INNODB锁(2)
在上一篇文章写了锁的基本概述以及行锁的三种形式,这一篇的主要内容如下:
- 一致性非锁定读
- 自增长与锁
- 外键和锁
一致性性非锁定读
一致性非锁定读是InnoDB通过多版本并发控制(MVCC,multi version concurrency control)的方式来读取当前执行时间数据库中的最近一次快照,如果读取的行正在执行DELETE、UPDATE操作,这时读取操作不会等待行上锁的释放,相反,InnoDB存储引擎会去读取行的一个快照数据,如下图:
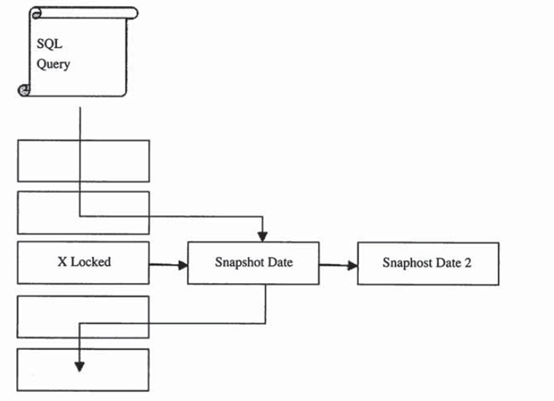
上图直观地展示了InnoDB存储引擎一致性的非锁定读,之所以称其为非锁定读,因为不需要等待访问的行上X锁的释放。快照数据是指该行之前版本的数据,该实现是通过Undo段来实现,而Undo用来在事务中回滚数据,因此快照数据本身是没有额外的开销。此外,读取快照数据是不需要上锁的,因为没有必要对历史的数据进行修改。
可以看到,非锁定读的机制大大提高了数据读取的并发性,在InnoDB存储因为默认设置下,这是默认的读取方式,即读取不会占用和等待表上的锁。但是在不同事务隔离级别下,读取的方式不同,并不是每个事务隔离级别下读取的都是一致性读。同样,即使都是使用一致性读,但是对于快照数据的定义也不相同。
通过上图,我们可以看出快照数据其实就是当前数据之前的历史版本,可能有多个版本。一个行可能又不止一个快照数据。我们称这种技术为行多版本技术。由此带来的并发控制,称之为多版本并发控制(MVCC,multi version concurrency control)
在READ COMMITTED和REPEATABLE READ下,InnoDB存储引擎使用非锁定的一致性读。然而,对于快照数据的定义却不相同。在READ COMMITTED事务隔离级别下,对于快照数据,非一致性读总是读取被锁定行的最新一份快照数据。在REPEATABLE READ事务隔离级别下,对于快照数据,非一致性读总是读取事务开始时的行数据版本。下面看一个列子:
| 时间序列 | 会话A | 会话B |
| 1 | mysql> begin; #开启一个事务 Query OK, 0 rows affected (0.00 sec) mysql> select * from tb1 where a = 5; |
|
| 2 |
mysql> begin; mysql> update tb1 set a = 13 where a = 5; #开启一个事务B,更新同一条数据 |
|
| 3 |
#这时候RR和RC隔离级别,查询到的数据都是如下(都解决了脏读问题): mysql> select * from tb1 where a = 5; |
|
| 4 |
#提交事务 mysql> commit; |
|
| 5 |
#在RR的隔离级别下数据读到的数据如下:读取事务开始时的版本 mysql> select * from tb1 where a = 5; |
|
| 6 |
#在RC的隔离级别下读到的数据如下:总是读取最新的一份快照数据。 mysql> select * from tb1 where a = 5; #这里我们提到过,同一个事务中两次读到的数据并不一样,其实违反了事务的隔离性,出现了幻读! |
自增长和锁
自增长在数据库中是非常常见的一种属性,也是很多DBA或开发人员首选的主键方式。在InnoDB存储引擎的内存结构中,对每个含有自增长值的表都有一个自增长计数器。当对含有自增长的计数器的表进行插入操作时,这个计数器会被初始化,执行如下的语句来得到计数器的值:
select max(auto_inc_col) from t for update;
插入操作会依据这个自增长的计数器值加1赋予自增长列。这个实现方式称为AUTO-INC Locking。这种锁其实是采用一种特殊的表锁机制,为了提高插入的性能,锁不是在一个事务完成后才释放,而是在完成对自增长值插入的SQL语句后立即释放。【注意自增锁释放的时机】
虽然AUTO-INC Locking从一定程度上提高了并发插入的效率,但还是存在一些性能上的问题。首先,对于有自增长值的列的并发插入性能较差,事务必须等待前一个插入的完成,虽然不用等待事务的完成。其次,对于INSERT….SELECT的大数据的插入会影响插入的性能,因为另一个事务中的插入会被阻塞。
从MySQL 5.1.22版本开始,InnoDB存储引擎中提供了一种轻量级互斥量的自增长实现机制,这种机制大大提高了自增长值插入的性能。并且从该版本开始,InnoDB存储引擎提供了一个参数innodb_autoinc_lock_mode来控制自增长的模式,该参数的默认值为1。在继续讨论新的自增长实现方式之前,需要对自增长的插入进行分类。如下说明:
- insert-like:指所有的插入语句,如INSERT、REPLACE、INSERT…SELECT,REPLACE…SELECT、LOAD DATA等。
- simple inserts:指能在插入前就确定插入行数的语句,这些语句包括INSERT、REPLACE等。需要注意的是:simple inserts不包含INSERT…ON DUPLICATE KEY UPDATE这类SQL语句。
- bulk inserts:指在插入前不能确定得到插入行数的语句,如INSERT…SELECT,REPLACE…SELECT,LOAD DATA。
- mixed-mode inserts:指插入中有一部分的值是自增长的,有一部分是确定的。入INSERT INTO t1(c1,c2) VALUES(1,’a’),(2,’a’),(3,’a’);也可以是指INSERT…ON DUPLICATE KEY UPDATE这类SQL语句。
接下来分析参数innodb_autoinc_lock_mode以及各个设置下对自增长的影响,其总共有三个有效值可供设定,即0、1、2,具体说明如下:
- 0:这是MySQL 5.1.22版本之前自增长的实现方式,即通过表锁的AUTO-INC Locking方式,因为有了新的自增长实现方式,0这个选项不应该是新版用户的首选了。
- 1:这是该参数的默认值,对于”simple inserts”,该值会用互斥量(mutex)去对内存中的计数器进行累加的操作。对于”bulk inserts”,还是使用传统表锁的AUTO-INC Locking方式。在这种配置下,如果不考虑回滚操作,对于自增值列的增长还是连续的。并且在这种方式下,statement-based方式的replication还是能很好地工作。需要注意的是,如果已经使用AUTO-INC Locing方式去产生自增长的值,而这时需要再进行”simple inserts”的操作时,还是需要等待AUTO-INC Locking的释放。
- 2:在这个模式下,对于所有”INSERT-LIKE”自增长值的产生都是通过互斥量,而不是AUTO-INC Locking的方式。显然,这是性能最高的方式。然而,这会带来一定的问题,因为并发插入的存在,在每次插入时,自增长的值可能不是连续的。此外,最重要的是,基于Statement-Base Replication会出现问题。因此,使用这个模式,任何时候都应该使用row-base replication。这样才能保证最大的并发性能及replication主从数据的一致。
mysql> show variables like "innodb_autoinc_lock_mode"; #这个数值默认是1,并且是个只读的变量,不能改变,可以从源码改变
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_autoinc_lock_mode | 1 |
+--------------------------+-------+
1 row in set (0.00 sec) mysql> set global innodb_autoinc_lock_mode = 2;
ERROR 1238 (HY000): Variable 'innodb_autoinc_lock_mode' is a read only variable
这里需要特别注意,InnoDB跟MyISAM不同,MyISAM存储引擎是表锁设计,自增长不用考虑并发插入的问题。因此在master上用InnoDB存储引擎,在slave上用MyISAM存储引擎的replication架构下,用户可以考虑这种情况。
另外,InnoDB存储引擎,自增持列必须是索引,同时必须是索引的第一个列,如果不是第一个列,会抛出异常,而MyiSAM不会有这个问题。
在给一个字段设置自增之后,从起始值开始,每次加1,那么这个起始值和步长是以下两个参数控制的:
mysql> show variables like "auto_increment%";
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_increment_increment | 1 | #设置自增值的起始值
| auto_increment_offset | 1 | #设置自增值的步长
+--------------------------+-------+
2 rows in set (0.00 sec) mysql> set auto_increment_increment = 2; #设置起始值为2
Query OK, 0 rows affected (0.00 sec) mysql> set auto_increment_offset = 2; #设置步长为2
Query OK, 0 rows affected (0.00 sec) mysql> create table test1(id int auto_increment primary key, name varchar(20)); #创建表,插入测试数据
Query OK, 0 rows affected (0.05 sec) mysql> insert into test1(name) values("zhao");
Query OK, 1 row affected (0.00 sec) mysql> insert into test1(name) values("qian");
Query OK, 1 row affected (0.01 sec) mysql> insert into test1(name) values("sun");
Query OK, 1 row affected (0.00 sec) mysql> select * from test1;
+----+------+
| id | name |
+----+------+
| 2 | zhao |
| 4 | qian |
| 6 | sun |
+----+------+
3 rows in set (0.00 sec)
外键和锁:
简单说一下外键,外键主要用于引用完整性的约束检查。在InnoDB存储引擎中,对于一个外键列,如果没有显示地对这个列加索引,InnoDB存储引擎会自动对其加一个索引,因为这样可以避免表锁。这比Oracle数据库做得好,Oracle数据库不会自动添加索引,用户必须自己手动添加,这也导致了Oracle数据库中可能产生死锁。
对于外键值的插入或更新,首先需要检查父表中的记录,既SELECT父表。但是对于父表的SELECT操作,不是使用一致性非锁定读的方式,因为这会发生数据不一致的问题,因此这时使用的是SELECT…LOCK IN SHARE MODE方式,即主动对父表加一个S锁。如果这时父表上已经这样加X锁,子表上的操作会被阻塞,如下:
实例如下:
# 创建parent表;
create table parent(
tag_id int primary key auto_increment not null,
tag_name varchar(20)
); # 创建child表;
create table child(
article_id int primary key auto_increment not null,
article_tag int(11),
CONSTRAINT tag_at FOREIGN KEY (article_tag) REFERENCES parent(tag_id)
); # 插入数据;
insert into parent(tag_name) values('mysql');
insert into parent(tag_name) values('oracle');
insert into parent(tag_name) values('mariadb');
开始测试
# Session A
mysql> begin
mysql> delete from parent where tag_id = 3; # Session B
mysql> begin
mysql> insert into child(article_id,article_tag) values(1,3); #阻塞
第二列是外键,执行该语句时被阻塞。
在上述的例子中,两个会话中的事务都没有进行COMMIT或ROLLBACK操作,而会话B的操作会被阻塞。这是因为tag_id为3的父表在会话中已经加了一个X锁,而此时在会话B中用户又需要对父表中tag_id为3的行加一个S锁,这时INSERT的操作会被阻塞。设想如果访问父表时,使用的是一致性的非锁定读,这时Session B会读到父表有tag_id=3的记录,可以进行插入操作。但是如果会话A对事务提交了,则父表中就不存在tag_id为3的记录。数据在父、子表就会存在不一致的情况。若这时用户查询INNODB_LOCKS表,会看到如下结果:
mysql> select * from information_schema.innodb_locks\G
*************************** 1. row ***************************
lock_id: 3359:35:3:4
lock_trx_id: 3359
lock_mode: S
lock_type: RECORD
lock_table: `test`.`parent`
lock_index: PRIMARY
lock_space: 35
lock_page: 3
lock_rec: 4
lock_data: 3
*************************** 2. row ***************************
lock_id: 3358:35:3:4
lock_trx_id: 3358
lock_mode: X
lock_type: RECORD
lock_table: `test`.`parent`
lock_index: PRIMARY
lock_space: 35
lock_page: 3
lock_rec: 4
lock_data: 3
2 rows in set, 1 warning (0.00 sec)
从锁结构可以看出,对于parent表加了两个锁,一个S锁和一个X锁。
博文基本摘自inside君的《MySQL技术内幕--INNODB存储引擎》,实际地址来自:http://www.ywnds.com/?p=9129
INNODB锁(2)的更多相关文章
- innodb 锁分裂继承与迁移
innodb行锁简介 行锁类型 LOCK_S:共享锁 LOCK_X: 排他锁 GAP类型 LOCK_GAP:只锁间隙 LOCK_REC_NO_GAP:只锁记录 LOCK_ORDINARY: 锁记录和记 ...
- InnoDB锁机制分析
InnoDB锁机制常常困扰大家,不同的条件下往往表现出不同的锁竞争,在实际工作中经常要分析各种锁超时.死锁的问题.本文通过不同条件下的实验,利用InnoDB系统给出的各种信息,分析了锁的工作机制.通过 ...
- MySQL数据恢复和复制对InnoDB锁机制的影响
MySQL通过BINLOG记录执行成功的INSERT,UPDATE,DELETE等DML语句.并由此实现数据库的恢复(point-in-time)和复制(其原理与恢复类似,通过复制和执行二进制日志使一 ...
- [转载] 数据库分析手记 —— InnoDB锁机制分析
作者:倪煜 InnoDB锁机制常常困扰大家,不同的条件下往往表现出不同的锁竞争,在实际工作中经常要分析各种锁超时.死锁的问题.本文通过不同条件下的实验,利用InnoDB系统给出的各种信息,分析了锁的工 ...
- mysql innodb锁简析(2)
继续昨天的innodb锁的分析: 注:此博文参考一下地址,那里讲的也很详细.http://xm-king.iteye.com/blog/770721 mysql事务的隔离级别分为四种,隔离级别越高,数 ...
- MySQL · 特性分析 · innodb 锁分裂继承与迁移
http://mysql.taobao.org/monthly/2016/06/01/ innodb行锁简介 行锁类型 LOCK_S:共享锁 LOCK_X: 排他锁 GAP类型 LOCK_GAP:只锁 ...
- Innodb 锁系列2 事务锁
上一篇介绍了Innodb的同步机制锁:Innodb锁系列1 这一篇介绍一下Innodb的事务锁,只所以称为事务锁,是因为Innodb为实现事务的ACID特性,而添加的表锁或者行级锁. 这一部分分两篇来 ...
- Innodb 锁 (简单笔记)
看过很多innodb锁的文章,已经明白的就不写了,简单做个笔记 Innodb 锁的兼容性: 1.意向锁和意向锁之间都是兼容的 2.X(排他锁)与任何锁都是不兼容的 3.排他意向锁 IX 于S锁是不 ...
- MySQL- InnoDB锁机制
InnoDB与MyISAM的最大不同有两点:一是支持事务(TRANSACTION):二是采用了行级锁.行级锁与表级锁本来就有许多不同之处,另外,事务的引入也带来了一些新问题.下面我们先介绍一点背景知识 ...
- MySQL InnoDB锁机制
概述: 锁机制在程序中是最常用的机制之一,当一个程序需要多线程并行访问同一资源时,为了避免一致性问题,通常采用锁机制来处理.在数据库的操作中也有相同的问题,当两个线程同时对一条数据进行操作,为了保证数 ...
随机推荐
- react实现的点击拖拽元素效果
之前用vue做日程管理组件的时候,用到了点击拖拽的效果,即点击元素,鼠标移动到哪里,元素移动到哪里,鼠标松开,拖拽停止,现在在弄react,于是也在想实现这个效果,经过一番折腾,效果出来了,代码如下: ...
- php学习十四:抽象,接口和多态
多态为面向对象编程的精华所在,js等面向过程的语言虽然可以模拟面向对象,但是毕竟模仿的永远比不上真的,所以了解而且会使用面向对象的多态是必不可少的 在了解多态之前,我们必须要了解接口,但是接口又是在抽 ...
- nginx 重复提交 重复请求问题
我遇到的奇葩问题. 后台使用的是nginx + tomcat 前端页面确实只发送了一个ajax请求到后台. 后台却接收到了两条请求! 百度了一下,说是因为nginx负载均衡,一个请求超时后会重复发送一 ...
- [Web Chart系列之六] canvas Chart 导出图文件
前言 博主正在参加CSDN2013年度博客之星评选,如果这篇文章对您有用,请投他一票: 投票地址:http://vote.blog.csdn.net/blogstaritem/blogstar2013 ...
- OC开发_代码片段——使用Xib自定义tableViewCell
一.实现步骤 1.新建一个XIB文件:描述cell——tableCell.xib 2.新建UITableViewCell的子类,也就是cell文件:封装XIB内部的所有东西——TestCell.m \ ...
- 求全局最小割(SW算法)
hdu3002 King of Destruction Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (J ...
- numeric_limits 模板的相关知识点
说白了,它是一个模板类,它主要是把C++当中的一些内建型别进行了封装,比如说numeric_limits<int>是一个特化后的类,从这个类的成员变量与成员函数中,我们可以了解到int的很 ...
- Linux定时对日志批量打包Shell脚本及定时任务crontab 详细用法
一.需求背景 因此次项目的生产环境中部署了多套系统,每天会产生大量的日志(数百GB的量),侵占了服务器宝贵的存储资源空间.为了有效缓解服务器存储压力,考虑通过Linux的Shell脚本结合cr ...
- nginx配置文件内容详情及基本属性配置
Nginx的配置文件nginx.conf配置详解如下: user nginx nginx ; Nginx用户及组:用户 组.window下不指定 worker_processes 8; 工作进程:数目 ...
- 【Loadrunner】性能测试:通过服务器日志获取性能需求
性能测试:通过服务器日志获取性能需求 接触过性能测试的童鞋都知道,想要做好一个项目的性能测试,性能需求的获取至关重要~!如果公司有做过性能测试还好,大家可以拿之前的性能测试数据作为参 ...