第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址
有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息,那么这种一般都是 js 的 Ajax 动态请求生成的信息
我们以百度新闻为列:
1、分析网站
首先我们浏览器打开百度新闻,在网页中间部分找一条新闻信息

然后查看源码,看看在源码里是否有这条新闻,可以看到源文件里没有这条信息,这种情况爬虫是无法爬取到信息的
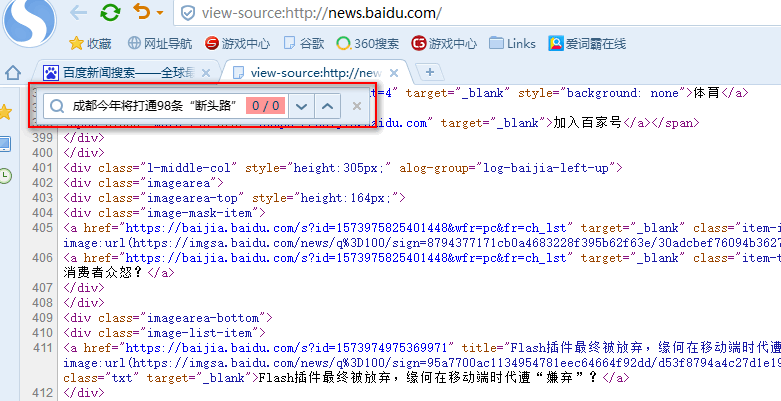
那么我们就需要抓包分析了,启动抓包软件和抓包浏览器,前后有说过软件了,就不在说了,此时我们经过抓包看到这条信息是通过Ajax动态生成的JSON数据,也就是说,当html页面加载完成后才生成的,所有我们在源文件里无法找到,当然爬虫也找不到
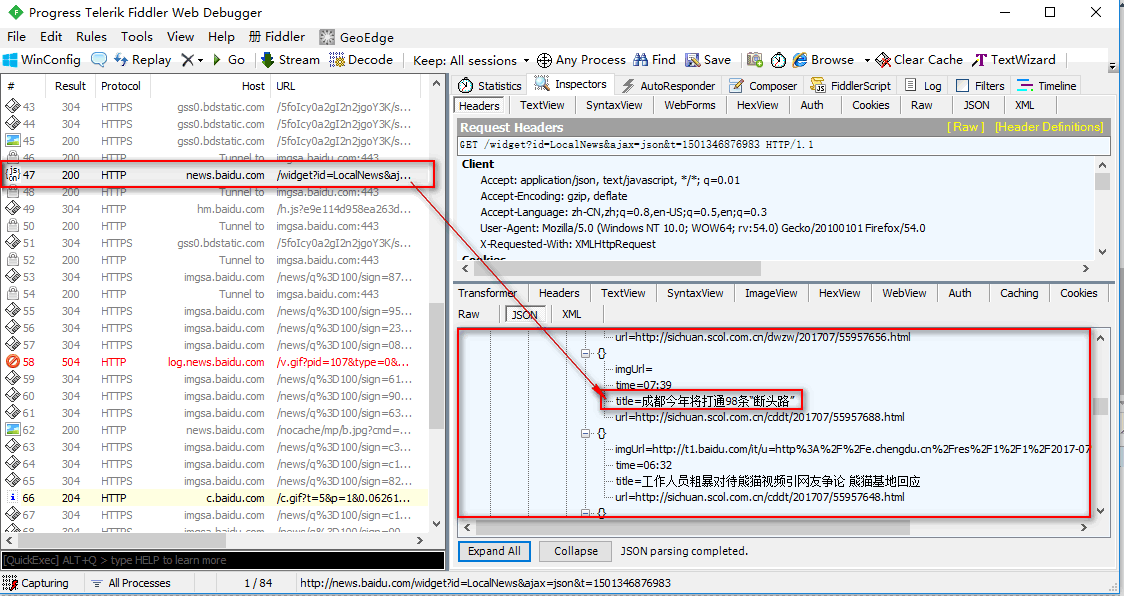
我们首先将这个JSON数据网址拿出来,到浏览器看看,我们需要的数据是不是全部在里面,此时我们看到这次请求里只有 17条信息,显然我们需要的信息不是完全在里面,还得继续看看其他js包
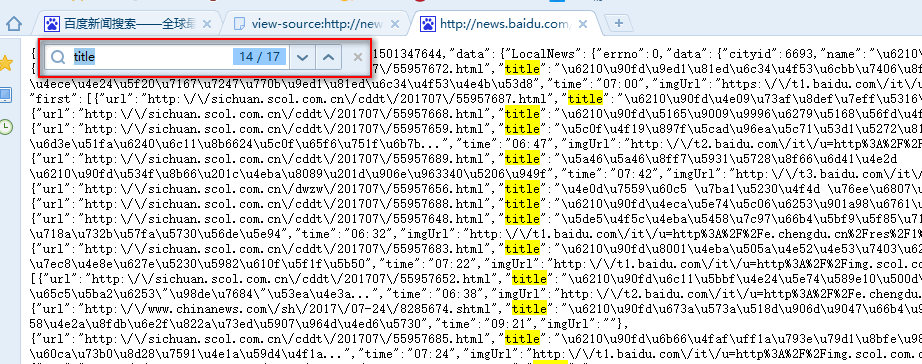
我们将抓包浏览器滚动条拉到底,以便触发所有js请求,然后在继续找js包,我们将所有js包都找完了再也没看到新闻信息的包了
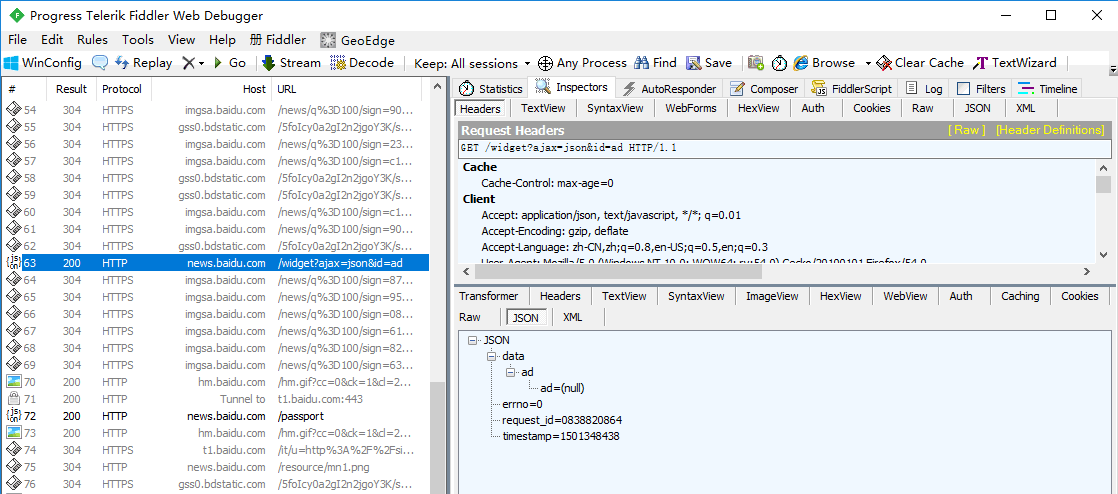
那信息就不在js包里了,我们回头在看看其他类型的请求,此时我们看到很多get请求响应的是我们需要的新闻信息,说明只有第一次那个Ajax请求返回的JSON数据,后面的Ajax请求返回的都是html类型的字符串数据,
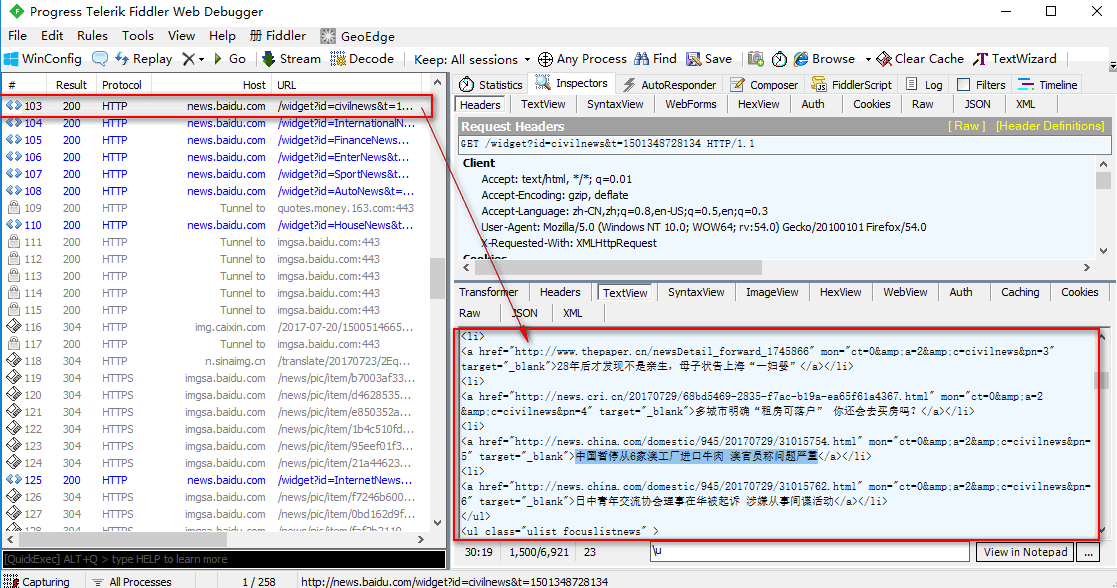
我们将Ajax请求返回的JSON数据的网址和Ajax请求返回html类型的字符串数据网址,拿来做一下比较看看是否能找到一定规律,
此时我们可以看到,JSON数据的网址和html类型的字符串数据网址是一个请求地址,
只是请求时传递的参数不一样而已,那么说明无论返回的什么类型的数据,都是在一个请求地址处理的,只是根据不同的传参返回不同类型的数据而已
http://news.baidu.com/widget?id=LocalNews&ajax=json&t=1501348444467 JSON数据的网址 http://news.baidu.com/widget?id=civilnews&t=1501348728134 html类型的字符串数据网址 http://news.baidu.com/widget?id=InternationalNews&t=1501348728196 html类型的字符串数据网址
我们可以将html类型的字符串数据网址加上JSON数据的网址参数,那是否会返回JSON数据类型?试一试,果然成功了
http://news.baidu.com/widget?id=civilnews&ajax=json 将html类型的字符串数据网址加上JSON数据的网址参数 http://news.baidu.com/widget?id=InternationalNews&ajax=json 将html类型的字符串数据网址加上JSON数据的网址参数
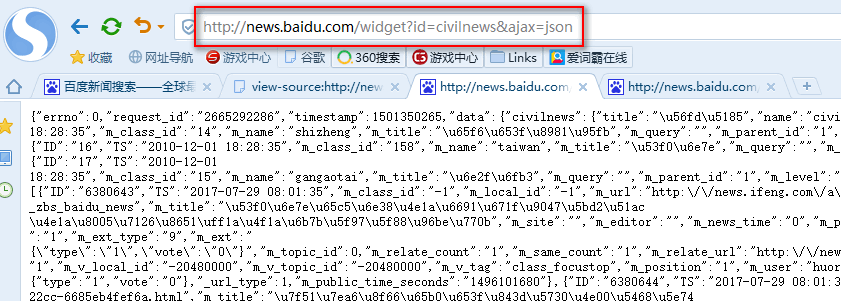
这下就好办了,找到所有的html类型的字符串数据网址,按照上面的方法将其转换成JSON数据的网址,然后循环的去访问转换后的JSON数据的网址,就可以拿到所有新闻的url地址了
crapy实现
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re
import json
from adc.items import AdcItem
from scrapy.selector import Selector class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['news.baidu.com'] #爬取域名
start_urls = ['http://news.baidu.com/widget?id=civilnews&ajax=json'] qishiurl = [ #的到所有页面id
'InternationalNews',
'FinanceNews',
'EnterNews',
'SportNews',
'AutoNews',
'HouseNews',
'InternetNews',
'InternetPlusNews',
'TechNews',
'EduNews',
'GameNews',
'DiscoveryNews',
'HealthNews',
'LadyNews',
'SocialNews',
'MilitaryNews',
'PicWall'
] urllieb = []
for i in range(0,len(qishiurl)): #构造出所有idURL
kaishi_url = 'http://news.baidu.com/widget?id=' + qishiurl[i] + '&ajax=json'
urllieb.append(kaishi_url)
# print(urllieb) def parse(self, response): #选项所有连接
for j in range(0, len(self.urllieb)):
a = '正在处理第%s个栏目:url地址是:%s' % (j, self.urllieb[j])
yield scrapy.Request(url=self.urllieb[j], callback=self.enxt) #每次循环到的url 添加爬虫 def enxt(self, response):
neir = response.body.decode("utf-8")
pat2 = '"m_url":"(.*?)"'
url = re.compile(pat2, re.S).findall(neir) #通过正则获取爬取页面 的URL
for k in range(0,len(url)):
zf_url = url[k]
url_zf = re.sub("\\\/", "/", zf_url)
pduan = url_zf.find('http://')
if pduan == 0:
print(url_zf) #输出获取到的所有url
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息的更多相关文章
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册
第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册 基于类的路由映射 from django.conf.urls import url, incl ...
- 第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表、课程章节表、课程视频表、课程资源表
第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表.课程章节表.课程视频表.课程资源表 创建名称为app_courses的 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
随机推荐
- mongoose之findOneAndUpdate方法之代码示例
categoryModel.findOneAndUpdate({name:{$in:req.body.categorys}},{$inc:{total:1}},function(err){ if (e ...
- C++类中的成员函数和构造函数为模板函数时的调用方法
所谓模板函数其实就是建立一个通用函数,这个通用函数的形参类型不具体指定,用一个虚拟类型来代表,这个通用函数就被称为函数模板. 例: #include <iostream> using na ...
- [Windows Azure] Create and use a reporting service in Windows Azure SQL Reporting
Create and use a reporting service in Windows Azure SQL Reporting In this tutorial you will learn ab ...
- 利用jenkins的api来完成相关工作流程的自动化
[本文出自天外归云的博客园] 背景 1. 实际工作中涉及到安卓客户端方面的测试,外推或运营部门经常会有很多的渠道,而每个渠道都对应着一个app的下载包,这些渠道都记录在安卓项目下的一个渠道列表文件中. ...
- java中volatile关键字的理解
一.基本概念 Java 内存模型中的可见性.原子性和有序性.可见性: 可见性是一种复杂的属性,因为可见性中的错误总是会违背我们的直觉.通常,我们无法确保执行读操作的线程能适时地看到其他线程写入的值,有 ...
- 固定高度div,随内容自动变高css定义方法
*{ font-size:12px; margin:0; padding:0;}方法1:#testBox{border:1px solid #cccccc;padding:5px;width:220p ...
- jquery开发的数字相加游戏(你能玩几分)
jquery开发的数字相加游戏,我在一轮中玩了632分(如下图),你能玩几分,哈哈... 我要试一试 下面贡献下这款“数字相加游戏”的开发过程. html部分: <div class=" ...
- Namespace declaration statement has to be the very first statement or after any declare call in the script
0x00缘起 代码部署在windows上,出现了一个bug,临时用记事本打开修改了一下,于是出现了500错误 0x01排错 查看log,提示如下 "Namespace declaration ...
- 基于QT和OpenCV的人脸检測识别系统(2)
紧接着上一篇博客的讲 第二步是识别部分 人脸识别 把上一阶段检測处理得到的人脸图像与数据库中的已知 人脸进行比对,判定人脸相应的人是谁(此处以白色文本显示). 人脸预处理 如今你已经得到一张人脸,你能 ...
- 建立window SVN服务器
在windows下搭建SVN服务器: 首先从http://www.visualsvn.com/server/download/ 下载最新的VisualSVN-Server-x.x.x.msi,然后本机 ...