JAVA-JDK1.7-ConCurrentHashMap-源码并且debug说明
概述
在一个程序员的成长过程就一定要阅读源码,并且了解其中的原理,只有这样才可以深入了解其中的功能,就像ConCurrentHashMap 是线程安全的,到底是如何安全的?以及如何正确使用它?rehash在什么情况?红黑树存储原理?不了解其中源码原理是不行的。所以今天就写一篇Java源码的,关于ConCurrentHashMap的源码,大部分来自于网上摘抄,有的需要自己测试验证,现作为随笔记录于此,便于记录整理 ,并且分享给大家共同进步。
ConCurrentHashMap的出生背景
哈希表是非常高效的数据结构,在JAVA开发中,最常见最频繁使用的就是HashMap和HashTable,但是在线程的使用范围中就显得乏力了,简单来说,HashMap是线程不安全的,在并发中环境中,可能会形成环状链表,导致get操作时候,cpu空转,死循环。HashTable虽然和HashMap原理几乎一样,差别只有2个;第一是,不允许key和value为null;第二是,他是线程安全的。但是HashTable线程安全的策略简单粗暴,所有相关操作都是synchronized的,相当于给整个hash表加了一把大锁,在多线程访问的时候,只要有一个线程访问或者操作这个对象,那其他线程只能阻塞,相当于将所有操作串行化,牺牲了很大的性能。所以就需要性能好又安全的哈希表结构,所以就有了本文的主角ConCurrentMap。现在我们逐步说明不同版本的原理。
ConCurrentHashMap简介
ConCurrentHashMap采用了锁分段技术:加入容器中有多把锁,没一把锁用于锁容器中一部分数据,那么当线程访问容器中里不同的数据段的数据时,线程间就不会存在锁竞争,从而就可以提高并发访问效率,简而言之,就是将数据一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也可能被其他线程访问。
ConCurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,并且在代码中HashEntry和Segment是两个静态内部类,数据结构如下图所示:
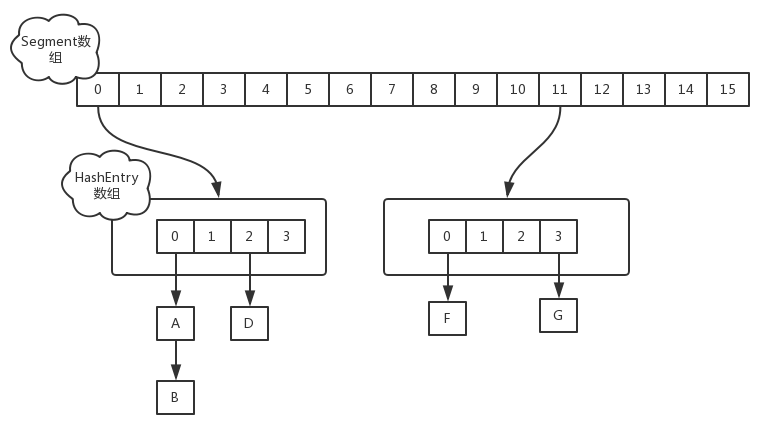
Segment数组的意义就是将一个大的table分割成多个小的table 来进行加锁,也就是上面提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。HashEntry用来封装映射表的键/值对;Segment充当锁的角色,每个Segment对象守护散列表的若干个的桶。每个桶是由若干个HashEntry对象连接起来的链表。
ConCurrentHashMap不允许key为null,ConCurrentHashMap不允许空值的主要原因是,在非并发映射中几乎不能容忍的模糊性是无法容纳的,主要一点是如果map.get(key)返回null,则无法检测key是否显示映射为null或未映射,在非并发中你可以使用map.contains(key)进行检查,但在并发映射中,映射可能在调用之间发生变化。
继承关系:ConcurrentHashMap继承了AbstractMap类,同时实现了ConcurrentMap接口。

HashEntry 类
HashEntry 用来封装散列映射表中的键值对,可以理解为一个桶。在 HashEntry 类中,key,hash 和 next 域都被声明为 final 型,value 域被声明为 volatile 型。
1 /**
2 * ConcurrentHashMap list entry. Note that this is never exported
3 * out as a user-visible Map.Entry.
4 */
5 static final class HashEntry<K,V> {
6 final int hash;
7 final K key;
8 volatile V value;
9 volatile HashEntry<K,V> next;
10
11 HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
12 this.hash = hash;
13 this.key = key;
14 this.value = value;
15 this.next = next;
16 }
17
18 39 }
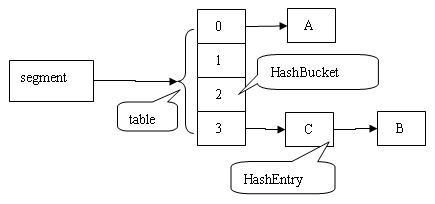
在 ConcurrentHashMap 中,在散列时如果产生“碰撞”,将采用“链地址法”来处理“碰撞”:把“碰撞”的 HashEntry 对象链接成一个链表。由于 HashEntry 的 next 域为 final 型,所以新节点只能在链表的表头处插入。下图是在一个空桶中依次插入 A,B,C 三个 HashEntry 对象后的结构图:

Segment 类
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。 count 变量是一个计数器,它表示每个 Segment 对象管理的 table 数组(若干个 HashEntry 组成的链表)包含的 HashEntry 对象的个数。每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的总数。
5 static final class Segment<K,V> extends ReentrantLock implements Serializable {
32
33 private static final long serialVersionUID = 2249069246763182397L;
34
42 static final int MAX_SCAN_RETRIES =
43 Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
44
49 transient volatile HashEntry<K,V>[] table;
50
55 transient int count;
56
64 transient int modCount;
65
71 transient int threshold;
72
79 final float loadFactor;
80
81 Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
82 this.loadFactor = lf;
83 this.threshold = threshold;
84 this.table = tab;
85 }
86
87 final V put(K key, int hash, V value, boolean onlyIfAbsent) {省略}
130
131 /**
132 * Doubles size of table and repacks entries, also adding the
133 * given node to new table
134 */
135 @SuppressWarnings("unchecked")
136 private void rehash(HashEntry<K,V> node) {省略}
196
197
207 private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {...}
245 private void scanAndLock(Object key, int hash) {...}
269
270 /**
271 * Remove; match on key only if value null, else match both.
272 */
273 final V remove(Object key, int hash, Object value) {...}
307
308 final boolean replace(K key, int hash, V oldValue, V newValue) {...}
331
332 final V replace(K key, int hash, V value) {...}
353
354 final void clear() {...}
366 }
下图是依次插入 ABC 三个 HashEntry 节点后,Segment 的结构示意图:
ConCurrentHashMap的构造方法
构造方法如下:
1 /**
2 * Creates a new, empty map with the specified initial
3 * capacity, load factor and concurrency level.
4 *
5 * @param initialCapacity the initial capacity. The implementation
6 * performs internal sizing to accommodate this many elements.
7 * @param loadFactor the load factor threshold, used to control resizing.
8 * Resizing may be performed when the average number of elements per
9 * bin exceeds this threshold.
10 * @param concurrencyLevel the estimated number of concurrently
11 * updating threads. The implementation performs internal sizing
12 * to try to accommodate this many threads.
13 * @throws IllegalArgumentException if the initial capacity is
14 * negative or the load factor or concurrencyLevel are
15 * nonpositive.
16 */
17 @SuppressWarnings("unchecked")
18 public ConcurrentHashMap(int initialCapacity,
19 float loadFactor, int concurrencyLevel) {
20 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
21 throw new IllegalArgumentException();
22 if (concurrencyLevel > MAX_SEGMENTS)
23 concurrencyLevel = MAX_SEGMENTS;
24 // Find power-of-two sizes best matching arguments
25 int sshift = 0;
26 int ssize = 1;
27 while (ssize < concurrencyLevel) {
28 ++sshift;
29 ssize <<= 1;
30 }
31 this.segmentShift = 32 - sshift;
32 this.segmentMask = ssize - 1;
33 if (initialCapacity > MAXIMUM_CAPACITY)
34 initialCapacity = MAXIMUM_CAPACITY;
35 int c = initialCapacity / ssize;
36 if (c * ssize < initialCapacity)
37 ++c;
38 int cap = MIN_SEGMENT_TABLE_CAPACITY;
39 while (cap < c)
40 cap <<= 1;
41 // create segments and segments[0]
42 Segment<K,V> s0 =
43 new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
44 (HashEntry<K,V>[])new HashEntry[cap]);
45 Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
46 UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
47 this.segments = ss;
48 }
这个构造函数有三个入参,如果用户不指定则会使用默认值,initialCapacity为16,loadFactor为0.75(负载因子,扩容时需要参考),concurrentLevel为16。现在我对初始化进行debug测试见下图:
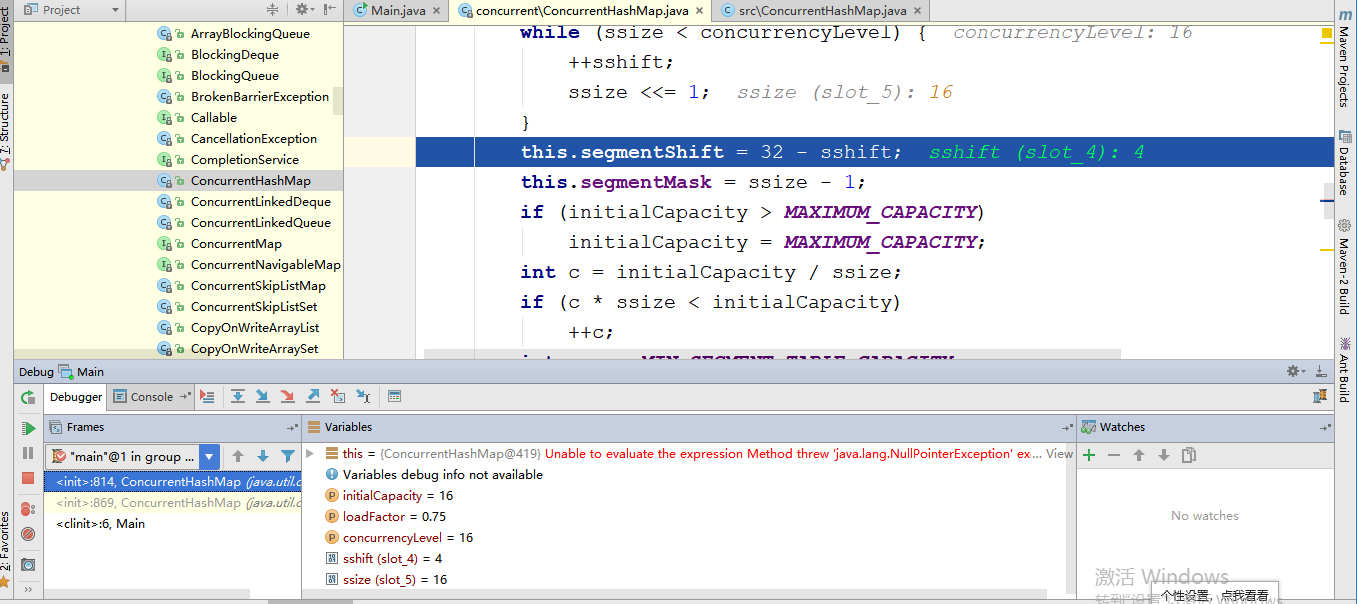
从上图可以知道当走到第31行代码时 31 this.segmentShift = 32 - sshift; 参数变量的值为图上所示,初始化大小 initialCapacity为16,负载 loadFactor为0.75(负载因子,扩容需要参考),并行度concurrencyLevel为16,sshit为4:2的sshit次方等于ssize,ssize为16:这是segment数组的长度,根据concurrencyLevel算出,代码可知ssize一定是大于或者等于concurrencyLevel最小的2次幂,为什么Segment大小一定是2次幂,那是因为通过位与散列算法来定位Segment的index,通过上面的结果计算出segmentShift和segmentMask,即segmentShit是28,为什么32减去4呢,因为hash()方法的输出最大位数就是32位数,segmentMask是散列运算的掩码,这里值是15,
关于segmentShit和segmentMask,
这两个全局变量主要作用就是定位segment,int j =(hash >>> segmentShift) & segmentMask。
segmentMask:段掩码,假如segments数组长度为16,则段掩码为16-1=15;segments长度为32,段掩码为32-1=31。这样得到的所有bit位都为1,可以更好地保证散列的均匀性
segmentShift:2的sshift次方等于ssize,segmentShift=32-sshift。若segments长度为16,segmentShift=32-4=28;若segments长度为32,segmentShift=32-5=27。而计算得出的hash值最大为32位,无符号右移segmentShift,则意味着只保留高几位(其余位是没用的),然后与段掩码segmentMask位运算来定位Segment。
第一步debug就是确定Segment的数组长度为16,并且初始化定位segment的变量。现在进行第二步debug
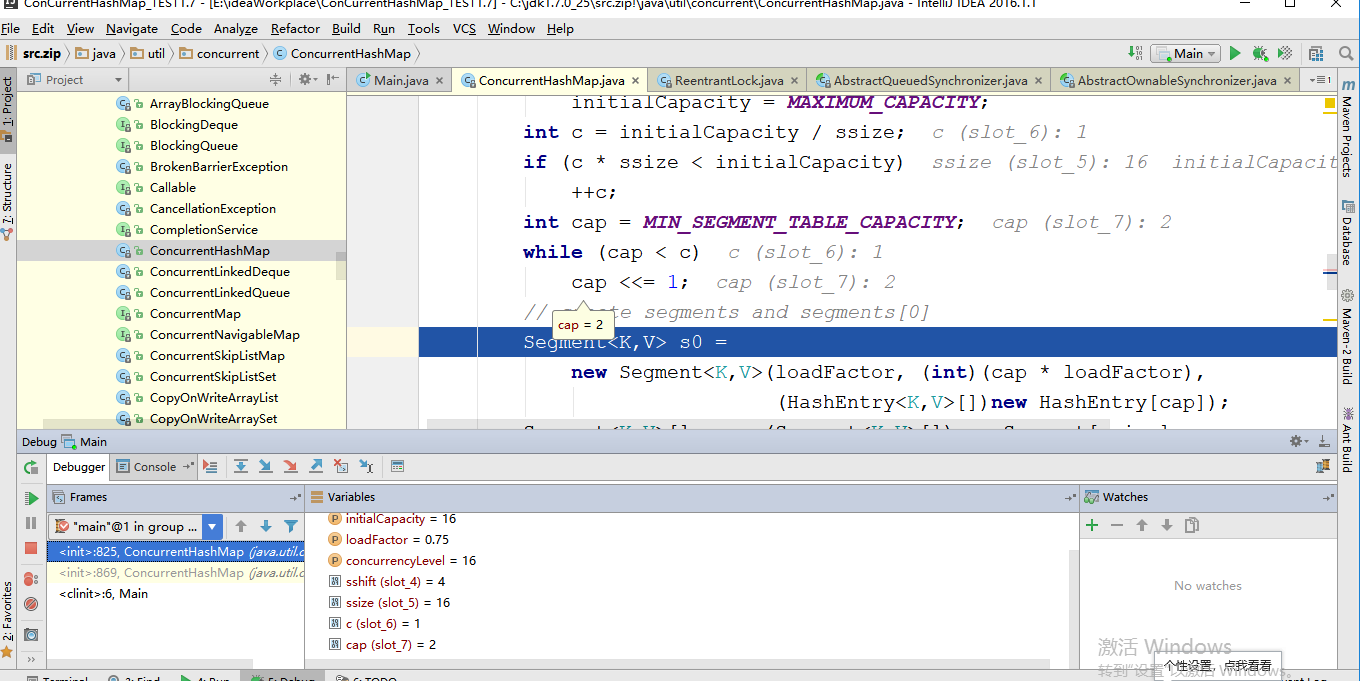
当运行到42行代码时候,由上图所示确认了经过计算得出HashEntry的数组初始化长度为2,进行第三部debug
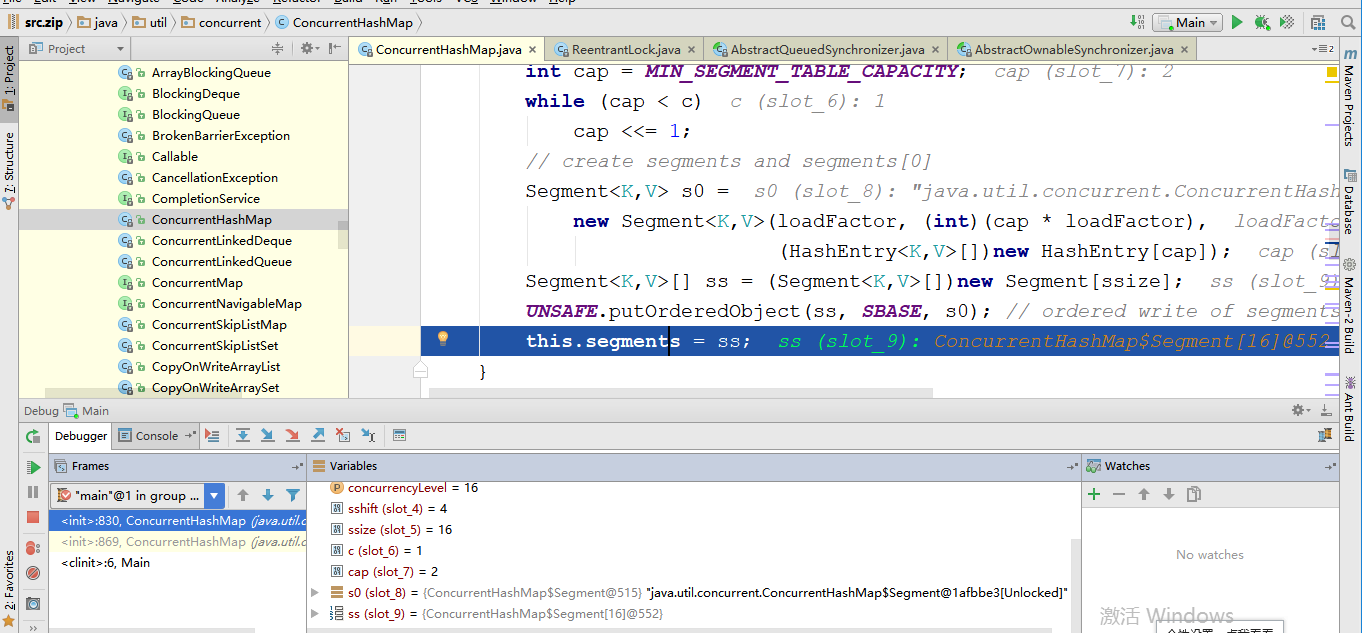
这里初始化了Segment,创建segments数组并初始化第一个Segment,其余的Segment延迟初始化,并且添加第0个元素
在源码中我们可以看出在构造ConCurrentHashMap中主要做3件事情。
1,确认并发度,也就是Segment的数组长度,并保证他是2的n次幂。
2,确认HashEntry数组的初始化长度,并保证他是2的n次幂。
3,将Segment初始化,并只是填充第0个元素。
put()方法
第一步主要是验证传参以及定位segment的index,主要流程是先获取key的hash值,定位segment,调用segment的put方法。这里就需要上文初始化得到的segmentShit和segmentMask的值就是下图的22行代码。
1 /**
2 * Maps the specified key to the specified value in this table.
3 * Neither the key nor the value can be null.
4 *
5 * <p> The value can be retrieved by calling the <tt>get</tt> method
6 * with a key that is equal to the original key.
7 *
8 * @param key key with which the specified value is to be associated
9 * @param value value to be associated with the specified key
10 * @return the previous value associated with <tt>key</tt>, or
11 * <tt>null</tt> if there was no mapping for <tt>key</tt>
12 * @throws NullPointerException if the specified key or value is null
13 */
14 @SuppressWarnings("unchecked")
15 public V put(K key, V value) {
16 Segment<K,V> s;
17 if (value == null)
18 throw new NullPointerException();
19 int hash = hash(key);
20 int j = (hash >>> segmentShift) & segmentMask;
21 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
22 (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
23 s = ensureSegment(j);
24 return s.put(key, hash, value, false);
25 }
hash方法源码为:也就是上图的19行代码:总的来说就是先拿到key的hashCode,然后对这个值进行再散列。
1 private int hash(Object k) {
2 int h = hashSeed;
3
4 if ((0 != h) && (k instanceof String)) {
5 return sun.misc.Hashing.stringHash32((String) k);
6 }
7
8 h ^= k.hashCode();
9
10 // Spread bits to regularize both segment and index locations,
11 // using variant of single-word Wang/Jenkins hash.
12 h += (h << 15) ^ 0xffffcd7d;
13 h ^= (h >>> 10);
14 h += (h << 3);
15 h ^= (h >>> 6);
16 h += (h << 2) + (h << 14);
17 return h ^ (h >>> 16);
18 }
返回第一张图put方法的23行的代码方法源码为:这里主要调用segment的put方法,
1 final V put(K key, int hash, V value, boolean onlyIfAbsent) {
2 HashEntry<K,V> node = tryLock() ? null :
3 scanAndLockForPut(key, hash, value);
4 V oldValue;
5 try {
6 HashEntry<K,V>[] tab = table;
7 int index = (tab.length - 1) & hash;
8 HashEntry<K,V> first = entryAt(tab, index);
9 for (HashEntry<K,V> e = first;;) {
10 if (e != null) {
11 K k;
12 if ((k = e.key) == key ||
13 (e.hash == hash && key.equals(k))) {
14 oldValue = e.value;
15 if (!onlyIfAbsent) {
16 e.value = value;
17 ++modCount;
18 }
19 break;
20 }
21 e = e.next;
22 }
23 else {
24 if (node != null)
25 node.setNext(first);
26 else
27 node = new HashEntry<K,V>(hash, key, value, first);
28 int c = count + 1;
29 if (c > threshold && tab.length < MAXIMUM_CAPACITY)
30 rehash(node);
31 else
32 setEntryAt(tab, index, node);
33 ++modCount;
34 count = c;
35 oldValue = null;
36 break;
37 }
38 }
39 } finally {
40 unlock();
41 }
42 return oldValue;
43 }
上图segment大致过程是:
- 加锁
- 定位key在tabl数组上的索引位置
index,获取到头结点 - 判断是否有hash冲突
- 如果没有冲突直接将新节点
node添加到数组index索引位 - 如果有冲突,先判断是否有相同key
- 有相同key直接替换对应node的value值
- 没有添加新元素到链表尾部
- 解锁
这里需要注意的是scanAndLockForPut方法,他在没有获取到锁的时候不仅会通过自旋获取锁,还会做一些其他的查找或新增节点的工,以此来提升put性能。
在上图代码有一段是调用scanAndLockForPut方法,对应行数第三行,该方法的源码是:
1 /**
2 * Scans for a node containing given key while trying to
3 * acquire lock, creating and returning one if not found. Upon
4 * return, guarantees that lock is held. UNlike in most
5 * methods, calls to method equals are not screened: Since
6 * traversal speed doesn't matter, we might as well help warm
7 * up the associated code and accesses as well.
8 *
9 * @return a new node if key not found, else null
10 */
11 private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
12 HashEntry<K,V> first = entryForHash(this, hash);
13 HashEntry<K,V> e = first;
14 HashEntry<K,V> node = null;
15 int retries = -1; // negative while locating node
16 while (!tryLock()) {
17 HashEntry<K,V> f; // to recheck first below
18 if (retries < 0) {
19 if (e == null) {
20 if (node == null) // speculatively create node
21 node = new HashEntry<K,V>(hash, key, value, null);
22 retries = 0;
23 }
24 else if (key.equals(e.key))
25 retries = 0;
26 else
27 e = e.next;
28 }
29 else if (++retries > MAX_SCAN_RETRIES) {
30 lock();
31 break;
32 }
33 else if ((retries & 1) == 0 &&
34 (f = entryForHash(this, hash)) != first) {
35 e = first = f; // re-traverse if entry changed
36 retries = -1;
37 }
38 }
39 return node;
40 }
scanAndLockForPut方法在当前线程获取不到segment锁的情况下,完成查找或新建节点的工作。当获取到锁后直接将该节点加入链表即可,提升了put操作的性能。大致过程:
- 定位key在HashEntry数组的索引位,并获取第一个节点
- 尝试获取锁,如果成功直接返回,否则进入自旋
- 判断是否有hash冲突,没有就直接完成新节点的初始化
- 有hash冲突,开始遍历链表查找是否有相同key
- 如果没找到相同key,那么就完成新节点的初始化
- 如果找到相同key,判断循环次数是否大于最大扫描次数
- 如果循环次数是否大于最大扫描次数,就直接CAS拿锁(阻塞式)
- 如果循环次数不大于最大扫描次数,判断头结点是否有变化
- 进入下次循环。
上面的Segment.rehash() 扩容方法就是segment的put方法第30行代码,Segment.rehash() 的源码是:
1 for (HashEntry<K,V> last = next;
2 last != null;
3 last = last.next) {
4 int k = last.hash & sizeMask;
5 if (k != lastIdx) {
6 lastIdx = k;
7 lastRun = last;
8 }
9 }
10 newTable[lastIdx] = lastRun;
11 // Clone remaining nodes
12 for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
13 V v = p.value;
14 int h = p.hash;
15 int k = h & sizeMask;
16 HashEntry<K,V> n = newTable[k];
17 newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
18 }
19 }
20 }
21 }
22 // 将新的节点加到对应索引位
23 int nodeIndex = node.hash & sizeMask; // add the new node
24 node.setNext(newTable[nodeIndex]);
25 newTable[nodeIndex] = node;
26 table = newTable;
27 }
在这里我们可以发现每次扩容是针对一个单独的Segment的,在扩容完成之前中不会对扩容前的数组进行修改,这样就可以保证get()不被扩容影响。大致过程是:
- 新建扩容后的数组,容量是原来的两倍
- 遍历扩容前的数组
- 通过
e.hash & sizeMask;计算key新的索引位 - 转移数据
- 将扩容后的数组指向成员变量
table
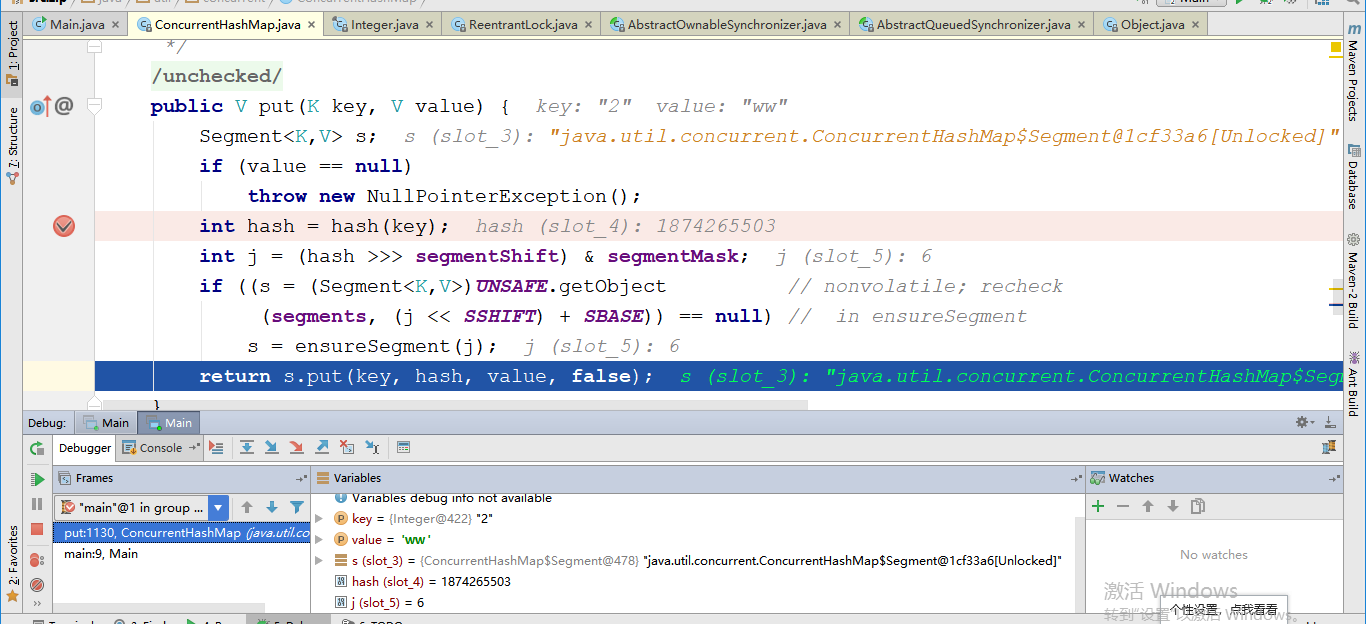
现在进行put方法的debug测试:
第一步,传值put(2,"ww"),计算hash值,定位要保存的segment数组,
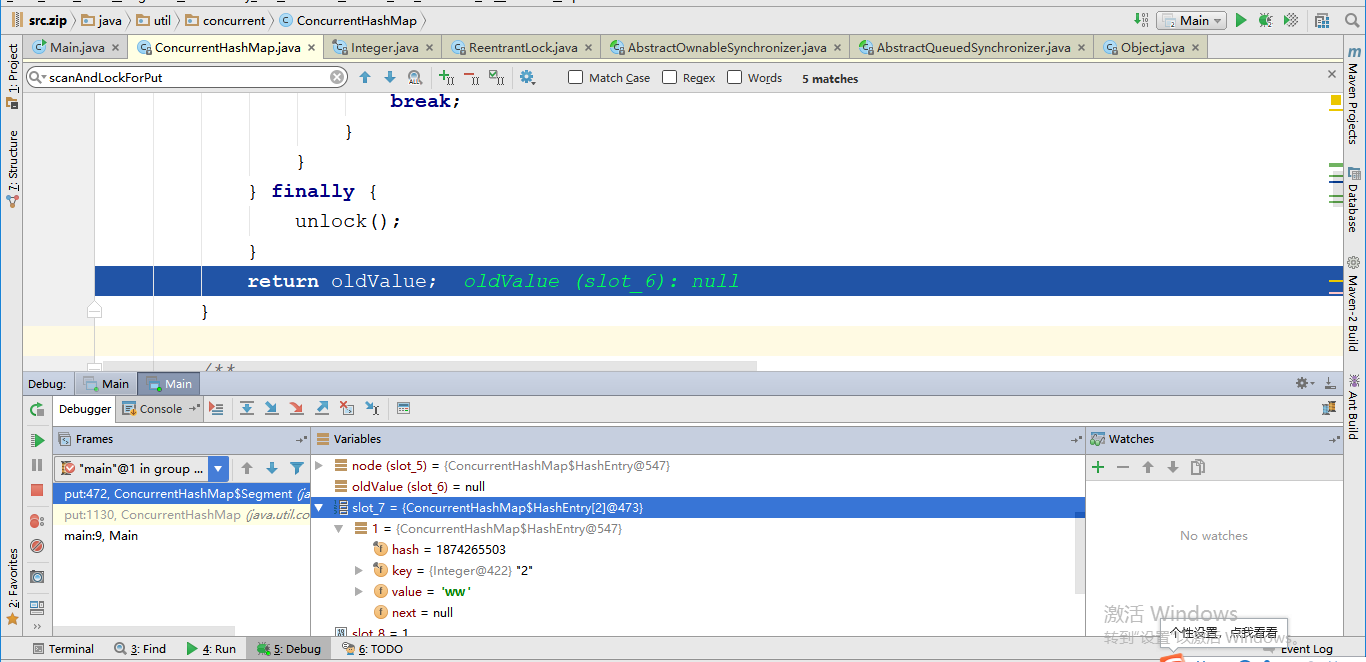
第二步,进入segment的put方法,值写入第7个segment数组中。在这一步需要执行的东西较多,但是比较重要的是,在写入前创建HashEentry节点初始化然后加锁,添加然后解锁。
get()方法
我们可以看到get方法是没有加锁的,因为HashEntry的value和next属性是volatile的,volatile直接保证了可见性,所以读的时候可以不加锁。
1 public V get(Object key) {
2 Segment<K,V> s; // manually integrate access methods to reduce overhead
3 HashEntry<K,V>[] tab;
4 int h = hash(key);
5 // 计算出Segment的索引位
6 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
7 // 以原子的方式获取Segment
8 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
9 (tab = s.table) != null) {
10 // 原子方式获取HashEntry
11 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
12 (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
13 e != null; e = e.next) {
14 K k;
15 // key相同
16 if ((k = e.key) == key || (e.hash == h && key.equals(k)))
17 // value是volatile所以可以不加锁直接取值返回
18 return e.value;
19 }
20 }
21 return null;
22 }
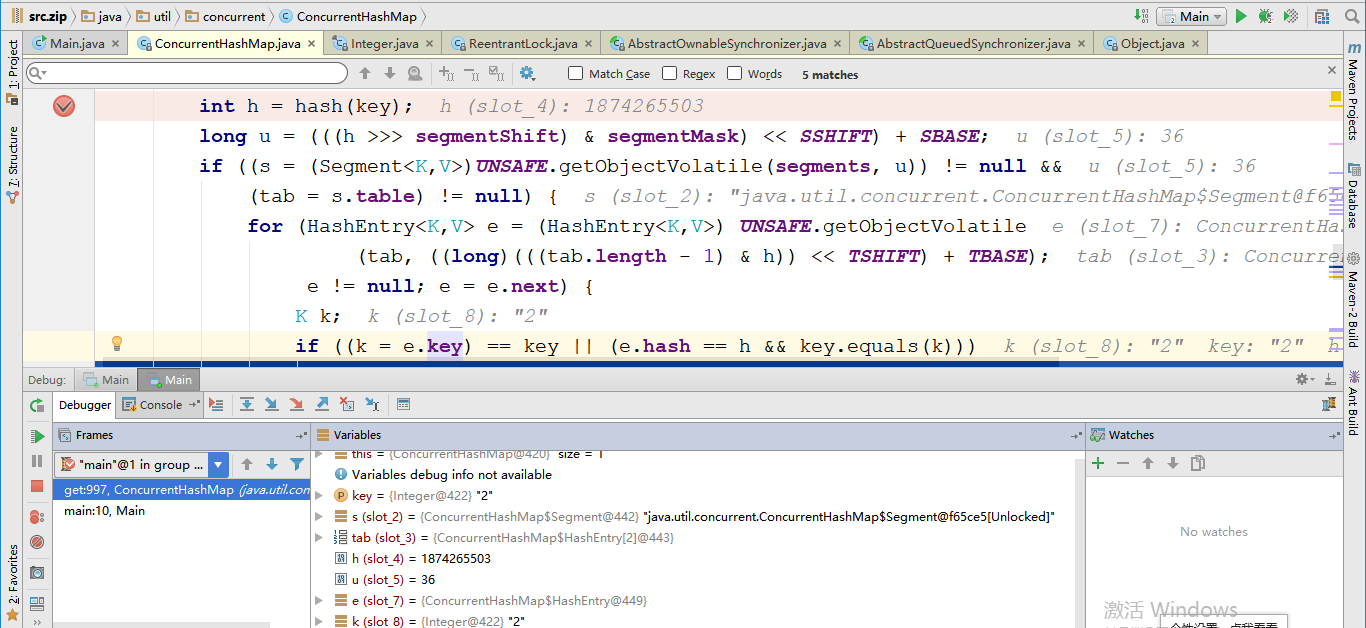
debug测试get(2),原来就存在key==2的value,看下图,先计算hash值,然后计算segment索引位置,然后判断是否存在segment和hashTable然后循环对比key值,返回value,
size()方法
1 public int size() {
2 // Try a few times to get accurate count. On failure due to
3 // continuous async changes in table, resort to locking.
4 final Segment<K,V>[] segments = this.segments;
5 int size;
6 // true表示size溢出32位(大于Integer.MAX_VALUE)
7 boolean overflow; // true if size overflows 32 bits
8 long sum; // sum of modCounts
9 long last = 0L; // previous sum
10 int retries = -1; // first iteration isn't retry
11 try {
12 for (;;) {
13 // retries 如果retries等于2则对所有Segment加锁
14 if (retries++ == RETRIES_BEFORE_LOCK) {
15 for (int j = 0; j < segments.length; ++j)
16 ensureSegment(j).lock(); // force creation
17 }
18 sum = 0L;
19 size = 0;
20 overflow = false;
21 // 统计每个Segment元素个数
22 for (int j = 0; j < segments.length; ++j) {
23 Segment<K,V> seg = segmentAt(segments, j);
24 if (seg != null) {
25 sum += seg.modCount;
26 int c = seg.count;
27 if (c < 0 || (size += c) < 0)
28 overflow = true;
29 }
30 }
31 if (sum == last)
32 break;
33 last = sum;
34 }
35 } finally {
36 // 解锁
37 if (retries > RETRIES_BEFORE_LOCK) {
38 for (int j = 0; j < segments.length; ++j)
39 segmentAt(segments, j).unlock();
40 }
41 }
42 //
43 return overflow ? Integer.MAX_VALUE : size;
44 }
size的核心思想是先进性两次不加锁统计,如果两次的值一样则直接返回,否则第三个统计的时候会将所有segment全部锁定,再进行size统计,所以size()尽量少用。因为这是在并发情况下,size其他线程也会改变size大小,所以size()的返回值只能表示当前线程、当时的一个状态,可以算其实是一个预估值。
debug进行测试:for体现了除非对比第二次执行break才可以跳出循环,
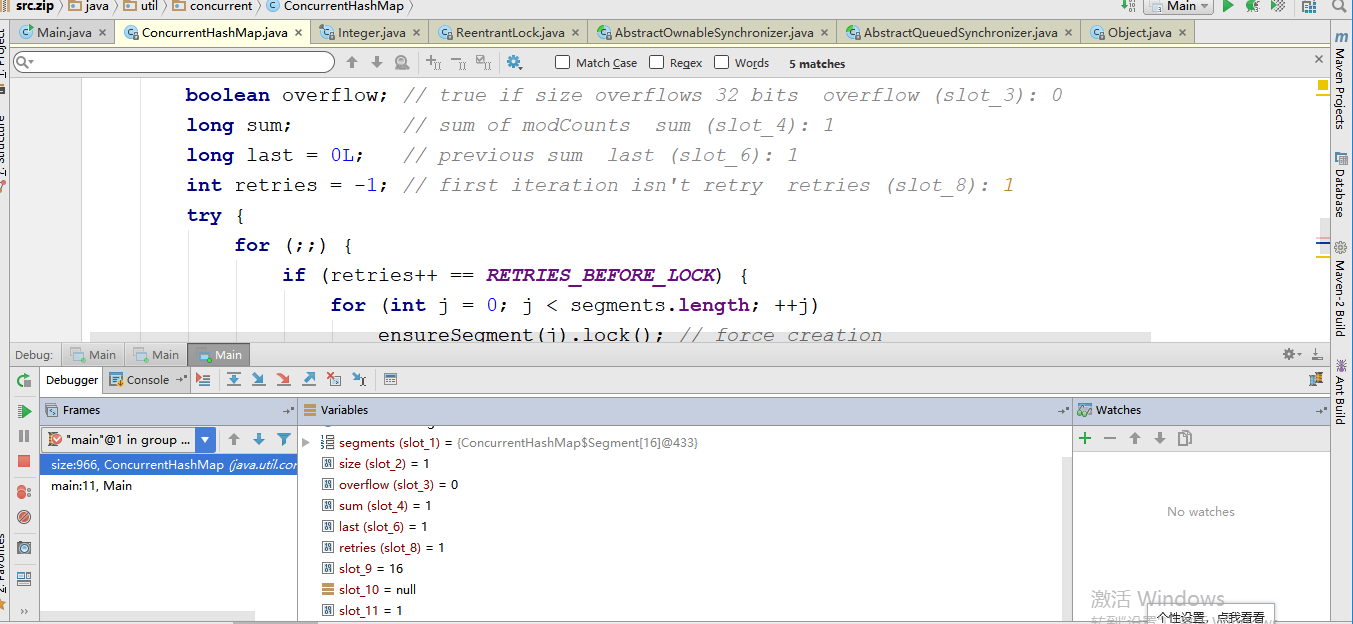
isEmpty() 方法
1 public boolean isEmpty() {
2 long sum = 0L;
3 final Segment<K,V>[] segments = this.segments;
4 for (int j = 0; j < segments.length; ++j) {
5 Segment<K,V> seg = segmentAt(segments, j);
6 if (seg != null) {
7 // 只要有一个Segment的元素个数不为0则表示不为null
8 if (seg.count != 0)
9 return false;
10 // 统计操作总数
11 sum += seg.modCount;
12 }
13 }
14 if (sum != 0L) { // recheck unless no modifications
15 for (int j = 0; j < segments.length; ++j) {
16 Segment<K,V> seg = segmentAt(segments, j);
17 if (seg != null) {
18 if (seg.count != 0)
19 return false;
20 sum -= seg.modCount;
21 }
22 }
23 // 说明在统计过程中ConcurrentHashMap又被操作过,
24 // 因为上面判断了ConcurrentHashMap不可能会有元素,所以这里如果有操作一定是新增节点
25 if (sum != 0L)
26 return false;
27 }
28 return true;
29 }
- 先判断Segment里面是否有元素,如果有直接返回,如果没有则统计操作总数;
- 为了保证在统计过程中ConcurrentHashMap里面的元素没有发生变化,再对所有的Segment的操作数做了统计;
- 最后 sum==0 表示ConcurrentHashMap里面确实没有元素返回true,否则一定进行过新增元素返回false。
和size方法一样这个方法也是一个若一致方法,最后的结果也是一个预估值。
总结
ConcurrentHashMap 拥有更高的并发性。在 HashTable 和由同步包装器包装的 HashMap 中,使用一个全局的锁来同步不同线程间的并发访问。同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器。这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了。
ConcurrentHashMap 的高并发性主要来自于三个方面:
用分离锁(Segment锁)实现多个线程间的更深层次的共享访问;
用 HashEntery 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求;
通过对同一个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性;
参考链接:
https://my.oschina.net/xiaolyuh/blog/3080609
http://xiaobaoqiu.github.io/blog/2014/12/25/concurrenthashmap/
JAVA-JDK1.7-ConCurrentHashMap-源码并且debug说明的更多相关文章
- 死磕 java集合之ConcurrentHashMap源码分析(三)
本章接着上两章,链接直达: 死磕 java集合之ConcurrentHashMap源码分析(一) 死磕 java集合之ConcurrentHashMap源码分析(二) 删除元素 删除元素跟添加元素一样 ...
- JDK1.7 ConcurrentHashMap 源码浅析
概述 ConcurrentHashMap是HashMap的线程安全版本,使用了分段加锁的方案,在高并发时有比较好的性能. 本文分析JDK1.7中ConcurrentHashMap的实现. 正文 Con ...
- 死磕 java集合之ConcurrentHashMap源码分析(一)
开篇问题 (1)ConcurrentHashMap与HashMap的数据结构是否一样? (2)HashMap在多线程环境下何时会出现并发安全问题? (3)ConcurrentHashMap是怎么解决并 ...
- JDK1.8 ConcurrentHashMap源码阅读
1. 带着问题去阅读 为什么说ConcurrentHashMap是线程安全的?或者说 ConcurrentHashMap是如何防止并发的? 2. 字段和常量 首先,来看一下ConcurrentHa ...
- 死磕 java集合之ConcurrentHashMap源码分析(二)——扩容
本章接着上一章,链接直达请点我. 初始化桶数组 第一次放元素时,初始化桶数组. private final Node<K,V>[] initTable() { Node<K,V> ...
- 死磕Java之聊聊HashSet源码(基于JDK1.8)
HashSet的UML图 HashSet的成员变量及其含义 public class HashSet<E> extends AbstractSet<E> implements ...
- 死磕Java之聊聊HashMap源码(基于JDK1.8)
死磕Java之聊聊HashMap源码(基于JDK1.8) http://cmsblogs.com/?p=4731 为什么面试要问hashmap 的原理
- Java之ConcurrentHashMap源码解析
ConcurrentHashMap源码解析 目录 ConcurrentHashMap源码解析 jdk8之前的实现原理 jdk8的实现原理 变量解释 初始化 初始化table put操作 hash算法 ...
- java Thread 类的源码阅读(oracle jdk1.8)
java线程类的源码分析阅读技巧: 首先阅读thread类重点关注一下几个问题: 1.start() ,启动一个线程是如何实现的? 2.java线程状态机的变化过程以及如何实现的? 3. 1.star ...
- 并发-ConcurrentHashMap源码分析
ConcurrentHashMap 参考: http://www.cnblogs.com/chengxiao/p/6842045.html https://my.oschina.net/hosee/b ...
随机推荐
- <转>libevent使用demo
这篇文章介绍下libevent在socket异步编程中的应用.在一些对性能要求较高的网络应用程序中,为了防止程序阻塞在socket I/O操作上造成程序性能的下降,需要使用异步编程,即程序准备好读写的 ...
- XGBoost特征选择
1. 特征选择的思维导图 2. XGBoost特征选择算法 (1) XGBoost算法背景 2016年,陈天奇在论文< XGBoost:A Scalable Tree Boosting Sys ...
- ciscn_2019_s_6
例行检查 没有开启nx保护,考虑用shellcode来做这道题 程序放入ida查看 我们可以输入48个字符覆盖0使printf打印出bp的值 继续看这里,buf的大小实际上只有0x38的大小,但是re ...
- List.Sum…统计信息(Power Query 之 M 语言)
数据源: 任意数据源,一列数值,一列非数值(文本) 目标: 对数值列进行求和等计算,对非数值列进行计数等计算 操作过程: 选取待计算的列>[转换]>[统计信息]>选取 M公式: ...
- CF363A Soroban 题解
Content 给出一个数 \(n\),请你用算盘来表示 \(n\). 这里的算盘和普通的算盘一样,只不过竖着摆放罢了.左边只有一个珠子,每个珠子表示 \(5\):右边有四个珠子,每个珠子表示 \(1 ...
- 阿里云ilogtail收集自建Kubernetes容器日志文件
背景 1,k8s属于自建. 2,需要收集应用服务容器里面指定目录的日志. 3,计划收集所有私有云php和nginx日志. 4,日志格式化处理. 思考 1,一个私有云一个Project,还是统一放入一个 ...
- java 输入输出IO流 RandomAccessFile文件的任意文件指针位置地方来读写数据
RandomAccessFile的介绍: RandomAccessFile是Java输入输出流体系中功能最丰富的文件内容访问类,它提供了众多的方法来访问文件内容,它既可以读取文件内容,也可以向文件输出 ...
- JAVA实现调用默认浏览器打开网页
/** * @title 使用默认浏览器打开 * @param url 要打开的网址 */ private static void browse2(String url) throws Excepti ...
- 基于DNN的残余回声抑制
摘要 由于功率放大器或扬声器的限制,即使在回声路径完全线性的情况下,麦克风捕获的回声信号与远端信号也不是线性关系.线性回声消除器无法成功地消除回声的非线性分量.RES是在AES后对剩余回声进行抑制的一 ...
- Qt5设置lineEdit正则表达式
说明 本文演示Qt 版本: qt5.14 一个例子 下面的代码中演示 输入框只能输入 冒号.A-F.a-f,数字0~9,最长输入64个字符 /// 设置验证 auto le_set_check = [ ...