python爬虫之抓取小说(逆天邪神)
2022-03-06 23:05:11
申明:自我娱乐,对自我学习过程的总结。
正文:
环境:
系统:win10,
python版本:python3.10.2,
工具:pycharm。
项目目标:
实现对单本小说的更新判断,省去人工登录浏览器看小说的繁琐操作。
如果小说内容更新了,那么自动下载你没看过的小说内容到本地,并保存为txt格式。
对项目代码封装成可单独运行在win10上的exe文件。
最终效果:都已实现。可以判断小说更新了没;更新了就下载下来;通过调整小说的已看章节数(就是你上次浏览小说章节位置记录)可以达到直接保存整本小说。
项目实现流程:
1. 主程序
我这里只写了一个main.py,就一个主函数解决了。
# 这个是一个爬取小说的工具
# 内容针对逆天邪神
# 功能1:是判断小说是否更新,如果更新就下载下来
# 功能2:下载整本小说(单线程),一般都是自动下载最新更新的几章,单线程足够。——懒
import requests
import re
from bs4 import BeautifulSoup
import os
if __name__ == '__main__':
novel_url = "https://www.bige3.com/book/1030/" # 逆天邪神
return_value = is_update(novel_url) # 更新章节数
if return_value == 0:
print("小说尚未更新!")
else:
print("小说已更新" + str(return_value) +"章!")
print("正在下载已更新的小说......")
download_novel(return_value)
# os.system("pause") # 调试时注释掉,封装时打开,用于观察结果
2. 功能函数
2.1 功能函数is_update()
def is_update(url):
heards = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
}
try:
resp = requests.get(url, headers=heards)
resp.raise_for_status() # 检查Response状态码,若不是200则产生HttpError异常
resp.encoding = 'utf-8'
except:
print("爬取失败")
resp = re.findall(r'<a href =.*?>(.*?)</a>', resp.text)
# print("请求返回的列表中的最后一章是:" + resp[-1])
with open("小说更新记录.txt", "r", encoding='utf-8') as f: # 打开文件
data = f.read() # 读取文件
# print("source_novel_data is:" + str(data))
if data == str(resp[-1]):
# print("===章节一致,小说尚未更新!")
return 0
else:
# print("!==小说更新啦,并将更新值加入到小说更新记录.txt")
data_num = re.findall(r'\d+', data) # list
data_num = ''.join(data_num) # str
resp_num = re.findall(r'\d+', resp[-1])
resp_num = ''.join(resp_num)
gap_num = int(resp_num)-int(data_num) # 更新章节数
with open("小说更新记录.txt", "w", encoding='utf-8') as f: # 打开文件
f.write(str(resp[-1])) # 读取文件
print("writing is ok!")
return gap_num
2.2 功能函数download_novel(return_value)
# 单线程方式
def download_novel(return_value):
if return_value >= 1:
for i in range(1, return_value+1, 1):
print(i)
with open("小说更新记录.txt", "r", encoding='utf-8') as f: # 打开文件
data = f.read() # 读取文件 str
data_num = re.findall(r'\d+', data) # list
data_num = ''.join(data_num) # str
download_num = int(data_num)+1-(i-1)
# print(download_num)
print(novel_url+str(download_num)+'.html')
resp = requests.get(novel_url+str(download_num)+'.html')
# print(resp.content)
soup = BeautifulSoup(resp.text, 'lxml')
soup.select('#chaptercontent')
mytxt = soup.text[soup.text.find('下一章'):soup.text.rfind('『点此报错')]
mytxt = mytxt[3:]
mytxt = mytxt.strip()
mytxt = mytxt.replace(' ', '\n')
novel_save_location = "./novel_downloads/逆天邪神第"+str(download_num-1)+"章.txt"
with open(novel_save_location, "w", encoding='utf-8') as f: # 打开文件
f.write(mytxt)
print("下载完毕!")
else:
print("invalid parameter!")
注意:
调试时要创建文件夹
novel_downloads,并标注为Exclusion,防止pycharm自动创建索引,使电脑卡顿。封装后的main.exe要保证它所在的路径下有两个东西:文件夹
novel_downloads和文件小说更新记录.txt。初始阶段保证文件
小说更新记录.txt里有个数字就行,随便啥(1 or 1935等)
全部代码:(直接能爬)
# 这个是一个爬取小说的工具
# 内容针对逆天邪神
# 功能1:是判断小说是否更新,如果更新就下载下来
# 功能2:下载整本小说(单线程),一般都是自动下载最新更新的几章,单线程足够。——懒
import requests
from lxml import etree
import re
from bs4 import BeautifulSoup
import os
def is_update(url):
heards = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
}
try:
resp = requests.get(url, headers=heards)
resp.raise_for_status() # 检查Response状态码,若不是200则产生HttpError异常
resp.encoding = 'utf-8'
except:
print("爬取失败")
resp = re.findall(r'<a href =.*?>(.*?)</a>', resp.text)
# print("请求返回的列表中的最后一章是:" + resp[-1])
with open("小说更新记录.txt", "r", encoding='utf-8') as f: # 打开文件
data = f.read() # 读取文件
# print("source_novel_data is:" + str(data))
if data == str(resp[-1]):
# print("===章节一致,小说尚未更新!")
return 0
else:
# print("!==小说更新啦,并将更新值加入到小说更新记录.txt")
data_num = re.findall(r'\d+', data) # list
data_num = ''.join(data_num) # str
resp_num = re.findall(r'\d+', resp[-1])
resp_num = ''.join(resp_num)
gap_num = int(resp_num)-int(data_num) # 更新章节数
with open("小说更新记录.txt", "w", encoding='utf-8') as f: # 打开文件
f.write(str(resp[-1])) # 读取文件
print("writing is ok!")
return gap_num
# 单线程方式
def download_novel(return_value):
if return_value >= 1:
for i in range(1, return_value+1, 1):
print(i)
with open("小说更新记录.txt", "r", encoding='utf-8') as f: # 打开文件
data = f.read() # 读取文件 str
data_num = re.findall(r'\d+', data) # list
data_num = ''.join(data_num) # str
download_num = int(data_num)+1-(i-1)
# print(download_num)
print(novel_url+str(download_num)+'.html')
resp = requests.get(novel_url+str(download_num)+'.html')
# print(resp.content)
soup = BeautifulSoup(resp.text, 'lxml')
soup.select('#chaptercontent')
mytxt = soup.text[soup.text.find('下一章'):soup.text.rfind('『点此报错')]
mytxt = mytxt[3:]
mytxt = mytxt.strip()
mytxt = mytxt.replace(' ', '\n')
novel_save_location = "./novel_downloads/逆天邪神第"+str(download_num-1)+"章.txt"
with open(novel_save_location, "w", encoding='utf-8') as f: # 打开文件
f.write(mytxt)
print("下载完毕!")
else:
print("invalid parameter!")
if __name__ == '__main__':
novel_url = "https://www.bige3.com/book/1030/" # 逆天邪神
return_value = is_update(novel_url)
if return_value == 0:
print("小说尚未更新!")
else:
print("小说已更新" + str(return_value) +"章!")
print("正在下载已更新的小说......")
download_novel(return_value)
os.system("pause")
缺点:单线程,没有用到异步协程,也没有用线程池实现对小说下载章节数较多时的快速下载优势。之后有空再优化代码,并实现相应的功能。
实现效果:
例如章节是目前是

最新章节为:1936章 灾厄奏鸣 ,我改个数字演示。
不改话,就没有新章节更新:

改后跑起来,应该是
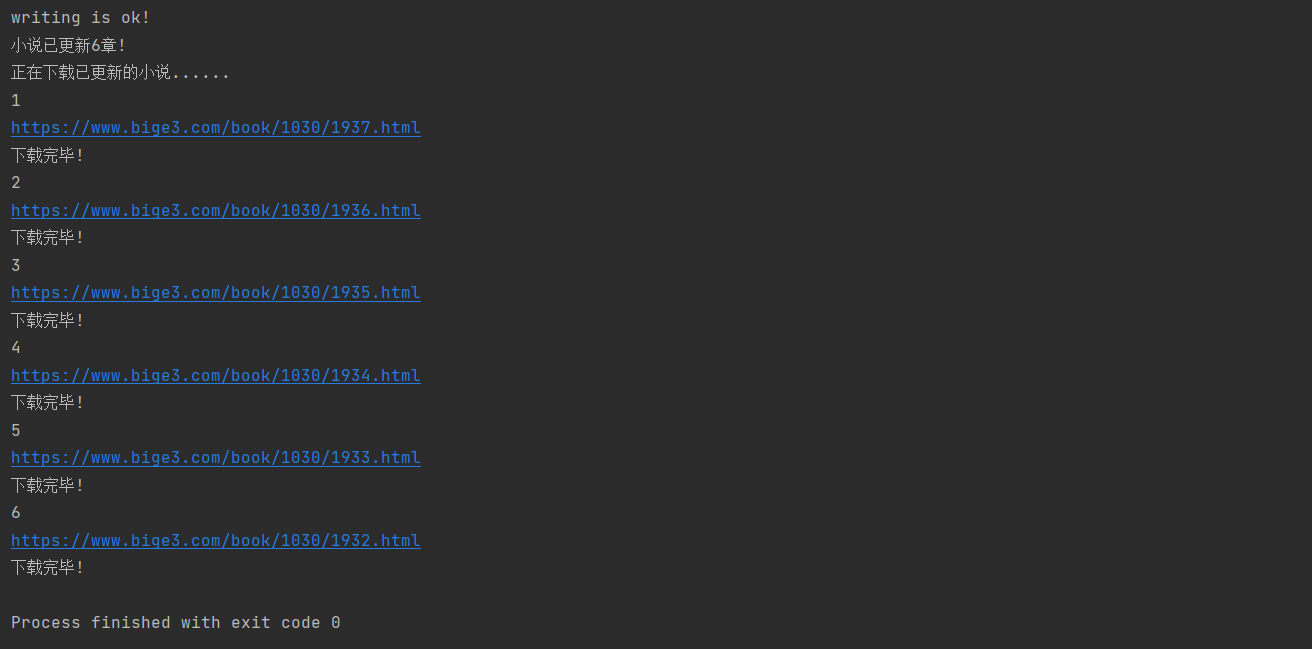
对应的文件夹里是:
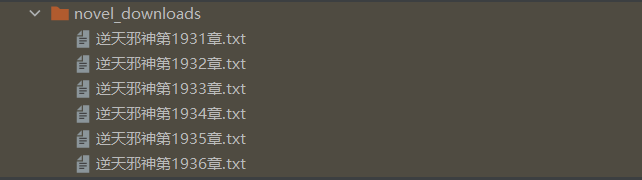
打开后内容是:
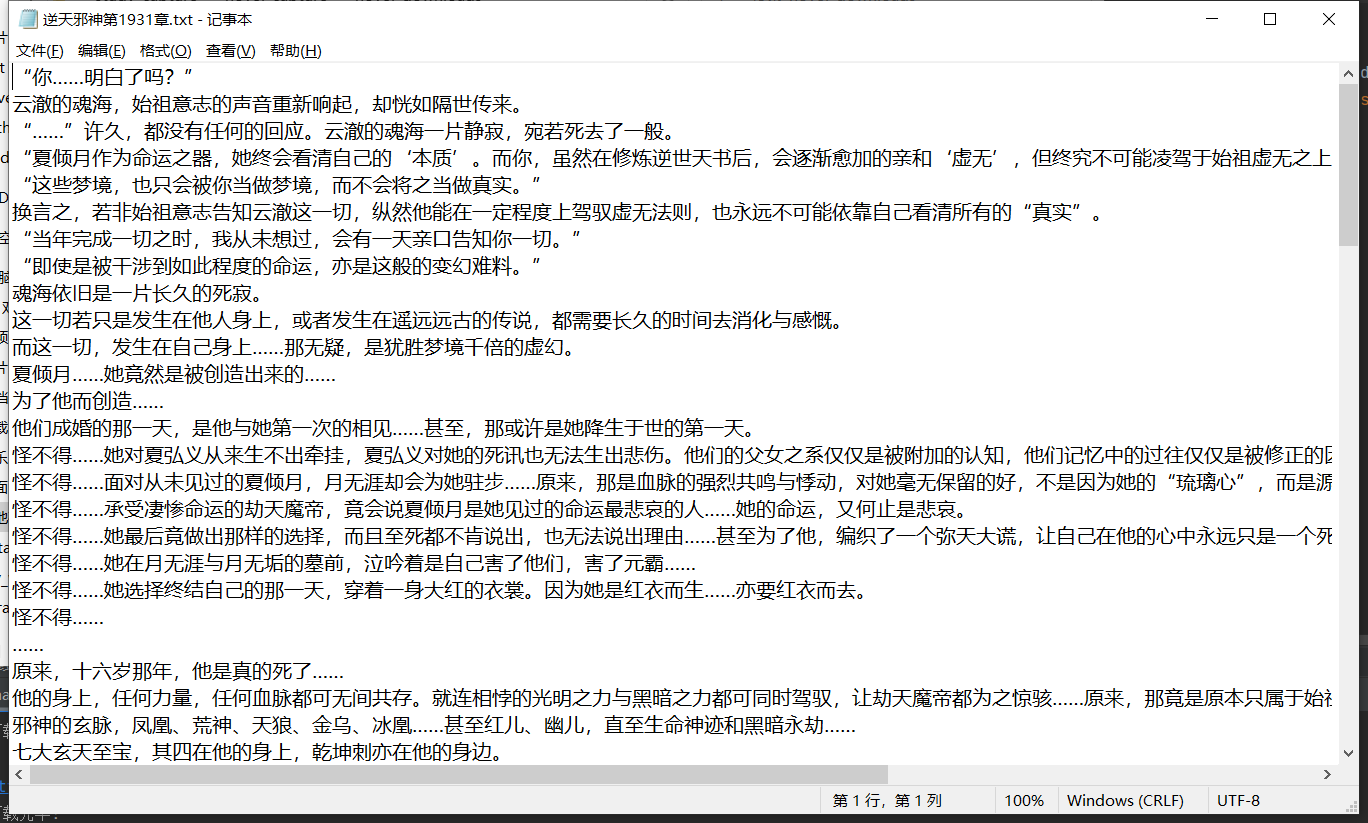
Over!!!!!
封装问题
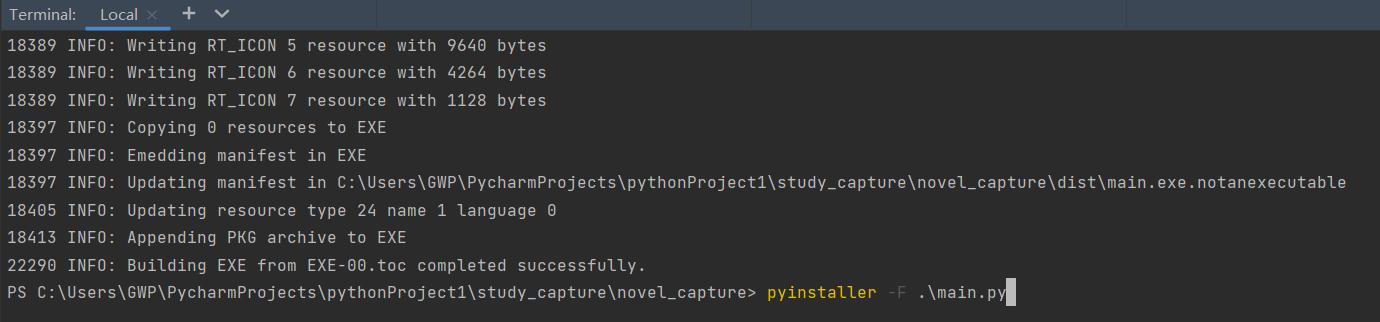
步骤:
在pycharm项目路径下打开终端输入:
pip install pyinstallercd到项目的.py文件路径下
cd .\study_capture\novel_capture\执行:
pyinstaller -F .\main.py
结果是:
项目中用到的知识点:
这里面可以有些在优化程序时被我给去掉了,嘿嘿
请求网页数据
resp = requests.get(url, headers=heards)
python中list与string的转换
data_num = re.findall(r'\d+', data) # 正则出来的是list
data_num = ''.join(data_num) # str
小说章节数的确认
resp = re.findall(r'<a href =.*?>(.*?)</a>', resp.text)
TXT文本的读取
encoding='utf-8' 是有必要的,不然会报错。
with open("小说更新记录.txt", "r", encoding='utf-8') as f: # 打开文件
data = f.read() # 读取文件
TXT文本的回写
with open("小说更新记录.txt", "w", encoding='utf-8') as f: # 打开文件
f.write(str(resp[-1])) # 读取文件
BS4对HTML进行值的筛选
#表示识别标签
soup = BeautifulSoup(resp.text, 'lxml')
soup.select('#chaptercontent')
取列表元素最后一个
resp[-1]
将列表中的章节数字拿出
data_num = re.findall(r'\d+', data) # list
python特定位置的字符串截取
soup.text str型
find('下一章') 左边开始第一个索引
rfind('『点此报错') 右边开始第一个索引
mytxt = soup.text[soup.text.find('下一章'):soup.text.rfind('『点此报错')]
字符串的拼接:
novel_save_location = "./novel_downloads/逆天邪神第"+str(download_num-1)+"章.txt"
小说保存时:
1.里面有空白,直接用
mytxt = mytxt.strip()
时没有去掉,不知道啥原因。我记得听网课说是:去掉空格,空白,换行符,其他好像都去了,最后还剩小说之间一些空白。
解决方式:因为没有发现是啥符号(notepad++),于是之间将空白拿过来用(copy)。
mytxt=mytxt.replace(' ', '\n')
#目的是:在TXT文本中句子太长,于是我直接在每句话结束后换行。效果还行,与网站对比。
感谢观看!!!第一次写,好慢,好菜,回去写作业去了。呜呜呜
python爬虫之抓取小说(逆天邪神)的更多相关文章
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫实现抓取腾讯视频所有电影【实战必学】
2019-06-27 23:51:51 阅读数 407 收藏 更多 分类专栏: python爬虫 前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- Python爬虫,抓取淘宝商品评论内容!
作为一个资深吃货,网购各种零食是很频繁的,但是能否在浩瀚的商品库中找到合适的东西,就只能参考评论了!今天给大家分享用python做个抓取淘宝商品评论的小爬虫! 思路 我们就拿"德州扒鸡&qu ...
- python爬虫数据抓取方法汇总
概要:利用python进行web数据抓取方法和实现. 1.python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返 ...
- python爬虫批量抓取ip代理
使用爬虫抓取数据时,经常要用到多个ip代理,防止单个ip访问太过频繁被封禁.ip代理可以从这个网站获取:http://www.xicidaili.com/nn/.因此写一个python程序来获取ip代 ...
- Python爬虫:抓取手机APP的数据
摘要 大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 表单: 表单中包括了用户名和密码,当然都是加密 ...
随机推荐
- iPhone12和iPhone12pro的区别有什么?
阅读全部 说法一 iPhone12和iPhone12pro的区别有:颜色.价格.运行内存.拍照.屏幕最高亮度.电池容量.材质.重量等,具体对比如下: 颜色:iPhone12五色可选,青春绚丽:iPho ...
- 前端HTML基础之form表单
目录 一:form表单 1.form表单功能 2.表单元素 二:form表单搭建(注册页面) 1.编写input会出现黄色阴影问题 三:完整版,前端代码(注册页面) 四:type属性介绍 1.inpu ...
- 一:linux安装nginx
目录 1.yun安装 2.二进制安装 3.编译安装 1.yun安装 nginx官网:https://nginx.org/ [root@web01 ~]# vim /etc/yum.repos.d/ng ...
- HowToDoInJava Java 教程·翻译完成
原文:HowToDoInJava 协议:CC BY-NC-SA 4.0 欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远. ApacheCN 学习资源 目录 核心 Java 教程 什 ...
- 布客·ApacheCN 编程/大数据/数据科学/人工智能学习资源 2020.4
公告 我们的机器学习群(915394271)正式改名为财务提升群,望悉知. 请关注我们的公众号"ApacheCN",回复"教程/路线/比赛/报告/技术书/课程/轻小说/漫 ...
- [USACO19JAN]Exercise Route P
先让我们探索一下两条非树边以及树边能构成简单环的条件是什么,你会发现将第一条非树边的两个点在树上形成的链记为 \(W_1\),另一条即为 \(W_2\),那么当且仅当 \(W_1, W_2\) 有交时 ...
- redis中scan和keys的区别
scan和keys的区别 redis的keys命令,通来在用来删除相关的key时使用,但这个命令有一个弊端,在redis拥有数百万及以上的keys的时候,会执行的比较慢,更为致命的是,这个命令会阻塞r ...
- git每次操作都要输入账号密码 解决方案
1.执行命令: git config --global credential.helper store git pull 2.输入用户名密码,以后就不会再次要求用户名密码了
- druid 数据源密码加密配置
<!-- 数据源配置 --> <bean id="default" class="com.alibaba.druid.pool.DruidDataSou ...
- .NET 云原生架构师训练营(权限系统 RGCA 开发任务)--学习笔记
目录 目标 模块拆分 OPM 开发任务 目标 基于上一讲的模块划分做一个任务拆解,根据任务拆解实现功能 模块拆分 模块划分已经完成了边界的划分,边界内外职责清晰 OPM 根据模块拆分画出 OPM(Ob ...