构建高性能数据库缓存之redis主从复制
一、什么是redis主从复制?
主从复制,当用户往Master端写入数据时,通过Redis Sync机制将数据文件发送至Slave,Slave也会执行相同的操作确保数据一致;且实现Redis的主从复制非常简单。
二、redis主从复制特点
1、同一个Master可以拥有多个Slaves。
2、Master下的Slave还可以接受同一架构中其它slave的链接与同步请求,实现数据的级联复制,即Master->Slave->Slave模式;
3、Master以非阻塞的方式同步数据至slave,这将意味着Master会继续处理一个或多个slave的读写请求;
4、Slave端同步数据也可以修改为非阻塞是的方式,当slave在执行新的同步时,它仍可以用旧的数据信息来提供查询;否则,当slave与master失去联系时,slave会返回一个错误给客户端;
5、主从复制具有可扩展性,即多个slave专门提供只读查询与数据的冗余,Master端专门提供写操作;
6、通过配置禁用Master数据持久化机制,将其数据持久化操作交给Slaves完成,避免在Master中要有独立的进程来完成此操作。
三、redis主从复制原理
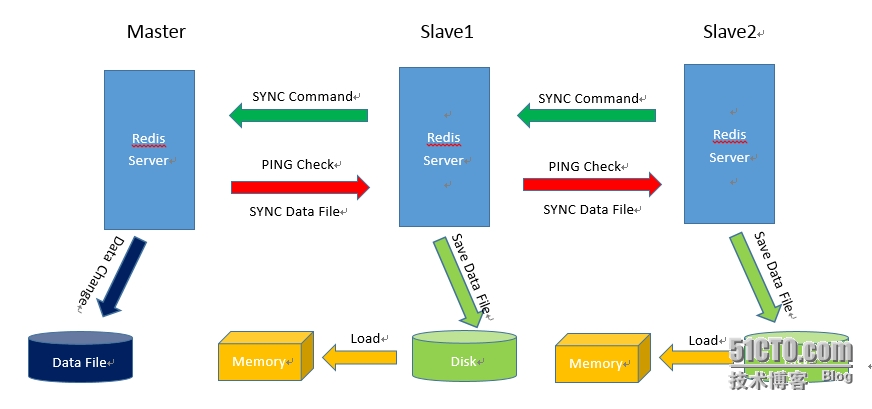 当启动一个Slave进程后,它会向Master发送一个SYNC Command,请求同步连接。无论是第一次连接还是重新连接,Master都会启动一个后台进程,将数据快照保存到数据文件中,同时Master会记录所有修改数据的命令并缓存在数据文件中。后台进程完成缓存操作后,Master就发送数据文件给Slave,Slave端将数据文件保存到硬盘上,然后将其在加载到内存中,接着Master就会所有修改数据的操作,将其发送给Slave端。若Slave出现故障导致宕机,恢复正常后会自动重新连接,Master收到Slave的连接后,将其完整的数据文件发送给Slave,如果Mater同时收到多个Slave发来的同步请求,Master只会在后台启动一个进程保存数据文件,然后将其发送给所有的Slave,确保Slave正常。
当启动一个Slave进程后,它会向Master发送一个SYNC Command,请求同步连接。无论是第一次连接还是重新连接,Master都会启动一个后台进程,将数据快照保存到数据文件中,同时Master会记录所有修改数据的命令并缓存在数据文件中。后台进程完成缓存操作后,Master就发送数据文件给Slave,Slave端将数据文件保存到硬盘上,然后将其在加载到内存中,接着Master就会所有修改数据的操作,将其发送给Slave端。若Slave出现故障导致宕机,恢复正常后会自动重新连接,Master收到Slave的连接后,将其完整的数据文件发送给Slave,如果Mater同时收到多个Slave发来的同步请求,Master只会在后台启动一个进程保存数据文件,然后将其发送给所有的Slave,确保Slave正常。
四、服务器资源列表

五、配置过程
关于Redis的安装与配置这里便不操作,想了解的朋友请阅读:高性能数据库缓存之redis(一)http://cfwlxf.blog.51cto.com/3966339/1423106
3、1 Master端操作如下:
运行redis服务
|
1
|
[root@redis_master sh]# redis-server/etc/redis/redis.conf |
查询redis运行日志
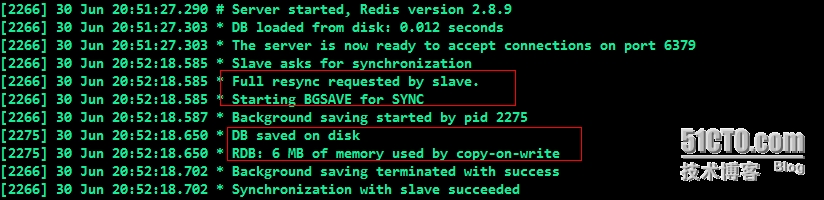
##通过阅读日志文件输出的一些信息,可以看出Master与Slave建立连接时,需要执行的会话机制:加载数据文件至硬盘,用时0.012秒,可想而知速度是多么的快,当然得依据数据的大小去评测;服务连接至6379端口,收到Slave同步连接请求,开启“BGSAVE”同步等;
清除Master端数据库中所有Key
|
1
2
3
4
5
|
[root@redis_master sh]# redis-cli127.0.0.1:6379> FLUSHALLOK127.0.0.1:6379> keys *(empty list or set) |
3、2 Slave端操作如下:
[root@redis_slave ~]# vim/etc/redis/redis.conf
#添加Master端的IP与端口
|
1
2
|
# slaveof <masterip><masterport>slaveof 192.168.8.8 6379 |
运行redis
|
1
|
[root@redis_slave ~]# redis-server/etc/redis/redis.conf |
查询Slave运行日志
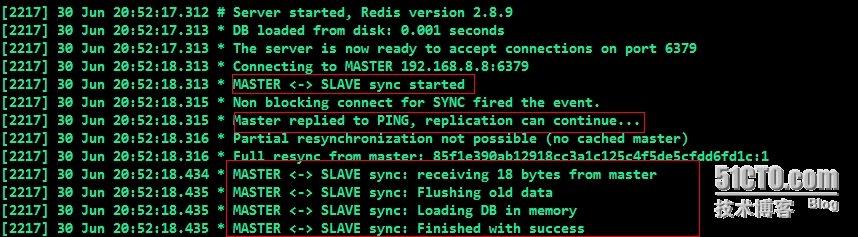
##分析redis日志,可以看出Slave与Master建立连接,数据同步的过程;如:发送SYNC命令,与Master端192.168.8.8:6379建立连接,然后Slave sync started;随后Master发送PING命令检查Slave的存活状态,复制被继续….
查询数据库中的所有key
|
1
2
3
|
[root@redis_slave ~]# redis-cli 127.0.0.1:6379> keys *(empty list or set) |
3、3 slave2端操作如下:
[root@redis_slave2 ~]# vim/etc/redis/redis.conf
#添加Slave端的IP与端口,实现级联复制;
|
1
2
|
# slaveof <masterip><masterport>slaveof 192.168.8.10 6379 |
#运行redis服务
|
1
|
[root@redis_slave2 ~]# redis-server/etc/redis/redis.conf |
查询redis运行日志
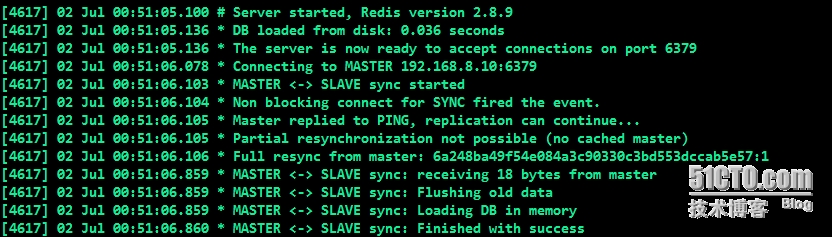
##结果与Slave1类似,只不过Slave2与Slave1(192.168.8.10:6379)建立连接,同步数据;MySQL的级联复制便是这样,Master->Slave1->Slave2;
#查询数据库的所有key
[root@redis_slave2 ~]# redis-cli
127.0.0.1:6379> keys *
(empty list or set)
3、4 master端操作如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@redis_master sh]# redis-cli127.0.0.1:6379> MSET ID 1005 NAMEMariaDB City BeiJingOK127.0.0.1:6379> MGET ID NAME City1) "1005"2) "MariaDB"3) "BeiJing"127.0.0.1:6379> keys *1) "NAME"2) "ID"3) "City" |
3、5 客户端验证同步结果
slave1端验证
|
1
2
3
4
5
6
7
8
9
10
|
[root@redis_slave ~]# redis-cli127.0.0.1:6379> auth !@#aedf127.0.0.1:6379> keys *1) "City"2) "NAME"3) "ID"127.0.0.1:6379> MGET ID NAME City1) "1005"2) "MariaDB"3) "BeiJing" |
slave2端验证
|
1
2
3
4
5
6
7
8
9
|
[root@redis_slave2 ~]# redis-cli127.0.0.1:6379> keys *1) "ID"2) "NAME"3) "City"127.0.0.1:6379> MGET ID NAME City1) "1005"2) "MariaDB"3) "BeiJing" |
四、Master write,Slave read机制
Redis的主从复制,通过程序实现数据的读写分离,让Master负责处理写请求,Slave负责处理读请求;通过扩展Slave处理更多的并发请求,减轻Master端的负载,如下图:
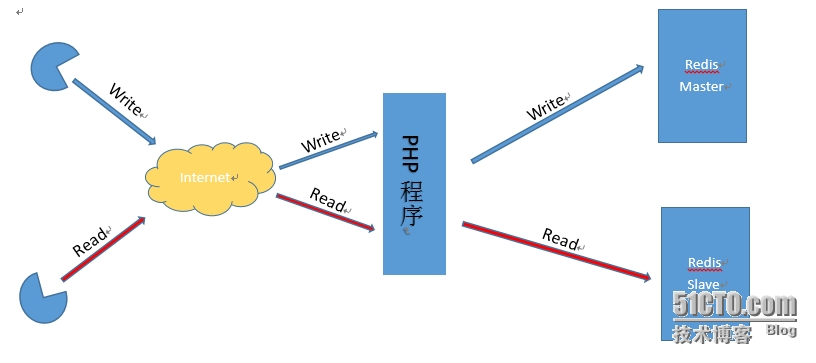
此图画得比较简易,展示了实现Redis读写分离的过程,通过判断用户读写请求,将write请求发送给Redis Master处理,Read请求发送给Redis Slave处理,文章中的不足之处,欢迎大家指点。
本文出自 “一步一脚印,从运维到DBA” 博客,请务必保留此出处http://cfwlxf.blog.51cto.com/3966339/1433637
构建高性能数据库缓存之redis主从复制的更多相关文章
- 构建高性能数据库缓存之redis(二)
一.概述 在构建高性能数据库缓存之redis(一)这篇文档中,阐述了Redis数据库(key/value)的特点.功能以及简单的配置过程,相信阅读过这篇文档的朋友,对Redis数据库会有一点的了解,此 ...
- 构建高性能数据库缓存之Redis(一)
一.Redis概述 1.1 什么是redis Redis是一个开源的用ANSI C编写.支持网络.基于内存.亦可持久化的日志型.Key-Value数据库,根据DB-Engines.com站点月度排行的 ...
- 数据库缓存mybatis,redis
简介 处理并发问题的重点不在于你的设计是怎样的,而在于你要评估你的并发,并在并发范围内处理.你预估你的并发是多少,然后测试r+m是否支持.缓存的目的是为了应对普通对象数据库的读写限制,依托与nosql ...
- NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- 【转】 NoSQL初探之人人都爱Redis:(4)Redis主从复制架构初步探索
一.主从复制架构简介 通过前面几篇的介绍中,我们都是在单机上使用Redis进行相关的实践操作,从本篇起,我们将初步探索一下Redis的集群,而集群中最经典的架构便是主从复制架构.那么,我们首先来了解一 ...
- 配置Redis主从复制
[构建高性能数据库缓存之redis主从复制][http://database.51cto.com/art/201407/444555.htm] 一.什么是redis主从复制? 主从复制,当用户往Mas ...
- 利用Azure Redis Cache构建百万量级缓存读写
Redis是一个非常流行的基于内存的,低延迟,高吞吐量的key/value数据存储,被广泛用于数据库缓存,session的管理,热数据高速访问,甚至作为数据库方式提高应用程序可扩展性,吞吐量,和实施处 ...
- 高性能文件缓存key-value存储—Redis
1.高性能文件缓存key-value存储-Memcached 2.ASP.NET HttpRuntime.Cache缓存类使用总结 备注:三篇博文结合阅读,简单理解并且使用,如果想深入学习,请多参考文 ...
- Redis数据库 02事务| 持久化| 主从复制| 集群
1. Redis事务 Redis不支持事务,此事务不是关系型数据库中的事务: Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化.按顺序地执行.事务在执行的过程中,不会被其他客户端发送来的 ...
随机推荐
- RabbitMQ的应用场景以及基本原理介绍 【转】
http://blog.csdn.net/whoamiyang/article/details/54954780 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 背景 应用 ...
- Spring(二十二):Spring 事务
事务简介: 事务管理是企业级应用程序开发中必不可少的技术,用来确保数据的完整性和一致性. 事务就是一系列的动作,它们被当做一个单独的工作单元.这些动作要么全部完成,要么全部不起作用. 事务的是四个关键 ...
- ubuntu完全卸载apache2
最近刚接触ubuntu和apache,第一次配置就被apahce搞到完全崩溃,跟着网上的配置修改apache的charset和apache2.conf以后,开始出现访问http://localhost ...
- HTTP协议中源端口和目标端口的问题
[提问] How is source port for HTTP determined? Is there ever collision in NAT? I know that when a HT ...
- java实现文件的断点续传的下载
java的断点续传是基于之前java文件下载基础上的功能拓展 首先设置一个以线程ID为名的下载进度文件, 每一次下载的进度会保存在这个文件中,下一次下载的时候,会根据进度文件里面的内容来判断下载的进度 ...
- [Algorithm] Delete a node from Binary Search Tree
The solution for the problem can be divided into three cases: case 1: if the delete node is leaf nod ...
- linux 查找文件或者服务
[root@localhost ~]# whereis mysql mysql: /usr/bin/mysql /usr/lib/mysql /usr/share/mysql /usr/share/m ...
- iOS应用程序状态图
理解应用的状态对于我们开发iOS大有裨益. 当前应用所处什么状态,什么促使它在各个状态间进行过渡,你的代码又是如何 唤醒这些过渡,等等等等. 先请看下图: 1. 当应用出于非运行状态时,它处于图中的& ...
- mysql中间件研究(Atlas,cobar,TDDL)[转载]
mysql中间件研究(Atlas,cobar,TDDL) mysql-proxy是官方提供的mysql中间件产品可以实现负载平衡,读写分离,failover等,但其不支持大数据量的分库分表且性能较差. ...
- Linux使用笔记
1:Ubuntu系统获取超级权限: 在终端输入:sudo passwd,重置uinx密码.然后输入 su ,输入密码,即可进入root权限. 2:更改文件属性 Linux文件的基本权限有九个,分别是o ...