Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath
1、快速开始
XPath是一种可以快速在HTML文档中选择并抽取元素、属性和文本的方法。
在Chrome,打开开发者工具,可以使用$x工具函数来使用XPath来选择元素,比如选中所有的超链接。
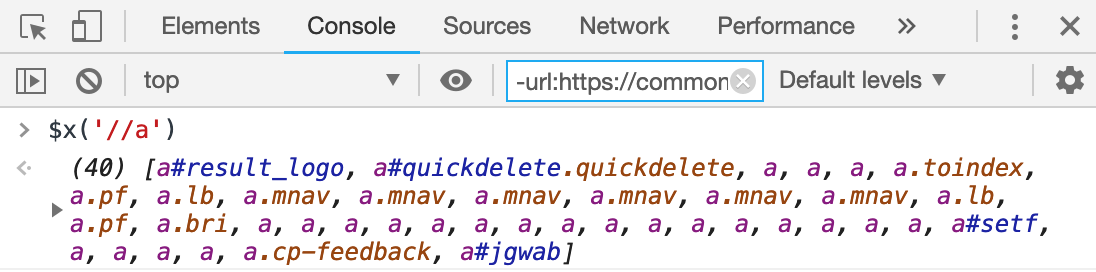
1.1、XPath的基本格式
XPath通过"路径表达式"(Path Expression)来选择节点。
在形式上,"路径表达式"与传统的文件系统非常类似。

比如我们依次获得Html节点(即最根节点)、Html下的Body节点、Html下的Body下的所有Div节点。
单斜杠与双斜杠:
在这里我们使用了单斜杠(/)作为最开始的元素,表示从根节点选取。如果我不想每次都从HTML元素出发,想直接取到Body元素,可以使用双斜杠(//),它表示直接命中待选择元素,而不考虑位置,如//body可以直接取到Body元素。

获取到节点的属性,可以使用@符号
[例1]
//h1/a/@id :获取所有h1元素直接子元素a的id属性。
获取节点的文本,使用text()函数
[例1]
//h1/a/text():获取所有h1元素直接子元素a的文本内容。
1.2、XPath的基本实例
我们以一个简易的类HTML文档,来进行实例分析。
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
[例1]
bookstore :选取 bookstore 元素的所有子节点。
[例2]
/bookstore :选取根节点bookstore,这是绝对路径写法。
[例3]
bookstore/book :选取所有属于 bookstore 的子元素的 book元素,这是相对路径写法。
[例4]
//book :选择所有 book 子元素,而不管它们在文档中的位置。
[例5]
bookstore//book :选择所有属于 bookstore 元素的后代的 book 元素,而不管它们位于 bookstore 之下的什么位置。
[例6]
//@lang :选取所有名为 lang 的属性。
2、XPath的谓语条件
谓语用来在查询的时候设置条件,来达到筛选的效果。
2.1、设置返回的节点数量

2.2、根据节点的属性或属性值来返回节点
[例1]
//div[@class] :选择文档中的所有拥有class属性的div节点。
[例2]
//div[@class='postTitle']:选择文档中的所有拥有class属性且值为postTitle的div节点。
2.3、根据节点是否有特点子元素来返回节点
[例1]
//div[a] :选择文档中的所有拥有a子元素的div节点。
3、XPath的通配符
"*"表示匹配任何元素节点。"@*"表示匹配任何属性值。node()表示匹配任何类型的节点。
[例1]
//* :选择文档中的所有元素节点。
[例2]
/*/* :表示选择所有第二层的元素节点。
[例3]
/HTML/* :表示选择HTML的所有元素子节点。
[例4]
//title[@*] :表示选择所有带有属性的title元素。
[例5]
//book/title | //book/price :表示同时选择book元素的title子元素和price子元素。
Scrapy:学习笔记(1)——XPath的更多相关文章
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- XML学习笔记6——XPath语言
在上一篇笔记的结尾,我们接触到了两个用于选择XML文档中特定范围的元素<selector>和<field>,这两个元素的取值都是XPath表达式,那么,什么是XPath呢?简单 ...
- scrapy学习笔记(1)
初探scrapy,发现很多入门教程对应的网址都失效或者改变布局了,走了很多弯路.于是自己摸索做一个笔记. 环境是win10 python3.6(anaconda). 安装 pip install sc ...
- Scrapy学习笔记(5)-CrawlSpider+sqlalchemy实战
基础知识 class scrapy.spiders.CrawlSpider 这是抓取一般网页最常用的类,除了从Spider继承过来的属性外,其提供了一个新的属性rules,它提供了一种简单的机制,能够 ...
- scrapy 学习笔记2
本章学习爬虫的 回调和跟踪链接 使用参数 回调和跟踪链接 上一篇的另一个爬虫,这次是为了抓取作者信息 # -*- coding: utf-8 -*- import scrapy class Myspi ...
- scrapy学习笔记一
以前写爬虫都是直接手写获取response然后用正则匹配,被大佬鄙视之后现在决定开始学习scrapy 一.安装 pip install scrapy 二.创建项目 scrapy startprojec ...
- Scrapy 学习笔记(一)数据提取
Scrapy 中常用的数据提取方式有三种:Css 选择器.XPath.正则表达式. Css 选择器 Web 中的 Css 选择器,本来是用于实现在特定 DOM 元素上应用花括号内的样式这样一个功能的. ...
- scrapy 学习笔记
1.scrapy 配合 selenium.phantomJS 抓取动态页面, 单纯的selemium 加 Firefox浏览器就可以抓取动态页面了, 但开启窗口太耗资源,而且一般服务器的linux 没 ...
随机推荐
- Java精选笔记_面向对象(多态、异常)
多态 概述 可以理解为事物存在的多种体现形态.同样的引用调用同样的方法却做了不同的事情 多态的本质是:一个程序中同名的不同方法. 多态的体现 父类的引用指向子类的对象,父类的引用接收子类的对象. 多态 ...
- Java 基本语法----数组
数组 数组概述 数组是多个相同类型数据的组合,实现对这些数据的统一管理. 数组属引用类型,数组型数据是对象(Object),数组中的每个元素相当于该对象的成员变量. 数组中的元素可以是任何数据类型,包 ...
- kafka的相关操作脚本
总结最近用到的kafka相关命令和脚本. 1.创建Topic./kafka-topics.sh --zookeeper cc13-141:2182 --topic mytopic --replicat ...
- 计算从ios照片库中选取的图片文件大小
本文转载至:http://blog.csdn.net/longzs/article/details/8373586 从 iphone 的 照片库中选取的图片,由于 系统不能返回其文件的具体路径,所以这 ...
- nil、Nil、NULL与NSNull的区别及应用
总结 nil:OC中的对象的空指针 Nil:OC中类的空指针 NULL:C类型的空指针 NSNull:数值类的空对象 详细解析应用如下: 1.nil 指向一个对象的指针为空 在objc.h中的定义 ...
- 如何提高AJAX客户端响应速度
AJAX的出现极大的改变了Web应用客户端的操作模式,它使的用户可以在全心工作时不必频繁的忍受那令人厌恶的页面刷新.理论上AJAX技术在很大的程度上可以减少用户操作的等待时间,同时节约网络上的数据流量 ...
- MUI 页面跳转(传值+接收)
官方:做web app,一个无法避开的问题就是转场动画:web是基于链接构建的,从一个页面点击链接跳转到另一个页面, 如果通过有刷新的打开方式,用户要面对一个空白的页面等待: 如果通过无刷新的方式,用 ...
- Docker源码分析(五):Docker Server的创建
1.Docker Server简介 Docker架构中,Docker Server是Docker Daemon的重要组成部分.Docker Server最主要的功能是:接受用户通过Docker Cli ...
- Android 动画fillAfter和fillBefore
fillBefore是指动画结束时画面停留在此动画的第一帧; fillAfter是指动画结束是画面停留在此动画的最后一帧. Java代码设置如下: /*****动画结束时,停留在最后一帧******* ...
- windows 下,go语言 交叉编译
http://bbs.csdn.net/topics/390601048 参考上面的操作