服了这个药血压会降低么? 如果APP增加这个功能会增加用户的使用时长么? 如果 ...
- Graph machine learning 工具
OGB: Open Graph Benchmark https://ogb.stanford.edu/ https://github.com/snap-stanford/ogb OGB is a co ...
- graph处理工具
仅作为记录笔记,完善中...................... 1 PyGSP https://pygsp.readthedocs.io/en/stable/index.html ht ...
随机推荐
- day01互联网架构理论
- Fragment放置后台很久(Home键退出很长时间),返回时出现Fragment重叠解决方案
后来在google查到相关资料,原因是:当Fragment长久不使用,系统进行回收,FragmentActivity调用onSaveInstanceState保存Fragment对象.很长时间后,再次 ...
- DOM解析xml学习笔记
一.dom解析xml的优缺点 由于DOM的解析方式是将整个xml文件加载到内存中,转化为DOM树,因此程序可以访问DOM树的任何数据. 优点:灵活性强,速度快. 缺点:如果xml文件比较大比较复杂会占 ...
- SpringMVC(3):AJAX
一,AJAX 简介 AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML) AJAX 不是新的编程语言,而是一种使用现有标准的新方法 ...
- 【Matlab】取整函数:fix/round/floor/ceil
fix-向零方向取整.(向中间取整) round-向最近的方向取整.(四舍五入) floor-向负无穷大方向取整.(向下取整) ceil-向正无穷大方向取整.(向上取整)
- Nginx区分PC和手机
目录 一.简介 二.配置 nginx识别手机端跳转到wap pc端跳转移动端 一.简介 有时候需要当手机访问PC站页面时自动跳转到对应的手机站页面. 二.配置 nginx识别手机端跳转到wap 即手机 ...
- [WPF] 用 OpacityMask 模仿 UWP 的 Text Shimmer 动画
1. UWP 的 Text Shimmer 动画 在 UWP 的 Windows Composition Samples 中有一个 Text Shimmer 动画,它用于展示如何使用 Composit ...
- React中使用 react-router-dom 路由传参的三种方式详解【含V5.x、V6.x】!!!
路由传值的三种方式(v5.x) params参数 //路由链接(携带参数): <Link to='/demo/test/tom/18'}>详情</Link> //或 <L ...
- zctf_2016_note3(unlink)
这道题完全没想到漏洞在哪(还是菜了) 这道题目我通过海哥的博客学习的 (16条消息) zctf_2016_note3_seaaseesa的博客-CSDN博客 例行检查我就不放了 进入edit页面 这里 ...
- UVA294 约数 Divisors 题解
Content 给定 \(n\) 个区间 \([l,r]\),求出每个区间内约数个数最大的数. 数据范围:\(1\leqslant l<r\leqslant 10^{10}\),\(r-l\le ...