2、haproxy配置参数详解
代理相关配置参数
内容参考自马哥教育
HAProxy官方文档 https://cbonte.github.io/haproxy-dconv/2.0/configuration.html






URI Syntax:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag> //<scheme>表示协议;<user>:<password>可以省略;<params>表示参数;?<query>表示查询字符串;
URI的左半部分是:<scheme>://<user>:<password>@<host>:<port>/<path>;<params>
;<params>
ftp://downloads.dongshi.com/pub/gnu;type=d //type=d就是指明了类型,是一个params
http://www.dongshi.com/hammers;sale=false/index.html;graphics=true //红色部分为params
?<query>
http://www.joes-hardware.com/inventory-check.cgi?item=12741 //?item=12741表示要把item=12741当作查询条件,通过URL(红色部分)把条件发送给服务器端,然后服务器端会把查询条件嵌入到php或jsp的页面程序当中,由这个页面程序基于mysql或者其他存储协议发往服务器端,并由服务器端执行并取回结果,所以?item=12741是查询字符串。
什么情况下可以用到URI算法?(调度方式:对URL做hash计算,将计算结果除以总权重数)
当后端服务器是缓存服务器时特别有用,即无论哪个客户端发出请求,只要资源链接是同一个,haproxy主机都可以始终把请求发送至同一个backend server(缓存服务器)。假如有一个资源链接在之前没有被用户请求过,所以并没有缓存,那么haproxy就会根据后端缓存服务器的权重挑选一个backend server响应用户的请求。一旦根据算法挑选backend server结束,haproxy内部就会维护一个hash表,表中存储的是键值对,键是URL的hash值,值是之前挑选出的对应的backend server的地址,因此如果有客户端再次请求同一个资源链接时,haproxy会把URL做hash计算,对比内部维护的hash表,有相同的键就直接把这个请求发送到键对应的值的backend server中。

URI算法示例(根据请求的URL进行调度)
# vim /etc/haproxy/haproxy.cfg //在代理服务器上进行操作
#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend websrvs
5 balance uri //使用uri算法
6 hash-type consistent //类型为consistent
server web1 192.168.128.132: check
server web2 192.168.128.133: check
# systemctl reload haproxy
# systemctl status haproxy
# for i in {1..10}; do echo "<h1>Page $i on node2" > /var/www/html/test$i.html; done //在node2上添加10个页面
# for i in {1..10}; do echo "<h1>Page $i on node3" > /var/www/html/test$i.html; done //在node3上添加10个页面

从上面的图片可以看出,利用uri算法可以把同一个资源链接始终发送至后端的同一个backend server,无论使用什么样的请求方式。如果其中一台backend server宕机的话,haproxy会把这个主机上的请求发送至另外一台haproxy主机。
hdr算法演示:根据用户的User-Agent进行调度
# vim /etc/haproxy/haproxy.cfg //修改内容如下
backend websrvs
balance hdr(User-Agent)
hash-type consistent
server web1 192.168.128.132: check
server web2 192.168.128.133: check
# systemctl reload haproxy
# for i in {1..5}; do echo "<h1>Page$i on node2</h1>" > /var/www/html/ceshi$i.html; done //在node2上创建web页面
# for i in {1..5}; do echo "<h1>Page$i on node3</h1>" > /var/www/html/ceshi$i.html; done //在node3上创建web页面
可以看出不同的User-Agent请求相同的资源链接会被调度至不同的服务器


代理参数:
balance: 指明调度算法;
动态:权重可动态调整
静态:调整权重不会实时生效
roundrobin: 轮询(加权轮询),动态算法,每个后端主机最多支持4128个连接;
static-rr: 轮询,静态算法,每个后端主机支持的数量无上限;
leastconn: 根据后端主机的负载数量进行调度;仅适用长连接的会话;动态;
source:这种算法有静态和动态两种,取决于hash类型
hash-type:
map-based:取模法;静态;
consistent:一致性哈希法;动态;
uri:
hash-type
map-based:更省资源
consistent:由于服务器总会上下线,所以一般会把hash-type设置为consistent
url_param: 根据url中的指定的参数的值进行调度;把值做hash计算,并除以总权重;比如sale=false/index.html的值就是false/index.html。功用:在url中添加一个参数,根据用户请求参数值的类型来做出调度决策。
hash-type
map-based:
consistent:
hdr(<name>):根据请求报文中指定的header(如use_agent, referer, cookie,hostname)进行调度;把指定的header的值做hash计算;
hash-type
map-based:
consistent:
bind:做绑定,指明要监听的地址
bind [<address>]:<port_range> [,...]
bind [<address>]:<port_range> [,...] interface <interface>
示例:
# vim /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main
5 bind *:80 //修改如下
6 bind *:8080 //注意如果端口进行改动,一定要重启服务,reload是不起作用的
default_backend websrvs #---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend websrvs
balance hdr(User-Agent)
hash-type consistent
server web1 192.168.128.132: check
# systemctl restart haproxy
# ss -tunl //可以看到已经监听了8080端口
tcp LISTEN 0 128 *:8080 *:*
tcp LISTEN 0 128 *:80 *:*
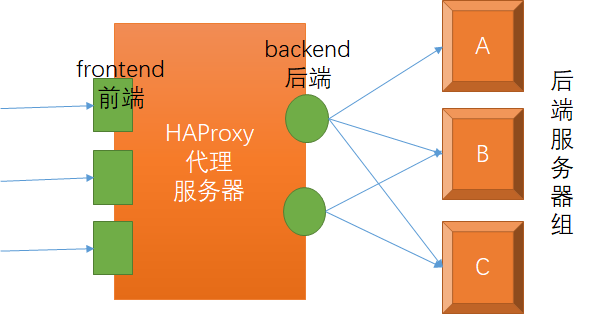
bind只能用于frontend, listen(listen既能面向前端,又能面向后端):
因为作为代理服务器,当客户端的请求过来时,代理服务器haproxy需要接受用户的请求,所以需要监听端口;
而当代理服务器把客户端的请求重构后并把自己扮演为客户端的向后端的backend server请求时,代理服务器接受backend server的响应报文是不需要监听端口的。
mode:指明haproxy实例运行时的模式或协议
HAProxy的工作模式有两种:http协议的 反向代理、tcp链接协议的负载均衡;默认为tcp;
tcp, http, health
log:
maxconn:设定前端最大并发连接数
后端有多个backend sevrer,对于最大连接数的设置有以下几个:在前端可以定义多个frontend或者多个listen,每一个frontend都要通过backend把用户的请求发往后端的backend server,而maxconn是定义每一个前端的最大连接数。如果是定义在全局上就是整个服务器的最大连接数,在global中也可以定义maxconn,所有的frontend或者listen的最大连接数加起来等于全局的。如果把最大连接数定义在frontend或者listen中则是设置前端的,前端的请求会通过某一个后端负载均衡至后端的服务器,一个backend可以定义多个后端主机。为了避免后端主机被压垮,可以在backend中设置后端服务器可以承载的链接数,应该设定所有后端服务器可承受的连接数量应该大于等于前端的最大并发连接数的。
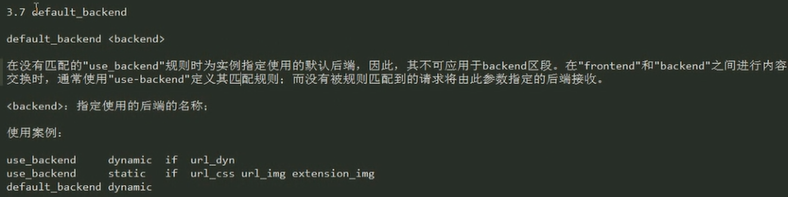
default_backend:定义默认后端
为frontend指明使用的默认后端;
use_backend: 条件式后端调用;
K.I.S.S: Keep it simple, stupid.
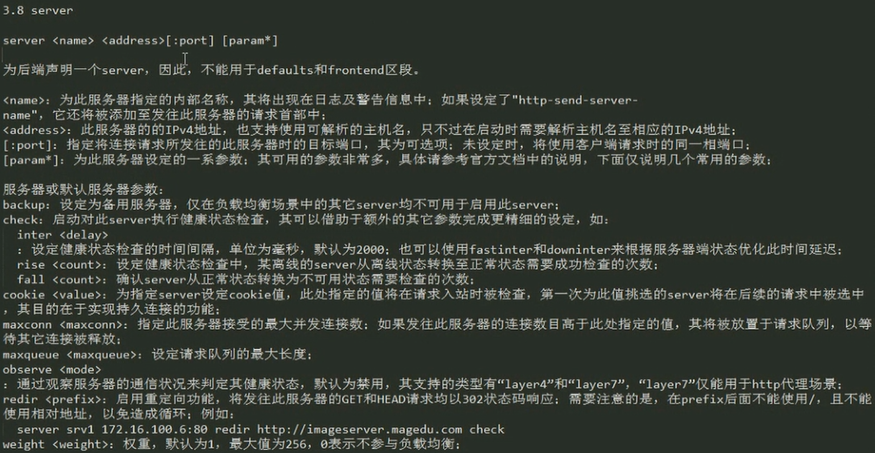
server:
server <name> <addr>[:port] [param*]
[param*]有很多选项
backup: 设定当前server为backup server;
check: 健康状态检测,有三种:(注意:健康状态检测信息不应该记录在日志中,因为这些信息会非常占用空间)
inter <delay>:检测时间间隔;单位为ms, 默认为2000;
fall: up --> down, soft state, soft state, hard state;
rise:down --> up,
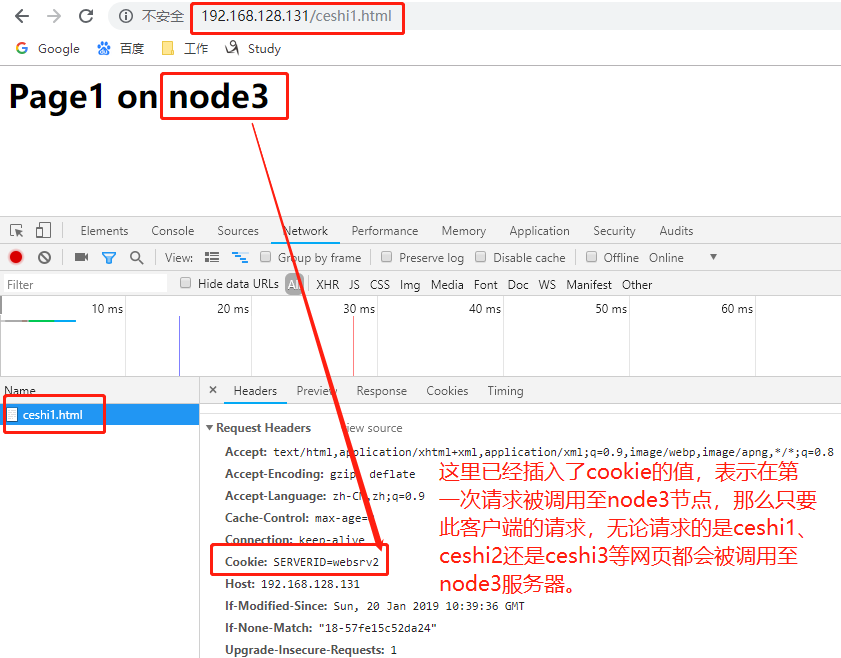
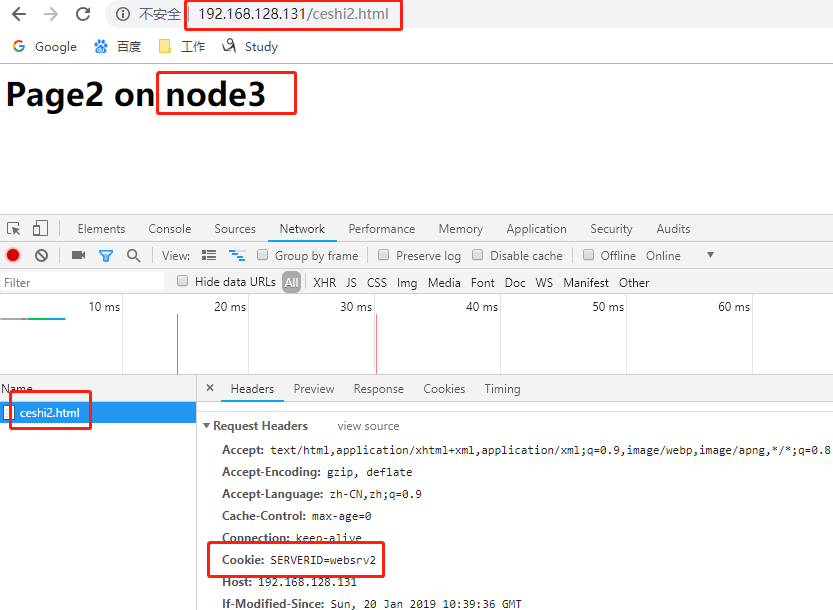
cookie <value>:每一个用户请求通过前端到达backend,backend会根据算法挑出一个后端服务器。后端服务器把响应报文由haproxy响应给客户端时,同时backend 会把backend指向后端服务器的cookie信息也发给客户端一份,比如backend把客户端的信息调度到node1,那么cookie信息就会指明是node1。如 果是基于cookie信息绑定的话,当同一个客户端再来请求时,haproxy就会检查请求所带的cookie信息,因此就会知道此前挑选了node1,就会发往 同一个服务器。这个cookie是会话级别的,而不是基于源地址绑定。客户端经过haproxy代理服务器请求时,代理服务器会重构报文因此报文的源地址 都是代理服务器的地址即源地址是一样,但请求报文中携带者客户端的cookie信息,所以代理服务器会基于cookie信息把请求发往不同的后端服务器。
maxconn: 此服务接受的并发连接的最大数量;
maxqueue: 请求队列的最大长度;
observe: 根据流量判断后端server的健康状态;
weight: 指定权重,默认为1,最大为256;0表示不被调度;
redir <prefix>: 重定向;所有发往此服务器的请求均以302响应;
server srv1 192.168.128.132:80 redir http://imageserver.nihaocom check //指调度时所有发往192.168.128.132:80主机的请求都重定向至http://imageserver.nihaocom主机,prefix指http://imageserver.nihaocom后面不能跟"/"。后端real server重定向。
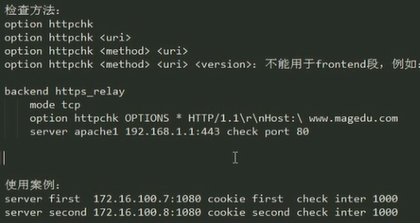
后端http服务时的健康状态的检测方法:(只能是http协议)
option httpchk
基于浏览器cookie实现session sticky:

cookie <name>:name是必须的,是cookie自己的名字,跟给server发送的信息是没有关系的。当一个用户发出请求,haproxy会操作客户端发送请求所携带的cookie信息,虽然客户端携带的cookie信息已经有了之前访问所对应的backend server的信息,但是haproxy会在原有的基础之上加上其他标识信息,这个另加信息只为haproxy使用,那么如何使用?在backend中为每一个后端real server指明一个唯一的cookie标识,把这个表示插入客户端每一次访问的cookie信息中去。把这个标识插入到原有cookie中什么位置?有三种方式:1、把原有cookie重写,抛弃之前的cookie;2、insert,即把标识插入到cookie中去;3、prefix,把标识附加在原有cookie的前面。但是insert方式最为常见。
启用基于cookie的每客户端会话绑定示例演示
要点:
(1) 每个server有自己惟一的cookie标识(websrv1/websrv1);
(2) 在backend中定义为用户请求调度完成后操纵其cookie。
# vim /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main
bind *:
bind *:
default_backend websrvs #---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend websrvs
balance roundrobin
15 cookie SERVERID insert nocache indirect //如果希望用户请求发送至后端real server后能基于cookie会话绑定的话,就需要添加cookie参数的配置信息。
//在这里把cookie的name取为SERVERID,SERVERID的值会被赋予websrv1或者websrv2,这要取决于请求被调度上哪个real server上,insert是指明cookie的给定方式
16 server web1 192.168.128.132:80 check weight 1 cookie websrv1 //添加cookie信息,客户端访问时会在原有的cookie信息后面插入web1信息
17 server web2 192.168.128.133:80 check weight 3 cookie websrv2 //必须是唯一标识
# systemctl status haproxy
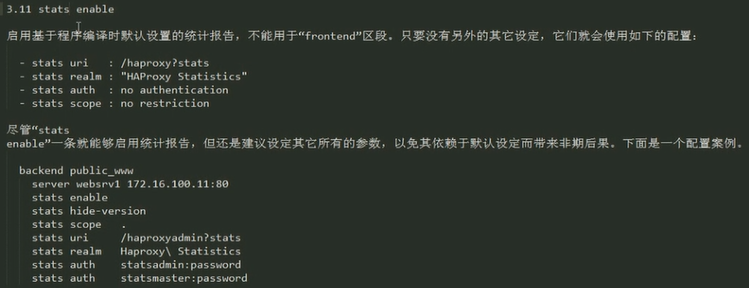
启用stats:
listen statistics
bind *:9090
stats enable
stats hide-version
#stats scope .
stats uri /haproxyadmin?stats
stats realm "HAPorxy\ Statistics"
stats auth admin:mageedu
stats admin if TRUE
向日志中记录额外信息:
capture request header
capture response header
当mode为http时,记录丰富的日志信息:
option httplog
错误页面重定向:
errorfile: 使用haproxy主机本地文件进行响应;
errorloc, errorloc302: 使用指定的url进行响应,响应状态码为302;不适用于GET以外的其它请求方法;
errorloc303:返回303状态码;
访问控制:
http_request
tcp_request
添加请求或响应报文首部:
reqadd
rspadd
ACL
定义,及调用;
2、haproxy配置参数详解的更多相关文章
- HAproxy 配置参数详解
HAproxy 配置参数详解 /etc/haproxy/haproxy.cfg # 配置文件 ----------------------------------------------------- ...
- mha配置参数详解
mha配置参数详解: 参数名字 是否必须 参数作用域 默认值 示例 hostname Yes Local Only - hostname=mysql_server1, hostname=192.168 ...
- reids配置参数详解
转自:http://www.jb51.net/article/60627.htm reids配置参数详解 #daemonize no 默认情况下, redis 不是在后台运行的,如果需要在后台运行, ...
- nginx配置参数详解
配置参数详解 user nginx nginx ; Nginx用户及组:用户 组.window下不指定 worker_processes 8; 工作进程:数目.根据硬件调整,通常等于CPU数量或者2倍 ...
- Redis配置参数详解
Redis配置参数详解 /********************************* GENERAL *********************************/ // 是否作为守护进 ...
- MHA配置参数详解 【转】
mha配置参数详解: 参数名字 是否必须 参数作用域 默认值 示例 hostname Yes Local Only - hostname=mysql_server1, hostname=192.168 ...
- zookeeper的配置参数详解(zoo.cfg)
配置参数详解(主要是%ZOOKEEPER_HOME%/conf/zoo.cfg文件) 参数名 说明 clientPort 客户端连接server的端口,即对外服务端口,一般设置为2181吧. data ...
- samba 配置参数详解
samba 配置参数详解: 一.全局配置参数 workgroup = WORKGROUP说明:设定 Samba Server 所要加入的工作组或者域. server string = Samba S ...
- [转帖]持久化journalctl日志清空命令查看配置参数详解
持久化journalctl日志清空命令查看配置参数详解 最近 linux上面部署服务 习惯使用systemd 进行处理 这样最大的好处能够 使用journalctl 进行查看日志信息. 今天清理了下 ...
随机推荐
- 31、cookie小test
请尽量使用JQuery进行代码编写,需求如下: 1. 页面初始化样式如图 2. 顶部input框中输入内容,按下回车enter键后,“正在进行” 列表中加入该条内容. 3. 顶部input框中输 ...
- Windows下64位Apache+PHP+MySQL配置
软件下载 目前,Apache和PHP均未出现官方的64位版本. Apache 64位: http://files.cnblogs.com/liangjie/httpd-2.2.19-win64.rar ...
- Win7局域网内共享文件设置方式
1.右键-->打开网络和共享中心 2.打开网络和共享中心-->单击更改高级共享设置 3.选中文件(夹)-->属性->共享 4.共享-->添加用户,并赋予相应权限 5.选中 ...
- python全栈开发 * 03 基本数据类型 * 180601
python基本数据类型 ( int , bool , str ) 一 python基本数据类型 (一)int ==> 整数.进行数学运算 (二)str ==> 字符串. ...
- 免费API 接口罗列,再也不愁没有服务器开发不了APP了(下)【申明:来源于网络】
免费API 接口罗列,再也不愁没有服务器开发不了APP了(下)[申明:来源于网络] 地址:http://mp.weixin.qq.com/s/QzZTIG-LHlGOrzfdvCVR1g
- Gym 101775A - Chat Group - [简单数学题][2017 EC-Final Problem A]
题目链接:http://codeforces.com/gym/101775/problem/A It is said that a dormitory with 6 persons has 7 cha ...
- java的几种对象(PO,VO,DAO,BO,POJO,DTO)解释
一.PO:persistant object 持久对象,可以看成是与数据库中的表相映射的java对象.最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合.PO中应该不包含任何对数 ...
- 1.7Oob方法的作用
public class Exse2 { public static void main(String[] args) { sumIntLong(10,15); sumIntLong(20,30); ...
- Python-----redis数据库
# redis数据库:基于内存的高性能key-value数据库,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存:#缺点:1.数据库容量受到物理内存的限制, ...
- (转载)Java Map中的Value值如何做到可以为任意类型的值
转载地址:http://www.importnew.com/15556.html 如有侵权,请联系作者及时删除. 搬到我的博客来,有空细细品味,把玩. 本文由 ImportNew - shut ...