第七章:网络优化与正则化(Part1)
任何数学技巧都不能弥补信息的缺失.
——科尼利厄斯·兰佐斯(Cornelius Lanczos)
匈牙利数学家、物理学家
文章相关
虽然神经网络具有非常强的表达能力,但是当应用神经网络模型到机器学习时依然存在一些难点问题.主要分为两大类:
- 优化问题:深度神经网络的优化十分困难.首先,神经网络的损失函数是一个非凸函数,找到全局最优解通常比较困难.其次,深度神经网络的参数通常非常多,训练数据也比较大,因此也无法使用计算代价很高的二阶优化方法,而一阶优化方法的训练效率通常比较低.此外,深度神经网络存在梯度消失或爆炸问题,导致基于梯度的优化方法经常失效.
- 泛化问题:由于深度神经网络的复杂度比较高,并且拟合能力很强,很容易在训练集上产生过拟合.因此在训练深度神经网络时,同时也需要通过一定的正则化方法来改进网络的泛化能力.
目前,研究者从大量的实践中总结了一些经验方法,在神经网络的表示能 力、复杂度、学习效率和泛化能力之间找到比较好的平衡,并得到一个好的网络 模型.本章从网络优化和网络正则化两个方面来介绍这些方法.在网络优化方面,介绍一些常用的优化算法、参数初始化方法、数据预处理方法、逐层归一化方 法和超参数优化方法.在网络正则化方面,介绍一些提高网络泛化能力的方法, 包括 L1 和 L2 正则化、权重衰减、提前停止、丢弃法、数据增强和标签平滑.
7.1 网络优化
网络优化是指寻找一个神经网络模型来使得经验(或结构)风险最小化的过程,包括模型选择以及参数学习等.深度神经网络是一个高度非线性的模型,其风险函数是一个非凸函数,因此风险最小化是一个非凸优化问题.此外,深度 神经网络还存在梯度消失问题.因此,深度神经网络的优化是一个具有挑战性的 问题.本节概要地介绍神经网络优化的一些特点和改善方法.
7.1.1 网络优化难点
1. 网络结构多样性
神经网络的种类非常多,比如卷积网络、循环网络、图网络等.不同网络的结构也非常不同,有些比较深,有些比较宽.不同参数在网络中的作用也有很大的 差异,比如连接权重和偏置的不同,以及循环网络中循环连接上的权重和其他权 重的不同.
由于网络结构的多样性,我们很难找到一种通用的优化方法.不同优化方法 在不同网络结构上的表现也有比较大的差异.
此外,网络的超参数一般比较多,这也给优化带来很大的挑战.
2. 高维变量的非凸优化
低维空间的非凸优化问题主要是存在一些局部最优点.基于梯度下降的优化方法会陷入局部最优点,因此在低维空间中非凸优化的主要难点是如何选择 初始化参数和逃离局部最优点.深度神经网络的参数非常多,其参数学习是在 非常高维空间中的非凸优化问题,其挑战和在低维空间中的非凸优化问题有所 不同.
鞍点:在高维空间中,非凸优化的难点并不在于如何逃离局部最优点,而是如何逃离鞍点(Saddle Point)[Dauphin et al., 2014].鞍点的梯度是 0,但是在一些维度上是最高点,在另一些维度上是最低点,如图7.1所示.
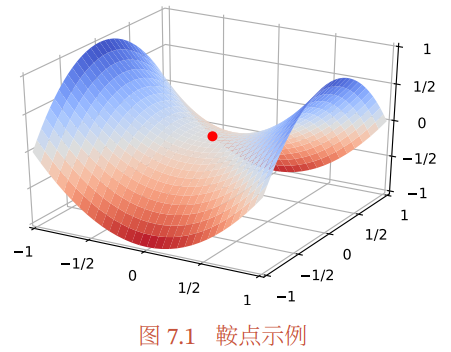
在高维空间中,局部最小值(Local Minima)要求在每一维度上都是最低点,这种概率非常低.假设网络有 10, 000 维参数,梯度为 0 的点(即驻点(Sta-tionary Point))在某一维上是局部最小值的概率为 $$,那么在整个参数空间中,驻点是局部最优点的概率为 $^{10,000}$ ,这种可能性非常小.也就是说,在高维空间中大部分驻点都是鞍点.
基于梯度下降的优化方法会在鞍点附近接近于停滞,很难从这些鞍点中逃离.因此,随机梯度下降对于高维空间中的非凸优化问题十分重要,通过在梯度方向上引入随机性,可以有效地逃离鞍点.
平坦最小值:深度神经网络的参数非常多,并且有一定的冗余性,这使得每单个参数对最终损失的影响都比较小,因此会导致损失函数在局部最小解附近通常是一个平坦的区域,称为平坦最小值(Flat Minima)[Hochreiter et al., 1997; Li et al., 2017a].图7.2给出了平坦最小值和尖锐最小值(Sharp Minima)的示例.
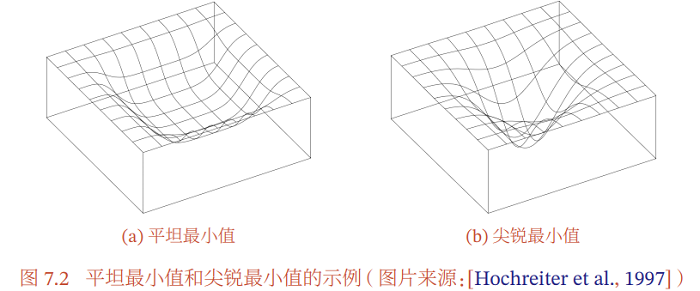
在一个平坦最小值的邻域内,所有点对应的训练损失都比较接近,表明我们在训练神经网络时,不需要精确地找到一个局部最小解,只要在一个局部最小解的邻域内就足够了.平坦最小值通常被认为和模型泛化能力有一定的关系.一般而言,当一个模型收敛到一个平坦的局部最小值时,其鲁棒性会更好,即微小的参数变动不会剧烈影响模型能力;而当一个模型收敛到一个尖锐的局部最小值 时,其鲁棒性也会比较差.具备良好泛化能力的模型通常应该是鲁棒的,因此理 想的局部最小值应该是平坦的.
局部最小解的等价性:在非常大的神经网络中,大部分的局部最小解是等价的, 它们在测试集上性能都比较相似.此外,局部最小解对应的训练损失都可能非常 接近于全局最小解对应的训练损失 [Choromanska et al., 2015].虽然神经网络 有一定概率收敛于比较差的局部最小值,但随着网络规模增加,网络陷入比较差的局部最小值的概率会大大降低.在训练神经网络时,我们通常没有必要找全局最小值,这反而可能导致过拟合.
7.1.2 神经网络优化的改善方法
改善神经网络优化的目标是找到更好的局部最小值和提高优化效率.目前 比较有效的经验性改善方法通常分为以下几个方面:
- 使用更有效的优化算法(第7.2节)来提高梯度下降优化方法的效率和稳定性,比如动态学习率调整、梯度估计修正等.
- 使用更好的参数初始化方法(第7.3节)、数据预处理方法(第7.4节) 来提高优化效率.
- 修改网络结构来得到更好的优化地形(Optimization Landscape).
优化地形指在高维空间中损失函数的曲面形状.好的优化地形通常比较平滑.
7.2 优化算法
目前,深度神经网络的参数学习主要是通过梯度下降法来寻找一组可以最小化结构风险的参数.在具体实现中,梯度下降法可以分为:批量梯度下降、随机梯度下降以及小批量梯度下降三种形式.根据不同的数据量和参数量,可以选择一种具体的实现形式.本节介绍一些在训练神经网络时常用的优化算法.这些优化算法大体上可以分为两类:1)调整学习率,使得优化更稳定;2)梯度估计修正,优化训练速度.
7.2.1 小批量梯度下降
在训练深度神经网络时,训练数据的规模通常都比较大.如果在梯度下降 时,每次迭代都要计算整个训练数据上的梯度,这就需要比较多的计算资源.另 外大规模训练集中的数据通常会非常冗余,也没有必要在整个训练集上计算梯 度.因此,在训练深度神经网络时,经常使用小批量梯度下降法(Mini-Batch Gradient Descent).
令 $(; ) $表示一个深度神经网络,$$ 为网络参数,在使用小批量梯度下降进行优化时,每次选取 $$ 个训练样本 $\mathcal{S}_{t}=\left\{\left(\boldsymbol{x}^{(k)}, \boldsymbol{y}^{(k)}\right)\right\}_{k=1}^{K}$ .第 $$ 次迭代(Iteration) 时损失函数关于参数 $$ 的偏导数为
$\mathfrak{g}_{t}(\theta)=\frac{1}{K} \sum_{(\boldsymbol{x}, \boldsymbol{y}) \in \delta_{t}} \frac{\partial \mathcal{L}(\boldsymbol{y}, f(\boldsymbol{x} ; \theta))}{\partial \theta}$
其中 $\mathcal{L}(\cdot)$ 为可微分的损失函数,$$ 称为批量大小(Batch Size).
第 $$ 次更新的梯度 $g_$ 定义为
$\mathbf{g}_{t} \triangleq \mathfrak{g}_{t}\left(\theta_{t-1}\right)$
使用梯度下降来更新参数,
$\theta_{t} \leftarrow \theta_{t-1}-\alpha \mathbf{g}_{t}$
其中 $\alpha > 0$ 为学习率.
每次迭代时参数更新的差值 $\Delta \theta_{t}$ 定义为
$\Delta \theta_{t} \triangleq \theta_{t}-\theta_{t-1}$
$\Delta \theta_{t}$ 和梯度 $\mathbf{g}_{t}$ 并不需要完全一致.$\Delta \theta_{t}$ 为每次迭代时参数的实际更新方向,即 $\theta_{t}=\theta_{t-1}+\Delta \theta_{t}$.在标准的小批量梯度下降中,$\Delta \theta_{t}=-\alpha \mathbf{g}_{t}$.
从上面公式可以看出,影响小批量梯度下降法的主要因素有:1)批量大小 、2)学习率 、3)梯度估计.为了更有效地训练深度神经网络,在标准的小批 量梯度下降法的基础上,也经常使用一些改进方法以加快优化速度,比如如何选 择批量大小、如何调整学习率以及如何修正梯度估计.我们分别从这三个方面来 介绍在神经网络优化中常用的算法.这些改进的优化算法也同样可以应用在批量或随机梯度下降法上.
7.2.2 批量大小选择
在小批量梯度下降法中,批量大小(Batch Size)对网络优化的影响也非常大.一般而言,批量大小不影响随机梯度的期望,但是会影响随机梯度的方差.批量大小越大,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,因此可以设置较大的学习率.而批量大小较小时,需要设置较小的学习率,否则模型会不收敛.学习率通常要随着批量大小的增大而相应地增大.一个简单有效的方法是线性缩放规则(Linear Scaling Rule)[Goyal et al., 2017]:当批量大小增加 倍时,学习率也增加 倍 .线性缩放规则往往在批量大小比较小时适用,当批量大小非常大时,线性缩放会使得训练不稳定.
知识:
方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。
$\sigma^{2}=\frac{\sum(X-\mu)^{2}}{N}$
$\sigma^{2} $ 为总体方差,$ X$ 为变量, $\mu$ 为总体均值, $N$ 为总体例数。
图7.3给出了从回合(Epoch)和迭代(Iteration)的角度,批量大小对损失 下降的影响.每一次小批量更新为一次迭代,所有训练集的样本更新一遍为一个 回合,两者的关系为
$1 \text { 回合 }(\text { Epoch })=\left(\frac{\text { 训练样本的数量 } N}{\text { 批量大小 }}\right) \times \text { 迭代 }(\text { Iteration })$
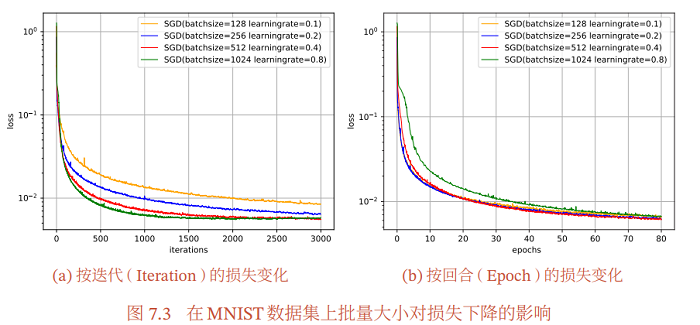
从图7.3a可以看出,批量大小越大,下降效果越明显,并且下降曲线越平滑.但从图7.3b可以看出,如果按整个数据集上的回合(Epoch)数来看,则是批量样本数越小,下降效果越明显.适当小的批量会导致更快的收敛.
此外,批量大小和模型的泛化能力也有一定的关系.[Keskar et al., 2016] 通 过实验发现:批量越大,越有可能收敛到尖锐最小值;批量越小,越有可能收敛到平坦最小值.
7.2.3 学习率调整
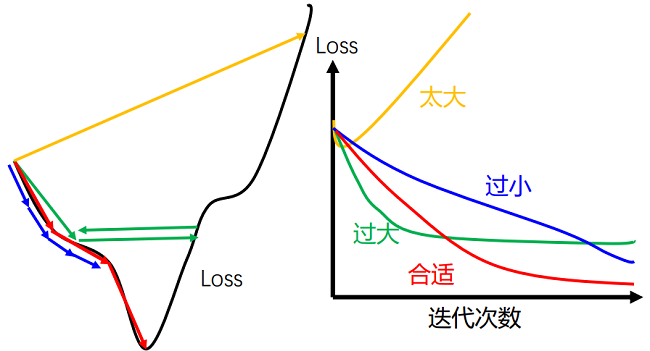
学习率是神经网络优化时的重要超参数.在梯度下降法中,学习率 的取值 非常关键,如果过大就不会收敛,如果过小则收敛速度太慢.常用的学习率调整 方法包括学习率衰减、学习率预热、周期性学习率调整以及一些自适应调整学习 率的方法,比如 AdaGrad、RMSprop、AdaDelta 等.自适应学习率方法可以针对 每个参数设置不同的学习率
7.2.3.1 学习率衰减
从经验上看,学习率在一开始要保持大些来保证收敛速度,在收敛到最优点附近时要小些以避免来回振荡.比较简单的学习率调整可以通过学习率衰减 (Learning Rate Decay)的方式来实现,也称为学习率退火(Learning Rate An- nealing).
不失一般性,这里的衰减方式设置为按迭代次数进行衰减.
假设初始化学习率为 $_0$ ,在第 $$ 次迭代时的学习率 $_$ .常见的衰减方法有以 下几种:
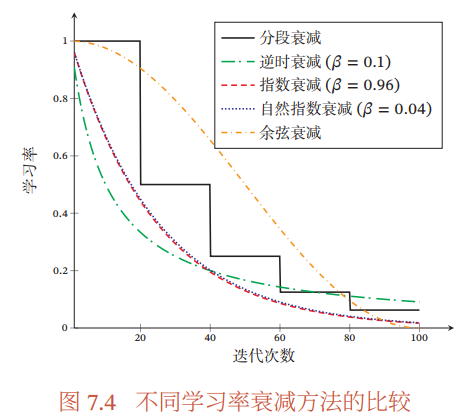
分段常数衰减(Piecewise Constant Decay):即每经过 $_1 , _2 , ⋯ , _$ 次迭代将学习率衰减为原来的 $_1 , _2 , ⋯ , _$ 倍,其中 $_$ 和 $_ < 1$ 为根据经验设置的超参数.分段常数衰减也称为阶梯衰减(Step Decay)
逆时衰减(Inverse Time Decay):
$\alpha_{t}=\alpha_{0} \frac{1}{1+\beta \times t}$
其中 $$ 为衰减率.
指数衰减(Exponential Decay):
$\alpha_{t}=\alpha_{0} \beta^{t}$
其中 $ < 1$ 为衰减率.
自然指数衰减(Natural Exponential Decay):
$\alpha_{t}=\alpha_{0} \exp (-\beta \times t)$
其中 $$ 为衰减率.
余弦衰减(Cosine Decay):
$\alpha_{t}=\frac{1}{2} \alpha_{0}\left(1+\cos \left(\frac{t \pi}{T}\right)\right)$
其中 $$ 为总的迭代次数.
7.2.3.2 学习率预热
在小批量梯度下降法中,当批量大小的设置比较大时,通常需要比较大的学习率.但在刚开始训练时,由于参数是随机初始化的,梯度往往也比较大,再加上比较大的初始学习率,会使得训练不稳定.
为了提高训练稳定性, 我们可以在最初几轮迭代时, 采用比较小的学习率,等梯度下降到一定程度后再恢复到初始的学习率,这种方法称为学习率预热(Learning Rate Warmup).
一个常用的学习率预热方法是逐渐预热(Gradual Warmup)[Goyal et al., 2017].假设预热的迭代次数为 $^ ′$ ,初始学习率为 $_0$ ,在预热过程中,每次更新的学习率为
$\alpha_{t}^{\prime}=\frac{t}{T^{\prime}} \alpha_{0}, \quad 1 \leq t \leq T^{\prime}$
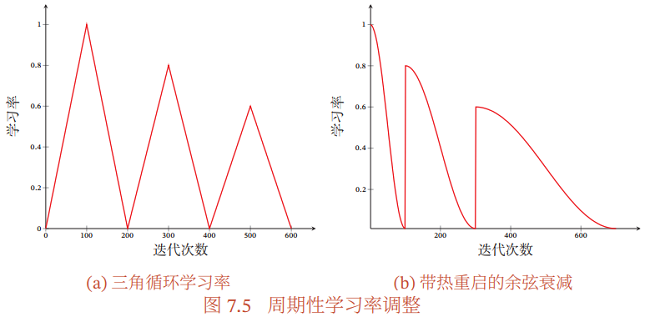
7.2.3.3 周期性学习率调整
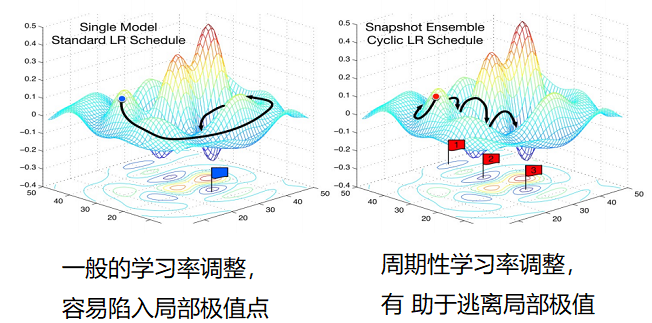
为了使得梯度下降法能够逃离鞍点或尖锐最小值,一种经验性的方式是在训练过程中周期性地增大学习率.当参数处于尖锐最小值附近时,增大学习率有助于逃离尖锐最小值;当参数处于平坦最小值附近时,增大学习率依然有可能在该平坦最小值的吸引域(Basin of Attraction)内.因此,周期性地增大学习率虽然可能短期内损害优化过程,使得网络收敛的稳定性变差,但从长期来看有助于找到更好的局部最优解.
本节介绍两种常用的周期性调整学习率的方法:循环学习率和带热重启的随机梯度下降.
循环学习率:一种简单的方法是使用循环学习率(Cyclic Learning Rate)[Goyal et al., 2017],即让学习率在一个区间内周期性地增大和缩小.通常可以使用线性缩放来调整学习率,称为三角循环学习率(Triangular Cyclic Learning Rate).
假设每个循环周期的长度相等都为 $2Δ$,其中前 $ Δ$ 步为学习率线性增大阶段, 后 $Δ$ 步为学习率线性缩小阶段.在第 $$ 次迭代时,其所在的循环周期数 $ $为
$m=\left\lfloor 1+\frac{t}{2 \Delta T}\right\rfloor$
其中 $⌊⋅⌋$ 表示“向下取整”函数.第 $$ 次迭代的学习率为
$\alpha_{t}=\alpha_{\min }^{m}+\left(\alpha_{\max }^{m}-\alpha_{\min }^{m}\right)(\max (0,1-b))$
其中 $\alpha_{\max }^{m}$ 和 $\alpha_{\min }^{m}$ 分别为第 $m$ 个周期中学习率的上界和下界, 可以随着 $m$ 的增 大而逐渐降低; $b \in[0,1]$ 的计算为
$b=\left|\frac{t}{\Delta T}-2 m+1\right|$
带热重启的随机梯度下降:带热重启的随机梯度下降(Stochastic Gradient De- scent with Warm Restarts,SGDR)[Loshchilov et al., 2017a] 是用热重启方式来替代学习率衰减的方法.学习率每间隔一定周期后重新初始化为某个预先设定值,然后逐渐衰减.每次重启后模型参数不是从头开始优化,而是从重启前的参数基础上继续优化.
假设在梯度下降过程中重启 $$ 次,第 $$ 次重启在上次重启开始第 $_$ 个回 合后进行,$_$ 称为重启周期.在第 $$ 次重启之前,采用余弦衰减来降低学习率. 第 $t$ 次迭代的学习率为
$\alpha_{t}=\alpha_{\min }^{m}+\frac{1}{2}\left(\alpha_{\max }^{m}-\alpha_{\min }^{m}\right)\left(1+\cos \left(\frac{T_{c u r}}{T_{m}} \pi\right)\right)$
其中 $\alpha_{\max }^{m}$ 和 $\alpha_{\min }^{m}$ 分别为第 $m$ 个周期中学习率的上界和下界, 可以随着 $m $ 的增大而逐渐降低; $T_{c u r} $ 为从上次重启之后的回合 ( Epoch ) 数. $T_{c u r}$ 可以取小数, 比 如 $0.1 、 0.2$ 等, 这样可以在一个回合内部进行学习率衰减. 重启周期 $T_{m}$ 可以随着 重启次数逐渐增加,比如 $T_{m}=T_{m-1} \times \kappa$ , 其中 $\kappa \geq 1$ 为放大因子.
图7.5给出了两种周期性学习率调整的示例(假设初始学习率为 1),每个周期中学习率的上界也逐步衰减.
学习率衰减的局限性:
- 非自适应,不能够根据当前梯度情况做出调整.
- 每个参数的维度上收敛速度都不相同,应该根据不同参数的收敛情况分别设置学习率.
7.2.3.4 AdaGrad 算法
在标准的梯度下降法中,每个参数在每次迭代时都使用相同的学习率.由于每个参数的维度上收敛速度都不相同,因此根据不同参数的收敛情况分别设置学习率.
AdaGrad 算法(Adaptive Gradient Algorithm)[Duchi et al., 2011] 是借鉴 $L2$ 正则化的思想,每次迭代时自适应地调整每个参数的学习率.
在第 $$ 次迭代时, 先计算每个参数梯度平方的累计值
$G_{t}=\sum_{\tau=1}^{t} \mathbf{g}_{\tau} \odot \mathbf{g}_{\tau}$
其中 $\odot$ 为按元素乘积, $\boldsymbol{g}_{\tau} \in \mathbb{R}^{|\theta|}$ 是第 $\tau$ 次迭代时的梯度.
AdaGrad 算法的参数更新差值为
$\Delta \theta_{t}=-\frac{\alpha}{\sqrt{G_{t}+\epsilon}} \odot \mathbf{g}_{t}$
其中 $\alpha$ 是初始的学习率, $\epsilon$ 是为了保持数值稳定性而设置的非常小的常数, 一般 取值 $\mathrm{e}^{-7} $到 $\mathrm{e}^{-10}$ . 此外,这里的开平方、除、加运算都是按元素进行的操作.
在 AdaGrad 算法中, 如果某个参数的偏导数累积比较大, 其学习率相对较小; 相反, 如果其偏导数累积较小,其学习率相对较大. 但整体是随着迭代次数的增加,学习率逐渐缩小.
AdaGrad 算法的缺点是在经过一定次数的迭代依然没有找到最优点时, 由于这时的学习率已经非常小,很难再继续找到最优点。
举例:$w_{i}$ 是模型的一个参数 ,$\theta=\left\{w_{1}, \ldots, w_{i}, \ldots, w_{|\theta|}\right\}$
开始计算:
${\large w_{i}^{1} \leftarrow w_{i}^{0}-\frac{a}{\sigma_{i}^{0}} g_{i}^{0} \quad \sigma_{i}^{0}=\sqrt{\left(g_{i}^{0}\right)^{2}+\delta}} $
${\large w_{i}^{2} \leftarrow w_{i}^{1}-\frac{a}{\sigma_{i}^{1}} g_{i}^{1} \quad \sigma_{i}^{1}=\sqrt{\left(g_{i}^{0}\right)^{2}+\left(g_{i}^{1}\right)^{2}+\delta}}$
${\large w_{i}^{3} \leftarrow w_{i}^{2}-\frac{a}{\sigma_{i}^{2}} g_{i}^{2} \quad \sigma_{i}^{2}=\sqrt{\left(g_{i}^{0}\right)^{2}+\left(g_{i}^{1}\right)^{2}+\left(g_{i}^{2}\right)^{2}+\delta}}$
.......
${\large w_{i}^{t+1} \leftarrow w_{i}^{t}-\frac{a}{\sigma_{i}^{t}} g_{i}^{t} \quad \sigma_{i}^{t}=\sqrt{\sum_{\tau=0}^{t}\left(g_{i}^{\tau}\right)^{2}+\delta}}$
梯度下降:
${\large w_{i}^{t+1} \leftarrow w_{i}^{t}-a g_{i}^{t} \longrightarrow}$ 大梯度,大步长
AdaGrad:
${\large w_{i}^{t+1} \leftarrow w_{i}^{t}-\frac{a}{\sqrt{\sum_{\tau=0}^{t}\left(g_{i}^{\tau}\right)^{2}+\delta}} g_{i}^{t}}$
算法过程:

7.2.3.5 RMSprop 算法
RMSprop 算法是 Geoff Hinton 提出的一种自适应学习率的方法 [Tieleman et al., 2012],可以在有些情况下避免 AdaGrad 算法中学习率不断单调下降以至于过早衰减的缺点.
RMSprop:将 $G^t$ 的计算由累积方式变成了指数衰减移动平均。
RMSprop 算法首先计算每次迭代梯度 $_$ 平方的指数衰减移动平均,
$G_{t}=\beta G_{t-1}+(1-\beta) \mathbf{g}_{t} \odot \mathbf{g}_{t}$
$=(1-\beta) \sum^{t} \beta^{t-\tau} \mathbf{g}_{\tau} \odot \mathbf{g}_{\tau}$
其中 $$ 为衰减率,一般取值为 0.9.
RMSprop 算法的参数更新差值为
$\Delta \theta_{t}=-\frac{\alpha}{\sqrt{G_{t}+\epsilon}} \odot \mathbf{g}_{t}$
其中 $$ 是初始的学习率,比如 0.001.
从上式可以看出,RMSProp 算法和 AdaGrad 算法的区别在于 $_$ 的计算由累积方式变成了指数衰减移动平均.在迭代过程中,每个参数的学习率并不是呈衰减趋势,既可以变小也可以变大.
举例:$w_{i}$ 是模型的一个参数 ,$\theta=\left\{w_{1}, \ldots, w_{i}, \ldots, w_{|\theta|}\right\}$
${\large w_{i}^{1} \leftarrow w_{i}^{0}-\frac{a}{\sigma_{i}^{0}} g_{i}^{0} \quad \sigma_{i}^{0}=g_{i}^{0}}$
${\large w_{i}^{2} \leftarrow w_{i}^{1}-\frac{a}{\sigma_{i}^{1}} g_{i}^{1} \quad \sigma_{i}^{1}=\sqrt{\beta\left(\sigma_{i}^{0}\right)^{2}+(1-\beta)\left(g_{i}^{1}\right)^{2}+\delta}}$
${\large w_{i}^{3} \leftarrow w_{i}^{2}-\frac{a}{\sigma_{i}^{2}} g_{i}^{2} \quad \sigma_{i}^{2}=\sqrt{\beta\left(\sigma_{i}^{1}\right)^{2}+(1-\beta)\left(g_{i}^{2}\right)^{2}+\delta}} $
.......
${\large w_{i}^{t+1} \leftarrow w_{i}^{t}-\frac{a}{\sigma_{i}^{t}} g_{i}^{t} \quad \sigma_{i}^{t}=\sqrt{\beta\left(\sigma_{i}^{t-1}\right)^{2}+(1-\beta)\left(g_{i}^{t}\right)^{2}+\delta}} $
算法过程:

7.2.3.6 AdaDelta 算法
AdaDelta 算法[Zeiler, 2012] 也是 AdaGrad 算法的一个改进.和 RMSprop 算法类似,AdaDelta 算法通过梯度平方的指数衰减移动平均来调整学习率.
AdaDelta算法也像RMSProp算法一样,使用了小批量随机梯度$\boldsymbol{g}_t$按元素平方的指数加权移动平均变量$\boldsymbol{s}_t$。在时间步0,它的所有元素被初始化为0。给定超参数$0 \leq \rho < 1$(对应RMSProp算法中的$\gamma$),在时间步$t>0$,同RMSProp算法一样计算:
$\boldsymbol{s}_t \leftarrow \rho \boldsymbol{s}_{t-1} + (1 - \rho) \boldsymbol{g}_t \odot \boldsymbol{g}_t. $
与RMSProp算法不同的是,AdaDelta算法还维护一个额外的状态变量$\Delta\boldsymbol{x}t$,其元素同样在时间步0时被初始化为0。
Step1:我们使用$\Delta\boldsymbol{x}_{t-1}$来计算自变量的变化量:
$\boldsymbol{g}_{t}^{\prime} \leftarrow \sqrt{\frac{\Delta x _{t-1}+\epsilon}{s_t+\epsilon}} \odot \boldsymbol{g}_{t}$
其中$\epsilon$是为了维持数值稳定性而添加的常数,如$10^{-5}$。
Step2:接着更新自变量:
$\boldsymbol{x}_t \leftarrow \boldsymbol{x}_{t-1} - \boldsymbol{g}'_t. $
Step3:我们使用$\Delta\boldsymbol{x}_t$来记录自变量变化量$\boldsymbol{g}'_t$按元素平方的指数加权移动平均:
$\Delta\boldsymbol{x}_t \leftarrow \rho \Delta\boldsymbol{x}_{t-1} + (1 - \rho) \boldsymbol{g}'_t \odot \boldsymbol{g}'_t. $
可以看到,如不考虑 $\epsilon$ 的影响,AdaDelta算法跟RMSProp算法的不同之处在于使用 $\sqrt{\Delta\boldsymbol{x}_{t-1}}$ 来替代学习率 $\eta$。
7.2.4 梯度估计修正
除了调整学习率之外,还可以进行梯度估计(Gradient Estimation)的修正.从图7.3看出,在随机(小批量)梯度下降法中,如果每次选取样本数量比较小,损失会呈现振荡的方式下降.也就是说,随机梯度下降方法中每次迭代的梯度估计和整个训练集上的最优梯度并不一致,具有一定的随机性.一种有效地缓解梯度估计随机性的方式是通过使用最近一段时间内的平均梯度来代替当前时 刻的随机梯度来作为参数更新的方向,从而提高优化速度.
7.2.4.1 动量法
动量(Momentum)是模拟物理中的概念.一个物体的动量指的是该物体 在它运动方向上保持运动的趋势,是该物体的质量和速度的乘积.动量法(Mo- mentum Method)是用之前积累动量来替代真正的梯度.每次迭代的梯度可以 看作加速度.
在第 $$ 次迭代时,计算负梯度的“加权移动平均”作为参数的更新方向
$v^{t}=\alpha v^{t-1}-\epsilon g^{t}$
$\Delta \theta \leftarrow v_{t}$
$\theta_{t+1} \leftarrow \theta_{t}+\Delta \theta$
其中 $g_{t}$ 为梯度 .
这样,每个参数的实际更新差值取决于最近一段时间内梯度的加权平均值.当某个参数在最近一段时间内的梯度方向不一致时,其真实的参数更新幅度变 小;相反,当在最近一段时间内的梯度方向都一致时,其真实的参数更新幅度变大,起到加速作用.一般而言,在迭代初期,梯度方向都比较一致,动量法会起到加速作用,可以更快地到达最优点.在迭代后期,梯度方向会不一致,在收敛值附近振荡,动量法会起到减速作用,增加稳定性.从某种角度来说,当前梯度叠加上部分的上次梯度,一定程度上可以近似看作二阶梯度.
举例:
$v^{0}=0$
$v^{1}=-\epsilon \mathbf{g}^{0}$
$v^{2}=-\alpha \epsilon \mathbf{g}^{0}-\epsilon \mathbf{g}^{1}$
算法过程:

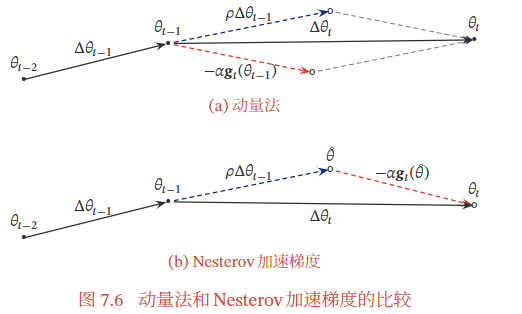
7.2.4.2 Nesterov 加速梯度
Nesterov 加速梯度(Nesterov Accelerated Gradient,NAG)是一种对动量法的改进 [Nesterov, 2013; Sutskever et al., 2013],也称为Nesterov 动量法(Nes- terov Momentum).
在动量法中,实际的参数更新方向 $\Delta \theta_{t} $ 为上一步的参数更新方向 $ \Delta \theta_{t-1}$ 和当前梯度的反方向 $-\mathbf{g}_{t} $ 的叠加. 这样, $\Delta \theta_{t}$ 可以被拆分为两步进行,先根据 $\Delta \theta_{t-1} $ 更 新一次得到参数 $\hat{\theta}$,再用 $-\mathbf{g}_{t}$ 进行更新.
$\hat{\theta}=\theta_{t-1}+\rho \Delta \theta_{t-1} $
$\theta_{t}=\hat{\theta}-\alpha \mathbf{g}_{t}$
其中梯度 $\mathbf{g}_{t}$ 为点 $\theta_{t-1}$ 上的梯度, 因此在第二步更新中有些不太合理. 更合理的更 新方向应该为 $\hat{\theta}$ 上的梯度.
这样, 合并后的更新方向为
$\Delta \theta_{t}=\rho \Delta \theta_{t-1}-\alpha g_{t}\left(\theta_{t-1}+\rho \Delta \theta_{t-1}\right)$
其中 $\mathfrak{g}_{t}\left(\theta_{t-1}+\rho \Delta \theta_{t-1}\right) $ 表示损失函数在点 $\hat{\theta}=\theta_{t-1}+\rho \Delta \theta_{t-1}$ 上的偏导数.
图7.6给出了动量法和 Nesterov加速梯度在参数更新时的比较.
7.2.4.3 Adam算法
Adam算法使用了动量变量 $\boldsymbol{v}_t$ 和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量 $\boldsymbol{s}_t$,并在时间步 0 将它们中每个元素初始化为0。给定超参数 $0 \leq \beta_1 < 1$(算法作者建议设为0.9),时间步 $t$ 的动量变量 $\boldsymbol{v}_t$ 即小批量随机梯度$\boldsymbol{g}_t$ 的指数加权移动平均:
$\boldsymbol{v}_t \leftarrow \beta_1 \boldsymbol{v}_{t-1} + (1 - \beta_1) \boldsymbol{g}_t. $
和RMSProp算法中一样,给定超参数 $0 \leq \beta_2 < 1$(算法作者建议设为0.999), 将小批量随机梯度按元素平方后的项 $\boldsymbol{g}_t \odot \boldsymbol{g}_t$做指数加权移动平均得到 $\boldsymbol{s}_t$ :
$\boldsymbol{s}_t \leftarrow \beta_2 \boldsymbol{s}_{t-1} + (1 - \beta_2) \boldsymbol{g}_t \odot \boldsymbol{g}_t. $
由于我们将 $\boldsymbol{v}_0$ 和 $\boldsymbol{s}_0$ 中的元素都初始化为 0, 在时间步 $t$ 我们得到 $\boldsymbol{v}_{t}=\left(1-\beta_{1}\right) \sum \limits _{i=1}^{t} \beta_{1}^{t-i} \boldsymbol{g}_{i}$。将过去各时间步小批量随机梯度的权值相加,得到 $\left(1-\beta_{1}\right) \sum \limits _{i=1}^{t} \beta_{1}^{t-i}=1-\beta_{1}^{t}$。需要注意的是,当$t$较小时,过去各时间步小批量随机梯度权值之和会较小。例如,当 $\beta_1 = 0.9$ 时,$\boldsymbol{v}_1 = 0.1\boldsymbol{g}_1$ 。为了消除这样的影响,对于任意时间步$t$,我们可以将 $\boldsymbol{v}_t$ 再除以 $1 - \beta_1^t$ ,从而使过去各时间步小批量随机梯度权值之和为1。这也叫作偏差修正。在Adam算法中,我们对变量$\boldsymbol{v}_t$ 和 $\boldsymbol{s}_t$ 均作偏差修正:
$\hat{\boldsymbol{v}}_t \leftarrow \frac{\boldsymbol{v}_t}{1 - \beta_1^t} $
$\hat{\boldsymbol{s}}_t \leftarrow \frac{\boldsymbol{s}_t}{1 - \beta_2^t} $
接下来,Adam算法使用以上偏差修正后的变量$\hat{\boldsymbol{v}}_t$和$\hat{\boldsymbol{s}}_t$,将模型参数中每个元素的学习率通过按元素运算重新调整:
$\boldsymbol{g}_t' \leftarrow \frac{\eta \hat{\boldsymbol{v}}_t}{\sqrt{\hat{\boldsymbol{s}}_t} + \epsilon}$
其中 $\eta$ 是学习率,$\epsilon$ 是为了维持数值稳定性而添加的常数,如 $10^{-8}$。和AdaGrad算法、RMSProp算法以及AdaDelta算法一样,目标函数自变量中每个元素都分别拥有自己的学习率。最后,使用 $\boldsymbol{g}_t'$ 迭代自变量:
$\boldsymbol{x}t \leftarrow \boldsymbol{x}{t-1} - \boldsymbol{g}_t'. $
7.2.4.4 梯度截断
在深度神经网络或循环神经网络中,除了梯度消失之外,梯度爆炸也是影响学习效率的主要因素.在基于梯度下降的优化过程中,如果梯度突然增大,用大的梯度更新参数反而会导致其远离最优点.为了避免这种情况,当梯度的模大于 一定阈值时,就对梯度进行截断,称为梯度截断(Gradient Clipping)[Pascanu et al., 2013].
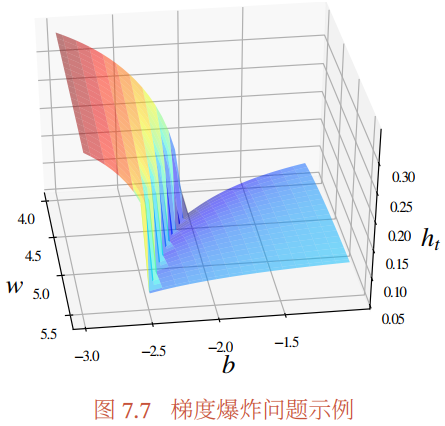
图7.7给出了一个循环神经网络的损失函数关于参数的曲面. 图中的曲面为只有一个隐藏神经元的循环神经网络 $h_{t}=\sigma\left(w h_{t-1}+b\right) $ 的损失函数,其中 $w$ 和 $ b$ 为参数. 假如 $h_{0}$ 初始值为 $0.3$ , 损失函数为 $\mathcal{L}=\left(h_{100}-0.65\right)^{2} $. 从图7.7中可以 看出,损失函数关于参数 $w, b$ 的梯度在某个区域会突然变大.
梯度截断是一种比较简单的启发式方法, 把梯度的模限定在一个区间, 当梯度的模小于或大于这个区间时就进行截断. 一般截断的方式有以下几种:
按值截断:在第 $$ 次迭代时,梯度为 $_$ ,给定一个区间 $[, ]$,如果一个参数的梯度小于 $$ 时,就将其设为 $$;如果大于 $$ 时,就将其设为 $$.
$\boldsymbol{g}_{t}=\max \left(\min \left(\boldsymbol{g}_{t}, b\right), a\right)$
按模截断:按模截断是将梯度的模截断到一个给定的截断阈值 $$.如果 $\|\boldsymbol{g}_{t} \|^{2} \leq b$ , 保持 $\boldsymbol{g}_{t} $不变. 如果 $\left\|\boldsymbol{g}_{t}\right\|^{2}>b$ , 令 $\mathbf{g}_{t}=\frac{b}{\left\|\boldsymbol{g}_{t}\right\|} \mathbf{g}_{t}$ . 截断阈值 $$ 是一个超参数,也可以根据一段时间内的平均梯度来自动调整实验中发现,训练过程对阈值 $$ 并不十分敏感,通常一个小的阈值就可以得到很好的 结果 [Pascanu et al., 2013].
$\mathbf{g}^{t}=\left\{\begin{array}{c} \mathbf{g}^{t},\left\|\mathbf{g}^{t}\right\| \leq b \\\frac{b}{\left\|\mathbf{g}^{t}\right\|} \mathbf{g}^{t},\left\|\mathbf{g}^{t}\right\|>b \end{array}\right.$
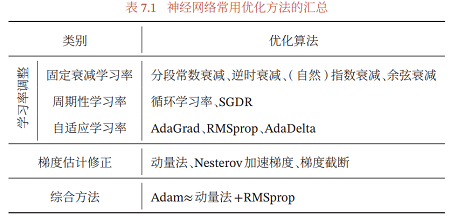
7.2.5 优化算法小结
本节介绍的几种优化方法大体上可以分为两类:1)调整学习率,使得优化 更稳定;2)梯度估计修正,优化训练速度.
表7.1汇总了本节介绍的几种神经网络常用优化算法.
这些优化算法可以使用下面公式来统一描述概括:
$\Delta \theta_{t} =-\frac{\alpha_{t}}{\sqrt{G_{t}+\epsilon}} M_{t}$
$G_{t} =\psi\left(\mathbf{g}_{1}, \cdots, \boldsymbol{g}_{t}\right)$
$M_{t} =\phi\left(\mathbf{g}_{1}, \cdots, \mathbf{g}_{t}\right)$
其中 $\boldsymbol{g}_{t}$ 是第 $t$ 步的梯度; $\alpha_{t}$ 是第 $t$ 步的学习率, 可以进行衰减, 也可以不变 ; $\psi(\cdot) $是学习率缩放函数, 可以取 $1$ 或历史梯度的模的移动平均 ; $\phi(\cdot) $ 是优化后的参数 更新方向,可以取当前的梯度 $\mathbf{g}_{t}$ 或历史梯度的移动平均.
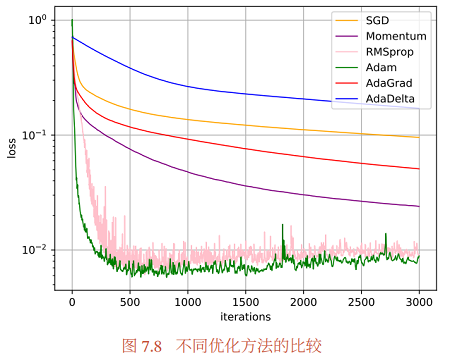
图7.8给出了这几种优化方法在 MNIST 数据集上收敛性的比较 (学习率为0.001 , 批量大小为 128 ).
第七章:网络优化与正则化(Part1)的更多相关文章
- 第七章:网络优化与正则化(Part2)
文章相关 1 第七章:网络优化与正则化(Part1) 2 第七章:网络优化与正则化(Part2) 7.3 参数初始化 神经网络的参数学习是一个非凸优化问题.当使用梯度下降法来进行优化网络参数时,参数初 ...
- 精通Web Analytics 2.0 (9) 第七章:失败更快:爆发测试与实验的能量
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第七章:失败更快:爆发测试与实验的能量 欢迎来到实验和测试这个棒极了的世界! 如果Web拥有一个超越所有其他渠道的巨大优势,它就 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (38) ------ 第七章 使用对象服务之动态创建连接字符串和从数据库读取模型
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 第七章 使用对象服务 本章篇幅适中,对真实应用中的常见问题提供了切实可行的解决方案. ...
- 《Entity Framework 6 Recipes》中文翻译系列 (41) ------ 第七章 使用对象服务之标识关系中使用依赖实体与异步查询保存
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 7-7 标识关系中使用依赖实体 问题 你想在标识关系中插入,更新和删除一个依赖实体 ...
- Java语言程序设计(基础篇) 第七章 一维数组
第七章 一维数组 7.2 数组的基础知识 1.一旦数组被创建,它的大小是固定的.使用一个数组引用变量,通过下标来访问数组中的元素. 2.数组是用来存储数据的集合,但是,通常我们会发现把数组看作一个存储 ...
- objective-c第七章课后练习2
题:改变第七章例子中print方法,增加bool参数,判断如果是YES则对分数进行约简 @interface Fraction : NSObject { //int num,den; } @prope ...
- 读《编写可维护的JavaScript》第七章总结
第七章 事件处理 7.1 典型用法 作者首先给了个我们一个处理事件的方法.看起来也没啥俩样,不过后来给出的优化方法很值得学习: // 不好的写法 function handleClick(even ...
- 第七章 LED将为我们闪烁:控制发光二极管
第七章 LED将为我们闪烁:控制发光二极管 本章我们将会看到一个完整的linux驱动程序,通过linux驱动程序控制LED的四个小灯,通俗的说就是通过向linux驱动程序来控制LED小灯的开关.用到 ...
- Getting Started With Hazelcast 读书笔记(第七章)
第七章 部署策略 Hazelcast具有适应性,能根据不同的架构和应用进行特定的部署配置,每个应用可以根据具体情况选择最优的配置: 数据与应用紧密结合的模式(重点,of就是这种) 胖客户端模式(最好用 ...
随机推荐
- Ubuntu安装ssh,及失败解决方案
网上有很多介绍在Ubuntu下开启SSH服务的文章,但大多数介绍的方法测试后都不太理想,均不能实现远程登录到Ubuntu上,最后分析原因是都没有真正开启ssh-server服务.最终成功的方法如下: ...
- vue 快速入门 系列 —— vue-cli 下
其他章节请看: vue 快速入门 系列 Vue CLI 4.x 下 在 vue loader 一文中我们已经学会从零搭建一个简单的,用于单文件组件开发的脚手架:本篇,我们将全面学习 vue-cli 这 ...
- Java的安装过程和开发环境
首先需要安装jdk(Java Development Kit开发工具包) 下载地址:https://www.oracle.com/java/technologies/javase-downloads. ...
- 使用 C# 下载文件的十八般武艺
文件下载是一个软件开发中的常见需求.本文从最简单的下载方式开始步步递进,讲述了文件下载过程中的常见问题并给出了解决方案.并展示了如何使用多线程提升 HTTP 的下载速度以及调用 aria2 实现非 H ...
- python-scrapy框架学习
Scrapy框架 Scrapy安装 正常安装会报错,主要是两个原因 0x01 升级pip3包 python -m pip install -U pip 0x02 手动安装依赖 需要手动安装 wheel ...
- 30 个极大提高开发效率超级实用的 VSCode 插件
Visual Studio Code 的插件对于在提升编程效率和加快工作速度非常重要.这里有 30 个最受欢迎的 VSCode 插件,它们将使你成为更高效的搬砖摸鱼大师.这些插件主要适用于前端开发人员 ...
- 题解 P3317 [SDOI2014]重建
题解 前置芝士:深度理解的矩阵树定理 矩阵树定理能求生成树个数的原因是,它本质上求的是: \[\sum_T \prod_{e\in T} w_e \] 其中 \(w_e\) 是边权,那么我们会发现其实 ...
- sentinel使用(结合OpenFeign)
前提 需要先安装sentinel. 父项目POM pom.xml <?xml version="1.0" encoding="UTF-8"?> &l ...
- httpClient 下载
private void button2_Click(object sender, EventArgs e) { get(); } private async Task get() { await D ...
- Windows下NodeJS安装与npm环境变量配置
node.js下载:https://nodejs.org/en/download/ 参考:https://www.jianshu.com/p/812de13f1276 1.安装过程基本直接" ...