java集合-哈希表HashMap
一、简介
HashMap是一个散列表,是一种用于存储key-value的数据结构。
二、类图
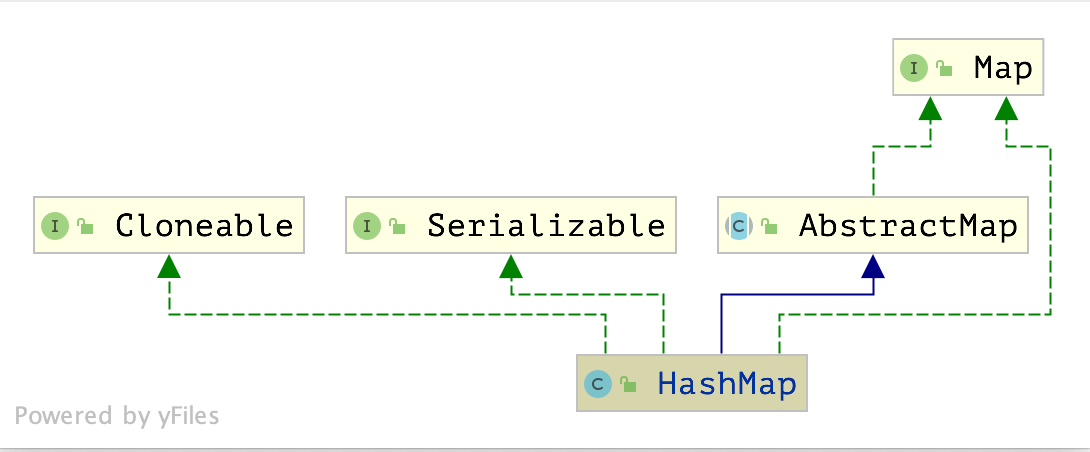
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
1 实现了三个接口
1.1 java.util.Map 接口,提供键/值 需要实现的方法
1.2 java.io.Serializable 接口,表示 HashMap 支持序列化的功能。
1.3 java.lang.Cloneable 接口,表示 HashMap 支持克隆。
2、继承一个类
java.util.AbstractMap抽象类,是Map接口的 实现类之一,也是HashMap、TreeMap、ConcurrentHashMap 等的父类,它提供了Map 接口中方法的基本实现。
三、常用方法
添加单个元素 put(K key, V value)
//添加单个元素
public V put(K key, V value) {
//hash(key):计算key的hash值,返回值是int类型
return putVal(hash(key), key, value, false, true);
}
//计算key的hash值
static final int hash(Object key) {
int h;
// key.hashCode() 做位运算,得到一个int类型值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//设置元素方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; //数组
Node<K,V> p; //对应位置的 Node 节点
int n;//数组长度 tab.length
int i;//当前数组下标(通过hash计算出来的下标)
//如果table为空,就resize()扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//tab=resize()扩容,并且n等于扩容后数组长度
//根据hash取模运算得到数组下标i,并取得Node节点,如果node节点是null,则初始化Node节点,在赋值数组下标位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//数组当前下标处为空,初始化Node节点
else {
Node<K,V> e; //临时变量,用来保存原先在HashMap的旧节点
K k;//用来保存节点对应的key值
//第一个if判断
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//判断节点的hash相等,并且key也相等,才算找到节点
e = p;
else if (p instanceof TreeNode)//判断Node节点是不是树几点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//红黑树插入数据
else {
//单链表遍历
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//判断e = p.next节点是否为null,为null说明已经遍历到链表结尾了
p.next = newNode(hash, key, value, null);//创建Node,并添加到链表尾部
//判断节点大小是否大于等于8,大于的话把 单链表转成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//通过tab和hash重新计算得到链表,把链表转成红黑树
break;
}
//判断e节点是否的hash和key 是否跟添加的key匹配,如果匹配跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//判断e不等于null,说明找到key值对应的节点了,原先key值存在这个链表中,进行赋值操作
if (e != null) { // existing mapping for key
V oldValue = e.value;
//判断 onlyIfAbsent 如果为true不会修改原先的值 或者 原先旧的值是null 会修改
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;//返回旧的值
}
}
++modCount;//修改次数+1
if (++size > threshold)//判断加入元素后的hash大小,是否大于阈值
resize();//扩容
afterNodeInsertion(evict);
return null;
}
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, //数组长度
index; //通过hash计算得到的数组下标
Node<K,V> e;//通过hash计算得到的数组下标,获得链表的开始节点
//判断数组为空 或者 数组长度小于64则进行扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();//扩容
else if ((e = tab[index = (n - 1) & hash]) != null) {//根据hash重新计算得到链表的开始节点
TreeNode<K,V> hd = null,
tl = null;
do {
//遍历链表的节点,把Node<K,V> e 转换成 TreeNode<K,V> p
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
//数组位置替换成树节点,并转换成红黑树
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
//扩容
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//取得旧数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;//取得旧数组长度
int oldThr = threshold;//旧阈值
int newCap, //新数组长度
newThr = 0;//新阈值(下次需要扩容的值)
if (oldCap > 0) {//判断旧数组长度是否大于0
if (oldCap >= MAXIMUM_CAPACITY) {//判断当前数组长度是否大于最大值,大于就不扩容了,直接返回原数组
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY; // 默认大小 16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//默认 0.75f * 16 = 12
}
if (newThr == 0) {//newThr == 0说明是初始化 第一次扩容
float ft = (float)newCap * loadFactor;//设置的创建hashMap 容量大小 * 负载因子
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);//判断是否超过了最大值
}
threshold = newThr;//下次需要扩容的数组大小
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//创建一个新的长度为newCap的数组,
table = newTab;//新数组赋值给HashMap参数table
if (oldTab != null) {
//遍历旧数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;//旧数组,对应的Node节点
//判断对应的Node旧节点不为null
if ((e = oldTab[j]) != null) {
oldTab[j] = null;//旧数组下标设置为null,方便gc回收
//判断旧Node节点next是否有下一个节点,如果为null,说明只有一个节点,则直接进行赋值即可
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;//根据旧node节点重新计算hash对应的位置,进行赋值
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//遍历红黑树节点,重新计算在新数组的下标,插入数据
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;//链表的下一个节点
//遍历单链表,从新计算链表节点,在新数组的下标,进行赋值
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;//返回新数组
}
根据key获取元素 get(Object key)
//根据key获取value值
public V get(Object key) {
Node<K,V> e;//key对应的node节点
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//根据key和它的hash值获取Node节点
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; //hashMap的数组
Node<K,V> first, //首节点
e;
int n;//数组长度
K k;//节点对应key值
//(n - 1) & hash 取模运算
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//检查第一个节点是否是key,如果是返回first
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//开始遍历
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);//红黑树获取对应的节点
//链表链表-获得对应的key所在节点
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;//hash和key相同,说明找到了直接return 返回值,跳出循环
} while ((e = e.next) != null);
}
}
return null;//没找到key对应的node返回null
}
根据key删除元素
//根据key删除元素
public V remove(Object key) {
Node<K,V> e;//要删除的节点
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab;//hashMap的数组
Node<K,V> p;//hash取模后,对应数组下标的node节点 (这个节点也是匹配到的节点的上一节点)
int n, //数组长度
index;//hash取模后的数组下标
//判断 hash取模后的数组对应的node是否为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null,//key值对应的node
e;//临时变量node
K k;//节点key值
V v;//节点value值
//判断是否在第一个节点匹配到了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {//判断下一个节点是否为null,不为null,开始查找
if (p instanceof TreeNode)//判断节点是否是红黑树,在树中查找
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//节点是链表,开始遍历链表
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;//hash和key都匹配了,说明找到节点了,赋值node,跳出循环
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//开始移除node节点
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)//判断节点是否是树
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);//红黑树移除节点
else if (node == p)//判断node节点是否是 第一个节点,如果是,直接指向node的下一个节点即可
tab[index] = node.next;
else
p.next = node.next;//指向查找到的node节点的next
++modCount;//修改次数加1
--size;//hashMap长度-1
afterNodeRemoval(node);
return node;//返回旧查找到的节点
}
}
return null;
}
小结
1、HashMap 是一种散列表的数据结构,底层采用数组 + 链表 + 红黑树来实现存储。
当链表长度大于8并且数组长度大于64的时候,会把链表转换成红黑树
当链表长度大于8并且数组长度小于64的时候,会进行扩容
在槽位的红黑树的节点数量小于等于 6 时,会退化回链表。
2、HashMap 的查找和添加 key-value 键值对的平均时间复杂度为 O(1) 。
对于槽位是链表的节点,平均时间复杂度为 O(k) 。其中 k 为链表长度。
对于槽位是红黑树的节点,平均时间复杂度为 O(logk) 。其中 k 为红黑树节点数量。
3、初始化大小为16,超过阀值【大小*0.75(负载因子)】时,按照两倍大小进行自动扩容。
4、允许null作为key值,非线程安全。
java集合-哈希表HashMap的更多相关文章
- java集合-哈希表HashTable
一.简介 HashTable也是一种key-value结构,key-value不允许null,并且这个类的几乎全部的方法都加上了synchronized锁,来保证并发安全,由于加了锁所以性能方面会比较 ...
- Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
概要 这一章,我们对HashMap进行学习.我们先对HashMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashMap.内容包括:第1部分 HashMap介绍第2部分 HashMa ...
- Java中哈希表(Hashtable)是如何实现的
Java中哈希表(Hashtable)是如何实现的 Hashtable中有一个内部类Entry,用来保存单元数据,我们用来构建哈希表的每一个数据是Entry的一个实例.假设我们保存下面一组数据,第一列 ...
- Java基础系列 - JAVA集合ArrayList,Vector,HashMap,HashTable等使用
package com.test4; import java.util.*; /** * JAVA集合ArrayList,Vector,HashMap,HashTable等使用 */ public c ...
- [Java集合] 彻底搞懂HashMap,HashTable,ConcurrentHashMap之关联.
注: 今天看到的一篇讲hashMap,hashTable,concurrentHashMap很透彻的一篇文章, 感谢原作者的分享. 原文地址: http://blog.csdn.net/zhanger ...
- 深入Java集合学习系列:HashMap的实现原理
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变 ...
- 深入Java集合学习系列:HashMap的实现原理--转
原文出自:http://www.cnblogs.com/xwdreamer/archive/2012/06/03/2532832.html 1. HashMap概述: HashMap是基于哈希表的Ma ...
- Java集合框架之三:HashMap源码解析
版权声明:本文为博主原创文章,转载请注明出处,欢迎交流学习! HashMap在我们的工作中应用的非常广泛,在工作面试中也经常会被问到,对于这样一个重要的集合模型我们有必要弄清楚它的使用方法和它底层的实 ...
- 转:深入Java集合学习系列:HashMap的实现原理
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现(Hashtable跟HashMap很像,唯一的区别是Hashtalbe中的方法是线程安全的,也就是同步的).此实现提供所 ...
随机推荐
- java例题_42 求满足809*??=800*??+9*??+1的??的值
1 /*42 [程序 42 求数字] 2 题目:809*??=800*??+9*??+1 3 其中??代表的两位数,8*??的结果为两位数,9*??的结果为 3 位数.求??代表的两位数,及 809* ...
- ionic3+angular 倒计时效果
// 声明变量 applicationInterval: any; // 定时器 nextBtnText: String; nextBtnBool: Boolean; // 使用定时器,每秒执行一次 ...
- Redis-AOF日志与RDB快照
AOF日志与RDB是Reids中两大持久化机制,当服务器或者Reids宕机的时候可以通过这两大机制恢复Redis的数据. 先说说AOF日志吧,在执行一条操作请求时,Redis先将命令在内存中执行,之后 ...
- [Fundamental of Power Electronics]-PART II-7. 交流等效电路建模-7.3 脉冲宽度调制器建模
7.3 脉冲宽度调制器建模 我们现在已经达成了本章开始的目标,为图7.1推导了一个有效的等效电路模型.但仍存在一个细节,对脉冲宽度调制(PWM)环节进行建模.如图7.1所示的脉冲宽度调制器可以产生一个 ...
- 如何讲一个网页转换为jpg?(图片!)
不需要安装插件!!! 打开网页,打开开发者工具 快捷键: ctrl+shift+p输入>full即可自动下载!
- 基于sinc的音频重采样(二):实现
上篇(基于sinc的音频重采样(一):原理)讲了基于sinc方法的重采样原理,并给出了数学表达式,如下: (1) 本文讲如何基于这个数学表达式来做软件实现.软件实现的 ...
- Chrome扩展开发基础教程(附HelloWorld)
1 概述 Chrome扩展开发的基础教程,代码基于原生JS+H5,教程内容基于谷歌扩展开发官方文档. 2 环境 Chrome 88.0.4324.96 Chromium 87.0.4280.141 B ...
- 【运维】Shell -- 快速上手Shell脚本
1.Shell概述 shell脚本是利用shell的功能所写的一个[程序(program)].这个程序是使用纯文本文件,将一些shell的语法与命令(含外部命令)写在里面,搭配正则表达式.管道命令与数 ...
- Mybatis3源码笔记(八)小窥MyBatis-plus
前言 Mybatis-Plus是一个 MyBatis增强工具包,简化 CRUD 操作,在 MyBatis 的基础上只做增强不做改变,为简化开发.提高效率而生,号称无侵入,现在开发中比较常用,包括我自己 ...
- 幻读:听说有人认为我是被MVCC干掉的
@ 目录 前言 系列文章 一.我是谁? 二.为什么有人会认为我是被MVCC干掉的 三.我真的是被MVCC解决的? 四.再聊当前读.快照读 当前读 快照读 五.告诉你们吧!当前读的情况下我是被next- ...