Python读取mdb文件以及shell检测
最近写了两个python的脚本不过实际意义不是很大,就是想练练python写程序,一直研究web方面脚本写的少多了,还有C语言也用的少多了。现在有时间得多写写程序,别把以前学到的知识给忘了。
【注:代码若被编辑器转义或编码,大家可点击代码框左上角的纯文本查看】
0×02 背景
当时想到写个这个脚本是前段时间看到一个文章写的“黑吃黑”的文章,发现shell后门网站的数据库直接暴漏在js里了,然后也去瞅了瞅就下载到了一个Webshell后门网站收到的shell的数据库,大概有8万条shell的链接和密码
这之中肯定有好多好多已经已经被管理员处理了,然后我就像用python把这些链接可以访问的筛选出来。但是当时脚本一直报错,就一直留着没写,最近就看了看网上的资料,写了下,目前是可以跑了,但是python的多线程确实是有限制。有点儿跑不开的感觉…
0×03脚本
首先需要安装一个python在windows上的一个扩展Python for Windows Extensions,这个扩展通过pip和easy_install都不能安装,应该不是一个常见的扩展。去这儿下载这个扩展:
https://sourceforge.net/projects/pywin32/files/
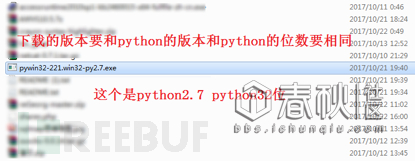
图上标注的问题一定要注意,文件一定要和python的版本和python的位数要匹配否则会报错的。安装好之后就可以写代码了。
1. # -*- utf-8 -*-
2. import win32com.client
3. import requests
4. from threading import *
5.
6. connection_lock = None
7.
8. # 定义检测链接的线程函数
9. def connect(url,file,password):
10. print url
11. print 'make a GET request'
12. try:
13. r = requests.get(url, timeout=5)
14. except:
15. print "url is abnormal."
16. connection_lock.release()
17. else:
18. if r.status_code == 200:
19. str = url+ '----' + password + '\n'
20. print str
21. file.writelines(str)
22. connection_lock.release()
23.
24. def main():
25.
26. global connection_lock
27. maxConnections = 30
28. file = open("url.txt",'a')
29. connection_lock = BoundedSemaphore(value = maxConnections)
30.
31. # 打开数据库进行链接,maUrl是打开表
32. conn = win32com.client.Dispatch(r'ADODB.Connection')
33. DSN = ';PROVIDER=Microsoft.Jet.OLEDB.4.0;DATA SOURCE=data.mdb'
34. conn.Open(DSN)
35. print 'connecting'
36. rs = win32com.client.Dispatch(r'ADODB.Recordset')
37. rs_name = 'maUrl'
38.
39. #
40. rs.Open('['+rs_name+']', conn, 1, 3)
41.
42. #遍历数据库中的行并进行多线程链接
43. while True:
44. url = rs.Fields.Item(1).Value
45. if url == None:
46. break
47. password = rs.Fields.Item(2).Value
48. url="http://"+url
49. connection_lock.acquire()
50.
51. #start the thread
52. t = Thread(target = connect, args=(url, file, password))
53. t.start()
54. rs.MoveNext()
55. file.close()
56.
57. if __name__ == "__main__"
58. main()
代码中说两个部分:
1. rs.Open()这儿第一个参数就是表名,第二个是打开数据库的句柄,后面两个参数照着写就行,具体是指代表adOpenKeyset 和adLockOptimistadLockOptimistic。有点儿蒙逼,但是看资料都是用的1,3.
2. 就是connection_lock = BoundedSemaphore(value = maxConnections)这儿就是创建一个线程池(在下自学的python可能有些术语不标准),启动线程的时候要去acquire一下,线程结束要release一下,就好像拿东西一样,用完了放回来,别人才能用。哈哈…
脚本跑完基本上筛选掉了95%的链接,这部分不是被做了跳转就是不能访问。剩下的5%基本上是可以访问的,但是能够访问不一定说明马还在,所以还要通过通过脚本访问链接再进一步排除一些,链接可以访问,但是页面做了更改的,或者是被防火墙拦截的页面,还有就是访问到域名服务商的页面,都要排除掉。
下面是进一步筛选的代码:
1. # -*- coding: utf-8 -*-
2. import urllib2
3. import re
4.
5. #检测标题中是否出现列表中一些敏感词汇
6. def check(key, title):
7. title = str(title)
8. print title
9. for t in key:
10. if t in title:
11. return False
12. return True
13.
14. if __name__ == '__main__':
15.
16. #有一下词汇的基本上就是被搞过的,或者设防了,或者没了
17. key = ["防火墙","阻断","不存在", "更名", "到期", "404", "502", "未找到", "删除", "访问","六合", "娱乐", "棋牌" ,"赌","出售","av","做爱","拒绝","综合","直播","色"]
18.
19. #准备txt存储结果
20. newfile = open('newurl.txt', 'w')
21.
22. #打开经过第一次筛选的文件
23. file = open("url.txt", 'r')
24.
25. #逐个去验证链接只进行了title检测,想不到还有啥其他的特征--,包括一些异常处理
26. for line in file:
27. print '-----------------------------------'
28. url = line.split('----', 1)[0]
29. print " checking:"+url
30. try:
31. response = urllib2.urlopen(url, timeout=10)
32. except Exception as e:
33. print "[-] Open Url Error."
34. else:
35. if response.geturl() == url:
36. try:
37. html = response.read()
38. except Exception as e:
39. print '[-] Open html error'
40. else:
41. title = re.search(r'<title>(.*)</title>', html, flags=re.I)
42. if title == None:
43. print '[+]' + '需手工检测:' + line
44. newfile.write(line)
45. else:
46. flag = check(key, title.group(1))
47. if flag:
48. print "[+] Find one."
49. newfile.write(line)
50. else:
51. print "[-] Url has been reseted."
52.
53. file.close()
54. newfile.close()
这个是单线程,多线程和多进程都测试了,效果还不如这个单线程好那。脚本跑完基本上可以筛选出大部分可用的马,但是还有一部分需要手工检测。不过经过这两轮的检测,测试了时间比较靠近的三万条shell最后剩下400多条了,可以说面积已经很小了,这东西好好整整,练习提权了,内网穿透不是好环境吗?哈哈…

0×03写在后面
之前有个freebuf的文章分析当年shell后门,单看文章吧感受不到啥感觉,直到你看到这几万条甚至十几万条的shell时候才有震撼。黑产的力量真的是可怕。
脚本语言可能会在日后的渗透中帮助我们很多,所以别把之前学东西给落下了。有些东西落下了不好捡起来,知识和人都是这样。
Python读取mdb文件以及shell检测的更多相关文章
- 记一次为解决Python读取PDF文件的Shell操作
目录 一.背景 二.问题 三.解决 四.一顿分析及 Shell 操作 五.后续 一.背景 本想将 PDF 文件转换为 Word 文档,然后网上搜索了一下发现有挺多转换的软件.有的是免费的.收费,咱也不 ...
- Python读取txt文件
Python读取txt文件,有两种方式: (1)逐行读取 data=open("data.txt") line=data.readline() while line: print ...
- Python读取Yaml文件
近期看到好多使用Yaml文件做为配置文件或者数据文件的工程,随即也研究了下,发现Yaml有几个优点:可读性好.和脚本语言的交互性好(确实非常好).使用实现语言的数据类型.有一个一致的数据模型.易于实现 ...
- python读取中文文件编码问题
python 读取中文文件后,作为参数使用,经常会遇到乱码或者报错asii错误等. 我们需要对中文进行decode('gbk') 如我有一个data.txt文件有如下内容: 百度 谷歌 现在想读取文件 ...
- Python读取SQLite文件数据
近日在做项目时,意外听说有一种SQLite的数据库,相比自己之前使用的SQL Service甚是轻便,在对数据完整性.并发性要求不高的场景下可以尝试! 1.SQLite简介: SQLite是一个进程内 ...
- Python读取xlsx文件
Python读取xlsx文件 脚本如下: from openpyxl import load_workbook workbook = load_workbook(u'/tmp/test.xlsx') ...
- Python 读取WAV文件并绘制波形图
aa Python 读取WAV文件并绘制波形图 ffmpeg -i test_pcm_mulaw.wav -f wav -codec:a pcm_s16le -ar 8000 -ac 1 out.wa ...
- 使用python读取yaml文件
在做APP测试时,通常需要把参数存到一个字典变量中,这时可以将参数写入yaml文件中,再读取出来. 新建yaml文件(android_caps.yaml),文件内容为: platformName: A ...
- python 读取bin文件
python读取bin文件并下发串口 # coding:utf-8import time, serialfrom struct import *import binascii file = ope ...
随机推荐
- 【bzoj1911】[Apio2010]特别行动队
1911: [Apio2010]特别行动队 Time Limit: 4 Sec Memory Limit: 64 MBSubmit: 4048 Solved: 1913[Submit][Statu ...
- overloading与overriding的区别
overloading: “重载”,参数和返回值可改变. overriding: “覆盖”,重写父类的虚函数,参数和返回值必须与父类相同. 重写Overriding是父类与子类之间多态性的一种表现,重 ...
- Visual Studio 2013 boost
E:\Visual Studio 2013\install\VC\bin\amd64>E:\IFC\boost_1_56_0_vs2013'E:\IFC\boost_1_56_0_vs2013' ...
- kafka常用运维命令
列出所有topic:bin/kafka-topics.sh --zookeeper localhost:2181 --list说明:其实就是去检查zk上节点的/brokers/topics子节点,打印 ...
- Git学习笔记——从一台电脑上传文件到Github上
目标:从一台电脑上传文件到Github上 前提: 1.这里假定已在Github上创建了仓库,建立了仓库 2.已在这台电脑上安装了Git客户端 实验环境: 1.Windows 10 64位,已安装了Gi ...
- sqlserver 2017 linux还原windows备份时的路径问题解决
windows的备份由于路径问题,在Linux上会报错 File 'YourDB_Product' cannot be restored to 'Z:\Microsoft SQL Server\MSS ...
- mongo学习- 副本集配置(事故自动转移)
一.安装mongodb 二.复制2份 三.启动 (1)mongod --config C:\mongofuben\zhu\conf\mongodb.config --replSet haibin/12 ...
- [转]TCP的拥塞控制
1.引言 计算机网络中的带宽.交换结点中的缓存和处理机等,都是网络的资源.在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就会变坏.这种情况就叫做拥塞. 拥塞控制就是防止 ...
- javadoc tags
Where Tags Can Be Used The following sections describe where the tags can be used. Note that these t ...
- Google Tango Java SDK开发:Configure and Connect 配置和连接
Configure and Connect 配置和连接 Note: This section assumes you are familiar with the Android Activity Li ...