CPU缓存刷新的误解
即使是资深的技术人员,我经常听到他们谈论某些操作是如何导致一个CPU缓存的刷新。看来这是关于CPU缓存如何工作和缓存子系统如何与执行核心交互的一个常见误区。本文将致力于解释CPU缓存的功能以及执行程序指令的CPU核心如何与缓存交互。我将以最新的Intel x86 CPU为例进行说明,其他CPU也使用相似技术以达到相同目的。
绝大部分常见的现代系统都被设计成在多处理器上共享内存。共享内存的系统都有一个单独的内存资源,它会被两个或者更多的独立CPU核心同时访问。核心到主存的延迟变化范围很大,大约在10-100纳秒。在100ns内,一个3GH的CPU可以处理多达1200条指令。每一个Sandy Bridge的CPU核心,在每个CPU时钟内可以并行处理4条指令。CPU使用缓存子系统避免了处理核心直接访问主存的延迟,这样能使CPU更高效的处理指令。一些缓存很小、非常快速并且集成在每个核心之内;而另一些则慢一些、更大、在各个核心间共享。这些缓存与寄存器和主内存一起构成了非持久性的内存体系。
当你在设计一个重要算法时要记住,缓存不命中所导致的延迟,可能会使你失去执行500条指令时间!这还仅是在单插槽(single-socket)系统上,如果是多插槽(multi-socket)系统,由于内存访问需要跨槽交互,可能会导致双倍的性能损失。
内存体系
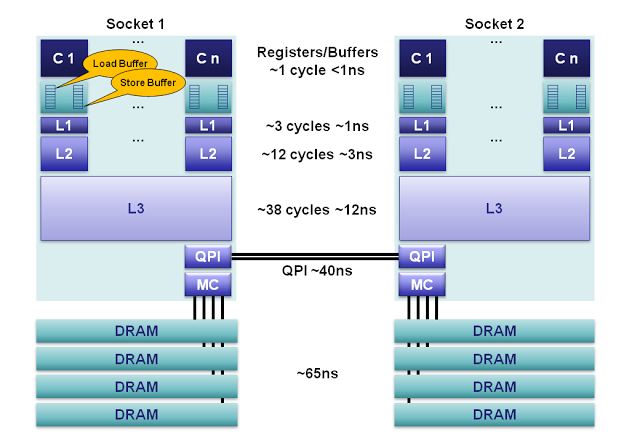
图1.对于2012 Sandy Bridge核心来说,内存模型可以大致按照如下进行分解:
1.寄存器:在每个核心上,有160个用于整数和144个用于浮点的寄存器单元。访问这些寄存器只需要一个时钟周期,这构成了对执行核心来说最快的内存。编译器会将本地变量和函数参数分配到这些寄存器上。当使用超线程技术(hyperthreading )时,这些寄存器可以在超线程协同下共享。
2.内存排序缓冲(Memory Ordering Buffers (MOB) ):MOB由一个64长度的load缓冲和36长度的store缓冲组成。这些缓冲用于记录等待缓存子系统时正在执行的操作。store缓冲是一个完全的相关性队列,可以用于搜索已经存在store操作,这些store操作在等待L1缓存的时候被队列化。在数据与缓存子系统传输时, 缓冲可以让处理器异步运转。当处理器异步读或者异步写的时候,结果可以乱序返回。为了使之与已发布的内存模型( memory model )一致,MOB用于消除load和store的顺序。
3.Level 1 缓存:L1是一个本地核心内的缓存,被分成独立的32K数据缓存和32K指令缓存。访问需要3个时钟周期,并且当指令被核心流水化时, 如果数据已经在L1缓存中的话,访问时间可以忽略。
4.L2缓存:L2缓存是一个本地核心内的缓存,被设计为L1缓存与共享的L3缓存之间的缓冲。L2缓存大小为256K,主要作用是作为L1和L3之间的高效内存访问队列。L2缓存同时包含数据和指令。L2缓存的延迟为12个时钟周期。
5.L3缓存: 在同插槽的所有核心都共享L3缓存。L3缓存被分为数个2MB的段,每一个段都连接到槽上的环形网络。每一个核心也连接到这个环形网络上。地址通过hash的方式映射到段上以达到更大的吞吐量。根据缓存大小,延迟有可能高达38个时钟周期。在环上每增加一个节点将消耗一个额外的时钟周期。缓存大小根据段的数量最大可以达到20MB。L3缓存包括了在同一个槽上的所有L1和L2缓存中的数据。这种设计消耗了空间,但是使L3缓存可以拦截对L1和L2缓存的请求,减轻了各核心私有的L1和L2缓存的负担。
6.主内存:在缓存完全没命中的情况下,DRAM通道到每个槽的延迟平均为65ns。具体延迟多少取决于很多因素,比如,下一次对同一缓存 行中数据的访问将极大降低延迟,而当队列化效果和内存刷新周期冲突时将显著增加延迟。每个槽使用4个内存通道聚合起来增加吞吐量,并通过在独立内存通道上流水线化( pipelining )将隐藏这种延迟。
7. NUMA:在一个多插槽的服务器上,会使用非一致性内存访问( non-uniform memory access )。所谓的非一致性是指,需要访问的内存可能在另一个插槽上,并且通过 QPI 总线访问需要额外花费40ns。 Sandy Bridge对于以往的兼容系统来说,在2插槽系统上是一个巨大的进步。在 Sandy Bridge上,QPI总线的能力从6.4GT/s提升到8.0GT/s,并且可以使用两条线路,消除了以前系统的瓶颈。对于 Nehalem and Westmere 来说,QPI只能使用内存控制器为一个单独插槽分配的带宽中的40%,这使访问远程内存成为一个瓶颈。另外,现在QPI链接可以使用预读取请求,而前一代系统不行。
关联度(Associativity Levels)
缓存是一个依赖于hash表的高效硬件。使用hash函数常常只是将地址中低位bit 进行映射 ,以实现缓存索引。hash表需要有解决对于同一位置冲突的机制。 关联度就是hash表中槽(slot)的数量,也被称为组(ways)和集合(sets),可以用来存储一个内存地址的hash版本。关联度的多少需要在存储数据的容量,耗电量和查询时间之间寻找平衡。(校对注:关联度越高,槽的数量越多,hash冲突越小,查询速度越快)
对于Sandy Bridge,L1和L2是8路组相连 ,L3是12路组相连 。(For Sandy Bridge the L1D and L2 are 8-way associative, the L3 is 12-way associative.)
缓存一致性
由于一些缓存在内核本地,我们需要一些方法保证一致性,使所有核心的内存视图一致。对于主流系统来说,内存子系统需要考虑“真实的来源(source of truth)”。如果数据只从缓存中来,那么它永远不会过期;当数据同时在缓存和主内存中存在时,缓存中存的是主拷贝(master copy)。这种内存管理被称为写-回(write-back),在此方式下,当新的缓存行占用旧行,导致旧行被驱逐时,缓存数据只会被写回主内存中。x86架构的每个缓存块的大小为64 bytes,称为缓存行( cache-line)。其它种类的处理器的缓存行大小可能不同。更大的缓存行容量降低延迟,但是需要更大的带宽(校对注:数据总线带宽)。
为了保证缓存的一致性,缓存控制器跟踪每一个缓存行的状态,这些状态的数量是有限的。Intel使用MESIF协议,AMD使用 MOESI。在MESIF协议下,缓存行处于以下5个状态中的1个。
被修改(Modified):表明缓存行已经过期,在接下来的场景中要写回主内存。当写回主内存后状态将转变为排它( Exclusive )。
独享(Exclusive):表明缓存行被当前核心单独持有,并且与主内存中一致。当被写入时,状态将转变为修改(Modified)。要进入这个状态,需要发送一个 Request-For-Ownership (RFO)消息,这包含一个读操作再加上广播通知其他拷贝失效。
共享(Shared):表明缓存行是一个与主内存一致的拷贝。
失效(Invalid):表明是一个无效的缓存行。
向前( Forward ):一个特殊的共享状态。用来表示在NUMA体系中响应其他缓存的特定缓存。
为了从一个状态转变为另一个状态,在缓存之间,需要发送一系列的消息使状态改变生效。对于上一代(或之前)的Nehalem核心的Intel CPU和 Opteron核心的AMD CPU,插槽之间确保缓存一致性的流量需要通过内存总线共享,这极大地限制了可扩展性。如今,内存控制器的流量使用一个单独的总线来传输。例如,Intel的QPI和AMD的HyperTransport就用于插槽间的缓存一致性通讯。
缓存控制器作为L3缓存段的一个模块连接到插槽上的环行总线网络。每一个核心,L3缓存段,QPI控制器,内存控制器和集成图形子系统都连接到这个环行总线上。环由四个独立的通道构成,用于:在每个时钟内完成请求、嗅探、确认和传输32-bytes的数据(The ring is made up of 4 independent lanes for: request, snoop, acknowledge, and 32-bytesdata per cycle)。L3缓存包含所有L1和L2缓存中的缓存行,这有助于帮助核心在嗅探变化时快速确认改变的行。用于L3缓存段的缓存控制器记录了哪个核心可能改变自己的缓存行。
如果一个核心想要读取一些数据,并且这些数据在缓存中并不处于共享、独占或者被修改状态;那么它就需要在环形总线上做一个读操作。它要么从主内存中读取(缓存没命中),要么从L3缓存读取(如果没过期或者被其他核心嗅探到改变)。在任何情况下,一致性协议都能保证,读操作永远不会从缓存子系统返回一份过期拷贝。
并发编程
如果我们的缓存总是保证一致性,那么为什么我们在写并发程序时要担心可见性?这是因为核心为了得到更好的性能,对于其它线程来说,可能会出现数据修改的乱序。这么做主要有两个理由。
首先,我们的编译器在生成程序代码时,为了性能,可能让变量在寄存器中存在很长的时间,例如,变量在一个循环中重复使用。如果我们需要这些变量在核心之间可见,那么变量就不能在寄存器分配。在C语言中,可以添加“volatile”关键字达到这个目标。要记住,c/c++中volatile并不能保证让编译器不重排我们的指令。因此,需要使用内存屏障。
排序的第二个主要问题是,一个线程写了一个变量,然后很快读取,有可能从读缓冲中获得比缓存子系统中最新值要旧的值。这对于遵循单写入者原则(Single Writer Principle)的程序来说没有任何问题,但是对于 Dekker 和Peterson锁算法就是个很大问题。为了克服这一点,并且确保最新值可见,线程不能从本地读缓冲中读取值。可以使用屏障指令,防止下一个读操作在另一线程的写操作之前发生。在Java中对一个volatile变量进行写操作,除了永远不会在寄存器中分配之外,还会伴随一个完全的屏障指令。在x86架构上,屏障指令在读缓冲排空之前,会显著影响放置屏障的线程的运行。在其它处理器上,屏障有更有效率的实现,例如 Azul Vega在读缓冲上放置一个标志用于边界搜索。
当遵循单写入者原则时,要确保Java线程之间的内存次序,避免store屏障,那么就使用j.u.c.Atomic(Int|Long|Reference).lazySet()方法,而非放置一个volatile变量。
误区
回到作为并发算法中的一部分的“刷新缓存”误区上,我想,可以说我们永远不会在用户空间的程序上“刷新”CPU缓存。我相信这个误区的来源是由于在某些并发算法需要刷新、标记或者清空store缓冲以使下一个读操作可以看到最新值。为了达到这点,我们需要内存屏障而非刷新缓存。
这个误解的另一个可能来源是,L1缓存,或者 TLB,在上下文切换的时候可能需要根据地址索引策略进行刷新。ARM,在ARMv6之前,没有在TLB条目上使用地址空间标签,因此在上下文切换的时候需要刷新整个L1缓存。许多处理器因为类似的理由需要L1指令缓存刷新,在许多场景下,仅仅是因为指令缓存没有必要保持一致。上下文切换消耗很大,除了污染L2缓存之外,上下文切换还会导致TLB和/或者L1缓存刷新。Intel x86处理器在上下文切换时仅仅需要TLB刷新。
(校对注:TLB是Translation lookaside buffer,即页表缓冲;里面存放的是一些页表文件,又称为快表技术,由于“页表”存储在主存储器中,查询页表所付出的代价很大,由此产生了TLB。)
原创文章,转载请注明: 转载自并发编程网 – ifeve.com
CPU缓存刷新的误解的更多相关文章
- C和C++中的volatile、内存屏障和CPU缓存一致性协议MESI
目录 1. 前言2 2. 结论2 3. volatile应用场景3 4. 内存屏障(Memory Barrier)4 5. setjmp和longjmp4 1) 结果1(非优化编译:g++ -g -o ...
- 基于JVM原理、JMM模型和CPU缓存模型深入理解Java并发编程
许多以Java多线程开发为主题的技术书籍,都会把对Java虚拟机和Java内存模型的讲解,作为讲授Java并发编程开发的主要内容,有的还深入到计算机系统的内存.CPU.缓存等予以说明.实际上,在实际的 ...
- 为什么CPU缓存会分为一级缓存L1、L2、L3?有什么意义?
https://baijiahao.baidu.com/s?id=1598811284058671259&wfr=spider&for=pc 简介:CPU缓存是CPU一个重要的组成部分 ...
- JMM内存模型、CPU缓存一致性原则(MESI)、指令重排、as-if-serial、happen-before原则
JMM三大特性原子性 汇编指令 --原子比较和交换在底层的支持 cmp-chxg 总线加锁机制 Synchronized Lock锁机制 public class VolatileAtomicSamp ...
- 【Java并发编程】从CPU缓存模型到JMM来理解volatile关键字
目录 并发编程三大特性 原子性 可见性 有序性 CPU缓存模型是什么 高速缓存为何出现? 缓存一致性问题 如何解决缓存不一致 JMM内存模型是什么 JMM的规定 Java对三大特性的保证 原子性 可见 ...
- cpu缓存和volatile
目录 CPU缓存的由来 CPU缓存的概念 CPU缓存的意义 缓存一致性协议-MESI协议 Store Buffers Store Forwarding Memory Barriers Invalida ...
- TLB和CPU缓存
TLB 如果每次应用程序访问一个线性地址都需要先解析(查PDT,PTT)那么效率十分低,为了提高执行效率CPU在CPU内部建立了一个TLB表,此表和寄存器一样访问速度极高.其会记录线性地址和物理地址之 ...
- 第三章 - CPU缓存结构和java内存模型
CPU 缓存结构原理 CPU 缓存结构 查看 cpu 缓存 速度比较 查看 cpu 缓存行 cpu 拿到的内存地址格式是这样的 CPU 缓存读 根据低位,计算在缓存中的索引 判断是否有效 0 去内存读 ...
- 保护模式篇——TLB与CPU缓存
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
随机推荐
- mysql5.7 初始化启动
root@0f6852dfee81:/# mysql --versionmysql Ver 14.14 Distrib 5.7.18-16, for debian-linux-gnu (x86_64 ...
- dubbo 提供者 ip不对
1.服务器多网卡绑定,导致服务起来后程序自己选择的ip不对. 2.提供服务的机器开启了vpn. 3.dubbo配置文件中写死了host. 以下为转载:转自http://www.ithao123.cn/ ...
- 并发包下常见的同步工具类详解(CountDownLatch,CyclicBarrier,Semaphore)
目录 1. 前言 2. 闭锁CountDownLatch 2.1 CountDownLatch功能简介 2.2 使用CountDownLatch 2.3 CountDownLatch原理浅析 3.循环 ...
- Educational Codeforces Round 54
这套题不难,但是场上数据水,导致有很多叉点 A. 因为是让求删掉一个后字典序最小,那么当a[i]>a[i+1]的时候,删掉a[i]一定最优!这个题有个叉点,当扫完一遍如果没有满足条件的,就删去最 ...
- (转)Java 中关于String的空对象(null) ,空值(empty),空格
原文出处:Java 中关于String的空对象(null) ,空值(empty),空格 定义 空对象: String s = null; 空对象是指定义一个对象s,但是没有给该对象分配空间,即没有实例 ...
- Error while trying to retrieve text for error ORA-12154
问题描述:vs中调试运行没有任何错误,但是发布到IIS中访问,就会报以上错误.IIS不会调试,所以一头雾水,不止错误在哪里. 分析:看到网上有人分析了Web.config模拟验证的问题恍然大悟: 原文 ...
- 安装bcmath 扩展
1.在php源码包中,默认就包含bcmath扩展的安装文件,只需手动安装一下即可 cd /root/build2/php-/ext/bcmath // 进入PHP的源码包目录中的bcmatch扩展目录 ...
- 如何使用vsphere client 克隆虚拟机
vSphere 是VMware公司推出一套服务器虚拟化解决方案. 工具/原料 vSphere 测试系统 方法/步骤 1.进入vSphere client,关闭需要克隆的虚拟机win7 2.选中ESXi ...
- scrollView不能进行滚动
原因:scrollView里只能包含一个layout,多个时,是不能进行滚动的.
- 如何用word文档在博客里发表文章
目前大部分的博客作者在用Word写博客这件事情上都会遇到以下3个痛点: 1.所有博客平台关闭了文档发布接口,用户无法使用Word,Windows Live Writer等工具来发布博客.使用Word写 ...