flink03-----1.Task的划分 2.共享资源槽 3.flink的容错
1. Task的划分
在flink中,划分task的依据是发生shuffle(也叫redistrubute),或者是并行度发生变化
- 1. wordcount为例


package cn._51doit.flink.day03; import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector; import java.util.Arrays; public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("feng05", 8888);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
Arrays.stream(line.split(" ")).forEach(w -> out.collect(Tuple2.of(w, 1)));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> filtered = wordAndOne.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> value) throws Exception {
return value.f1 != null;
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = filtered.keyBy(0);
//SingleOutputStreamOperator并行度为4
SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyed.sum(1);
result.print(); //sink的并行度也是2
env.execute();
}
}
其dataflow图如下所示

socketTextStream是单并行度source,无论你将并行度设置成多少,其并行度都是1,所以到flatMap算子时,并行度就变成了自己设置的4.整个dataflow分成3个Task,9个subTask。
- 2. 改变1,在flatMap后加上startNewChain(),即开启一个新的链
按常理来讲,此处的flatMap算子和filter算子间的链是要断开的,但此处自己测试并没有端,暂时还不知道为什么
- 3. 改变2 在flatMap后加上disableChaining(),即将概算自前后的OperatorChain都断开,将该算子单独划分一个task

可以发现,Task数由3变成4,subTask也相应的编程了13个
注意:此处为什么要使用startNewChain、disablechaining呢?
我们在进行计算时,会存在一些计算密集型的算子(比如涉及排序的算子),可以将之独立出来,然后将其调度到某些机器上,这个算子就能独享该机器的cpu,内存的资源,提高效率。
总结:Task划分的依据
(1)并行度发生变化时
(2)keyBy() /window()/apply() 等发生 Rebalance 重新分配(即shuffle)
(3)调用startNewChain()方法,开启一个新的算子链
(4)调用diableChaining()方法,即告诉当前算子操作不适用算子链操作
2. 共享资源槽(Sharing slot)
2.1 简单概念
每一个TaskManager(Worker)是一个JVM进程,它可能会在独立的线程上执行一个或者多个subtask。为了控制一个worker能接收多少个task,worker通过task slot来进行控制
每个task slot表示TaskManager拥有资源的一个固定⼤大⼩小的⼦子集。假如⼀一个TaskManager有三个slot,那么它会将其管理理的内存分成三份给各个slot。资源slot化意味着⼀一个subtask将不不需要跟来⾃自其他job的subtask竞争被管理理的内存,取⽽而代之的是它将拥有⼀一定数量量的内存储备。需要注意的是,这⾥里里不不会涉及到CPU的隔离,slot⽬目前仅仅⽤用来隔离task的受管理理的内存。
默认情况下,flink允许subtasks共享slots,即使它们是不同tasks的subtasks,只要它们来自同一个job。因此,一个slot可能会负责这个job的某个管道(pipeline)。共享资源槽有如下两个优点:
- Flink 集群需要与 job 中使用的最高并行度一样多的 slots。若是没有sharing slot,就需要计算作业总共包含多少个 tasks,从而判断集群需要多少slots,非常麻烦。
- 更好的资源利用率。在没有 slot sharing 的情况下,简单的 subtasks(source/map())将会占用和复杂的 subtasks (window)一样多的资源。
如下:
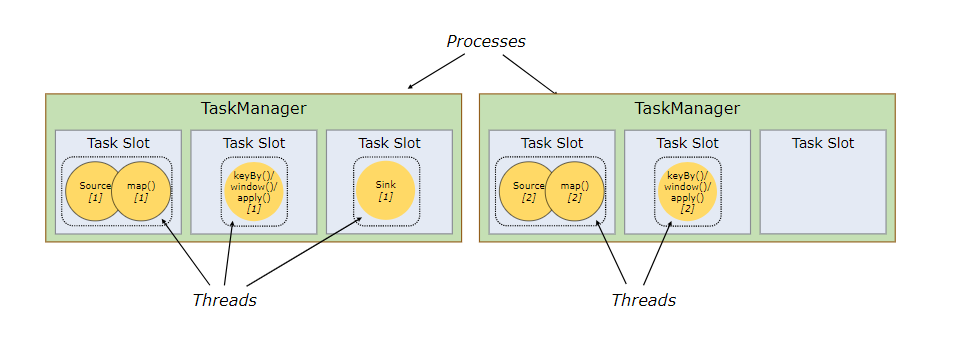
上图是没有采用sharing slot的情况,可见2个TaskManager只能使用两个并行,但若是换成sharing slot,则结果就大不一样,如下
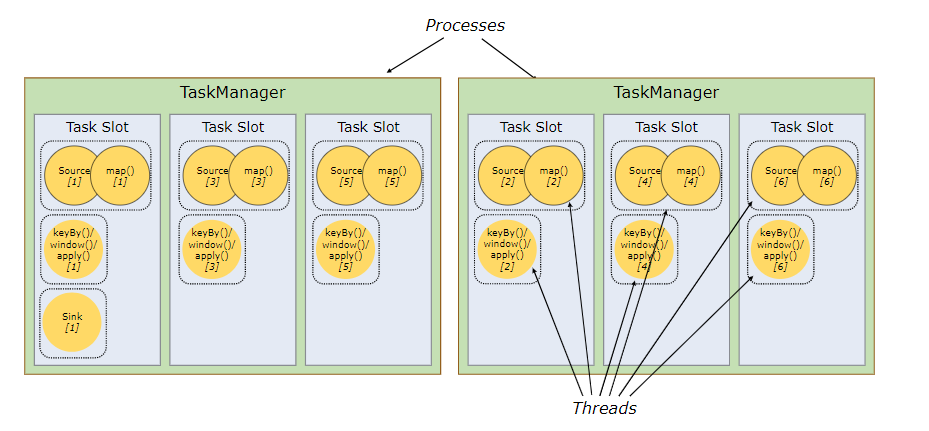
由图可明显看出,同样的slot数,使用sharing slot的情况并行度由2提高到6,这使得效率大大提高。
2.2 进一步理解
SlotSharingGroup是flink中用来实现slot共享的类,它尽可能的让subtasks共享一个slot。保证同一个group的sub-tasks共享一个slots。默认的slot sharing group名称为default,算子也有自己的名字,默认也是default并且算子只能进入与自己名字相同的slot sharing group(即默认一个job下的subtask都可以共享一个slot)。slot sharing group的名字由第一个进入该slot算子的名称而定,比如第一个进入该slot算子的名称为feng,则这个slot sharing group的名称就为feng。
有些时候不想使用资源共享槽,想让算子单独享用某个managerTask中的slot(比如一些计算密集型的算子,比如排序、机器学习等),即防止不合理的共享,这时候可以人为的强制指定operator的共享组。比如someStream.filter(...).slotSharingGroup("group1");就强制指定了filter的slot共享组为group1。
提交一个wordcount程序,并行度为4
代码如下
package cn._51doit.flink.day03; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector; import java.util.Arrays; public class SharingGroupDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //使用Socket创建DataStream
//socketTextStream是一个非并行的Source,不论并行度设置为多少,总是一个并行
//DataStreamSourc并行度为1
DataStreamSource<String> lines = env.socketTextStream("node-1.51doit.cn", 8888); //DataStream的并行度默认是使用你设置的并行度
//DataStream并行度为4
DataStream<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
Arrays.stream(line.split(" ")).forEach(w -> out.collect(Tuple2.of(w, 1)));
}
}); //keyBy属于shuffle(redistribute)算子
//KeyedStream并行度为4
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0);
//SingleOutputStreamOperator并行度为4
SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyed.sum(1); result.print(); env.execute(); }
}
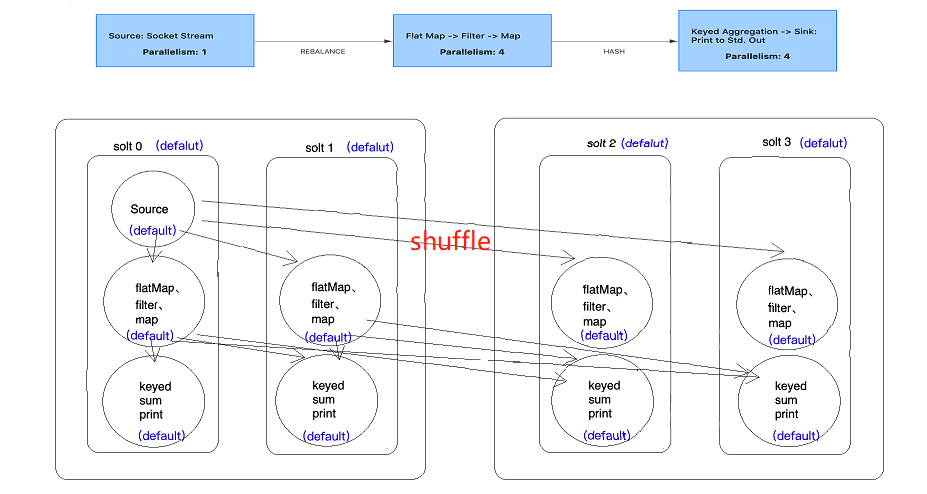
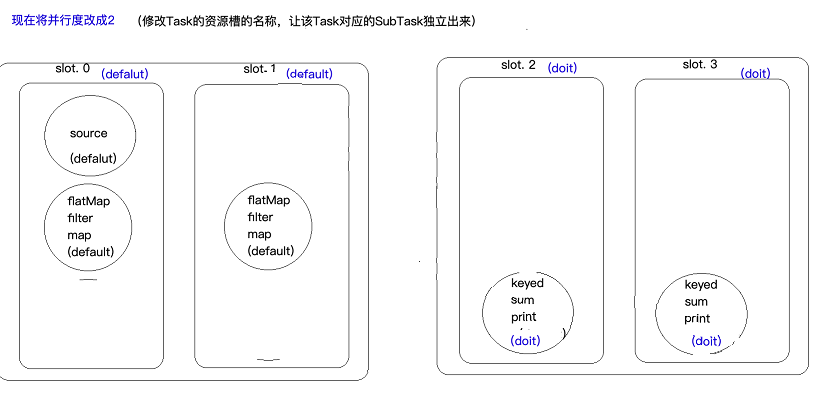
现将并行度沈设置成2,能发现有2个slot是空置的
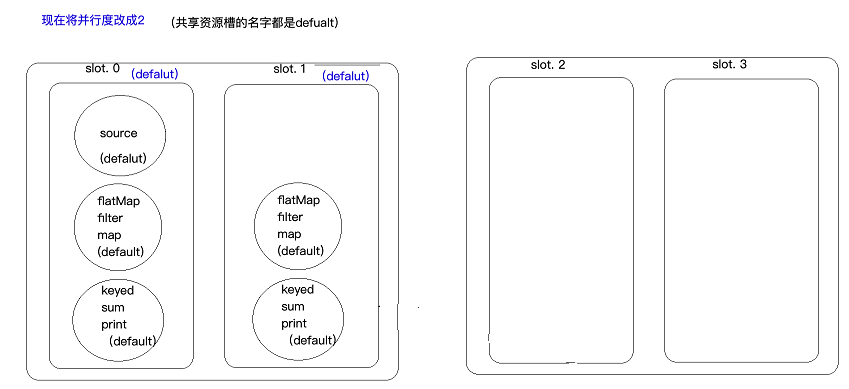
维持并行度为2,但是修改Task资源槽的名称,让该Task对应的subTask独立出来
此处在sum算子上打标签,即(sum.slotSharingGroup("doit")),sum包括其后面的算子名称都变为doit,但此处keyed为什么会变doit就不清楚了。
3.Flink的容错
3.1 State状态
Flink实时计算程序为了保证计算过程中,出现异常可以容错,就要将中间的计算结果数据存储起来,这些中间数据就叫做state。state可以是多种类型的,默认是保存在JobManager的内存中,也可以保存到TaskManager本地文件系统或HDFS这样的分布式文件系统。
3.2 StateBackEnd
用来保存的存储后端就叫做StateBackEnd,默认是保存在JobManager的内存中,也可以保存本地系统或HDFS这样的分布式文件系统。
3.3 CheckPointing
Flink实时计算为了容错,可以将中间数据定期保存下来,这种定期触发保存中间结果的机制叫CheckPointing,CheckPointing是周期性执行的,具体的过程是JobManager定期向TaskManager中的SubTask发送RPC消息,SubTask将其计算的State保存到StateBackEnd中,并且向JobManager响应Checkpoint是否成功。如果程序出现异常或者重启,TaskManager中的SubTask可以从上一次成功的CheckPointing的state恢复,具体见下图
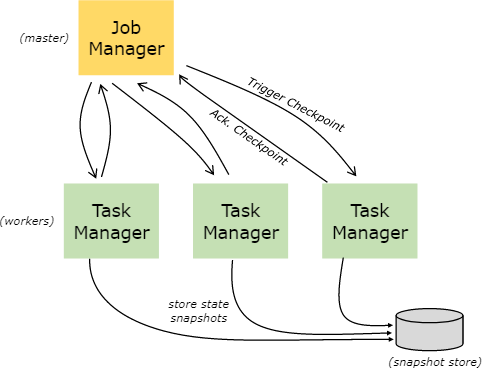
注意:JobManager只有在接收到所有subTask将计算结果的state成功保存到StateBackEnd的消息后,才会标记checkpoint成功。
3.4 重启策略
Flink实时计算程序为了容错,需要开启CheckPointing,一旦开启CheckPointing,如果没有重启策略,默认的重启策略是无限重启,也可以设置成其他的重启策略,如:重启固定次数以及重启间的间隔时间
3.5 CheckPointingMode
- exactly-once
精确一次性语义,可以保证数据消费且消费一次,但是要结合对应的数据源,比如Kafla支持exactly-once
- ar-least-once
至少消费一次,可能会重复消费,但是效率要比exactly-once高
4 state案例
4.1 简单概念
(1)state概念:
State是Flink计算过程的中间结果和状态信息,为了容错,必须把状态持久化到一个外部系统中去
(2)state的分类
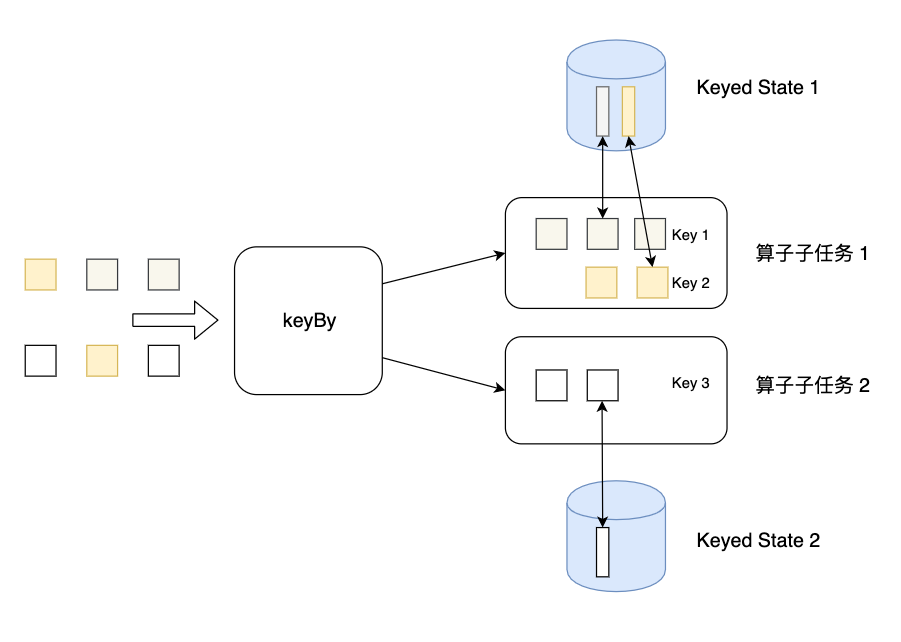
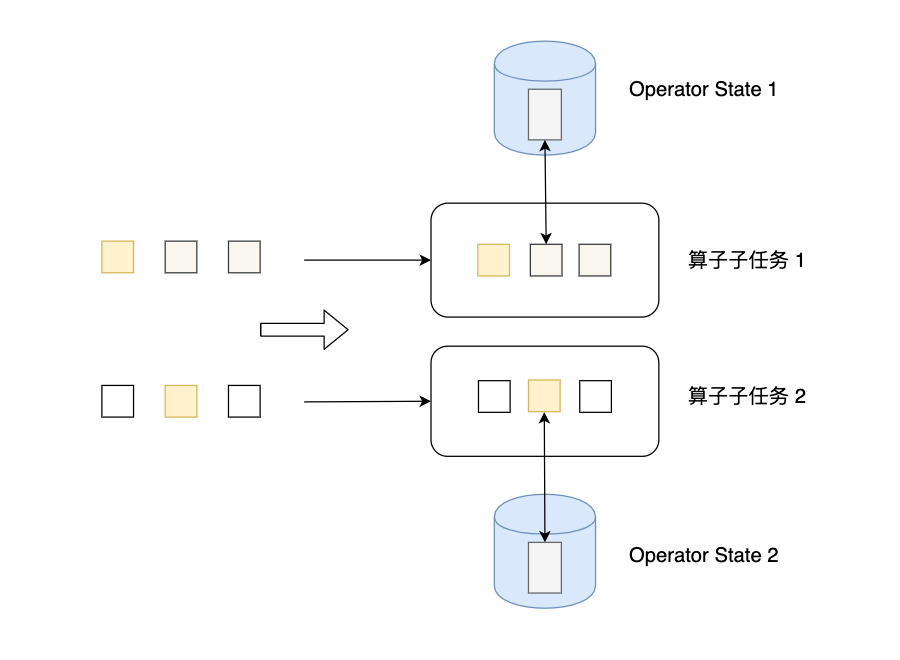
值得看的博客:https://www.lizenghai.com/archives/46460.html(下图来自此博客)
- KeyState:调用keyBy方法后,每个分区中相互独立的state
- Operatecast state:没有分组,每一个subTask自己维护一个状态
(3)state的使用
- 先定义一个状态描述器
- 通过context获取state
- 对数据处理后要更新数据
案例1:重启策略
RestartStrages
package cn._51doit.flink.day03; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector; import java.util.Arrays; public class RestartStrages {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("feng05", 8888);
// 开启checkpoint,索九checkpoint一次
env.enableCheckpointing(5000);
// 默认的重启策略就是无限重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000));
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
if (word.equals("feng")) {
int i = 1 / 0;
}
return Tuple2.of(word, 1);
}
});
//keyBy属于shuffle(redistribute)算子
//KeyedStream并行度为4
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0);
//SingleOutputStreamOperator并行度为4
SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyed.sum(1);
result.print();
env.execute();
}
}
发现程序中断后会重启,并且重启后,前面的计算结果还能被复用(sum算子内部实现了state的保存)
案例2:能否自己实现sum算子,既能正确的累加单词的次数,还能在程序出现异常时容错
MyHashMapDemo
package cn._51doit.flink.day03; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.HashMap; public class MyHashMapDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//开启checkpoint
env.enableCheckpointing(5000); //开启checkpoint,默认的重启策略就是无限重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000));
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
if (word.equals("laoduan")) {
int i = 1 / 0; //模拟出现错误,任务重启
}
return Tuple2.of(word, 1);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyed.map(new MapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
private HashMap<String, Integer> state = new HashMap<>();
@Override
public Tuple2<String, Integer> map(Tuple2<String, Integer> input) throws Exception {
String currentKey = input.f0;
Integer currentCount = input.f1;
Integer historyCount = state.get(currentKey);
if (historyCount == null) {
historyCount = 0;
}
int sum = historyCount + currentCount; //累加
//更新状态数据(我自己实现的计数器)
state.put(currentKey, sum);
return Tuple2.of(currentKey, sum); //输出结果
}
});
result.print();
env.execute();
}
}
此种定义hashMap的形式只能正确的累加单词的次数,并不能实现容错。
案例3:使用keyState实现sum,能满足需求
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//开启checkpoint
env.enableCheckpointing(5000); //开启checkpoint,默认的重启策略就是无限重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000)); SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
if (word.equals("laoduan")) {
int i = 1 / 0; //模拟出现错误,任务重启
}
return Tuple2.of(word, 1);
}
}); KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0); SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyed.map(new RichMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() { private transient ValueState<Integer> countState; //在构造器方法之后,map方法之前执行一次
@Override
public void open(Configuration parameters) throws Exception {
//初始化状态或恢复状态
//使用状态的步骤:
//1.定义一个状态描述器,状态的名称,存储数据的类型等
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>(
"wc-state",
Integer.class
);
//2.使用状态描述从对应的StateBack器获取状态
countState = getRuntimeContext().getState(stateDescriptor);
} @Override
public Tuple2<String, Integer> map(Tuple2<String, Integer> input) throws Exception {
String currentKey = input.f0;
Integer currentCount = input.f1;
Integer historyCount = countState.value();
if(historyCount == null) {
historyCount = 0;
}
int sum = historyCount + currentCount;
//更新state
countState.update(sum);
return Tuple2.of(currentKey, sum);
}
}); result.print(); env.execute();
案例4:OperatorState
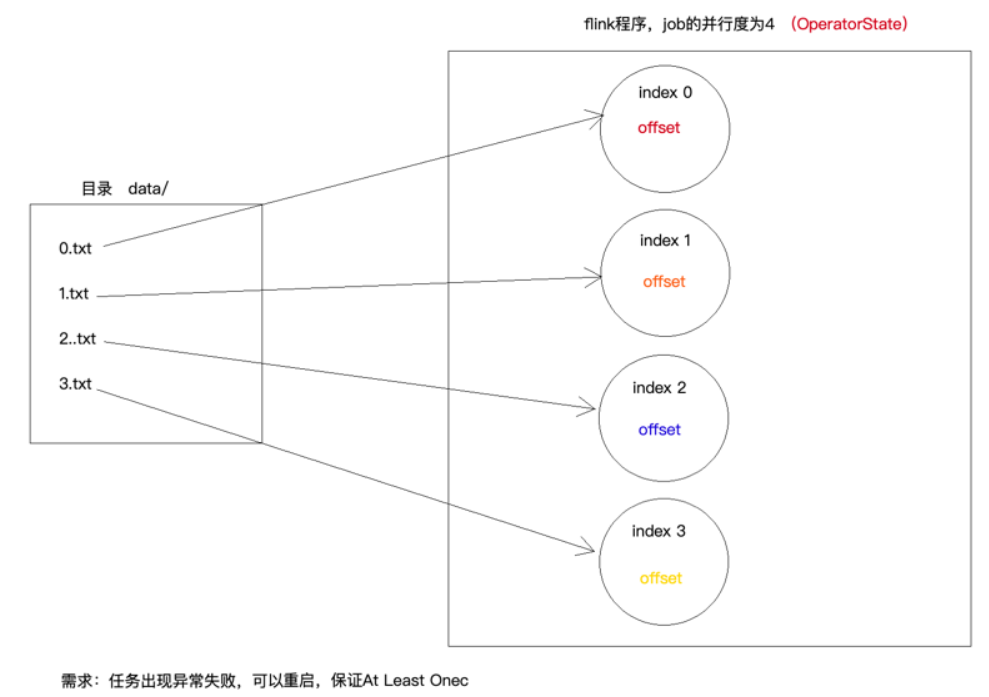
自定义Source
MyAtLeastOnceSource
package cn._51doit.flink.day03; import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction; import java.io.RandomAccessFile; public class MyAtLeastOnceSource extends RichParallelSourceFunction<String> implements CheckpointedFunction { private transient ListState<Long> listState; private boolean flag = true;
private Long offset = 0L; //在构造方法之后,open方法之前执行一次,用于初始化Operator State或恢复Operator State
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
//定义一个状态描述器
ListStateDescriptor<Long> stateDescriptor = new ListStateDescriptor<>(
"offset-state",
Long.class
);
//listState中存储的就是一个long类型的数值
listState = context.getOperatorStateStore().getListState(stateDescriptor); //从ListState中恢复数据
if(context.isRestored()) {
for (Long first : listState.get())
offset = first;
}
} //snapshotState方法是在checkpoint时,会调用
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
//将上一次checkpoint的数据清除
listState.clear();
//将最新的偏移量保存到ListState中
listState.add(offset);
} @Override
public void run(SourceContext<String> ctx) throws Exception {
int taskIndex = getRuntimeContext().getIndexOfThisSubtask();
RandomAccessFile raf = new RandomAccessFile("/Users/xing/Desktop/data/" + taskIndex + ".txt", "r");
//从指定的位置读取数据
raf.seek(offset);
//获取一个checkpoint的锁
final Object checkpointLock = ctx.getCheckpointLock();
while (flag) {
String line = raf.readLine();
if(line != null) {
//获取最新的偏移量
synchronized (checkpointLock) {
line = new String(line.getBytes("ISO-8859-1"), "UTF-8");
offset = raf.getFilePointer();
ctx.collect(taskIndex + ".txt => " + line);
}
} else {
Thread.sleep(1000);
}
} } @Override
public void cancel() {
flag = false;
}
}
MyAtLeastOnceSourceDemo
package cn._51doit.flink.day03; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class MyAtLeastOnceSourceDemo { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
env.enableCheckpointing(30000);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000)); //自定义一个多并行的Source
DataStreamSource<String> lines1 = env.addSource(new MyAtLeastOnceSource()); DataStreamSource<String> lines2 = env.socketTextStream("localhost", 8888); SingleOutputStreamOperator<String> error = lines2.map(new MapFunction<String, String>() {
@Override
public String map(String line) throws Exception {
if (line.startsWith("error")) {
int i = 1 / 0;
}
return line;
}
}); DataStream<String> union = lines1.union(error); union.print(); env.execute(); }
}
两次checkpoint之间的数据会被重复读,所以是AtListOnce
MyHashMaoDemo
flink03-----1.Task的划分 2.共享资源槽 3.flink的容错的更多相关文章
- 【iCore4 双核心板_uC/OS-II】例程五:信号量——共享资源
一.实验说明: 信号量是操作系统中的一类事件,是实现任务间通信的一个中间环节.当系统中的多个任务 在运行时,经常需要互相无冲突地访问同一个资源,或者需要互相支持的依赖,甚至有时还要互 相加以必要的限制 ...
- Intel64及IA-32架构优化指南第8章多核与超线程技术——8.9 其它共享资源的优化
8.9 其它共享资源的优化 在多线程应用中的资源优化依赖于处理器拓扑层级内相关联的Cache拓扑以及执行资源.在第7章中讨论了处理器拓扑以及标识处理器拓扑的一种软件算法. 在带有共享总线的平台中,总线 ...
- webpy 访问局域网共享资源
遇到一个问题: 在python shell 中调用局域网远程共享文件时,没问题.但是在webpy中调用时,报错:没有权限.那一定是apache设置问题. 网上找不到类似的方法,于是换个思路搜了一下“p ...
- 分享一下SQLSERVER技术交流QQ群里的群共享资源
分享一下SQLSERVER技术交流QQ群里的群共享资源 SQLSERVER技术交流QQ群已经开了一段时间了,人数已经有了100多号人, 而群里面很多SQLSERVER爱好者上传了他们宝贵的SQLSER ...
- AssetBundle系列——共享资源打包/依赖资源打包
有人在之前的博客中问我有关共享资源打包的代码,其实这一块很简单,就两个函数: BuildPipeline.PushAssetDependencies():依赖资源压栈: BuildPipeline.P ...
- win7问题解决,凭据管理器和无法访问,不允许一个用户使用一个以上用户名与服务器或共享资源进行多重连接。
WIN7凭据管理器,如果你用一个帐号远程登录以后在电脑中会记住这个信息,假如你想用另外的帐号,那么就到控制面板-凭据管理器里中进行修改或者删除. 如果你登录以后提示,“无法访问.不允许一个用户使用一个 ...
- 多重影分身——C#中多线程的使用二(争抢共享资源)
只要服务器承受得了,我们可以开任意个线程同时工作以提高效率,然而 两个线程争抢资源可能导致数据混乱. 例如: public class MyFood { public static int Last ...
- Java使用wait() notify()方法操作共享资源
Java多个线程共享资源: 1)wait().notify()和notifyAll()方法是本地方法,并且为final方法,无法被重写. 2)调用某个对象的wait()方法能让当前线程阻塞,并且当前线 ...
- java解决共享资源竞争
由于多线程的实现,在运行一个程序的时候可能会有很多的线程在同时运行,但是线程的调度并不是可见的,所以不会知道一个线程什么时候在运行,比如说 你坐在桌子前手拿着叉子,正要去叉盘中的最后一片食物,当你的叉 ...
随机推荐
- 数字在排序数组中出现的次数 牛客网 剑指Offer
数字在排序数组中出现的次数 牛客网 剑指Offer 题目描述 统计一个数字在排序数组中出现的次数. class Solution: def GetNumberOfK(self, data, k): i ...
- 用C++实现的数独解题程序 SudokuSolver 2.7 及实例分析
引言:一个 bug 的发现 在 MobaXterm 上看到有内置的 Sudoku 游戏,于是拿 SudokuSolver 求解,随机出题,一上来是个 medium 级别的题: 073 000 060 ...
- 直播预告|App 首页如何动态化更新?来看蚂蚁技术专家详解「支付宝」全新卡片技术栈
立即前往直播间预约观看 从icon到card,一场内容前置化的变革 从 Windows 时代开始,应用程序图标就成为了用户(流量)的主入口,一直持续到移动端时代. 图标即入口的方式,虽然足够方便但却不 ...
- 【java+selenium3】自动化处理文件上传 (十三)
一.文件上传 文件上传是自动化中棘手的部分,目前selenium并没有提供上传的实现api,所以知道借助外力来完成,如AutoIt.sikuli. AutoIt , 这是一个使用类似BASIC脚本语言 ...
- java中使用Process执行linux命令
代码如下 BufferedReader reader = null; String cmd = "netstat -anp|grep :8080";//命令中有管道符 | 需要如下 ...
- C# 计算农历日期方法(2021版)
解决问题 旧版农历获取方法报错,会有 到 2021年 m数组越界了 if (LunarData[m] < 4095) 此方法可以解决 主体代码 public static class China ...
- python爬取ip地址
ip查询,异步get请求 分析接口,请求接口响应json 发现可以data中获取 result.json()['data'][0]['location'] # _*_ coding : utf-8 _ ...
- <C#任务导引教程>练习四
//27,创建一个控制台应用程序,声明两个DateTime类型的变量dt,获取系统的当前日期时间,然后使用Format格式化进行规范using System;class Program{ sta ...
- [cf1495E]Qingshan and Daniel
选择其中卡片总数较少的一类,当相同时选择$t_{1}$所对应的一类(以下记作$A$类) 如果$t_{1}$不是$A$类,就先对$t_{1}$操作一次(即令$a_{1}$减少1) 下面,问题即不断删去$ ...
- Java 插入html字符串到PPT幻灯片
通过Java后端代码操作PPT幻灯片时,可直接在幻灯片中绘制形状,并在形状中添加文本字符串内容.本篇文章,介绍一种通过html字符串来添加内容到PPT幻灯片的的方法,可添加文字.图片.视频.音频等.下 ...