【python3】爬取新浪的栏目分类
目标地址: http://www.sina.com.cn/
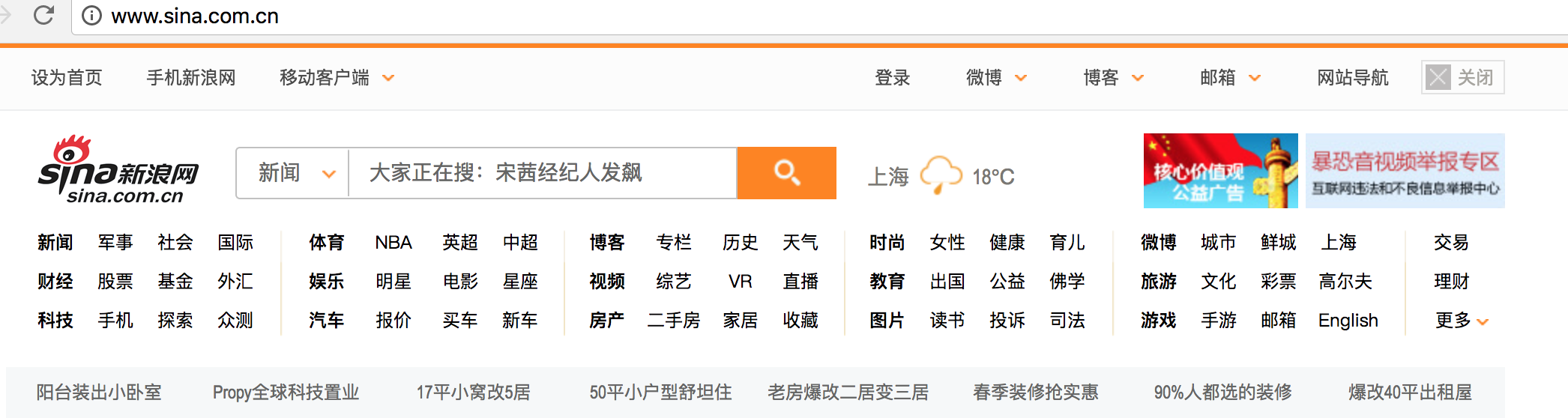
查看源代码,分析:
1 整个分类 在 div main-nav 里边包含
2 分组情况:1,4一组 、 2,3一组 、 5 一组 、6一组
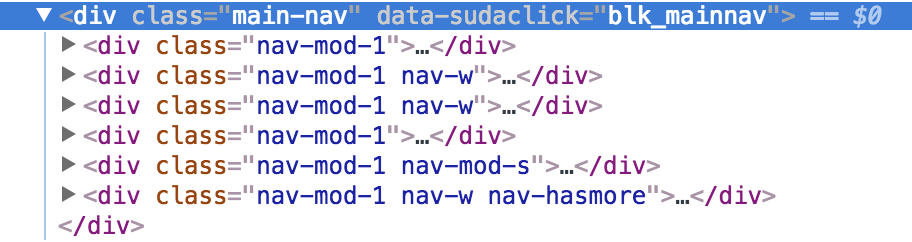
实现源码:
# coding=utf-8
import urllib.request
import ssl
from lxml import etree # 获取html内容
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
html = html.decode('utf-8')
return html # 获取内容
def get_title(arr, html, pathrole, sumtimes):
selector = etree.HTML(html)
content = selector.xpath(pathrole)
i = 0
while i <= sumtimes:
result = content[i].xpath('string(.)').strip()
arr.append(result)
i += 1
return arr # 创建ssl证书
ssl._create_default_https_context = ssl._create_unverified_context
url = "http://www.sina.com.cn/"
html = getHtml(url)
# 第一次获取
arr = []
pathrole1 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-w"]/ul/li'
retult1 = get_title(arr, html, pathrole=pathrole1, sumtimes=23) # 第二次获取
if retult1:
pathrole2 = '//div[@class="main-nav"]/div[@class="nav-mod-1"]/ul/li'
retult2 = get_title(retult1, html, pathrole=pathrole2, sumtimes=23)
else:
print("error") # 第三次获取
if retult2:
pathrole3 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-mod-s"]/ul/li'
retult3 = get_title(retult2, html, pathrole3, sumtimes=11)
else:
print("error") # 第四次获取
if retult3:
pathrole4 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-w nav-hasmore"]/ul/li'
retult4 = get_title(retult3, html, pathrole4, sumtimes=1)
else:
print("error") # 第五次获取:更多列表
if retult4:
pathrole5 = '//div[@class="main-nav"]/div[@class="nav-mod-1 nav-w nav-hasmore"]/ul/li/ul[@class="more-list"]/li'
retult5 = get_title(retult4, html, pathrole5, sumtimes=6)
print(retult5)
else:
print("error")
以上代码,还可以继续优化,比如 xpath 的模糊匹配。可以把前四组合为一个,继续学习!
【python3】爬取新浪的栏目分类的更多相关文章
- Python3:爬取新浪、网易、今日头条、UC四大网站新闻标题及内容
Python3:爬取新浪.网易.今日头条.UC四大网站新闻标题及内容 以爬取相应网站的社会新闻内容为例: 一.新浪: 新浪网的新闻比较好爬取,我是用BeautifulSoup直接解析的,它并没有使用J ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4.打开cmd,输入如下命令 pip install requests pip install BeautifulSoup4 打开我们要爬取的 ...
- python3使用requests爬取新浪热门微博
微博登录的实现代码来源:https://gist.github.com/mrluanma/3621775 相关环境 使用的python3.4,发现配置好环境后可以直接使用pip easy_instal ...
- Python 爬虫实例(7)—— 爬取 新浪军事新闻
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分 第二zh张图片,显示需要分页, 源代码: # coding:utf-8 import json import redis i ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- python爬取新浪股票数据—绘图【原创分享】
目标:不做蜡烛图,只用折线图绘图,绘出四条线之间的关系. 注:未使用接口,仅爬虫学习,不做任何违法操作. """ 新浪财经,爬取历史股票数据 ""&q ...
- xpath爬取新浪天气
参考资料: http://cuiqingcai.com/1052.html http://cuiqingcai.com/2621.html http://www.cnblogs.com/jixin/p ...
随机推荐
- e565. 关闭的时候隐藏窗口
By default, when the close button on a frame is clicked, nothing happens. This example shows how to ...
- Lua--------------------unity3D与Slua融合使用
下载与安装 下载地址 GitHub 安装过程 1.下载最新版,这里, 解压缩,将Assets目录里的所有内容复制到你的工程中,对于最终产品,可以删除slua_src,例子,文档等内容,如果是开发阶段则 ...
- 参考论坛:Mali kernel driver TX011-SW-99002-r5p1-00rel0 for firefly
最近手头有一块firefly_rk3288_reload的开发板,想实现在linux 下用openGL ES来做视频显示. 找到opengGL相关移植,参考论坛(http://bbs.t-firefl ...
- linux下重要的网络配置文件
linux下重要的网络配置文件:一; /etc/sysconfig/network 文件内容: NETWORKING=yes <= ...
- springboot+shiro+redis(集群redis版)整合教程
相关教程: 1. springboot+shiro整合教程 2. springboot+shiro+redis(单机redis版)整合教程 3.springboot+shiro+redis(单机red ...
- [Learn AF3]第五章 App Framework 3组件之Drawer——Side Menu
Drawer——Side menu 组件名称:Drawer 说明:af3中的side menu和af2中有很大变化,af3中的side menu实际上是通过插件$.afui.drawer来实现 ...
- 【调研】在总体为n的情况下,多少样本有代表性?
见这里: http://www.raosoft.com/samplesize.html
- 为Hadoop集群选择合适的硬件配置
随着Apache Hadoop的起步,云客户的增多面临的首要问题就是如何为他们新的的Hadoop集群选择合适的硬件. 尽管Hadoop被设计为运行在行业标准的硬件上,提出一个理想的集群配置不想提供硬件 ...
- daterangepicker日历插件使用参数注意问题
显示具体时间时分秒: timePicker设置为true,//有些资料写的pickerTime不太对 重点大坑:修改时间默认展示格式,把fomat写在locale中,网上很多资料说直接写在datera ...
- 文件传输协议(FTP,SFTP,SCP)(修改中)
FTP(File Transfer Protocol):是TCP/IP网络上两台计算机传送文件的协议,FTP是在TCP/IP网络和INTERNET上最早使用的协议之一,它属于网络协议组的应用层.FTP ...