zookeeper和Kafka集群安装配置
3个虚拟机,首先关闭防火墙,在进行下面操作

和多个follower
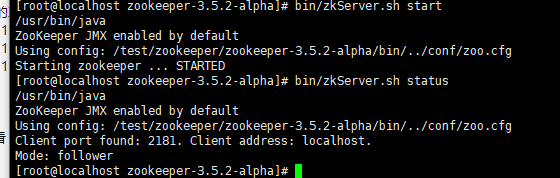


.png)

.png)

zookeeper和Kafka集群安装配置的更多相关文章
- (Linux环境Kafka集群安装配置及常用命令
Linux环境Kafka集群安装配置及常用命令 Kafka 消息队列内部实现原理 Kafka架构 一.下载Kafka安装包 二.Kafka安装包的解压 三.设置环境变量 四.配置kafka文件 4.1 ...
- kafka集群安装配置
1.下载安装包 2.解压安装包 3.进入到kafka的config目录修改server.properties文件 进入后显示如下: 修改log.dirs,基本上大部分都是默认配置 kafka依赖zoo ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- zookeeper+kafka集群安装之二
zookeeper+kafka集群安装之二 此为上一篇文章的续篇, kafka安装需要依赖zookeeper, 本文与上一篇文章都是真正分布式安装配置, 可以直接用于生产环境. zookeeper安装 ...
- zookeeper+kafka集群安装之一
zookeeper+kafka集群安装之一 准备3台虚拟机, 系统是RHEL64服务版. 1) 每台机器配置如下: $ cat /etc/hosts ... # zookeeper hostnames ...
- zookeeper+kafka集群安装之中的一个
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/cheungmine/article/details/26678877 zookeeper+kafka ...
- CentOS6安装各种大数据软件 第五章:Kafka集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- KafKa集群安装、配置
一.事前准备 1.kafka官网:http://kafka.apache.org/downloads. 2.选择使用版本下载. 3.kafka集群环境准备:(linux) 192.168.145.12 ...
- Kafka集群安装Version1.0.1(自带Zookeeper)
1.说明 Kafka集群安装,基于版本1.0.1, 使用kafka_2.12-1.0.1.tgz安装包, 其中2.12是编译工具Scala的版本. 而且不需要另外安装Zookeeper服务, 使用Ka ...
随机推荐
- Shape of passed values is (3490, 21), indices imply (3469, 21)
背景 处理DataFrame数据时,抛了这个错误:Shape of passed values is (3490, 21), indices imply (3469, 21) 解决 数据出现重复,导致 ...
- Django查询orm的前一天,前一周,一个月的数据
利用datatime模块的datetime.timedelta()方法 计算时间差,以下是用法 唯一要注意的是数据库存储models.datefield字段是日期格式,所以比较的数据也是日期格式 #当 ...
- OleDb未指定错误
桌面开发,居然也出这种问题: 1. C#读取Excel“未指定错误” http://www.connectionstrings.com/ http://www.dnetzj.com/Content/2 ...
- Hadoop MapReduce Task的进程模型与Spark Task的线程模型
Hadoop的MapReduce的Map Task和Reduce Task都是进程级别的:而Spark Task则是基于线程模型的. 多进程模型和多线程模型 所谓的多进程模型和多线程模型,指的是同一个 ...
- Django model中数据批量导入bulk_create()
在Django中需要向数据库中插入多条数据(list).使用如下方法,每次save()的时候都会访问一次数据库.导致性能问题: for i in resultlist: p = Account(nam ...
- Zabbix设置自定义监控
[zabbix]自定义监控项key值 说明: zabbix自带的默认模版里包括了很多监控项,有时候为了满足业务需求,需要根据自己的监控项目自定义监控项,这里介绍一种自定义监控项的方式. 1,首先编 ...
- 22. Generate Parentheses(回溯)
Given n pairs of parentheses, write a function to generate all combinations of well-formed parenthes ...
- VS2010/MFC编程入门之十(对话框:设置对话框控件的Tab顺序)
前面几节鸡啄米为大家演示了加法计算器程序完整的编写过程,本节主要讲对话框上控件的Tab顺序如何调整. 上一讲为“计算”按钮添加了消息处理函数后,加法计算器已经能够进行浮点数的加法运算.但是还有个遗留的 ...
- java提升路线
转载自:http://blog.csdn.net/a151296/article/details/43658853 作为一名即将从事java开发的应届毕业生,迷茫中,转载此篇文章,作为提升自己的学习方 ...
- #include <ntifs.h>出现PEPROCESS redefinition问题处理
转载:http://blog.csdn.net/ytfrdfiw/article/details/23334297 如果在自己的程序中,即包含ntddk.h和ntifs.h的时候,编译的时候会出现如下 ...