用scrapy框架爬取映客直播用户头像
1. 创建项目 scrapy startproject yingke cd yingke
2. 创建爬虫 scrapy genspider live
3. 分析http://www.inke.cn/hotlive_list.html网页的response,找到响应里面数据的规律,并找到的位置,通过response.xpath()获取到
4. 通过在pipline里面进行数据的清洗,过滤,保存
5. 实现翻页,进行下一页的请求处理
6. 运行爬虫 scrapy crawl live
说明:这个程序直接在parse方法里面进行图片保存,保存在本地,正常使用yield关键字进行在pipline中保存。
# -*- coding: utf-8 -*-
import scrapy
import re class LiveSpider(scrapy.Spider):
name = 'live'
allowed_domains = ['inke.cn']
start_urls = ['http://www.inke.cn/hotlive_list.html?page=1'] def parse(self, response):
div_list = response.xpath("//div[@class='list_box']") for div in div_list:
item = {}
img_src = div.xpath("./div[@class='list_pic']/a/img/@src").extract_first()
item["user_name"] = div.xpath(
"./div[@class='list_user_info']/span[@class='list_user_name']/text()").extract_first()
print(item["user_name"])
yield scrapy.Request( # 发送详情页的请求
img_src,
callback=self.parse_img,
meta={"item": item}
)
# 下一页
now_page = re.findall("page=(.*)", response.request.url)[0]
now_page= int(now_page) next_url = "http://www.inke.cn/hotlive_list.html?page={}".format(str(now_page+ 1))
yield scrapy.Request(
next_url,
callback=self.parse
) def parse_img(self, response):
user_name = response.meta["item"]["user_name"] with open("images/{}.png".format(user_name), "wb") as f: f.write(response.body)
运行效果:
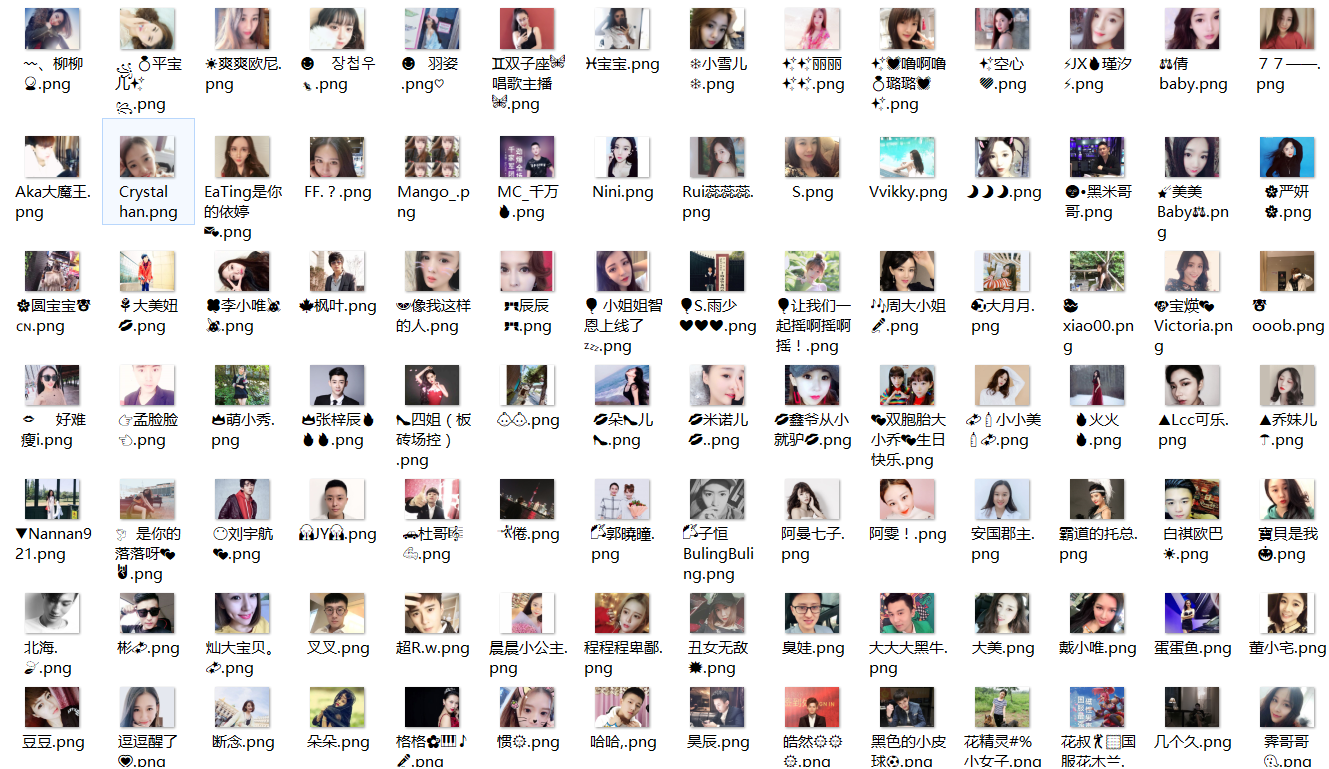
用scrapy框架爬取映客直播用户头像的更多相关文章
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- 使用scrapy框架爬取自己的博文
scrapy框架是个比较简单易用基于python的爬虫框架,http://scrapy-chs.readthedocs.org/zh_CN/latest/ 这个是不错的中文文档 几个比较重要的部分: ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- 使用scrapy框架爬取自己的博文(3)
既然如此,何不再抓一抓网页的文字内容呢? 谷歌浏览器有个审查元素的功能,就是按树的结构查看html的组织形式,如图: 这样已经比较明显了,博客的正文内容主要在div 的class = cnblogs_ ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- scrapy框架爬取豆瓣读书(1)
1.scrapy框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
随机推荐
- Codeforces Round #443 (Div. 1) A. Short Program
A. Short Program link http://codeforces.com/contest/878/problem/A describe Petya learned a new progr ...
- Application-Level层级异常捕获并定位程序的异常位置
最近遇到一个需求,在设置503错误页面时,如果程序出错,服务器自动发邮件通知所有程序员,方便程序员及时解决问题. 想到好像global.cs文件里面好像有个erro事件,然后找到了Applicatio ...
- C#_02.13_基础四_.NET方法
C#_02.13_基础四_.NET方法 一.方法概述: 方法是一块具有名称的代码.可以通过方法进行调用而在别的地方执行,也可以把数据传入方法并接受数据输出. 二.方法的结构: 方法头 AND 方法 ...
- GMA Round 1 简单的线性规划
传送门 简单的线性规划 已知D(x,y)满足$\left\{\begin{matrix}x>-3\\ y>1\\ x+y<12\end{matrix}\right.$ 求$\frac ...
- 一款开源免费的WPF图表控件ModernuiCharts
一款简洁好看的Chart控件 支持WPF.silverlight.Windows8 ,基本够用,主要是开源免费的.(商业控件ComponentOne for WPF要4w多呢) This proj ...
- oracle操作字符串:拼接、替换、截取、查找、长度、判断
1.拼接字符串 1)可以使用“||”来拼接字符串 select '拼接'||'字符串' as str from dual 2)通过concat()函数实现 select concat('拼接', '字 ...
- SharePoint 前端开发常用的对象之_spPageContextInfo
前言 _spPageContextInfo对象,是SharePoint开发一个非常常用的对象,尤其是前端开发,可以非常方便的获取到一些和站点有关的信息. 完整对象如下图,需要什么属性,可以自己获取,然 ...
- MSSQL 调用C#程序集 实现C#字符串到字符的转化
10多年前用过MSSQL 调用C#程序集来实现数据的加密和解密,也搞过通过字符偏移实现简单的加密和解密.这次就总结一下吧: C#如下: public class CLRFunctions { /// ...
- bootstrap-3-上传图片-列表显示
效果 导入的js和css <!-- 最新版本的 Bootstrap 核心 CSS 文件 --> <link rel="stylesheet" href=" ...
- IntelliJ IDEA 下载安装(含注册码)
https://blog.csdn.net/mashuai720/article/details/79389314