大数据开发实战:Hive优化实战1-数据倾斜及join无关的优化
Hive SQL的各种优化方法基本 都和数据倾斜密切相关。
Hive的优化分为join相关的优化和join无关的优化,从项目的实际来说,join相关的优化占了Hive优化的大部分内容,而join相关的优化又分为mapjoin可以解决的join优化和mapjoin无法解决的join优化。
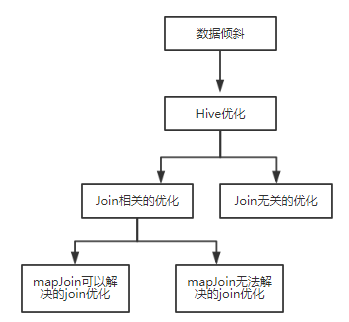
1、数据倾斜
倾斜来自于统计学里的偏态分布。所谓偏态分布,即统计数据峰值与平均值不相等的频率分布,根据峰值小于或大于平均值可分为正偏函数和负偏函数,其偏离的程度可用偏态系数刻画。
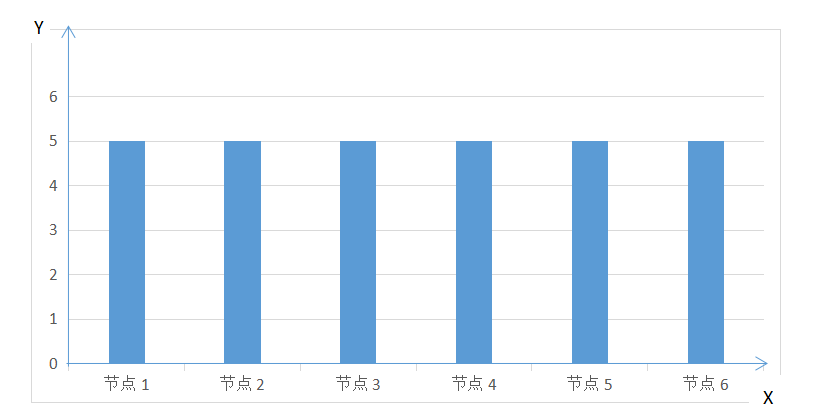
对应分布式数据处理来说,希望数据平均分布到每个处理节点。如果以每个处理节点为X轴,每个节点处理的数据为Y轴,我希望的柱状图如下:
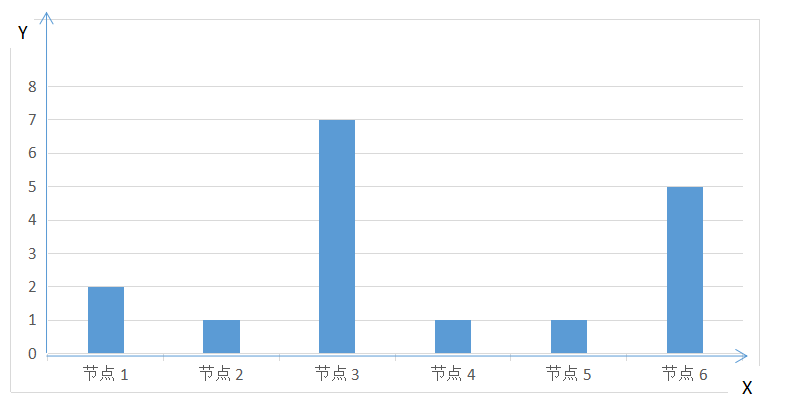
但是实际上由于业务数据本身的问题或者分布算法的问题,每个节点分配到的数据量很可能是下面的样式:
更极端情况出现下面的样式:
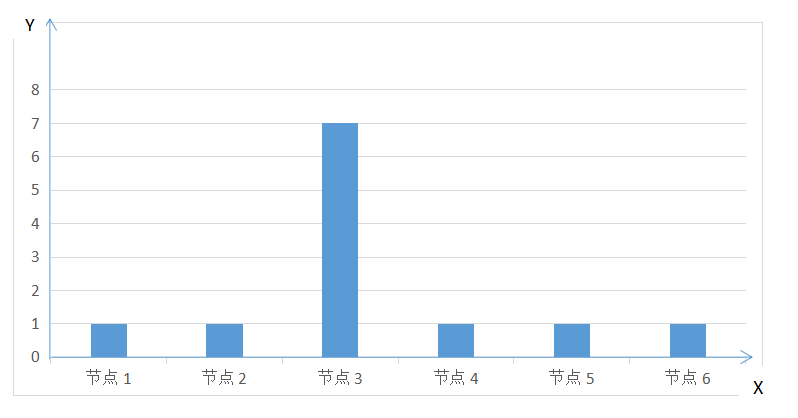
也就是说,只有待分到最多数据的节点处理完数据,整个数据处理任务才算完成,此时分布式的意义大大折扣了。实际上,即使每个节点分配到的数据量大致相同,数据仍然可能倾斜,
比如考虑统计词频的极端问题,如果某个节点分配的词都是一个词,那么显然此节点需要的耗时将很长。
Hive的优化正是采用各种措施和方法对上述场景的倾斜问题进行优化和处理。
2、Hive优化
在实际的Hive SQL开发的过程中,Hive SQL 性能的问题上实际上只有一小部分和数据倾斜有关,很多时候,Hive SQL运行慢是由于开发人员对于使用的数据了解不够以及一些不良的习惯引起的。
开发人员需要确定以下几点:
1、 需要计算的指标真的需要从数据仓库公共明细层来自行汇总吗? 是不是数据公共层团队开发公共汇总层已经可以满足自己的需求?对应大众的、KPI相关的指标等通常设计良好的数据仓库公共层
肯定已经包含了,直接使用即可。
2、真的需要扫描那么多分区吗,比如对于销售事务明细表来说,扫描一年的分区和扫描一周的分区所带来的计算、IO开销完全是两个数量级,所耗费时间肯定是不同的,所以开发人员要仔细考虑因为需求,
尽量不浪费计算和存储资源。
3、尽量不要使用select * from your_table这样的方式,用到哪些列就指定哪些列,另外WHERE条件中尽量添加过滤条件,以去掉无关的行,从而减少整个MapReduce任务宠需要处理、分发的数据量。
4、输入文件不要是大量的小文件,Hive默认的Input Split是128MB(可配置),小文件可先合并成大文件。
3、join无关的优化
Hive SQL性能问题基本上大部分都是和JOIN相关,对于和join无关的问题主要有group by相关的倾斜和count distinct相关的优化
3.1、group by引起的倾斜优化
group by引起的倾斜主要是输入数据行按照group by列分别布均匀引起的,比如,假设按照供应商对销售明细事实表来统计订单数,那么部分大供应商的订单量显然非常大,而多数供应商的订单量就一般,
由于group by 的时候是按照供应商的ID分发到每个Reduce Task,那么此时分配到大供应商的Reduce task就分配了更多的订单,从而导致数据倾斜。
对应group by引起的数据倾斜,优化措施非常简单,只需要设置下面参数即可:
set hive.map.aggr = true
set hive.groupby.skewindata = true
此时,Hive在数据倾斜的时候回进行负载均衡。
3.2、count distinct优化
在Hive开发过程中,应该小心使用count distinct,因为很容易引起性能问题,比如下面的SQL:
select count(distinct user) from some_table;
由于必须去重,因此Hive将会把Map阶段的输出全部分布到一个Reduce Task上,此时很容易引起性能问题,对于这种情况,可以通过先group by再count的方式优化,优化后的SQL如下:
select count(*)
from (select user from some_table group by user) temp;
其原理为:利用group by去重,再统计group by 的行数目。
参考资料:《离线和实时大数据开发实战》
大数据开发实战:Hive优化实战1-数据倾斜及join无关的优化的更多相关文章
- hadoop生态系统学习之路(八)hbase与hive的数据同步以及hive与impala的数据同步
在之前的博文中提到,hive的表数据是能够同步到impala中去的. 一般impala是提供实时查询操作的,像比較耗时的入库操作我们能够使用hive.然后再将数据同步到impala中.另外,我们也能够 ...
- 大数据开发主战场hive (企业hive应用)
hive在大数据套件中占很的地位,分享下个人经验. 1.在hive日常开发中,我们首先面对的就是hive的表和库,因此我要先了解库,表的命名规范和原则 如 dwd_whct_xmxx_m 第1部分为表 ...
- 【Hive】Hive笔记:Hive调优总结——数据倾斜,join表连接优化
数据倾斜即为数据在节点上分布不均,是常见的优化过程中常见的需要解决的问题.常见的Hive调优的方法:列剪裁.Map Join操作. Group By操作.合并小文件. 一.表现 1.任务进度长度为99 ...
- Hive使用Calcite CBO优化流程及SQL优化实战
目录 Hive SQL执行流程 Hive debug简单介绍 Hive SQL执行流程 Hive 使用Calcite优化 Hive Calcite优化流程 Hive Calcite使用细则 Hive向 ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 云小课|DGC数据开发之基础入门篇
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:欢迎来到DGC数据 ...
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- 大数据开发实战:离线大数据处理的主要技术--Hive,概念,SQL,Hive数据库
1.Hive出现背景 Hive是Facebook开发并贡献给Hadoop开源社区的.它是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员使用他们最为熟悉的SQL语言就可以进行海量数据的处 ...
随机推荐
- BZOJ2160: 拉拉队排练
Description 艾利斯顿商学院篮球队要参加一年一度的市篮球比赛了.拉拉队是篮球比赛的一个看点,好的拉拉队往往能帮助球队增加士气,赢得最终的比赛.所以作为拉拉队队长的楚雨荨同学知道,帮助篮球队训 ...
- 重写对象ToString方法
重写对象ToString方法,引入Newtonsoft.Json public override string ToString() { JsonSerializerSettings settings ...
- input文字颜色、光标颜色
<input type="text" placeholder="输入框"> input{ color: red;/*输入文字.光标颜色*/ -web ...
- 群晖NAS简介(转)
Synology 群晖科技(Synology )创立于 2000 年,自始便专注于打造高效能.可靠.功能丰富且绿色环保的 NAS 服务器,是全球少数几家以单纯的提供网络存储解决方案获得世界认同的华人企 ...
- 新浪微博基于MySQL的分布式数据库实践
提起微博,相信大家都是很了解的.但是有谁知道微博的数据库架构是怎样的呢?在今天举行的2011数据库技术大会上,新浪首席DBA杨海潮为我们详细解读了新浪微博的数据库架构——基于MySQL的分布式数据库实 ...
- Linux虚拟主机管理系统---wdcp
关于WDCP这款虚拟主机管理系统,是疯子使用的第二款Linux虚拟主机管理系统,使用是挺简单的,以前好像是因为编码问题而放弃这款面板. WDCP功能比较完善,基本上需要的功能都能满足,例如:在线下载. ...
- [Asp.net mvc]国际化
摘要 在实际项目中,经常遇到,开发的项目要提供给不同的国家使用,如果根据国家来开发不同的站点,肯定是非常耗时又耗成本的.asp.net中,提供了一种比较方便的方式,可以使用资源文件的方式,使我们的站点 ...
- ASP.NET Web API中展示实体Link相关的方面
有时候,向服务端请求一个实体,我们希望返回如下的格式: links: [ href: http://localhost:8901/api/user/diaries/2013-08-17, ...
- Javascript原型继承原理
对于面向对象的基础语法在此我就不重复了,对面向对象不熟悉的朋友可以参看<使用面向对象的技术创建高级 Web 应用程序>一文. prototype与[[prototype]] 在有面象对象基 ...
- ios7下UISearchBar UITextField 光标不出现的问题
app支持ios7,在UINavBar 里面加入搜索框,结果光标一直出现不了.在overstackflow网站搜索了一下,竟然有人遇到相同的问题.... 解决办法如下: searchBar.tintC ...