Not All Samples Are Created Equal: Deep Learning with Importance Sampling
@article{katharopoulos2018not,
title={Not All Samples Are Created Equal: Deep Learning with Importance Sampling},
author={Katharopoulos, Angelos and Fleuret, F},
journal={arXiv: Learning},
year={2018}}
概
本文提出一种删选合适样本的方法, 这种方法基于收敛速度的一个上界, 而并非完全基于gradient norm的方法, 使得计算比较简单, 容易实现.
主要内容
设\((x_i,y_i)\)为输入输出对, \(\Psi(\cdot;\theta)\)代表网络, \(\mathcal{L}(\cdot, \cdot)\)为损失函数, 目标为
\theta^* = \arg \min_{\theta} \frac{1}{N} \sum_{i=1}^N\mathcal{L}(\Psi(x_i;\theta),y_i),
\]
其中\(N\)是总的样本个数.
假设在第\(t\)个epoch的时候, 样本(被选中)的概率分布为\(p_1^t,\ldots,p_N^t\), 以及梯度权重为\(w_1^t, \ldots, w_N^t\), 那么\(P(I_t=i)=p_i^t\)且
\theta_{t+1}=\theta_t-\eta w_{I_t}\nabla_{\theta_t} \mathcal{L}(\Psi(x_{I_t};\theta_t),y_{I_t}),
\]
在一般SGD训练中\(p_i=1/N,w_i=1\).
定义\(S\)为SGD的收敛速度为:
S :=-\mathbb{E}_{P_t}[\|\theta_{t+1}-\theta^*\|_2^2-\|\theta_t-\theta^*\|_2^2],
\]
如果我们令\(w_i=\frac{1}{Np_i}\) 则
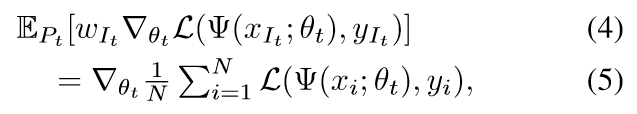
定义\(G_i=w_i\nabla_{\theta_t} \mathcal{L}(\Psi(x_{i};\theta_t),y_{i})\)

我们自然希望\(S\)能够越大越好, 此时即负项越小越好.
定义\(\hat{G}_i \ge \|\nabla_{\theta_t} \mathcal{L}(\Psi(x_{i};\theta_t),y_{i})\|_2\), 既然
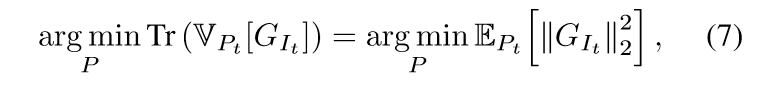
(7)式我有点困惑,我觉得(7)式右端和最小化(6)式的负项(\(\mathrm{Tr}(\mathbb{V}_{P_t}[G_{I_t}])+\|\mathbb{E}_{P_t}[G_{I_t}]\|_2^2\))是等价的.
于是有
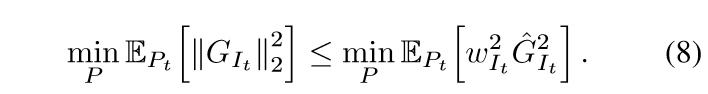
最小化右端(通过拉格朗日乘子法)可得\(p_i \propto \hat{G}_i\), 所以现在我们只要找到一个\(\hat{G}_i\)即可.
这个部分需要引入神经网络的反向梯度的公式, 之前有讲过,只是论文的符号不同, 这里不多赘诉了.

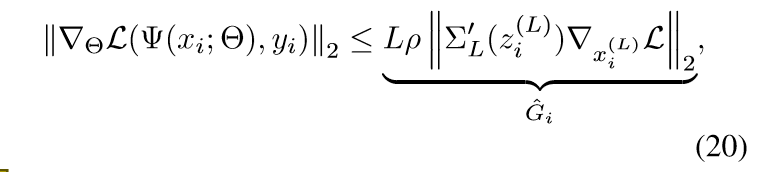
注意\(\rho\)的计算是比较复杂的, 但是\(p_i \propto \hat{G}_i\), 所以我们只需要计算\(\|\cdot\|\)部分, 设此分布为\(g\).
另外, 在最开始的时候, 神经网络没有得到很好的训练, 权重大小相差无几, 这个时候是近似正态分布的, 所以作者考虑设计一个指标,来判断是否需要根据样本分布\(g\)来挑选样本. 作者首先衡量

显然当这部分足够大的时候我们可以采用分布\(g\)而非正态分布\(u\), 但是这个指标不易判断, 作者进步除以\(\mathrm{Tr}(\mathbb{V}_u[G_i])\).

显然\(\tau\)越大越好, 我们自然可以人为设置一个\(\tau_{th}\). 算法如下

最后, 个人认为这个算法能减少计算量主要是因为样本少了, 少在一开始用正态分布抽取了一部分, 所以...
"代码"
主要是\(\hat{G}_i\)部分的计算, 因为涉及到中间变量的导数, 所以需要用到retain_grad().
"""
这里只是一个例子
"""
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.dense = nn.Sequential(
nn.Linear(10, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
self.final = nn.ReLU()
def forward(self, x):
z = self.dense(x)
z.retain_grad()
out = self.final(z)
return out, z
if __name__ == "__main__":
net = Net()
criterion = nn.MSELoss()
x = torch.rand((2, 10))
y = torch.rand((2, 10))
out, z = net(x)
loss = criterion(out, y)
loss.backward()
print(z.grad) #这便是我们所需要的
Not All Samples Are Created Equal: Deep Learning with Importance Sampling的更多相关文章
- Accelerating Deep Learning by Focusing on the Biggest Losers
目录 概 相关工作 主要内容 代码 Accelerating Deep Learning by Focusing on the Biggest Losers 概 思想很简单, 在训练网络的时候, 每个 ...
- (转) The major advancements in Deep Learning in 2016
The major advancements in Deep Learning in 2016 Pablo Tue, Dec 6, 2016 in MACHINE LEARNING DEEP LEAR ...
- Deep Learning in R
Introduction Deep learning is a recent trend in machine learning that models highly non-linear repre ...
- Summary on deep learning framework --- PyTorch
Summary on deep learning framework --- PyTorch Updated on 2018-07-22 21:25:42 import osos.environ[ ...
- [C3] Andrew Ng - Neural Networks and Deep Learning
About this Course If you want to break into cutting-edge AI, this course will help you do so. Deep l ...
- Deep Learning 5_深度学习UFLDL教程:PCA and Whitening_Exercise(斯坦福大学深度学习教程)
前言 本文是基于Exercise:PCA and Whitening的练习. 理论知识见:UFLDL教程. 实验内容:从10张512*512自然图像中随机选取10000个12*12的图像块(patch ...
- (转)WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE
Main Menu Fortune.com E-mail Tweet Facebook Linkedin Share icons By Roger Parloff Illustration ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- (转)The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)
Adit Deshpande CS Undergrad at UCLA ('19) Blog About The 9 Deep Learning Papers You Need To Know Abo ...
随机推荐
- 日常Java 2021/10/11
抽象类 所有对象都是通过类描述的,但不是所有的类都是用来描述对象,就好比抽象类,此类中没有足够的信息描述一个对象. 抽象类不能实例化对象,所以抽象类必须的继承,才可以使用. 抽象方法 Abstract ...
- Jenkins:参数化构建:分支|模块|回滚|打印日志
@ 目录 多分支 安装Git Parameter Plug-In 配置参数 选择构建分支 分模块 前提 分模块build 参数配置 分模块shell脚本 mvn 的基本用法 分模块运行 Jenkins ...
- Linux(CentOS)升级gcc版本
本人使用的是CentOS 6.2 64位系统,由于在安装系统的时候并没有勾选安装gcc编译器,因此需要自行安装gcc编译器. 系统信息查看命令: cat /etc/redhat-release 使用y ...
- markDodn使用技巧
markdown 标题 一级标题书写语法: 井符(#)加上空格加上标题名称 二级标题书写语法: 两个井符(#)加上空格加上标题名称 三级标题书写语法: 三个井符(#)加上空格加上标题名称 字体 字体加 ...
- Cilium 1.11 发布,带来内核级服务网格、拓扑感知路由....
原文链接:https://isovalent.com/blog/post/2021-12-release-111 作者:Cilium 母公司 Isovalent 团队 译者:范彬,狄卫华,米开朗基杨 ...
- 严重危害警告!Log4j 执行漏洞被公开!
12 月 10 日凌晨,Apache 开源项目 Log4j2 的远程代码执行漏洞细节被公开,漏洞威胁等级为:严重. Log4j2 是一个基于 Java 的日志记录工具.它重写了 Log4j 框架,引入 ...
- malloc实现
任何一个用过或学过C的人对malloc都不会陌生.大家都知道malloc可以分配一段连续的内存空间,并且在不再使用时可以通过free释放 掉.但是,许多程序员对malloc背后的事情并不熟悉,许多人甚 ...
- LuoguB2078 含 k 个 3 的数 题解
Content 给定一个数 \(n\),判断其数位中是否恰好有 \(k\) 个 \(3\). 数据范围:\(1<n\leqslant 10^{15}\),\(1<k\leqslant 15 ...
- LuoguP7080 [NWRRC2013]Ballot Analyzing Device 题解
Content 有 \(n\) 名选手参加一个比赛,有 \(m\) 个人为他们投票.第 \(i\) 个人的投票情况用一个长度为 \(n\),并且仅包含 . 和 X 两个字符的字符串,其中,如果第 \( ...
- 手动上下eureka上面服务
手动下eureka curl -X PUT http://eureka.xxx.xxx.com/eureka/apps/VIDEO-API/111.111.111.111:test-api:0000/ ...