推荐系统之最小二乘法ALS的Spark实现
1.ALS算法流程:
初始化数据集和Spark环境---->
切分测试机和检验集------>
训练ALS模型------------>
验证结果----------------->
检验满足结果---->直接推荐商品,否则继续训练ALS模型
2.数据集的含义
Rating是固定的ALS输入格式,要求是一个元组类型的数据,其中数值分别是如下的[Int,Int,Double],在建立数据集的时候,用户名和物品名需要采用数值代替
/**
* A more compact class to represent a rating than Tuple3[Int, Int, Double].
*/
@Since("0.8.0")
case class Rating @Since("0.8.0") (
@Since("0.8.0") user: Int,
@Since("0.8.0") product: Int,
@Since("0.8.0") rating: Double)
如下:第一列位用户编号,第二列位产品编号,第三列的评分Rating为Double类型
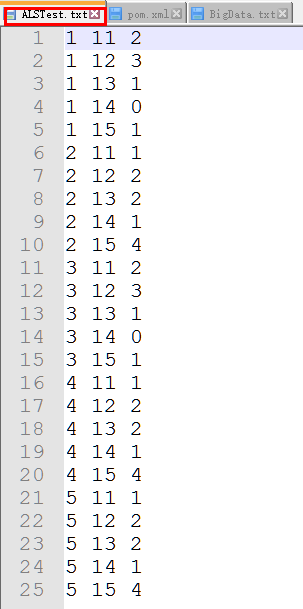
3.ALS的测试数据集源代码解读
3.1ALS类的所有字段如下
@Since("0.8.0")
class ALS private (
private var numUserBlocks: Int,
private var numProductBlocks: Int,
private var rank: Int,
private var iterations: Int,
private var lambda: Double,
private var implicitPrefs: Boolean, 使用显式反馈ALS变量或隐式反馈
private var alpha: Double, ALS隐式反馈变化率用于控制每次拟合修正的幅度
private var seed: Long = System.nanoTime()
) extends Serializable with Logging {
3.2 ALS.train方法
/**
* Train a matrix factorization model given an RDD of ratings given by users to some products,
* in the form of (userID, productID, rating) pairs. We approximate the ratings matrix as the
* product of two lower-rank matrices of a given rank (number of features). To solve for these
* features, we run a given number of iterations of ALS. This is done using a level of
* parallelism given by `blocks`.
*
* @param ratings RDD of (userID, productID, rating) pairs
* @param rank number of features to use
* @param iterations number of iterations of ALS (recommended: 10-20)
* @param lambda regularization factor (recommended: 0.01)
* @param blocks level of parallelism to split computation into 将并行度分解为等级
* @param seed random seed 随机种子
*/
@Since("0.9.1")
def train(
ratings: RDD[Rating], //RDD序列由用户ID 产品ID和评分组成
rank: Int, //模型中的隐藏因子数目
iterations: Int, //算法迭代次数
lambda: Double, //ALS正则化参数
blocks: Int, //块
seed: Long
): MatrixFactorizationModel = {
new ALS(blocks, blocks, rank, iterations, lambda, false, 1.0, seed).run(ratings)
}
3.3 基于ALS算法的协同过滤推荐
package com.bigdata.demo
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.Rating
/**
* Created by SimonsZhao on 3/30/2017.
* ALS最小二乘法
*/
object CollaborativeFilter {
def main(args: Array[String]) {
//设置环境变量
val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilter ")
//实例化环境
val sc = new SparkContext(conf)
//设置数据集
val data =sc.textFile("E:/scala/spark/testdata/ALSTest.txt")
//处理数据
val ratings=data.map(_.split(' ') match{
//数据集的转换
case Array(user,item,rate) =>
//将数据集转化为专用的Rating
Rating(user.toInt,item.toInt,rate.toDouble)
})
//设置隐藏因子
val rank=2
//设置迭代次数
val numIterations=2
//进行模型训练
val model =ALS.train(ratings,rank,numIterations,0.01)
//为用户2推荐一个商品
val rs=model.recommendProducts(2,1)
//打印结果
rs.foreach(println)
}
}
展开代码可复制
package com.bigdata.demo
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.Rating
/**
* Created by SimonsZhao on 3/30/2017.
* ALS最小二乘法
*/
object CollaborativeFilter {
def main(args: Array[String]) {
//设置环境变量
val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilter ")
//实例化环境
val sc = new SparkContext(conf)
//设置数据集
val data =sc.textFile("E:/scala/spark/testdata/ALSTest.txt")
//处理数据
val ratings=data.map(_.split(' ') match{
//数据集的转换
case Array(user,item,rate) =>
//将数据集转化为专用的Rating
Rating(user.toInt,item.toInt,rate.toDouble)
})
//设置隐藏因子
val rank=2
//设置迭代次数
val numIterations=2
//进行模型训练
val model =ALS.train(ratings,rank,numIterations,0.01)
//为用户2推荐一个商品
val rs=model.recommendProducts(2,1)
//打印结果
rs.foreach(println)
}
}
点击+复制代码
4.测试及分析
根据结果分析为第2个用户推荐了编号为15的商品,预测评分为3.99
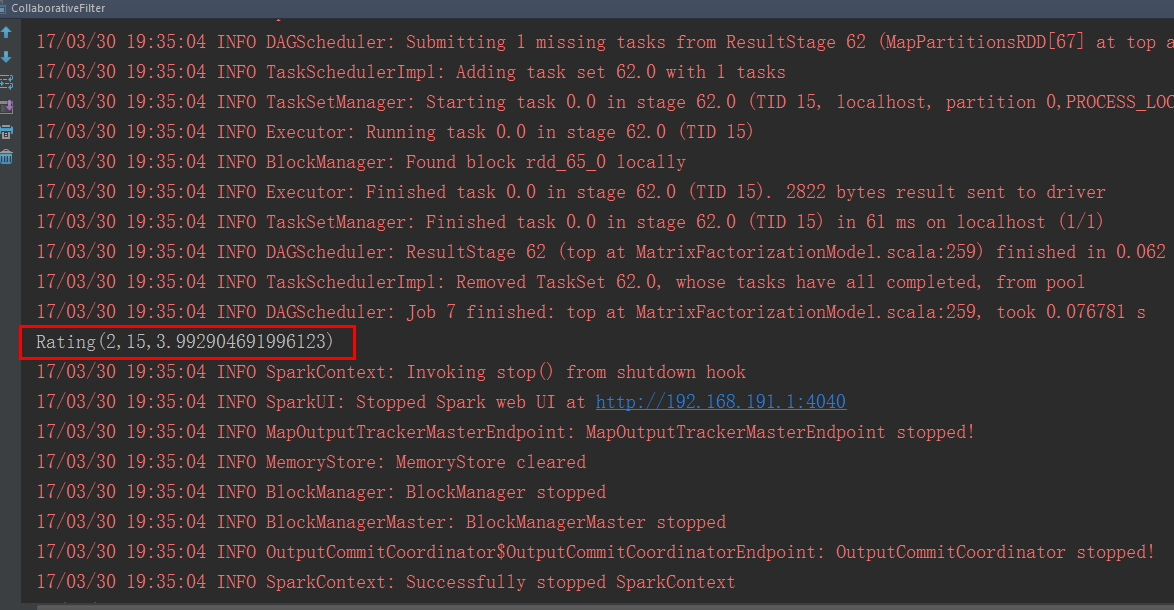
5.基于用户的推荐源代码(mllib)
注释的部分翻译:
用户向用户推荐产品
num返回多少产品。 返回的数字可能少于此值。
[[评分]]对象,每个对象包含给定的用户ID,产品ID和
评分字段中的“得分”。 每个代表一个推荐的产品,并且它们被排序
按分数,减少。 第一个返回的是预测最强的一个
推荐给用户。 分数是一个不透明的值,表示强列推荐的产品。
/**
* Recommends products to a user.
*
* @param user the user to recommend products to
* @param num how many products to return. The number returned may be less than this.
* @return [[Rating]] objects, each of which contains the given user ID, a product ID, and a
* "score" in the rating field. Each represents one recommended product, and they are sorted
* by score, decreasing. The first returned is the one predicted to be most strongly
* recommended to the user. The score is an opaque value that indicates how strongly
* recommended the product is.
*/
@Since("1.1.0")
def recommendProducts(user: Int, num: Int): Array[Rating] =
MatrixFactorizationModel.recommend(userFeatures.lookup(user).head, productFeatures, num)
.map(t => Rating(user, t._1, t._2))
6.基于物品的推荐源代码(mllib)
注释的部分翻译:
推荐用户使用产品,也就是说,这将返回最有可能的用户对产品感兴趣
每个都包含用户ID,给定的产品ID和评分字段中的“得分”。
每个代表一个推荐的用户,并且它们被排序按得分,减少。
第一个返回的是预测最强的一个推荐给产品。
分数是一个不透明的值,表示强烈推荐给用户。
/**
* Recommends users to a product. That is, this returns users who are most likely to be
* interested in a product.
*
* @param product the product to recommend users to 给用户推荐的产品
* @param num how many users to return. The number returned may be less than this. 返回个用户的个数
* @return [[Rating]] objects, each of which contains a user ID, the given product ID, and a
* "score" in the rating field. Each represents one recommended user, and they are sorted
* by score, decreasing. The first returned is the one predicted to be most strongly
* recommended to the product. The score is an opaque value that indicates how strongly
* recommended the user is.
*/
@Since("1.1.0")
def recommendUsers(product: Int, num: Int): Array[Rating] =
MatrixFactorizationModel.recommend(productFeatures.lookup(product).head, userFeatures, num)
.map(t => Rating(t._1, product, t._2))
END~
推荐系统之最小二乘法ALS的Spark实现的更多相关文章
- SparkMLlib—协同过滤之交替最小二乘法ALS原理与实践
SparkMLlib-协同过滤之交替最小二乘法ALS原理与实践 一.Spark MLlib算法实现 1.1 显示反馈 1.1.1 基于RDD 1.1.2 基于DataFrame 1.2 隐式反馈 二. ...
- 转载:Databricks孟祥瑞:ALS 在 Spark MLlib 中的实现
Databricks孟祥瑞:ALS 在 Spark MLlib 中的实现 发表于2015-05-07 21:58| 10255次阅读| 来源<程序员>电子刊| 9 条评论| 作者孟祥瑞 大 ...
- 推荐系统那点事 —— 基于Spark MLlib的特征选择
在机器学习中,一般都会按照下面几个步骤:特征提取.数据预处理.特征选择.模型训练.检验优化.那么特征的选择就很关键了,一般模型最后效果的好坏往往都是跟特征的选择有关系的,因为模型本身的参数并没有太多优 ...
- ALS部署Spark集群入坑记
[Stage 236:> (0 + 0) / 400]17/12/04 09:45:55 ERROR yarn.ApplicationMaster: User class threw excep ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- 基于Spark机器学习和实时流计算的智能推荐系统
概要: 随着电子商务的高速发展和普及应用,个性化推荐的推荐系统已成为一个重要研究领域. 个性化推荐算法是推荐系统中最核心的技术,在很大程度上决定了电子商务推荐系统性能的优劣,决定着是否能够推荐用户真正 ...
- 为什么spark中只有ALS
WRMF is like the classic rock of implicit matrix factorization. It may not be the trendiest, but it ...
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
随机推荐
- VS2010安装包制作全过程图解
项目的第一个版本出来了,要做个安装包,很久没做过已经有些淡忘了,网上差了差资料,写了一个,总结下,可能还不是很完善,仅作参考. 1.首先在打开 VS2010 >新建>项目 2.创建一 ...
- Xcode工程添加第三方文件的详细分析 Create folder references for any added folders(转)
在开发iOS项目的时候需要导入第三方的库文件,但是通过Xcode导入第三方源文件的时候会提示一些信息,不知所以然. 现在看到的文档都是针对Xcode3的,针对Xcode4的说明很少,现在分享出来. 官 ...
- Cookie 和 Session机制具体解释
原文地址:http://blog.csdn.net/fangaoxin/article/details/6952954 会话(Session)跟踪是Web程序中经常使用的技术,用来跟踪用户的整 ...
- 我的notepad++
我觉得,做开发的一定要有一个简单,但功能强大的文本编辑器.我比较喜欢notepad++,而且一直使用.准备通过这篇文章分享一下我的notepad++配置. 希望广大notepad++用户,如果有好的配 ...
- vuejs中使用echart图表
首先安装echart npm i echarts -S 加下来以使用这个图表为例 在vue组件中像这样使用: <template> <div :class="classNa ...
- .Net使用DES加密,.Net和java分别解密,并正则匹配替换加密密码为明文
在VS中用WindowsApplication做一个exe程序,用来给数据库密码加密,加密代码如下 private void generateBtn_Click(object sender, Even ...
- linux-满足多字符条件统计行数
测试数据: 2017-10-24 14:14:11:1123 [ INFO] order_type=add,order_id=9150882564978710367790292017-10-24 14 ...
- 编译Android 必须安装的库
要安装的库: 正在卸载 build-essential ...正在卸载 g++-multilib ...正在卸载 g++ ...正在卸载 gcc-multilib ...正在卸载 gcc ...正在卸 ...
- Python迭代器笔记
python中的三大器有迭代器,生成器,装饰器,本文重点讲解下迭代器的概念,使用,自定义迭代器等的介绍. 1.概念: 迭代器是一个对象,一个可以记住遍历位置的对象,迭代器对象从集合的第一个元素开始访问 ...
- warning C4305:“初始化”:从“double”到“float”截断
编译VS项目时出现警告: warning C4305:“初始化”:从“double”到“float”截断(warning C4305: 'initializing' : truncation from ...