python基础之 列表,元组,字典
other
help(str.strip) #查看是否有返回值以及返回值类型
[] :称为索引操作符
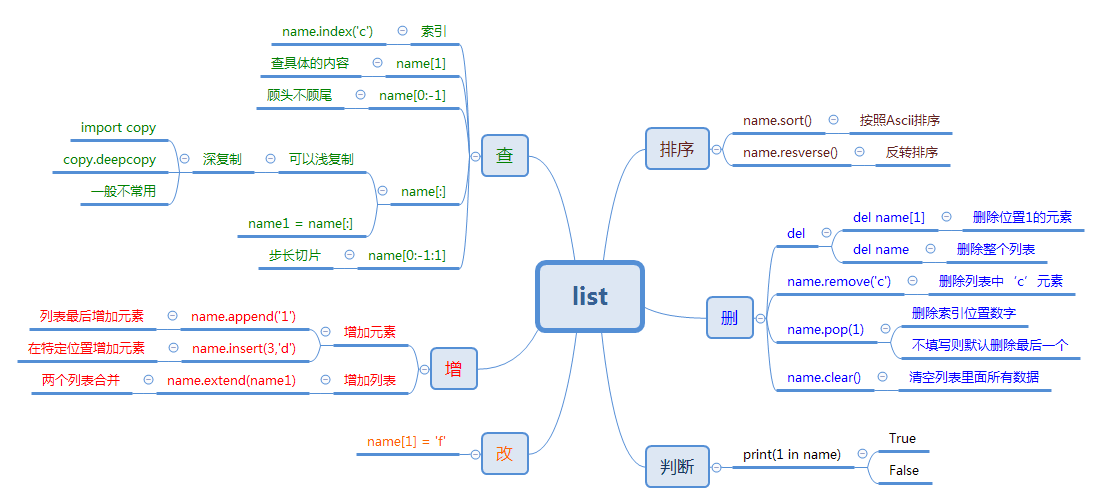
1.列表
列表相比字符串来说能存储大量数据的python的基本数据类型,并且也拥有字符串的一些方法(索引,切片等等)
列表是以[]中括号组成,每个元素以,逗号隔开的,容器型数据类型。
列表中的常见的方法
l1 =['kobe','james','t-mac','',789,[123,'admin']]
索引
print(l1[1])
print(ret1,type(ret1))
print(l1[-1]) 切片 顾头不顾腚
print(l1[:4])
print(l1[:5:2]) 倒叙取值
print(l1[-1:-4:-1]) 增加
l1.append('') #追加增加
l1.insert(1,'') #在索引为1的位置插入
l1.extend([123,'ab']) #迭代的而加入是:根据要添加的类型进行一次迭代之后,在添加到列表中。如果添加的时字符串,就分割之后,添加到列表。
#如果添加的是列表,就循环列表,在分别添加到要添加的列表中。和切片修改是同一个意思,说白了迭代增加的必须是可迭代的元素 删除
l1.pop(0) #按照索引删除,会将删除的元素作为返回值返回
l1.remove('kobe') #按照元素删除,不会返回被删数据
l1.clear() #清空列表 del 删除
del l1[0] #1.按照索引删除,默认删除最后一个
del l1[2:5:2] #按照切片(可以加步长)删除
del l1[:] 或者del l1#删除整个列表 改
l1[0] = "男神" #按索引修改,l1[0]指的时位置,修改l1[0]这个位置的元素的值为男神,本意指的li[0]这个元素,但是放在等号左边就是代表位置,要接受新值
l1[:3] = [123,""]或者l1[:3] ="" #按切片范围修改,要添加的内容必须是可迭代元素,和迭代增加一样
l1[1:4:2] = "" #切片(加步长):必须一一对应,改了几个就得写几个修改的值,不能多或少 查
按照索引(index),按照切片(步长查询),列表没有find方法
使用for循环 其他操作
len():去长度 index():通过元素找索引,找到第一个就返回,找不到就报错
l1.sort() 从小到大排序#不会生成新的字符串 l1.sort(reverse=True) #从大到小
l1.reverse()翻转 #不会生成新的字符串
other:
pop():执行后唯一有返回值的
2.元组
python中基础数据类型之一,容器型数据类型,存储大量的数据。只读列表。
元组是()里面的元素以,隔开的数据类型。
其他语言中,没有元组的概念。元组是不可以进行修改的,只能查询。元组中存储的都是重要的数据,个人信息等等。 元组练习
tu1 = (1,'kobe','',[1,2,'mac',True])
print(tu1[0]) #可以索引
print(tu1[:3]) #可以切片
print(tu1[:4:2]) #可以根据步长切片 查:注意:元组只能查不能改,
#根据索引和切片等进行查询或者#根据for循环
for item in tu1:
print(item) other
del tul print(tu1) #删除元组
print(len(tu1)) #查看元组长度
print(tu1.count("")) #查看包含字符个数
print(tu1.index("kobe") #和列表,字符串中使用一样,查找元素的索引 元组真的不能修改么?
tul = ('', True, 456, [123, 'jordan', '中文'])
tul[3].append('')
print(tul)
#:在元组中的元素的是可迭代对象的话,就可以改:儿子不能改,孙子可能改。
有意思的一个问题:
tu = (123,1,'123',True)
print(tu.index(True))
#这个索引不应该是3么? 因为True和false在内存中存储的是1和0,所以tu.index(True) =tu.index(1),打印这个相当于打印print(tu.index(1))的索引,元组中正好有1这个元素,所以打印1这个元素的索引 #坑
(22) --->int类型,不加,都是元素本身
(s) --->字符串类型
3.range
range函数练习
内置函数,python给你提供的一个功能。
将range视为:可控制范围的数字列表。 #打印1-100
for item in range(1,101):
print(item) #打印1-100奇数
for item in range(1,100,2):
print(item) #打印1-100偶数
for item in range(2,102,2):
print(item)
#打印10-1
for item in range(10,0,-1):
print(item, '', end='') 注意:
1.range()的起始位置默认为0
2.python2中是一起全部生成,不用迭代出来,直接打印,python3中是先放在内存里面,等使用了再生成。(这也是python3比python2性能上高的一点)
作业
# 使用循环查找一个字符串中指定字符的所有索引值, 保存在一个列表中,找出所有a的索引值
s = 'abcabcabc'
count = 0
l1=[]
for item in s:
if item == 'a':
l1.append(s.index('a',count,)) #主要是字符串索引可以通过起始位置和结束位置来查找
else:
pass
count += 1
print (l1)
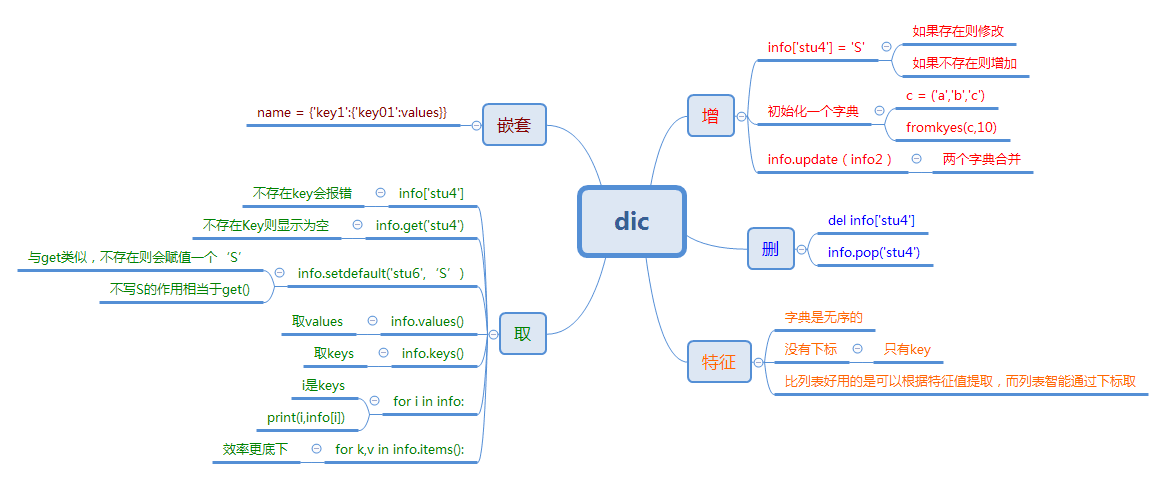
4.字典
为什么要使用元组?
1.列表如果存储的数据较多的话,查询速度会比较慢
2.列表存储数据的关联性不强
字典的查找是根据键值的hash来对应的内存地址进行查找的,比二分法还会快一些
字典介绍:
python中唯一的映射类的数据,花括号{}括起来,他是以键值对形式存储,每一对键值对以,逗号分开!
dic = {'name': 'kobe', 'age': 18, 'sex': 'man'} 字典的特点:
1.字典是以键值对形式存储的,
键:不重复的,唯一的,键的数据类型必须是不可变的数据类型。(键唯一;指的是无论添加多少个相同的键,只有最后一个起作用,起到了覆盖的作用)
值:任意数据类型,对象。
2.字典可以存储大量的键值对数据,
3.python3.6之前:字典是无序的。python3.6之后,字典变成有序的。3.7以后确实从语法层面上变得有序了。(3.6中的有序是解释器的作用,不是python的源码特点)
字典的优点:
1,字典存储大量的关系型数据。
2,字典的查询速度非常快。
字典的缺点:
占用空间大
dic ={
'name':'kobe',
'age':40,
'hobby':'wife'
}
增加操作
1.有就修改,没有就添加,根据键值,不会报错
dic['agesdas1']=20
2.有就不变,没有就添加,根据键值,不会报错
dic.setdefault('h') #默认添加None,默认返回键h的值,有返回值
dic.setdefault('name','123')
删除操作
pop() 删除,按照键删除
dic.pop('name') #按照键值删除,默认删除的键值不存在的话会报错
dic.pop('name','没有此键')#第二个参数为提示语,一般设置成None
clear() 清空
dic.clear()
popitem(): 3.6之前版本随机删除,但是3.6版本删除最后一个键值对,因为python3.6版本之前,dict类型是无序的,在3.6版本之后变成有序的了
ref = dic.popitem() 有返回值,是被删除的键值对组成的元组
del删除
del dic['name'] 按照键删除,如果键值不存在会报错
del dic 删除字典
修改操作
1.dic['age']=73 根据键值来修改,没有键值的话就添加
2.update
a.dic.update(abc="123",bcd="456") #有就覆盖,没有键值就增加
b.dic.update(dic2) #将一个字典添加到另一个字典中,dic1里面有和dic2相同的键值,就将dic1中键所对应值修改成dic2中(将dic2中的键值对覆盖追加到dic中)
update里面的键值不能是数字
查操作
print(dic['age']) 如果不存在键,则报错
print(dic.get('ag')) 如果不存在键,返回nono
print(dic.get('ag',"没有此键")) 可设置返回值
print(setdefault.('1'))
formkeys: 用于创建一个新的字典,并以可迭代对象中的元素分别作为字典中的键,且所有键对应同一个值,默认为None
iterable=[1,2] value='a'
v1 = dict.fromkeys(iterable,value)
iterable: 用于创建新的字典的键的可迭代对象(字符串、列表、元祖、字典)。
value: 可选参数, 字典所有键对应同一个值的初始值,默认为None。
print(v) {'1': 'a', '2': 'a'}
other 其他三个类似列表的类型,都可以转化成list,是高仿list,没有索引
print(dic.keys(),type(dic.keys()))
print(dic.values(),type(dic.values()))
print(dic.items()) #可以使用for循环
for k,y in dic.items():
print(k,y)
分别赋值:a =18,b=32,使用一句代码将其调转
a,b=32,18
print(a,b) #a=32,b=18
a,b={'name':'alex','age':73}
print(a,b) #a=name b=age
a,b =[123,2345]
print(a,b) #a=123 b=2345
原理就是将a和b指向的内存地址的标签调换
5.数据类型的比较
数据类型的划分:
容器非容器划分:
容器型数据类型:list,tuple,dict,set。
非容器型数据类型:int str bool
可变与不可变划分:
可变(不可哈希hash)的数据类型:list dict,set
不可变(可哈希hash的)的数据类型: int bool str tuple
序列类型:
6.字典里习题
#将a和b组合成c的样式,并支持扩展
a = [
'a,1',
'b,3,22',
'c,3,4',
'f,5'
] b=[
'a,2',
'b,4',
'd,2',
'e,12'
] c = [
'a,1,2',
'b,3,22,4',
'c,3,4',
'd,2',
'e,12',
'f,5'
] dic ={i[0]:i for i in a}
print(dic)
for ite in b:
if ite[0] in dic:
# if dic.get(ite[0]):
dic[ite[0]] += ite[1:]
else:
dic[ite[0]] = ite
print(list(dic.values()))
python基础之 列表,元组,字典的更多相关文章
- python的学习笔记01_4基础数据类型列表 元组 字典 集合 其他其他(for,enumerate,range)
列表 定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素 特性: 1.可存放多个值 2.可修改指定索引位置对应的值,可变 3.按照从左到右的顺序定义列表元素,下标从0开始顺序访问 ...
- Python入门基础学习(列表/元组/字典/集合)
Python基础学习笔记(二) 列表list---[ ](打了激素的数组,可以放入混合类型) list1 = [1,2,'请多指教',0.5] 公共的功能: len(list1) #/获取元素 lis ...
- Day2 - Python基础2 列表、字典、集合
Python之路,Day2 - Python基础2 本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1. 列表.元组操作 列表是我们最以后最常用的数据类型之一, ...
- python基础之列表、字典、元祖等 (二)
一.作用域 if 1==1: name = 'weibinf' print name 下面的结论对吗? 外层变量,可以被内层变量使用 内层变量,无法被外层变量使用 二.三元运算 result = 值1 ...
- python基础(五)列表,元组,集合
列表 在python中是由数个有序的元素组成的数据结构,每一个元素对应一个index索引来隐式标注元素在列表中的位置.是python中最常用的一种数据类型.需要注意的是列表中可以有重复相同的数据. 列 ...
- Python基础 之列表、字典、元组、集合
基础数据类型汇总 一.列表(list) 例如:删除索引为奇数的元素 lis=[11,22,33,44,55] #第一种: for i in range(len(lis)): if i%2==1: de ...
- Python 基础-python-列表-元组-字典-集合
列表格式:name = []name = [name1, name2, name3, name4, name5] #针对列表的操作 name.index("name1")#查询指定 ...
- Python初学笔记列表&元组&字典
一.从键盘获取 1 print("请输入") 2 username = input("姓名:") 3 age = input("年龄:") ...
- python中列表 元组 字典 集合的区别
列表 元组 字典 集合的区别是python面试中最常见的一个问题.这个问题虽然很基础,但确实能反映出面试者的基础水平. (1)列表 什么是列表呢?我觉得列表就是我们日常生活中经常见到的清单.比如,统计 ...
- Python基础数据类型-列表(list)和元组(tuple)和集合(set)
Python基础数据类型-列表(list)和元组(tuple)和集合(set) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客使用的是Python3.6版本,以及以后分享的 ...
随机推荐
- 【OpenFOAM案例】02 自己动手
前言:很多人说OpenFOAM很难,要啃上很多的理论书籍,什么流体力学.计算流体力学.矩阵理论.线性代数.数值计算.C++程序设计神马的,看看光这一堆书就能吓倒绝大多数的人.其实我们并不一定要从这些基 ...
- AI习惯的数学书籍、计算机经典书籍
http://download.csdn.net/download/wz619899442/8405297 https://www.amazon.com/Introduction-Automata-T ...
- 【原创 Hadoop&Spark 动手实践 6】Spark 编程实例与案例演示
[原创 Hadoop&Spark 动手实践 6]Spark 编程实例与案例演示 Spark 编程实例和简易电影分析系统的编写 目标: 1. 掌握理论:了解Spark编程的理论基础 2. 搭建 ...
- 【云计算】IaaS、PaaS和SaaS
1. SaaS:Software-as-a-Service(软件即服务) 提供给客户的服务是运营商运行在云计算基础设施上的应用程序,用户可以在各种设备上通过客户端界面访问,如浏览器.消费者不需要管理或 ...
- 【WPF】ImageMagick调节图片的颜色
需求:打开一张图片后,自由调节图片的颜色(色调). 思路:读取显示一张图片后,用ColorPicker取色器选择一种颜色,之后将图片的色调调节为该颜色. 工具: 1.图像工具 ImageMagick( ...
- DatagramSocket(邮递员):对应数据报的Socket概念,不需要创建两个socket,不可使用输入输出流。
UDP编程: DatagramSocket(邮递员):对应数据报的Socket概念,不需要创建两个socket,不可使用输入输出流. DatagramPacket(信件):数据包,是UDP下进行传输数 ...
- 加速Windows 2003关机速度的设置方法
indows 2003是目前版本最高的Windows操作系统,虽然其功能比历史上任何一个版都要强,但是其关机操作却给大家带来了一些小麻烦.其实我们完全可以解除这些麻烦,让关机加速 一.关闭关机事件 ...
- WebViewJavascriptBridge的使用说明
WebViewJavascriptBridge 项目介绍 在Obj-C 和 WKWebView, UIWebView 中的 Javascript之间传送信息的桥梁. 项目地址 如何使用 Javascr ...
- 【静默】Oracle各类响应文件何在?
[静默]Oracle各类响应文件何在? --root用户下执行: find -name *.rsp / 1.创建数据库的响应文件:$ORACLE_HOME/assistants/dbca/dbca. ...
- TensorFlow 1.4利用Keras+Estimator API进行训练和预测
Tensorflow 1.4中,Keras作为作为核心模块可以直接通过tf.keas进行调用,但是考虑到keras对tfrecords文件进行操作比较麻烦,而将keras模型转成tensorflow中 ...