numpy读取本地数据和索引
1、numpy读取数据
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)

做一个小demo:
现在这里有一个英国和美国各自youtube1000多个视频的点击,喜欢,不喜欢,评论数量(["views","likes","dislikes","comment_total"])的csv,运用刚刚所学习的只是,我们尝试来对其进行操作
数据来源:https://www.kaggle.com/datasnaek/youtube/data
# 暂无YouTube.csv数据
np.loadtxt(Us_video_data_numbers_path, delimiter=",", dtype=int, uppack=1)
delimiter:指定边界符号是什么,不指定会导致每行数据为一个整体的字符串而报错
dtype:默认情况下对于较大的数据会将其变为科学计数的方式
upack:默认是 Flase(0),默认情况下有多少条数据,就会有多少行;True(1)的情况下,每一列的数据会组成一行,原始数据有多少列,加载出来的数据就会有多少行,相当于转置(学过线代简而易懂)
转置的三种操作如下:
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print(A.T) # 转置操作
print("*"*10)
print(A.transpose()) # 转置操作
print("*"*10)
print(A.swapaxes(1, 0)) # 根据轴方向进行转置操作
[[1 4 7]
[2 5 8]
[3 6 9]]
[[1 4 7]
[2 5 8]
[3 6 9]]
[[1 4 7]
[2 5 8]
[3 6 9]]
2、numpy索引和切片
对于刚刚加载出来的数据,我如果只想选择其中的某一列(行)我们应该怎么做呢?
# 缺少数据集,暂且模拟实现
import numpy as np
USA_file_path = "./YouTuBe_Video_Data/America.csv"
t = np.loadtxt(USA_file_path, delimiter=",", dtype=int)
# 取第n行
print(t[2])
# 取连续的多行
print(t[2:])
# 取不连续的多行
print(t[2, 4, 6, 8, 10])
# 取列
print(t[1, :])
print(t[2:, :])
print(t[[2, 4, 6, 8, 10], :])
# 取连续的多列
print(t[:, 2:])
# 取不连续的多列
print(t[:, [0, 2]])
# 取行和列 如:第3行,第4列的值
print(t[2, 3])
# 取多行多列 如:第3行到第4行 第2列到第4列
# 取的是行和列交叉点的位置
print(t[2:5, 1:4])
# 取多个不相同的点
print(t[[0, 2], [0, 1]]) # 结果为(0,0) (2,1)
3、numpy中数值的修改
简单数值的修改:

那么问题来了:
比如我们想要把t中小于10的数字替换为3
一张图看明白:【可以看出为True的数值处全部改为了3】
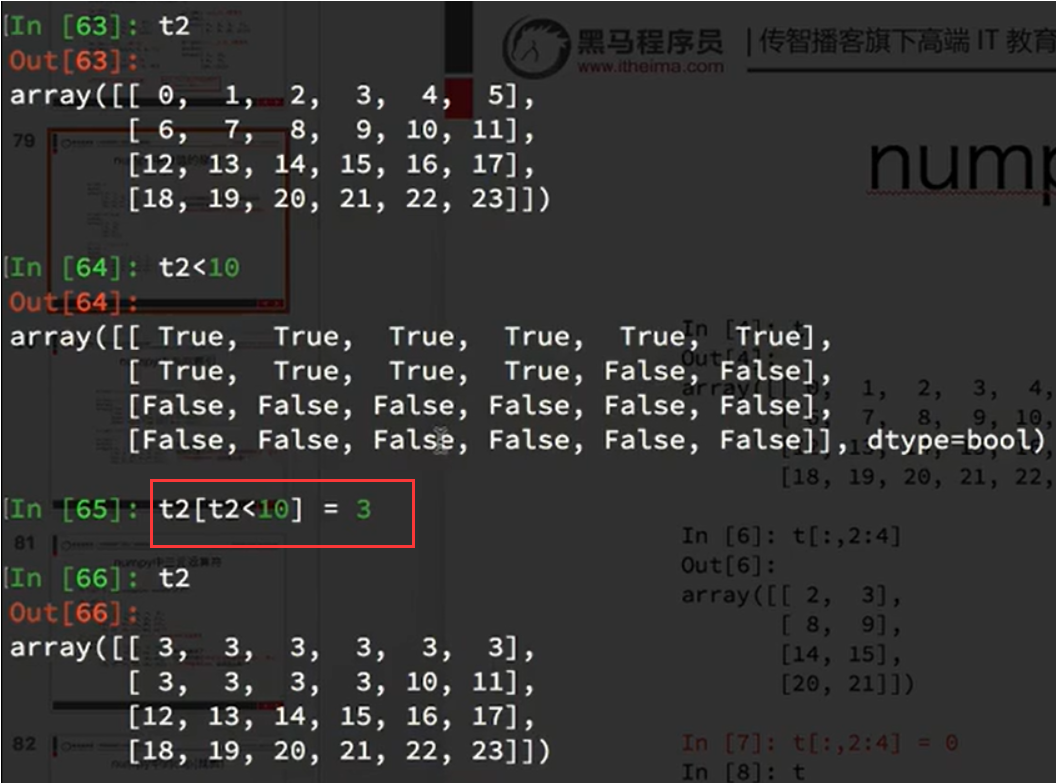
那么问题又来了:
如果我们想把t中小于10的数字替换为0,把大于10的替换为10,应该怎么做??
此处采用了三元运算符的思想

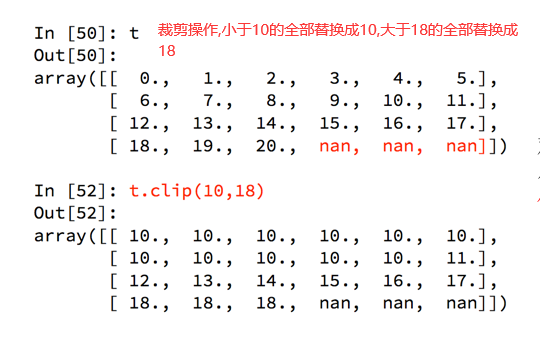
那么问题双来了:
如果我们想把t中小于10的数字替换为0,把大于18的替换为18,应该怎么做??
4、numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity, inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf)
- 比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf
那么如何指定一个nan或者inf呢?(注意他们的type类型)

5、numpy中的nan的注意点

那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响?
比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行
那么问题来了:
如何计算一组数据的中值或者是均值
如何删除有缺失数据的那一行(列)[在pandas中介绍]
6、numpy中常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)

默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
7、ndarry缺失值填充均值
t中存在nan值,如何操作把其中的nan填充为每一列的均值
import numpy as np
nan = np.nan
t = np.array([[0, 1, 2, 3, 4, 5],
[ 6, 7, nan, 9, 10, 11],
[12, 13, 14, nan, 16, 17],
[ 18, 19, 20, 21, 22, 23]])
def fill_nan_by_column_mean(t):
for i in range(t.shape[1]):
nan_num = np.count_nonzero(t[:, i][t[:, i] != t[:, i]]) # 计算非nan的个数
if nan_num > 0: # 存在nan值
now_col = t[:, i]
now_col_not_nan = now_col[np.isnan(now_col) == False].sum() # 求和
now_col_mean = now_col_not_nan / (t.shape[0] - nan_num) # 和/个数
now_col[np.isnan(now_col)] = now_col_mean # 赋值给now_col
t[:, i] = now_col # 赋值给t,即更新t的当前列
着实麻烦!后期学习pandas进行处理
numpy读取本地数据和索引的更多相关文章
- 04-numpy读取本地数据和索引
1.numpy读取数据 CSV:Comma-Separated Value,逗号分隔值文件 显示:表格状态 源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录 由于csv便于展示,读取和 ...
- Sql server 用T-sql读取本地数据文件dbf的数据文件
第一步启用Ad Hoc Distributed Queries 在SQLserver执行以下的语句: exec sp_configure 'show advanced options',1 reco ...
- win7(64位)Sql server 用T-sql读取本地数据文件dbf的数据文件
原文地址:https://www.cnblogs.com/cl1006/p/9924066.html 第一步启用Ad Hoc Distributed Queries 在SQLserver执行以下的语 ...
- jqGrid一次性读取本地数据
参考:http://blog.sina.com.cn/s/blog_54da57aa010154r7.html
- spark读取本地文件
/** * Read a text file from HDFS, a local file system (available on all nodes), or any * Hadoop-supp ...
- .NET读取Excel数据,提示错误:未在本地计算机上注册“Microsoft.ACE.OLEDB.12.0”提供程序
解决.NET读取Excel数据时,提示错误:未在本地计算机上注册“Microsoft.ACE.OLEDB.12.0”提供程序的操作: 1. 检查本机是否安装Office Access,如果未安装去去h ...
- 保存json数据到本地和读取本地json数据
private void saveJson(JsonBean bean) { File file = new File(getFilesDir(), "json.txt"); Bu ...
- 用NumPy genfromtxt导入数据
用NumPy genfromtxt导入数据 NumPy provides several functions to create arrays from tabular data. We focus ...
- mysql 读取硬盘数据
innodb 的最小管理单位是页 innodb的最小申请单位是区,一个区 1M,内含64个页,每个页16K ,即 64*16K=1M, 考虑到硬盘局部性,每次读取4个区,即读4M的数据加载至内存 线性 ...
随机推荐
- Storm近年的发展
storm作为第一款大数据领域的流式计算引擎,在2013年推出之后风头一时无二.后续虽然有spark streaming也作为流式计算的引擎,但storm依然在流式计算的江湖占有稳定的地位.直到201 ...
- [第六篇]——云服务器之Spring Cloud直播商城 b2b2c电子商务技术总结
云服务器 云服务器(Elastic Compute Service, ECS)是一种简单高效.安全可靠.处理能力可弹性伸缩的计算服务. 云服务器管理方式比物理服务器更简单高效,我们无需提前购买昂贵的硬 ...
- eclipes常见操作总结及项目2和3经验总结
eclipes常见操作总结及项目2经验总结 eclipes提示: 打开eclipes 选择window->perference->java->editor->content a ...
- 树莓派的kodi设置遥控器的方法
首先你需要买一个红外接收器,根据卖家的文档,插到树莓派的GPIO串口上, 我的红外接收器是18入口,17出口, 所以我的config.txt文件设置如下 dtoverlay=lirc-rpi,gpio ...
- Java实现导入Excel文件
一.配置文件名称.路径.内容: <bean id="multipartResolver" class="org.springframework.web.multip ...
- PHP中使用PDO操作事务的一些小测试
关于事务的问题,我们就不多解释了,以后在学习 MySQL 的相关内容时再深入的了解.今天我们主要是对 PDO 中操作事务的一些小测试,或许能发现一些比较好玩的内容. 在 MyISAM 上使用事务会怎么 ...
- jenkin—持续集成
jenkins与持续集成 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能.(百度百科) 持续集 ...
- pyqt5设计无边框窗口(一)
import sys from PyQt5 import QtGui,QtCore from PyQt5 import QtCore, QtGui, QtWidgets ############### ...
- Markdown学习 Day 001
Markdown学习 Day 001 快速标题 "#" + "空格" + "标题内容",回车即可,PS. "#"数量n代 ...
- 分组密码(五)AES算法② — 密码学复习(八)
在上一篇简单复习了AES的历史时间节点.产生背景.与DES的对比.算法框图(粗略)以及一些数学基础,如果不记得的话点击这里回顾.下面将介绍AES算法的细节. 下面给出AES算法的流程,图片来源:密码算 ...