Install hadoop on windows(non-virtual machine, such cygwin)
Download
Before starting make sure you have this two softwares
Extract downloaded tar file
Configuration
Step 1 – Windows path configuration
set HADOOP_HOME path in enviornment variable for windows
Right click on my computer > properties > advanced system settings > advance tab > environment variables > click on new
Set hadoop bin directory path
Find path variable in system variable > click on edit > at the end insert ‘; (semicolon)’ and paste path upto hadoop bin directory in my case it’s a
F:/Hortanwork/1gbhadoopram/Software/hadoop-2.7/hadoop-2.7.1/bin

Step 2 – Hadoop configuration
Edit hadoop-2.7.1/etc/hadoop/core-site.xml, paste the following lines and save it.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Edit hadoop-2.7.1/etc/hadoop/mapred-site.xml, paste the following lines and save it.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Edit hadoop-2.7.1/etc/hadoop/hdfs-site.xml, paste the following lines and save it, please create data folder somewhere and in my case i have created it in myHADOOP_HOME directory
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/f:/Hortanwork/1gbhadoopram/Software/hadoop-2.7/hadoop-2.7.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/f:/Hortanwork/1gbhadoopram/Software/hadoop-2.7/hadoop-2.7.1/data/datanode</value>
</property>
</configuration>
OR

Edit hadoop-2.7.1/etc/hadoop/yarn-site.xml, paste the following lines and save it.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Edit hadoop-2.7.1/etc/hadoop/hadoop-env.cmd, comment existing%JAVA_HOME% using @rem at start, give proper path and save it. (my jdk is in program files to avoid spaces i gave PROGRA~1)
Demo
Step 3 – Start everything
Very Important step!!!!
3.1) Before starting everything you need to add some [dot].dll and [dot].exe files of windows please download bin folder from my github repository –sardetushar_gitrepo_download
or download from https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1/bin
3.2) copy all the files dowloaded into the %HADOOP_HOME%\bin folder (The download file contains .dll and .exe file (winutils.exe for hadoop 2.7.1) which adapte for windows os).
3.3) Open cmd and type ‘hdfs namenode -format’ – after execution you will see below logs

3.4) Open cmd and point to sbin directory and type ‘start-all.cmd’
C:\UserDefined\BigData\hadoop-2.7.1\sbin>start-all.cmd
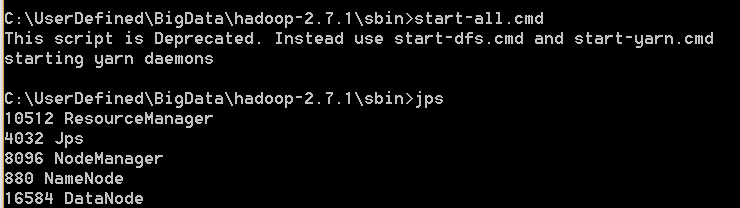
It will start following process
Namenode
Datanode
YARN resourcemanager
YARN nodemanager

JPS – to see services are running
open cmd and type – jps (for jps make sure your java path is set properly)

GUI
Step 4 – namenode GUI, resourcemanager GUI
Resourcemanager GUI address – http://localhost:8088
Namenode GUI address – http://localhost:50070
In next tutorial we will see how to run mapreduce programs in windows using eclipse and this hadoop setup
Install hadoop on windows(non-virtual machine, such cygwin)的更多相关文章
- [New Portal]Windows Azure Virtual Machine (11) 在本地使用Hyper-V制作虚拟机模板,并上传至Azure (1)
<Windows Azure Platform 系列文章目录> 本章介绍的内容是将本地Hyper-V的VHD,上传到Azure数据中心,作为自定义的虚拟机模板. 注意:因为在制作VHD的最 ...
- [New Portal]Windows Azure Virtual Machine (12) 在本地使用Hyper-V制作虚拟机模板,并上传至Azure (2)
<Windows Azure Platform 系列文章目录> 本章介绍的内容是将本地Hyper-V的VHD,上传到Azure数据中心,作为自定义的虚拟机模板. 注意:因为在制作VHD的最 ...
- [New Portal]Windows Azure Virtual Machine (13) 在本地使用Hyper-V制作虚拟机模板,并上传至Azure (3)
<Windows Azure Platform 系列文章目录> 本章介绍的内容是将本地Hyper-V的VHD,上传到Azure数据中心,作为自定义的虚拟机模板. 注意:因为在制作VHD的最 ...
- [New Portal]Windows Azure Virtual Machine (14) 在本地制作数据文件VHD并上传至Azure(1)
<Windows Azure Platform 系列文章目录> 之前的内容里,我介绍了如何将本地的Server 2012中文版 VHD上传至Windows Azure,并创建基于该Serv ...
- [New Portal]Windows Azure Virtual Machine (16) 使用Azure PowerShell创建Azure Virtual Machine
<Windows Azure Platform 系列文章目录> 注:本章内容和之前的[New Portal]Windows Azure Virtual Machine (12) 在本地制作 ...
- [New Portal]Windows Azure Virtual Machine (18) Azure Virtual Machine内部IP和外部IP
<Windows Azure Platform 系列文章目录> 在开始本章内容之前,请读者熟悉以下2篇博文: [New Portal]Windows Azure Virtual ...
- [New Portal]Windows Azure Virtual Machine (19) 关闭Azure Virtual Machine与VIP Address,Internal IP Address的关系(1)
<Windows Azure Platform 系列文章目录> 默认情况下,通过Azure Management Portal创建的Public IP和Private IP都是随机分配的. ...
- [New Portal]Windows Azure Virtual Machine (21) 将本地Hyper-V的VM上传至Windows Azure Virtual Machine
<Windows Azure Platform 系列文章目录> 本章介绍的内容是将本地Hyper-V的VHD,上传到Azure数据中心,并且保留OS中的内容. 注意:笔者没有执行Syspr ...
- [New Portal]Windows Azure Virtual Machine (22) 使用Azure PowerShell,设置Virtual Machine Endpoint
<Windows Azure Platform 系列文章目录> 我们可以通过Windows Azure Management Portal,打开Virtual Machine的Endpoi ...
- [New Portal]Windows Azure Virtual Machine (23) 使用Storage Space,提高Virtual Machine磁盘的IOPS
<Windows Azure Platform 系列文章目录> 注意:如果使用Azure Virtual Machine,虚拟机所在的存储账号建议使用Local Redundant.不建议 ...
随机推荐
- vue-cli 添加less 以及sass
1.sasscnpm i node-sass --save-dev cnpm i sass-loader --save-dev2.less npm install less --save-dev np ...
- antd中fomr中resetFields清空输入框
1.如果没有initValue的情况下,直接使用resetFields可以清空文本框的值 2.如果是有initValue的情况下,直接使用resetFields方法会直接重置为initValue的值 ...
- CTF-练习平台-Social之 密码?
一.密码? 看到题目提示是“张三”“生日”,再联系到我们设置密码时一般是名字的拼音首字母加生日,所以猜测是:zs19970315尝试后正确.
- 从dfs向动态规划过渡
据说每一个dfs,都能用动态规划思想做出来. 首先要明白dfs与动态规划的一些小要点 1)dfs重在通过使用递归来使用不同的选择,通过使用形参的改变实现不同情景的改变(形参既包括了代价,又包含了结 ...
- Descriptor&web.xml
Deployment Descriptor部署描述符: - 部署描述符是要部署到Web容器或EJB容器的Web应用程序或EJB应用程序的配置文件. - 部署描述符应包含EJB应用程序中所有企业bean ...
- MySQL Transaction--RC事务隔离级别下加锁测试
==============================================================================非索引列更新 在读提交的事务隔离级别下,在非 ...
- vulcanjs 开源工具方便快速开发react graphql meteor 应用
vulcan 开源工具方便快速开发react graphql meteor 应用 操作环境mac os 安装 meteor 安装(此安装有点慢,可以通过正确上网解决) curl https://ins ...
- Win8被禁购信息战由暗到明
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jhzyz/article/details/26629277 冯强/文 关于中国政府禁止採购微软Win ...
- JVM 详解
概念 数据类型 Java 虚拟机中,数据类型可以分为两类:基本类型和引用类型.基本类型的变量保存原始值,即:他代表的值就是数值本身:而引用类型的变量保存引用值.“引用值”代表了某个对象的引用,而不是对 ...
- QString 和char数组转换(转)
在qt开发过程中经常遇到QString类和char数组进行转换,在此记录一下: QString->char数组 1 2 3 QString str="12fff"; QByt ...