<zk在大型分布式系统中的应用>
Hadoop
- 在hadoop中,zk主要用来实现HA(High Availability)。这部分逻辑主要集中在hadoop common的HA模块中,HDFS的NameNode和Yarn的ResourceManager都是基于此HA模块来实现自己的HA功能的。同时,在YARN中又特别提供了zk来存储应用的运行状态。
YARN
- Yarn主要由ResourceManager、NodeManager、ApplicationMaster和Container四部分组成。
- 其中最核心的就是RM,它作为全局的资源管理器,负责整个系统的资源管理和分配。
RM单点问题
- RM是YARN中非常复杂的一个组件,负责集群中所有资源的统一管理和分配,同时接受各个NM的资源汇报信息,并把这些信息按照一定的策略分配给各个app。
- ResourceManager HA的解决方案就是使用 Active/Standby模式的RM HA架构。

- 可以看到,在运行期间会有多个RM存在,但只有一个处于Active状态,其他的是standby。当active节点无法正常工作时,其余处于standby的节点则会通过竞争选举产生新的节点。
主备切换
- RM使用基于zk实现的ActiveStandbyElector组件来确定RM的状态:Active或Standby。
具体做法如下:- 创建锁节点:在zk上有一个类似于/yarn-leader-election/pseudo-yarn-rm-cluster的锁节点,所有rm在启动时都会去竞争一个lock子节点/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock,该节点是临时节点。
- 注册Watcher监听:所有standby状态的rm都会向/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock节点注册一个节点变更的Watcher监听,利用临时节点的特性,能快速感知到Active状态的RM的运行状态。
- 主备切换:当active节点不可用时,其对应zk上的Lock节点也会随之被删除,其他standby状态的rm都会接收到zk server的watcher事件通知,然后重复步骤1。
- 以上,实际上就是通过临时节点 + Watcher事件通知来实现的。
- HDFS中的NameNode和RM模块都是使用ActiveStandbyElector组件来实现各自的HA的。
- RM使用基于zk实现的ActiveStandbyElector组件来确定RM的状态:Active或Standby。
Fencing(隔离)
- 在分布式环境中,经常会出现诸如单机“假死”的情况。所谓“假死”是指机器由于网络闪断或是自身负载过高(常见的有GC占用时间过长或CPU的负载过高等)而导致无法正常地对外进行及时响应。
- 在上述主备切换过程中,我们假设RM集群由rm1和rm2组成,且rm1为active,rm2为standby。某一刻rm1发生“假死”现象,此时zk认为rm1挂了,从而主备切换,rm2称为active。但是随后,rm1恢复了正常,其依然认为自己还处于active。那么就出现了我们常说的分布式“脑裂”(Brain-Split)现象,即存在多个处于Active状态的rm各司其职。
- Yarn引入了Fencing机制来解决上述问题,即借助zk数据节点的ACL权限控制机制来实现不同rm之间的隔离。
- 具体做法很简单:在主备切换过程中,多个rm之间通过竞争创建锁节点来实现主备状态的确定。这个过程中,有一点需要改进:创建的根节点必须携带zk的ACL信息,目的是为了独占该根节点,以防止其他RM对该节点进行更新。
- 具体来说:
- RM1出现假死之后,zk就会将其创建的锁节点移除,此时RM2会创建相应的锁节点,并切换为Active状态。RM1恢复之后,会试图去更新zk的相关数据,但是此时发现自己没有权限更新zk的相关数据节点。从而rm1自动切换到Standby状态。
RM状态存储
- 在RM中,RMStateStore能够存储一些RM内部状态信息,包括Application以及它们的Attempts信息、Delegatioln Token及Version Information等。
- RMStateStore中绝大多数信息都是不需要持久化存储,因为很容易从上下文信息中将其重构出来。
- 在存储的设计方案中,提供了三种可能的实现,分别如下:
- 基于内存实现,一般用于日常开发测试;
- 基于文件系统的实现,如HDFS;
- 基于zk的实现。
- 由于这些状态数据量都不大,因此hadoop官方建议基于zk来实现状态信息存储。
- 在zk上,rm的状态信息都存储在/rmstore这个根节点上,其数据节点的组织结构如下:

- Please read this link.
HBase
- HBase是一个基于Hadoop文件系统设计的面向海量数据的高可靠性、高性能、面向列、可伸缩的分布式存储系统。
- 与大部分分布式NoSQL数据库不同的是,HBase针对数据写入具有强一致性,甚至包括索引列也实现了强一致性。
- HBase整体架构如下图:

- 可以看到,在整个HBase架构体系中,zk是串联起HBase集群与client的关键所在。
- 早期Hbase没有引入zk时,存在一系列问题:
- RegionServer挂掉时,系统无法及时得知信息,client也无法知晓,因此服务难以迁移至其他RegionServer上
- 类似的问题都是缺少相应的分布式协调组件。
- 下面从以下几个方面讲解zk在HBase中的应用场景。
系统冗错
- (系统冗错其实就是监控rs
- 当HBase启动时,每个RegionServer都会到zk的/hbase/rs节点下创建一个信息节点(rs状态节点),例如/hbase/rs/[Hostname],同时HMaster会监听该节点。
- 当某个rs挂掉时,zk会因为在一段时间内无法接受其心跳信息(即Session失效),而删除掉该rs对应的rs状态节点。同时,HMaster收到zk的NodeDelete通知,并立即开始冗错工作:
- HMaster会将该RegionServer所处理的数据分片(Region)重新路由到其他节点上,并记录到Meta信息中供client查询。
- 那么,为什么不直接让HMaster来负责RegionServer的监控呢?是因为通过心跳机制来管理rs状态会使HMaster的负载随着系统容量而不断增大。并且,HMaster可能挂掉,因此数据还需要持久化。
RootRegion管理
- 对HBase集群而言,数据存储的位置信息是记录在元数据分片,也就是RootRegion上的。每次client发起新的请求,需要知道数据的位置,就会去查询RootRegion,而RootRegion自身的位置是记录在zk上的。当RootRegion发生变化,比如Region的手工移动、Balance或是RootRegion所在server发生故障等时,就能通过zk来感知到这一变化并做出一系列容灾措施。
Region状态管理
- Region是HBase中数据的物理切片,每个Region中记录了全局数据的一小部分。
- 对一个分布式系统而言,Region是会经常发生变更的。一旦Region发生移动,它必然会经历Offline和重新Online的过程。
- Offline期间数据是不能被访问的,并且Region的这个状态必须被全局知晓,否则可能会出现事务性的异常。
分布式SplitLog任务管理
- 当某台RS挂掉时,由于总有一部分新写入的数据还没有持久化到HFile中,因此在迁移该RegionServer的服务时,一个重要的工作就是从HLog中恢复这部分还在内存中的数据(WAL)。
- 而这部分工作最关键的一步就是SpitLog,即HMaster需要遍历该RS的HLog,并按Region切分成小块移动到新地址下,并进行数据的Replay。
- 由于单个RS的日志量相对庞大(可能有数千个Region,上GB的日志),一个快速恢复的可行方案就是将这个处理HLog的任务分配给多台rs来共同处理。
- 因此需要一个持久化组件来辅助HMaster完成任务的分配。当前的做法是,在zk上创建一个splitlog节点,将rs和待处理的region之间的映射关系存放到该节点。然后各个rs到该节点上领取任务并在执行后将成功or失败的信息更新到节点。
- 整个过程中,zk担负了分布式集群中相互通知和信息持久化的角色。
Kafka
- kafka:开源分布式消息系统
- 主要用于实现低延迟的发送和收集大量的事件和日志数据。
- kafka是一个吞吐量极高的分布式消息系统,其整体设计是典型的发布与订阅模式。
- 在kafka集群中,没有“中心主节点”的概念,所有server都是对等的。 --> 因而可以在不做任何配置更改的情况下实现server的添加和删除。同样,消息的生产者和消费者也能够随意重启和机器的上下线。
- kafka中生产者和消费者之间的部署关系如下图:
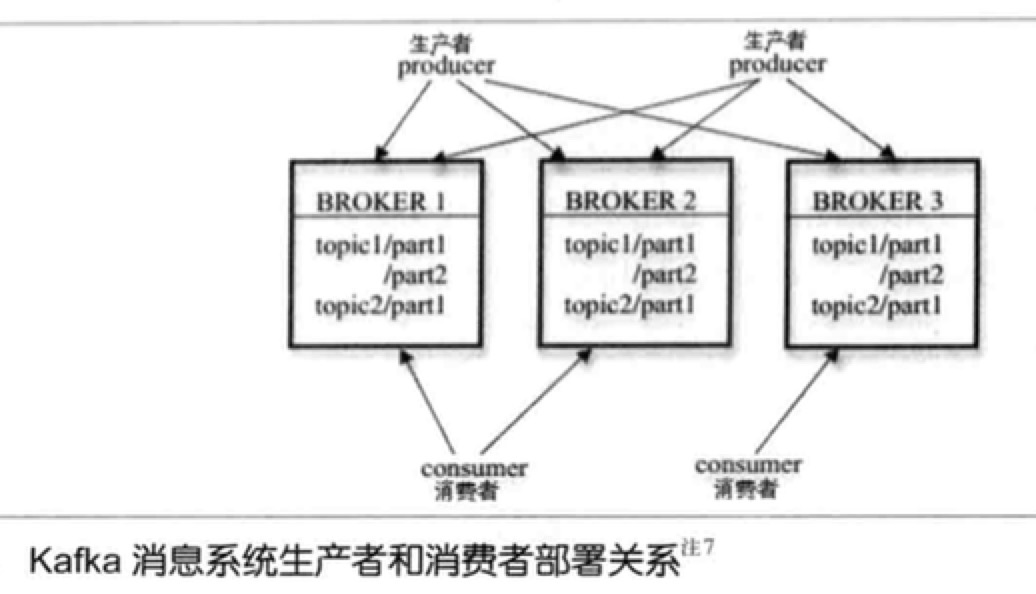
术语介绍
- Kafka是一个近似符合JMS规范的消息中间件实现。
- producer:
- consumer:
- topic:由用户定义并配置在kafka server端,用于建立producer和consumer之间的订阅关系
- partition:一个topic下面会分为多个分区
- broker:kafka的服务器,用于存储消息。
- group:用于归组同类消费者
- offset:
Broker注册
- 虽然broker是分布式部署并且相互之间是互相独立运行的,但还是需要有一个注册系统能够将整个集群中的broker server都管理起来。 --> 在kafka的设计中,选择了使用zk来进行所有broker的管理。
- broker节点:/brokers/ids --> 每个broker sever启动时都会到zk上注册 /broker/ids/[0...N] (临时节点,以动态表征broker server的可用性),broker会把自己的IP和port写入该节点。
- 可以看出每个broker节点都有一个全局唯一的 Broker ID.
Topic注册
- kafka中,用一个topic的消息会分成多个partition并分布到多个broker中。 --> 映射关系由zk维护。
- topic节点:/brokers/topics/[topic] (临时节点)
生产者负载均衡
- 因为同一个topic会被分区从而分布到不同的broker server上。因而生产者需要将消息合理地发送到这些分布式的broker上。 --> 从而产生了如何进行生产者负载均衡的问题。
- 对于生产者的负载均衡,kafka支持传统的四层负载均衡,同时也支持使用zk的方式来实现负载均衡。
四层负载均衡
- 设计简单:根据生产者的IP地址和端口来为其确定一个相关联的broker。通常一个生产者只会对应单个broker。
- 优点:1. 整体逻辑简单,不需要引入第三方系统。2. 每个producer只需与broker维护单个TCP链接即可。
- 缺点:1. 无法做到真正的负载均衡。因为每个producer产生的消息量不同,从而导致不同broker接收到的消息总数非常不均匀。2. 生产者无法实时感知到broker的新增与删除。
使用zk进行负载均衡
- 在kafka中,client使用了基于zk的负载均衡策略来解决producer的负载均衡问题。
- kafka producer会对zk上的“broker的新增与减少”、“Topic的新增与减少”和“Broker与Topic关联关系的变化”等事件注册watcher监听,从而实现一种动态的负载均衡机制。
消费者负载均衡
- kafka consumer也需要进行负载均衡来实现多个consumers合理地从对应broker server上接收消息。(生产者负载均衡则是producer合理地选择broker来发送消息)
- 对于一个消费者分组,如果组内的consumers发生变更或broker server发生变更,会触发消费者负载均衡。
- 关于consumer group:group是对整个kafka集群的概念,kafka保证每条消息在同一个group内只会被某一个consumer消费。(比如说kafka + Spark streaming的组合,那么所有的streaming executor组成一个group,去消费某个topic。)
- kafka提供的consumer负载均衡算法:
- topic的所有消息分区Pt --> 需要对Pt进行排序,从而使分布在同一个broker server的分区尽量靠在一起。
- 同一个group中的所有消费者Cg --> 对Cg进行排序。
- N = size(Pt) / size(Cg)
- 将编号为 i * N ~ (i + 1) * N - 1的消息分区分配给消费者Ci
- 更新zk上消息分区与消费者Ci的关系
kafka小结
- kafka从设计之初就是一个大规模分布式消息中间件,其server端存在多个broker,同时为了达到负载均衡,将每个topic的消息分成了多个partition,并分布在不同broker上。多个消费者和生产者能够同时发生和接收消息。
- kafka使用zk作为其分布式协调框架,能很好地将消息生产、消息存储和消息消费结合起来。借助zk,来保持包括producer、consumer和broker在内的所有组件无状态情况下,建立起producer和consumer之间的订阅关系,并实现了producer和consumer的负载均衡。
<zk在大型分布式系统中的应用>的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- DataGridView 访问任意行不崩溃
int index= this.dataGridView1.rows.Add(); 先执行这行代码,然后访问任意行,不崩溃, 赋值不存在的行,只是不显示,或者无值. 什么原理呢? 一些其他 priva ...
- GoldenGate使用SQLEXEC和GETVAL实现码表关联
使用OGG中的SQLEXEC参数,可以执行SQL语句或存储过程,再加上@GETVAL函数,可以在目标端获取源表没有的字段值.比如,源端有一个事实表和一个代码表COUNTRY_CODES,代码表中有两个 ...
- ltp-ddt inverted_return小trick
./runtest/ddt/i2c_readwrite # @name I2C write read test on slave device# @desc I2C write read test o ...
- SQL语句汇总(二)——数据修改、数据查询
SQL语句第二篇,不说废话直接开始吧. 首先创建一张表如下,创建表的方法在上篇介绍过了,这里就不再赘述. 添加新数据: INSERT INTO <表名> (<列名列表>) VA ...
- elasticsearch best_fields most_fields cross_fields从内在实现看区别——本质就是前两者是以field为中心,后者是词条为中心
1.最佳字段(Best fields):: 假设我们有一个让用户搜索博客文章的网站(允许多字段搜索,最佳字段查询),就像这两份文档一样: PUT /my_index/my_type/1 { " ...
- Docker Kubernetes 容器扩容与缩容
Docker Kubernetes 容器扩容与缩容 环境: 系统:Centos 7.4 x64 Docker版本:18.09.0 Kubernetes版本:v1.8 管理节点:192.168.1.79 ...
- ASP.NET MVC:缓存功能的设计及问题
这是非常详尽的asp.net mvc中的outputcache 的使用文章. [原文:陈希章 http://www.cnblogs.com/chenxizhang/archive/2011/12/14 ...
- JSOIWC2019游记
世除我WC...都去广二了qaq,就我还在nj ycs至少也去了pkuwc啊 这个JSOIWC2019的内容看起来很水,进入条件简单,但窝啥都不会,肯定垫底 内容清单: 1.26 上午听机房dalao ...
- PHP实现简单发红包(随机分配,平均分配)
最近碰到一些情况,把思路重新整理了一下,敲出代码.记下来,以后可以借鉴,进一步优化等. 大致的思路:红包主要分两种,一种是平均分配,一种是随机分配. 1.平均分配 平均分配相对好理解,只要把钱平均分给 ...
- 处理table 超出部分滚动问题
我们有个需求是这样的,鉴于我的表达能力还是直接上原型图吧 今天主要记录上面的第四条解决过程. 首先我们的布局使用的table,当想给tbody设置高度的时候,发现不起作用.原因是table的默认是di ...