python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4。打开cmd,输入如下命令
pip install requests
pip install BeautifulSoup4打开我们要爬取的页面,这里以新浪新闻为例,地址为:http://news.sina.com.cn/china/
按F12打开开发人员工具,点击左上角的图片,然后再页面中点击你想查看的元素:
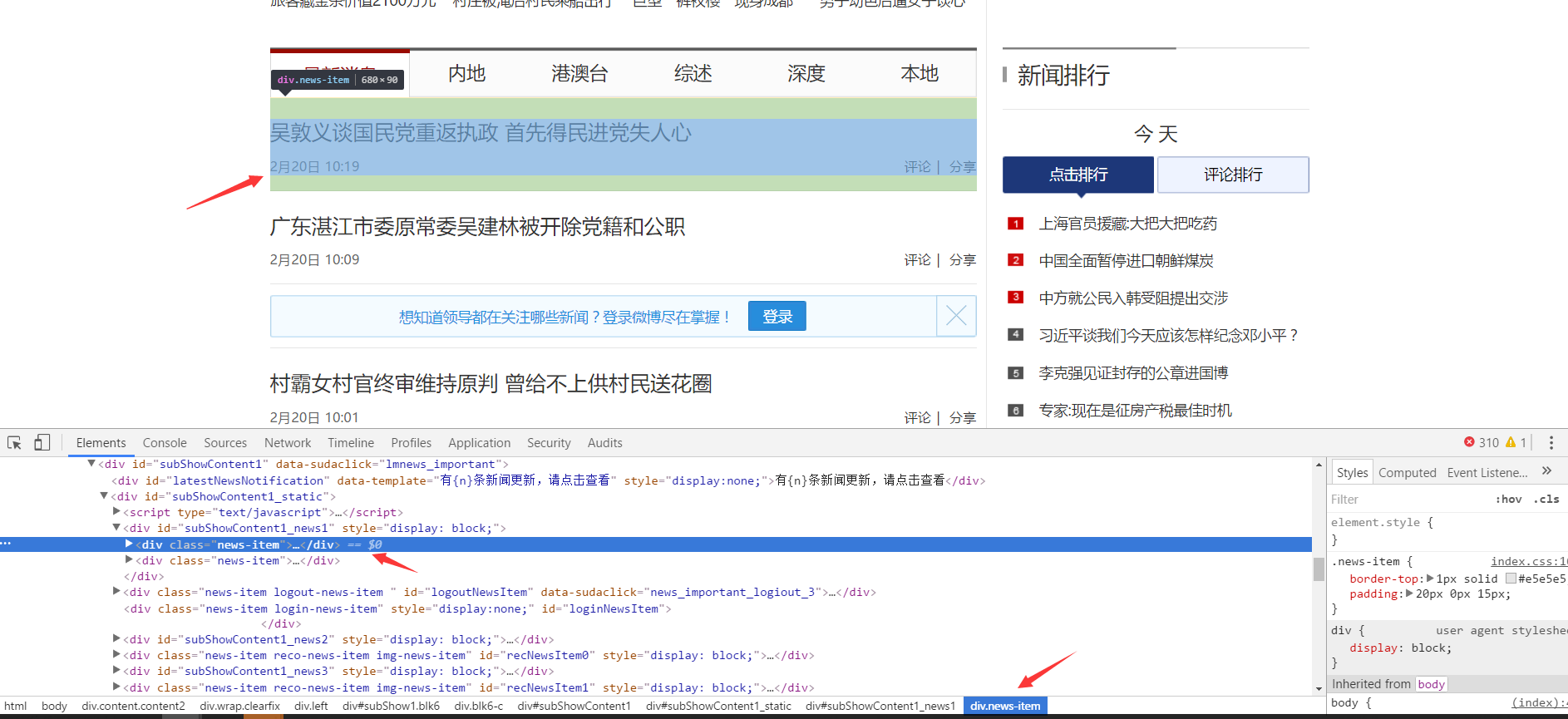
我点击了新闻标题处的元素,查看到该元素为class=news-item的元素:
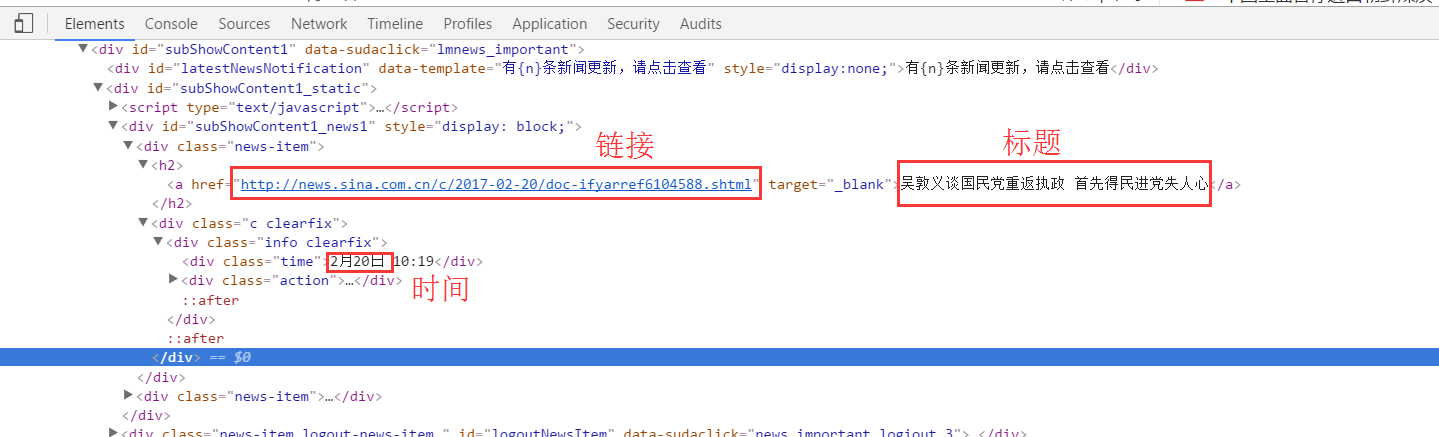
在这里,我们要获取新闻的时间,标题和链接,查看到分别在如下位置:
现在,就可以根据元素的结构编写爬虫代码了:
import requests
from bs4 import BeautifulSoup
url = 'http://news.sina.com.cn/china/'
res = requests.get(url)
# 使用UTF-8编码
res.encoding = 'UTF-8'
# 使用剖析器为html.parser
soup = BeautifulSoup(res.text, 'html.parser')
#遍历每一个class=news-item的节点
for news in soup.select('.news-item'):
h2 = news.select('h2')
#只选择长度大于0的结果
if len(h2) > 0:
#新闻时间
time = news.select('.time')[0].text
#新闻标题
title = h2[0].text
#新闻链接
href = h2[0].select('a')[0]['href']
#打印
print(time, title, href)运行程序,结果如下图所示:

python3爬虫-爬取新浪新闻首页所有新闻标题的更多相关文章
- Python3:爬取新浪、网易、今日头条、UC四大网站新闻标题及内容
Python3:爬取新浪.网易.今日头条.UC四大网站新闻标题及内容 以爬取相应网站的社会新闻内容为例: 一.新浪: 新浪网的新闻比较好爬取,我是用BeautifulSoup直接解析的,它并没有使用J ...
- 【python3】爬取新浪的栏目分类
目标地址: http://www.sina.com.cn/ 查看源代码,分析: 1 整个分类 在 div main-nav 里边包含 2 分组情况:1,4一组 . 2,3一组 . 5 一组 .6一组 ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python 爬虫实例(7)—— 爬取 新浪军事新闻
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分 第二zh张图片,显示需要分页, 源代码: # coding:utf-8 import json import redis i ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- python3使用requests爬取新浪热门微博
微博登录的实现代码来源:https://gist.github.com/mrluanma/3621775 相关环境 使用的python3.4,发现配置好环境后可以直接使用pip easy_instal ...
- python3 爬虫---爬取糗事百科
这次爬取的网站是糗事百科,网址是:http://www.qiushibaike.com/hot/page/1 分析网址,参数''指的是页数,第二页就是'/page/2',以此类推... 一.分析网页 ...
随机推荐
- 高并发应对:淘宝CDN缓存服务器部署探秘
转自:http://server.chinabyte.com/6/12663506.shtml “好,时间到,开抢!”坐在电脑前早已等待多时的宋兰(化名)一看时间已到2011年11月11日零时,便迫不 ...
- html中属于布尔类型的属性
1.noshade,用来表示有无阴影,多用于在<hr />标签当中 2.ckecked,用来表示是否默认选中,多用于单选按钮<input type="radio" ...
- Matlab 三维绘图与统计绘图
一. 三维绘图 p = : pi/: *pi; x = cos(p); y = sin(p); z = p; plot3(x,y,z) x = -:.:; %有-2为起点,2为递增步长,2为终止点 y ...
- 对Android 开发者有益的 40 条优化建议(转)
下面是开始Android编程的好方法: 找一些与你想做事情类似的代码 调整它,尝试让它做你像做的事情 经历问题 使用StackOverflow解决问题 对每个你像添加的特征重复上述过程.这种方法能够激 ...
- jQuery().end()的内部实现及源码分析
jQuery().end()的作用是返回当前jQuery对象的上一个状态. 1.end()源码: // 所有通过pushStack方法获得的jQuery对象都可以通过end方法返回之前的状态 // ...
- AD采样模块采集带模拟量真空表值的实验
实验采用带模拟量,分辨率为1-5V,量程为0--101kpa的真空表 数据采集模块采用DAM-8021, 16位模块 算法描述如下: 真空表读数范围: 0到-101kpa 模拟量输出: 1-5V 一 ...
- 精品绿色便携软件 & 录制操作工具
https://www.vtaskstudio.com/index.php 录制宏工具 https://soft.anruan.com/29821/ TinyTask V1.5 电脑版 https ...
- 题目1440:Goldbach's Conjecture(哥达巴赫猜想)
题目链接:http://ac.jobdu.com/problem.php?pid=1440 详解链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- mysql select缓存使用详解
mysql Query Cache 默认为打开.从某种程度可以提高查询的效果,但是未必是最优的解决方案,如果有的大量的修改和查询时,由于修改造成的cache失效,会给服务器造成很大的开销,可以通过qu ...
- POJ 2386 Lake Counting(搜索联通块)
Lake Counting Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 48370 Accepted: 23775 Descr ...