NeurIPS 2017 | TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning
在深度神经网络的分布式训练中,梯度和参数同步时的网络开销是一个瓶颈。本文提出了一个名为TernGrad梯度量化的方法,通过将梯度三值化为\({-1, 0, 1}\)来减少通信量。此外,本文还使用逐层三值化和梯度裁剪加速算法的收敛。
在传统的数据并行SGD的每次迭代\(t\)中,训练数据会被分成\(N\)份以供\(N\)个工作节点进行训练。工作节点\(i\)根据输入样本\(z_t^{(i)}\)计算参数的梯度\(\boldsymbol{g}_t^{(i)}\),之后,工作节点将梯度发送给参数服务器。参数服务器接收到所有工作节点的梯度后,对梯度进行聚合,然后把模型参数返回给工作节点。与基于参数服务器的传统数据并行SGD不同的是,TernGrad使用了参数本地化技术。也就是说,每个工作节点维护一个本地的参数副本,所有工作节点上的参数副本都由同一个随机种子初始化。在整个训练过程中,工作节点和参数服务器之间只传递量化后的梯度。
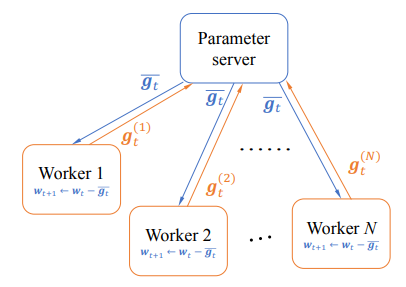
完整的TernGrad算法由Algorithm 1描述。相比于传统的数据并行SGD,TernGrad在每个工作节点上增加了梯度三值化和参数更新两个操作,参数服务器只需要聚合三值化后的梯度。

具体来说,TernGrad按照下式将梯度向量中的每个值映射到\(\{-1,0,+1\}\)上,这里\(\boldsymbol{b}_t\)是一个二元随机向量。
\]
\]
其中\(s_t\)是一个对\(\pm 1\)进行缩放的标量。\(\circ\)是Hadamard乘积,\(\text{sign}(\cdot)\)和\(\text{abs}(\cdot)\)分别返回每个元素的符号和绝对值。对于给定的\(\boldsymbol{g}_t\),\(\boldsymbol{b}_t\)的每个元素都独立地服从伯努利分布:
P(b_{tk}=1|\boldsymbol{g}_t) = |g_{tk}|/s_t\\
P(b_{tk}=0|\boldsymbol{g}_t) = 1-|g_{tk}|/s_t
\end{cases}
\]
其中\(b_{tk}\)和\(g_{tk}\)分别是\(\boldsymbol{b}_t\)和\(\boldsymbol{b}_t\)的第\(k\)个元素。之所以选择这种随机性舍入(stochastic rounding)而不是确定性舍入,是因为随机性舍入具有无偏的期望值且在低精度处理中应用广泛。
理论上,TernGrad至少可以将工作节点传递给参数服务器的通信量减少\(32/\log_2(3)\approx20.18\)倍。在实际实现上,我们至少需要2bit来编码\({-1, 0, 1}\)三个值,因此实际上能够减少约16倍的通信量。前面提到,TernGrad使用参数本地化技术来减少参数服务器传递给工作节点的通信量,也就是说参数服务器只对工作节点发送来的三值化梯度进行聚合。这可能导致聚合后的梯度\(\overline{\boldsymbol{g}_t}\)不再是三值化的,尤其是当工作节点使用不同的缩放因子\(s_t^{(i)}\)时。为了解决这一问题,作者使用标量共享技术,即所有工作节点之间共享同一个缩放因子\(s_t\):
\]
通过将参数本地化与标量共享相结合,理论上参数服务器传递给工作节点的通信量至少会降低\(32/\log_2(1+2N)\)倍。为了提高TernGrad的精度,本文提出了逐层三值化(layer-wise ternarizing)与梯度裁剪(gradient clipping)技术。在神经网络的每一层,梯度会随着后向传播而发生改变。因此,TernGrad在每一层使用不同的缩放因子,并且分别对权重和偏置进行三值化。为了进一步提高精度,还可以把梯度分割到不同的桶(bucket)中,再分别进行三值化。但是,这种方法将引入更多的浮点缩放因子并增加通信量。
逐层三值化可以缩小跨层梯度的动态值域所带来的方差间隔。然而,某一层梯度的动态值域仍然是一个问题。因此,TernGrad还使用了梯度裁剪技术,也就是限制梯度\(\boldsymbol{g}\)中元素\(g_i\)的范围:
\begin{cases}
g_i &|g_i| \leq c\sigma\\
\text{sign};(g_i)\cdot c\sigma &|g_i| \gt c\sigma
\end{cases}
\]
其中\(\sigma\)是\(\boldsymbol{g}\)中元素的标准差,\(c\)是一个需要调整的超参数,本文将该参数设置为2.5。在分布式训练时,每个工作节点先进行梯度裁剪操作,再进行梯度三值化操作。根据图2可以看出,无论是卷积层还是全连接层,所有的梯度都服从高斯分布并且集中在一个很小的范围内。梯度裁剪就是只保留小范围内的梯度,丢弃范围外的梯度。裁剪后,梯度近似服从正态分布,并且方向改变了一个小角度。
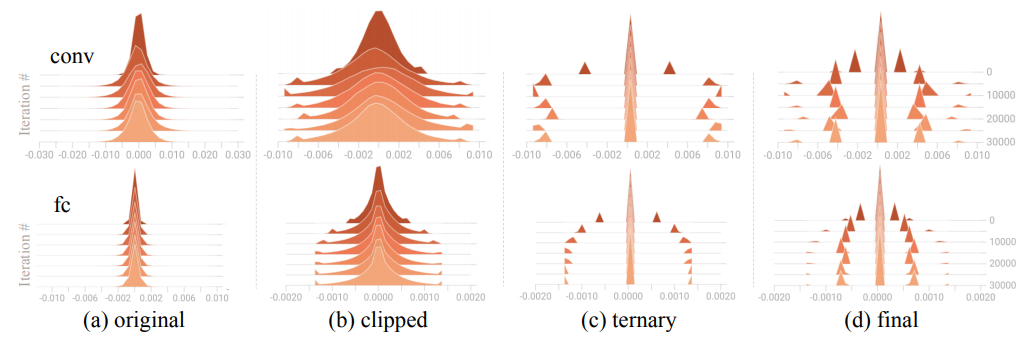
上述两种方法之所以有效,是因为当缩放因子\(s_t\)过大时,大多数梯度被三值化为\(0\),只有少数梯度被三值化为\(\pm 1\)。这就可能使得大多数参数不变而其他参数一直在调整,从而引入较高的训练方差。通过逐层三值化和梯度裁剪,就可以降低\(s_t\)的值,并且梯度分布近似于正态分布,从而降低了训练时的方差。
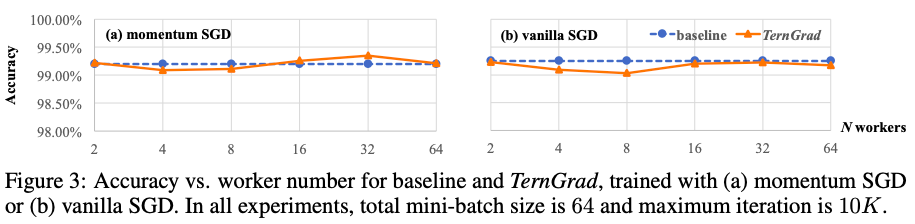
本文第一组实验主要比较了TernGrad在不同训练模式下的精度。这组实验用到了2个模型,分别是在MNIST数据集上训练的LeNet以及在CIFAR-10数据集上训练的ConvNet,其中ConvNET在训练时使用了数据增强技术。主要用到的优化算法包括传统的SGD,带动量的SGD以及Adam。图3是LeNet的实验结果。可以看到,使用TernGrad后的传统SGD和带动量的SGD可以在相同的迭代次数内收敛,并且精度不会损失很多。
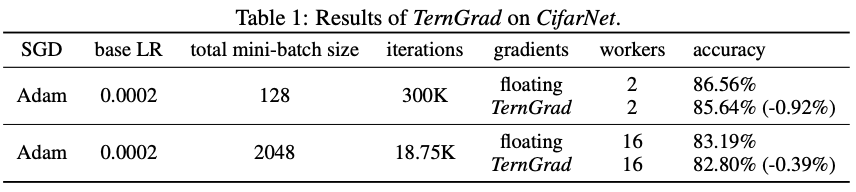
表1是ConvNet的实验结果。实验中,将每个工作节点的batch size设置为固定值。因此,总的batch size会随着工作节点的增加而线性增加。当batch size增大时,TernGrad和baseline的都会略有下降,这是因为较大的batch size会使参数的更新频率降低+,导致模型收敛到尖锐的极小值附近。
本文的第二部分实验主要介绍了将TernGrad在大规模训练时的效果。为了使TernGrad能够成功训练大型神经网络模型,实验中做了以下改动:
- 减少了dropout的比率。因为dropout为神经网络添加了随机性(相当于正则化),而TernGrad本身就引入了随机性。过高的dropout比率与TernGrad相结合会使模型效果变差。
- 使用较小的权值衰减策略,原因同上。
- 不对最后一层进行三值化。因为最后一层的one-hot编码会生成一个倾斜的分布,而三值化后的分布是对称的。
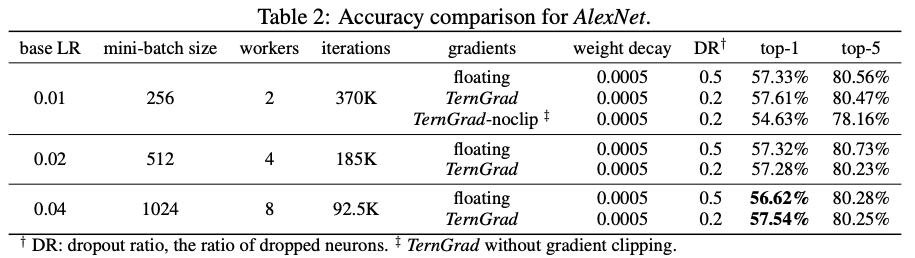
实验中所有的网络模型都使用带动量的SGD以及批量归一化(batch normalization)进行训练。AlexNet的结果如表2所示,每个工作节点的batch size固定为128。为了方便实验的进行,所有的深度网络模型都训练相同的epoch。因此,当工作节点增加时,总体的迭代次数就会变少,参数更新频率也会降低。在batch size增大的同时适当增加学习率可以克服这一问题。
接下来,我们对模型的性能,即吞吐量进行分析。我们主要分析了三个不同的网络模型——AlexNet、GoogLeNet和VggNet-A在使用不同数量的GPU时的吞吐量。
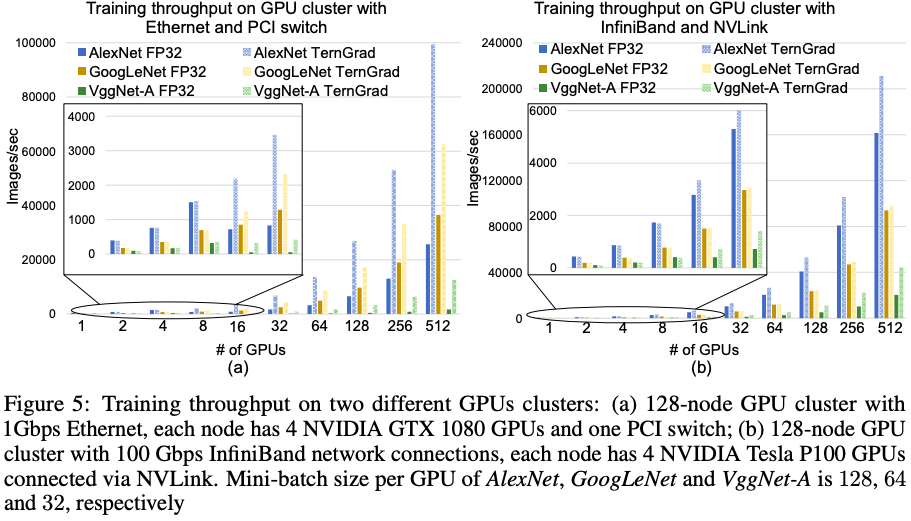
图5是三种网络模型在两个不同的GPU集群上的训练吞吐量。可以看到,TernGrad可以有效地提高训练吞吐量。总的来说,并行加速比取决于网络模型的通信-计算比、GPU的数量和网络带宽。拥有较大通信-计算比的网络模型(如AlexNet和VggNet-A)会更加受益于TernGrad。如图5(a)所示,TernGrad在带宽较小时表现非常好。图5(b)则说明使用高速互连网络(InfiniBand)时,TernGrad仍然可以对训练进行加速
NeurIPS 2017 | TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning的更多相关文章
- (转) Ensemble Methods for Deep Learning Neural Networks to Reduce Variance and Improve Performance
Ensemble Methods for Deep Learning Neural Networks to Reduce Variance and Improve Performance 2018-1 ...
- ISSCC 2017论文导读 Session 14 Deep Learning Processors,A 2.9TOPS/W Deep Convolutional Neural Network
最近ISSCC2017大会刚刚举行,看了关于Deep Learning处理器的Session 14,有一些不错的东西,在这里记录一下. A 2.9TOPS/W Deep Convolutional N ...
- ISSCC 2017论文导读 Session 14 Deep Learning Processors,A 2.9TOPS/W Deep Convolutional Neural Network SOC
最近ISSCC2017大会刚刚举行,看了关于Deep Learning处理器的Session 14,有一些不错的东西,在这里记录一下. A 2.9TOPS/W Deep Convolutional N ...
- NeurIPS 2017 | QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding
由于良好的可扩展性,随机梯度下降(SGD)的并行实现是最近研究的热点.实现并行化SGD的关键障碍就是节点间梯度更新时的高带宽开销.因此,研究者们提出了一些启发式的梯度压缩方法,使得节点间只传输压缩后的 ...
- EMNLP 2017 | Sparse Communication for Distributed Gradient Descent
通过将分布式随机梯度下降(SGD)中的稠密更新替换成稀疏更新可以显著提高训练速度.当大多数更新接近于0时,梯度更新会出现正偏差,因此我们将99%最小更新(绝对值)映射为零,然后使用该稀疏矩阵替换原来的 ...
- cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning 听课笔记
1. 深度学习面临的问题: 1)模型越来越大,很难在移动端部署,也很难网络更新. 2)训练时间越来越长,限制了研究人员的产量. 3)耗能太多,硬件成本昂贵. 解决的方法:联合设计算法和硬件. 计算硬件 ...
- ISSCC 2017论文导读 Session 14 Deep Learning Processors,DNPU: An 8.1TOPS/W Reconfigurable CNN-RNN
转载请注明,本文出自Bin的专栏http://blog.csdn.net/xbinworld,谢谢! DNPU: An 8.1TOPS/W Reconfigurable CNN-RNN Process ...
- cs231n spring 2017 lecture15 Efficient Methods and Hardware for Deep Learning
讲课嘉宾是Song Han,个人主页 Stanford:https://stanford.edu/~songhan/:MIT:https://mtlsites.mit.edu/songhan/. 1. ...
- cs231n spring 2017 lecture8 Deep Learning Networks 听课笔记
1. CPU vs. GPU: CPU核心少(几个),更擅长串行任务.GPU有很多核心(几千个),每一个核都弱,有自己的内存(几个G),很适合并行任务.GPU最典型的应用是矩阵运算. GPU编程:1) ...
随机推荐
- httprunner3.x全网最详细教程
一.所需环境 wiindows10以上 python3.6以上 httprunner3.1.6(最新版本) pycharm社区版 二.安装httprunner 1.卸载旧版本 卸载之前版本的命令为:p ...
- 【Java】IO
文章目录 IO 说明 流的分类 关于相对路径 节点流 FileRead 对read()操作升级:使用read的重载方法 总结 FileWriter 复制操作 总结 FileInput(Output)S ...
- RISC-V CPU加电执行流程
市面上采用RISC-V架构的CPU很多,且没有如X86那样高度细节的标准,故采用说明文档详细的SiFive Freedom U540-C000芯片来做介绍(下面统一称为FU540). FU540支持多 ...
- python测试框架-pytest
一.pytest 介绍.运行.参数化和数据驱动.Fixture pytest安装与介绍 官网 : pip install -U pytest 查看版本号:pytest --version 为何选择py ...
- Spark-寒假-实验3
1.安装 Hadoop 和 Spark 进入 Linux 系统,参照本教程官网"实验指南"栏目的"Hadoop 的安装和使用",完成 Hadoop 伪分布式模式 ...
- 论文翻译:2021_DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
论文地址:DeepFilterNet:基于深度滤波的全频带音频低复杂度语音增强框架 论文代码:https://github.com/ Rikorose/DeepFilterNet 引用:Schröte ...
- 基于SpringBoot如何实现一个点赞功能?
基于SpringBoot如何实现一个点赞功能? 解析: 基于 SpringCloud, 用户发起点赞.取消点赞后先存入 Redis 中,再每隔两小时从 Redis 读取点赞数据写入数据库中做持久化存储 ...
- golang中的匿名函数三种用法
package main import ( "fmt" "strconv" ) func main() { // 匿名函数的使用:方式1 f1 := func( ...
- Go 循环控制
#### Go 循环控制昨天有工作要忙, 断更一天,不过学习的事情,还是每天要坚持; 我还有头发, 还能学习^_^.***倘若我心中的山水, 你眼中都看到***上一节学习完流程控制,总结一下switc ...
- linux正则转换csv文件