RNN网络【转】
本文转载自:https://zhuanlan.zhihu.com/p/29212896
简单的Char RNN生成文本

我来钱庙复知世依,似我心苦难归久,相须莱共游来愁报远。近王只内蓉者征衣同处,规廷去岂无知草木飘。
你可能以为上面的诗句是某个大诗人所作,事实上上面所有的内容都是循环神经网络写的,是不是感觉很神奇呢?其实这里面的原理非常简单,只需要对循环神经网络有个清楚的理解,那么就能够实现上面的效果,在读完本篇文章之后,大家都能够学会如何使用循环神经网络来创作文本。
Char RNN的原理
在之前的文章中介绍过RNN的基本结构,其非常擅长处理序列问题,那么对于文本而言,其相当于也是一个序列,因为每句话都是由单词或汉字按照顺序组成的,所以也能够使用RNN对其进行处理,但是如何使用RNN进行文本生成呢?其实原理非常简单,下面我们就介绍一下Char RNN。
训练过程
一般而言,RNN的输入和输出存在着多种关系,比如1对多,多对多等等,不同的输入输出关系对应着不同的应用,网上也有很多这方面的文章可以去看看,这里我们要讲的Char RNN在训练网络的时候是相同长度的多对多的类型,也就是输入一个序列,输出一个相同的长度的序列。
具体的网络结构就是下面这个样子
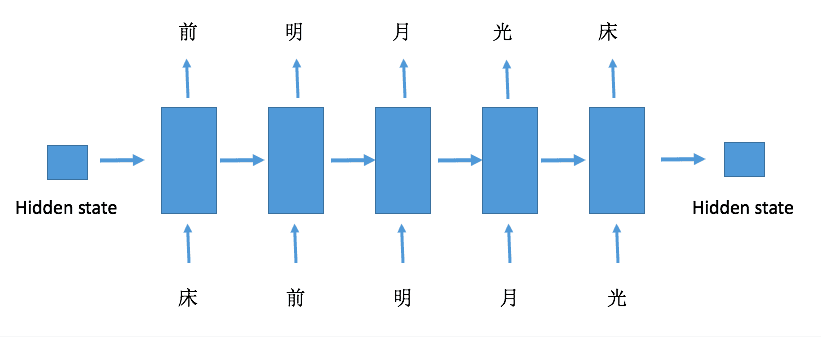
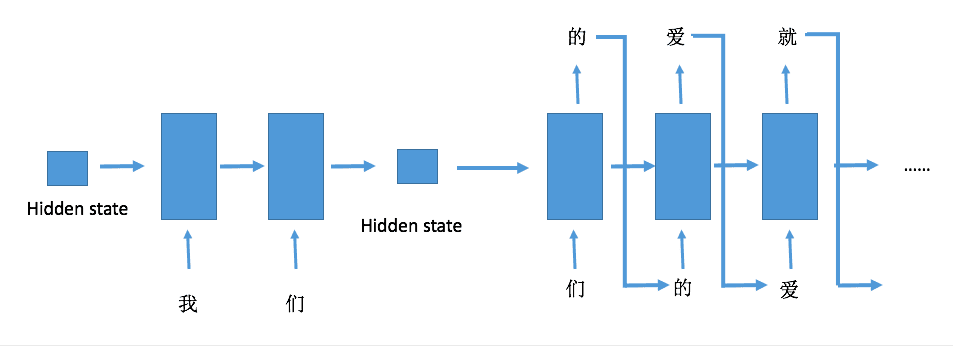
输入一句话作为输入序列,这句话中的每个字符都按照顺序进入RNN,每个字符传入RNN之后都能够得到一个输出,而这个输出就是这个字符在这句话中紧跟其后的一个字符,可以通过上面的图示清晰地看到这一点。这里要注意的是,一个序列最后一个输入对应的输出可以有多种选择,上面的图示是将这个序列的最开始的字符作为其输出,当然也可以将最后一个输入作为输出,以上面的例子说明就是'光'的输出就是'光'本身。
生成文本过程
在预测的时候需要给网络一段初始的序列进行预热,预热的过程并不需要实际的输出结果,只是为了生成具有记忆的隐藏状态,然后将隐藏状态保留,传入之后的网络,不断地更新句子,直到达到要求的输出长度,具体可以看下面的图示
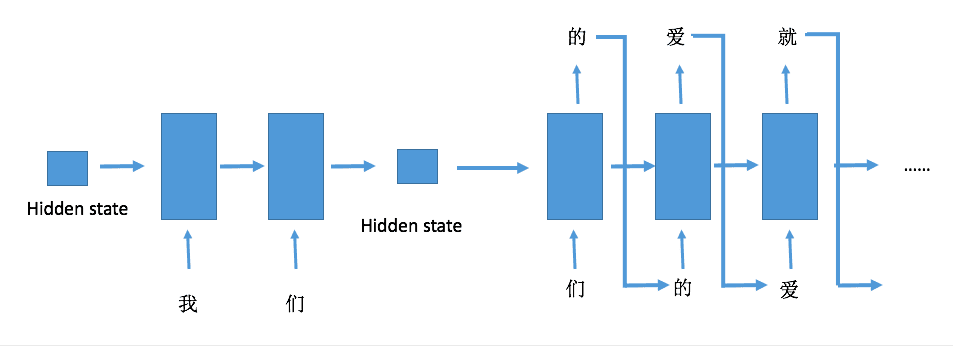
生成文本的过程就是每个字不断输入网络,然后将输出作为下一次的输出,不断循环递归,因为其会不限循环下去,所以可以设置一个长度让其停止。
实现细节
这里我们使用PyToch作为例子进行讲解,同时也提供了MXNet-Gluon的版本,因为他们的语法非常相似,所以实现两个几乎没有太大的区别,如果你不知道Gluon是什么,可以看看之前的一篇文章介绍。同时github也能找到tensorflow的实现。
数据预处理
在进行网络构建之前,需要对数据进行预处理,其实大体的思路很简单,就是建立字符的数字表示,因为字符没有办法直接输入到网络中,所以需要用不同的数字去代表不同的字符,同时可以设定一个最大字符数,如果文本中读取到的所有不重复的字符数超过了这个最大字符数,就按照字符出现的频率截取掉最后的部分。
实现的代码也非常简单
with open(text_path, 'r') as f:
text_file = f.readlines()
word_list = [v for s in text_file for v in s]
vocab = set(word_list)
# 如果单词超过最长限制,则按单词出现频率去掉最小的部分
vocab_count = {}
for word in vocab:
vocab_count[word] = 0
for word in word_list:
vocab_count[word] += 1
vocab_count_list = []
for word in vocab_count:
vocab_count_list.append((word, vocab_count[word]))
vocab_count_list.sort(key=lambda x: x[1], reverse=True)
if len(vocab_count_list) > max_vocab:
vocab_count_list = vocab_count_list[:max_vocab]
vocab = [x[0] for x in vocab_count_list]
self.vocab = vocab
self.word_to_int_table = {c: i for i, c in enumerate(self.vocab)}
self.int_to_word_table = dict(enumerate(self.vocab))
建立好一个字典用于字符和数字的相互转换之后,我们可以使用PyTorch中的Dataset类进行自定义我们的数据集合,只需要重载__getitem__和__len__这两个函数就可以了。
class TextData(data.Dataset):
def __init__(self, text_path, n_step, arr_to_idx):
self.n_step = n_step
with open(text_path, 'r') as f:
data = f.readlines()
text = [v for s in data for v in s]
num_seq = int(len(text) / n_step)
self.num_seq = num_seq
text = text[:num_seq * n_step] # 截去最后不够长的部分
arr = arr_to_idx(text)
arr = arr.reshape((num_seq, -1))
self.arr = torch.from_numpy(arr)
def __getitem__(self, index):
x = self.arr[index, :]
y = torch.zeros(x.size())
y[:-1], y[-1] = x[1:], x[0]
return x, y
def __len__(self):
return self.num_seq
网络定义
处理好数据之后,就可以进行网络的定义了,非常简单,网络只需要定义三层就可以了,第一层是word embedding,也就是词嵌入层,第二层是RNN层,第三层是线性映射,因为最后是一个分类问题,所以将结果的位数隐射到类别数目。
class CharRNN(nn.Module):
def __init__(self, num_classes, embed_dim, hidden_size, num_layers,
dropout):
super(CharRNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.word_to_vec = nn.Embedding(num_classes, embed_dim)
self.rnn = nn.GRU(embed_dim, hidden_size, num_layers, dropout)
self.proj = nn.Linear(hidden_size, num_classes)
def forward(self, x, hs=None):
batch = x.size(0)
if hs is None:
hs = Variable(
torch.zeros(self.num_layers, batch, self.hidden_size))
if torch.cuda.is_available():
hs = hs.cuda()
word_embed = self.word_to_vec(x) # batch x len x embed
word_embed = word_embed.permute(1, 0, 2) # len x batch x embed
out, h0 = self.rnn(word_embed, hs) # len x batch x hidden
le, mb, hd = out.size()
out = out.view(le * mb, hd)
out = self.proj(out)
out = out.view(le, mb, -1)
out = out.permute(1, 0, 2).contiguous() # batch x len x hidden
return out.view(-1, out.size(2)), h0
在向前传播的时候,我们可以指定传入的隐藏状态,虽然训练中可以不用特别指定,但是在生成文本的时候是需要指定的,同时里面有一些小细节,需要将数据的维度进行调换和处理,这是因为PyTorch中RNN的输入有要求。
另外在最后网络输出的时候,我们会将输出进行out.view(-1, out.size(1))这个操作,这个操作是为了将所有的序列拼起来,比如现在的输出是(batch, length),通过这个操作之后就变成了(batch x length, 1),这样做是为了方便loss的计算。
进行训练
训练过程非常简单,只需要把序列扔到网络中即可,这里有两个小细节,第一个是将label y进行y.view(-1),这对应于前面网络输出结构的操作,第二个细节是通nn.utils.clip_grad_norm()对网络进行梯度裁剪,因为RNN中容易出现梯度爆炸的问题。
for batch in dataloader:
x, y = batch
y = y.type(torch.LongTensor)
mb_size = x.size(0)
if use_gpu:
x = x.cuda()
y = y.cuda()
x, y = Variable(x), Variable(y)
out, _ = model(x)
batch_loss = criterion(out, y.view(-1))
# 反向传播
optimizer.zero_grad()
batch_loss.backward()
nn.utils.clip_grad_norm(model.parameters(), 5)
optimizer.step()
生成文本
在生成文本中,为了增加随机性,我们会将预测概率最高的前五个依概率进行选择,并不是每次都选择概率最大的,相关的代码如下。
def pick_top_n(preds, top_n=5):
top_pred_prob, top_pred_label = torch.topk(preds, top_n, 1)
top_pred_prob /= torch.sum(top_pred_prob)
top_pred_prob = top_pred_prob.squeeze(0).cpu().numpy()
top_pred_label = top_pred_label.squeeze(0).cpu().numpy()
c = np.random.choice(top_pred_label, size=1, p=top_pred_prob)
return c
在生成文本的时候,先通过一句话对网络进行预热,主要是为了得到预热后的隐藏状态,然后将这句话的最后一个词和预热之后的隐藏状态作为网络的第一个输入,得到结果,然后将结果作为下一步的输入,不断循环,直到达到最后的要求的长度。
model.load_state_dict(torch.load(checkpoint))
model.eval()
samples = [convert(c) for c in prime]
input_txt = torch.LongTensor(samples).unsqueeze(0)
if use_gpu:
input_txt = input_txt.cuda()
input_txt = Variable(input_txt)
_, init_state = model(input_txt) # 预热
result = samples
model_input = input_txt[:, -1].unsqueeze(1)
for i in range(text_len):
# out是输出的字符,大小为1 x vocab
# init_state是RNN传递的hidden state
out, init_state = model(model_input, init_state)
pred = pick_top_n(out.data)
model_input = Variable(torch.LongTensor(pred)).unsqueeze(0)
if use_gpu:
model_input = model_input.cuda()
result.append(pred[0])
总结
通过训练之后的网络,我们能够生成一些有意思的文本,比如可以将小说,歌曲,诗歌等等输入训练,然后可以生成一个相对应的文本,非常有意思,国外就有一个人使用Char RNN对《权利的游戏》进行了续写。
有趣归有趣,但是读完本篇文章,大家对Char RNN的原理有了深入的理解之后,发现这本质上其实只是一种语句逻辑的学习,比如前面的字符是”你的“,那么后面紧跟的一个字符就很大概率是一个名词,而不太可能是一个动词,这样不断的递归形成了一个又一个完整的句子,但是因为RNN长时依赖的问题,比较久之前的内容RNN其实已经遗忘,所以Char RNN并没有办法像作家一样创造出一片文章来表达一个观点,其只不过是对逻辑通顺语句的不断累加而已,所以这只是一个简单有趣的算法。
关于RNN的应用非常多,比如机器翻译,问答系统等等,都是用了seq2seq的模型,所以下一篇文章应该会将一下seq2seq的模型,并且实现一个简单的聊天机器人。
欢迎关注我的知乎专栏深度炼丹
欢迎访问我的博客
RNN网络【转】的更多相关文章
- 第二十节,使用RNN网络拟合回声信号序列
这一节使用TensorFlow中的函数搭建一个简单的RNN网络,使用一串随机的模拟数据作为原始信号,让RNN网络来拟合其对应的回声信号. 样本数据为一串随机的由0,1组成的数字,将其当成发射出去的一串 ...
- 深度学习原理与框架-递归神经网络-RNN_exmaple(代码) 1.rnn.BasicLSTMCell(构造基本网络) 2.tf.nn.dynamic_rnn(执行rnn网络) 3.tf.expand_dim(增加输入数据的维度) 4.tf.tile(在某个维度上按照倍数进行平铺迭代) 5.tf.squeeze(去除维度上为1的维度)
1. rnn.BasicLSTMCell(num_hidden) # 构造单层的lstm网络结构 参数说明:num_hidden表示隐藏层的个数 2.tf.nn.dynamic_rnn(cell, ...
- 深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.contrib.rnn.MultiRNNCell(堆叠多层LSTM) 4.mlstm_cell.zero_state(state初始化) 5.mlstm_cell(进行LSTM求解)
问题:LSTM的输出值output和state是否是一样的 1. rnn.LSTMCell(num_hidden, reuse=tf.get_variable_scope().reuse) # 构建 ...
- 使用tensorflow 构建rnn网络
使用tensorflow实现了简单的rnn网络用来学习加法运算. tensorflow 版本:1.1 import tensorflow as tf from tensorflow.contrib i ...
- 深度学习原理与框架-RNN网络框架-LSTM框架 1.控制门单元 2.遗忘门单元 3.记忆门单元 4.控制门单元更新 5.输出门单元 6.LSTM网络结构
LSTM网络是有LSTM每个单元所串接而成的, 从下面可以看出RNN与LSTM网络的差异, LSTM主要有控制门单元和输出门单元组成 控制门单元又是由遗忘门单元和记忆门单元的加和组成. 1.控制门单元 ...
- RNN 网络
原文:http://yangguang2009.github.io/2016/12/18/deeplearning/recurrent-neural-networks-for-deep-learnin ...
- 深度学习原理与框架-RNN网络架构-RNN网络 1.RNN的前向传播 2.RNN的反向传播
对于神经网络而言,每一个样本的输入与输入直接都是独立的,即预测的结果之间并没有联系 而对于RNN而言:不仅仅是有当前的输入,而且上一层的隐藏层也将进行输入,用于进行结果的预测.因此每一个输入都与之前的 ...
- 简单的RNN和BP多层网络之间的区别
先来个简单的多层网络 RNN的原理和出现的原因,解决什么场景的什么问题 关于RNN出现的原因,RNN详细的原理,已经有很多博文讲解的非常棒了. 如下: http://ai.51cto.com/art/ ...
- lecture7-序列模型及递归神经网络RNN
Hinton 第七课 .这里先说下RNN有recurrent neural network 和 recursive neural network两种,是不一样的,前者指的是一种人工神经网络,后者指的是 ...
随机推荐
- RESTful URL设计指南(转)
add by zhj: <RESTful Web Services Cookbook>这本书详细介绍了RESTFUL API的设计. 一般来说,一个好的URL,简单明了.这里有一个问题,对 ...
- Hadoop 之日志管理—应用在 YARN 中运行时的日志
背景: 在写这篇博文前,自己一直没有弄明白一个问题,“在 Map 函数和 Reduce 函数中使用 System.out.print 打印日志时,输出内容在哪里显示?”.试了好多回,在 log/* 目 ...
- Spark2.x学习笔记:Spark SQL的SQL
Spark SQL所支持的SQL语法 select [distinct] [column names]|[wildcard] from tableName [join clause tableName ...
- [py]django表单不清空实现的2种方法
参考 参考: django实现内容不清空2种方法 django form的作用 1.生成html标签 2.验证输入内容 form生成表单 zhuji/forms.py - 实例化表单 - 定制form ...
- 【Cocos2dx 3.3 Lua】导出Cocos2dx API文档
一.Doxygen导出Cocos2dx html doc 1.1 打开Doxygen软件,选择 File-->Open打开Cocos2dx docs目录下的doxyge ...
- QC质量管理七大手法
1.层别法 层别法就是将大量有关某一特定主题的观点.意见或想法按组分类,将收集到的大量的数据或资料按相互关系进行分组,加以层别.层别法一般和柏拉图.直方图等其它七大手法结合使用,也可单独使用. 2.查 ...
- Qt 布局管理器
在一个颜值当道的今天,无论买衣服,买车还是追星,颜值的高低已经变成了大家最看重的(不管男性女性都一样,千万别和我说你不是):而对于程序猿来说,开发一款软件,不再只注重逻辑和稳定性,美观和用户友好性也是 ...
- !!【通达信】求教:如何对A股的所有股票按照某个选股指标的某个参数排序? - 理想论坛 中国人气最旺的股票论坛
http://www.55188.com/thread-7152852-1-1.html .401进入指标排序,然后占右键把指标更改为MACD即可.(注意401前投资面有一个点!)
- zend studio9破解版
一.下载window http://downloads.zend.com/studio-eclipse/9.0.3/ZendStudio-9.0.3.msi 下载linux64 http://down ...
- sencha touch调试时Please close other application using ADB: Monitor, DDMS, Eclipse
1.运行——cmd—— netstat -aon|findstr "5037" 2.打开任务管理器,查看所有进程 显示进程pid(文件-查看)--查找pid=7740的结束.