Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.启动Hadoop集群
1>.自定义批量管理脚本
[yinzhengjie@s101 ~]$ more `which xzk.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -ne ];then
echo "无效参数,用法为: $0 {start|stop|restart|status}"
exit
fi #获取用户输入的命令
cmd=$ #定义函数功能
function zookeeperManger(){
case $cmd in
start)
echo "启动服务"
remoteExecution start
;;
stop)
echo "停止服务"
remoteExecution stop
;;
restart)
echo "重启服务"
remoteExecution restart
;;
status)
echo "查看状态"
remoteExecution status
;;
*)
echo "无效参数,用法为: $0 {start|stop|restart|status}"
;;
esac
} #定义执行的命令
function remoteExecution(){
for (( i= ; i<= ; i++ )) ; do
tput setaf
echo ========== s$i zkServer.sh $ ================
tput setaf
ssh s$i "source /etc/profile ; zkServer.sh $1"
done
} #调用函数
zookeeperManger
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xzk.sh` (zookeeper集群管理脚本)
[yinzhengjie@s101 ~]$ more `which xcall.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数"
exit
fi #获取用户输入的命令
cmd=$@ for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo ============= s$i $cmd ============
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
ssh s$i $cmd
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xcall.sh` (批量执行命令的脚本)
2>.启动zookeeper集群
[yinzhengjie@s101 ~]$ xzk.sh start
启动服务
========== s102 zkServer.sh start ================
ZooKeeper JMX enabled by default
Using config: /soft/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
========== s103 zkServer.sh start ================
ZooKeeper JMX enabled by default
Using config: /soft/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
========== s104 zkServer.sh start ================
ZooKeeper JMX enabled by default
Using config: /soft/zk/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[yinzhengjie@s101 ~]$
3>.启动hdfs分布式文件系统
[yinzhengjie@s101 ~]$ start-dfs.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.-bin/lib/log4j-slf4j-impl-2.4..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Starting namenodes on [s101 s105]
s101: starting namenode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-namenode-s101.out
s105: starting namenode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-namenode-s105.out
s102: starting datanode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-datanode-s102.out
s103: starting datanode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-datanode-s103.out
s104: starting datanode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-datanode-s104.out
Starting journal nodes [s102 s103 s104]
s102: starting journalnode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-journalnode-s102.out
s104: starting journalnode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-journalnode-s104.out
s103: starting journalnode, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-journalnode-s103.out
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/soft/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.-bin/lib/log4j-slf4j-impl-2.4..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Starting ZK Failover Controllers on NN hosts [s101 s105]
s101: starting zkfc, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-zkfc-s101.out
s105: starting zkfc, logging to /soft/hadoop-2.7./logs/hadoop-yinzhengjie-zkfc-s105.out
[yinzhengjie@s101 ~]$
4>.启动yarn集群
[yinzhengjie@s101 ~]$ start-yarn.sh
starting yarn daemons
s101: starting resourcemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-resourcemanager-s101.out
s105: starting resourcemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-resourcemanager-s105.out
s102: starting nodemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-nodemanager-s102.out
s104: starting nodemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-nodemanager-s104.out
s103: starting nodemanager, logging to /soft/hadoop-2.7./logs/yarn-yinzhengjie-nodemanager-s103.out
[yinzhengjie@s101 ~]$
5>.查看集群是否启动成功
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
ResourceManager
NameNode
DFSZKFailoverController
Jps
命令执行成功
============= s102 jps ============
JournalNode
DataNode
QuorumPeerMain
NodeManager
Jps
命令执行成功
============= s103 jps ============
Jps
QuorumPeerMain
JournalNode
DataNode
NodeManager
命令执行成功
============= s104 jps ============
DataNode
QuorumPeerMain
NodeManager
Jps
JournalNode
命令执行成功
============= s105 jps ============
Jps
NameNode
DFSZKFailoverController
命令执行成功
[yinzhengjie@s101 ~]$
检查WebUI是否正常打开:
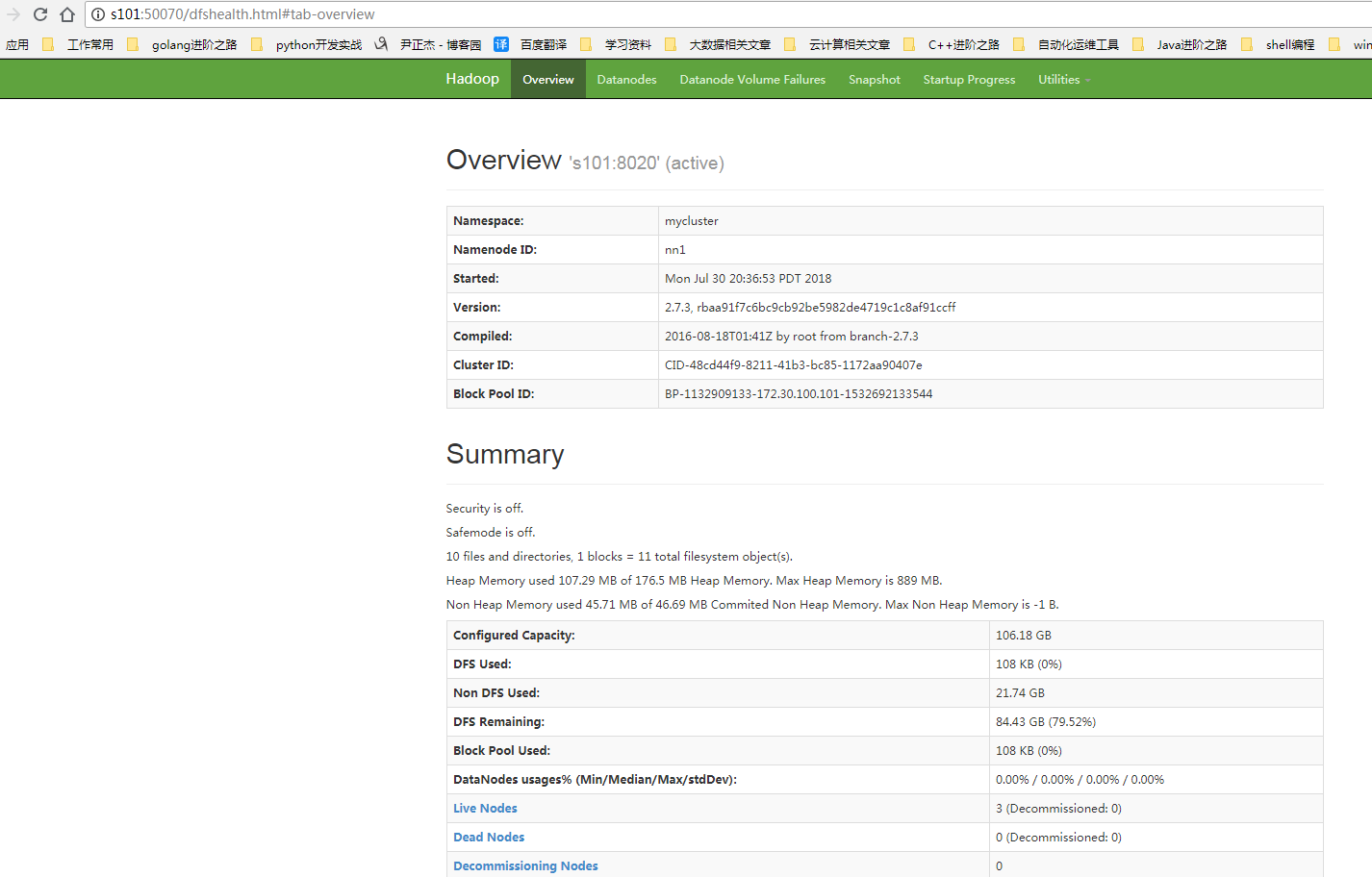
二.Spark集群的运行模式
1>.local
本地模式,不需要启动任何进程.使用jvm多个线程模拟worker。
2>.standalone
独立模式,master + worker,启动方式:spark-submit --master spark://s101:7077
3>.yarn
不需要启动任务spark进程,不需要安装spark集群,启动方式如:spark-submit --master yarn | yarn-client | yarn-cluster
.yarn-client
driver运行在client,appmaster只负责请求资源列表。 .yarn-cluster
appmaster除了请求资源列表之外,还要运行driver程序。
三.使用yarn操作步骤
我们需要停止spark集群,只需要安装Spark软件并且启动hadoop集群即可。
四.优化yarn集群配置案例
Spark集群之yarn提交作业优化案例的更多相关文章
- Spark集群的任务提交执行流程
本文转自:https://www.linuxidc.com/Linux/2018-02/150886.htm 一.Spark on Standalone 1.spark集群启动后,Worker向Mas ...
- Spark集群安装和WordCount编写
一.Spark概述 官网:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 为大数据处理而设计的快速通用的计算引擎. Spark加州大学 ...
- spark集群启动步骤及web ui查看
集群启动步骤:先启动HDFS系统,在启动spark集群,最后提交jar到spark集群执行. 1.hadoop启动cd /home/***/hadoop-2.7.4/sbinstart-all.sh ...
- Spark集群模式&Spark程序提交
Spark集群模式&Spark程序提交 1. 集群管理器 Spark当前支持三种集群管理方式 Standalone-Spark自带的一种集群管理方式,易于构建集群. Apache Mesos- ...
- 向Spark集群提交任务
1.启动spark集群. 启动Hadoop集群 cd /usr/local/hadoop/ sbin/start-all.sh 启动Spark的Master节点和所有slaves节点 cd /usr/ ...
- Spark集群搭建(local、standalone、yarn)
Spark集群搭建 local本地模式 下载安装包解压即可使用,测试(2.2版本)./bin/spark-submit --class org.apache.spark.examples.SparkP ...
- Spark 集群 任务提交模式
Spark 集群的模式及提交任务的方式 本文大致的内容图 Spark 集群的两种模式: Standalone 模式 Standalone-client 任务提交方式 提交命令 ./spark-subm ...
- Docker中提交任务到Spark集群
1. 背景描述和需求 数据分析程序部署在Docker中,有一些分析计算需要使用Spark计算,需要把任务提交到Spark集群计算. 接收程序部署在Docker中,主机不在Hadoop集群上.与Spa ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
随机推荐
- 读书笔记(chapter4)
进程调度 4.1多任务 1.多任务系统可以划分为:非抢占式多任务和抢占式多任务: (在此模式下,由调度程序来决定什么时候停止一个进程的运行,以便其他进程能够得到执行机会,这个动作叫抢占: 时间片实际上 ...
- book项目分析
需求1:用户注册 需求如下: 1)访问注册页面 2)填写注册信息,提交给服务器 3)服务器应该保存用户 4)当用户已经存在----提示用户注册 失败,用户名已存在 5)当用户不存在-----注册成功 ...
- docker+redis 持久化配置(AOF)
RDB持久化与AOF持久化简单描述 RDB:RDB使用快照的方式存储数据库中的内容,直接将所有键值对数据全部存入二进制文件.建议使用BGSAVE来进行备份,整个过程会新fork一个子进程来执行,不影响 ...
- [转帖]从 2G 到 5G,手机上网话语权的三次改变
从 2G 到 5G,手机上网话语权的三次改变 美国第一大电信运营商 Verizon 公司的 CEO Hans Vestberg 手持一部 iPad,屏幕上显示俯瞰地面的飞行地图.400 多公里外的洛杉 ...
- Linux初学笔记---关于进程管理等
菜鸟初学: 1. 查看进程用的命令: ps 具体用法 ps -A ro ps -e 显示所有进程 ps -u root 显示root 用户的进程 ps -u root -N 显示非root用户的进程 ...
- Oracle 使用PLSQL 导出 一个表的insert 语句
1. 使用工具 plsql . GUI的方法,如图示 2. 操作界面 3. 然后就看到了插入语句
- 一个简单的Oracle和 SQLSERVER 重建所有表索引的办法
1. SQLSERVER 使用微软自带的存储过程 exec sp_msforeachtable 'DBCC DBREINDEX(''?'')' 2. Oracle的办法: select 'alter ...
- C++ 类的静态成员变量及静态成员函数
ps:下面所说 成员=成员变量+成员函数: 作用 由于对象与对象之间的成员变量是相互独立的.所以要想共用数据,则需要使用静态成员和静态函数. 空间分配 静态成员是在程序编译时分配空间,而在程序结束时释 ...
- 关于linux上文件无法正确显示中文的情况解决
其实有遇到过多次,而且还有几次是css在预编译的时候,系统编码不对也会报错. 贴一个写的还不错的文章:http://www.360doc.com/content/11/0728/09/7102324_ ...
- codeforces 873C - Strange Game On Matrix
题目大意:给你一个n*m的只有0和1的矩阵,找到每列第一个1的位置a[i][j],a[i][j]及其a[min(k,n-i+1][j]中1的数量,每列位置值是1的可以变为0: 解题思路:因为数据较小, ...