Spark实时案例
1.概述
最近有同学问道,除了使用 Storm 充当实时计算的模型外,还有木有其他的方式来实现实时计算的业务。了解到,在使用 Storm 时,需要编写基于编程语言的代码。比如,要实现一个流水指标的统计,需要去编写相应的业务代码,能不能有一种简便的方式来实现这一需求。在解答了该同学的疑惑后,整理了该实现方案的一个案例,供后面的同学学习参考。
2.内容
实现该方案,整体的流程是不变的,我这里只是替换了其计算模型,将 Storm 替换为 Spark,原先的数据收集,存储依然可以保留。
2.1 Spark Overview
Spark 出来也是很久了,说起它,应该并不会陌生。它是一个开源的类似于 Hadoop MapReduce 的通用并行计算模型,它拥有 Hadoop MapReduce 所具有的有点,但与其不同的是,MapReduce 的 JOB 中间输出结果可以保存在内存中,不再需要回写磁盘,因而,Spark 能更好的适用于需要迭代的业务场景。
2.2 Flow
上面只是对 Spark 进行了一个简要的概述,让大家知道其作用,由于本篇博客的主要内容并不是讲述 Spark 的工作原理和计算方法,多的内容,这里笔者就不再赘述,若是大家想详细了解 Spark 的相关内容,可参考官方文档。[参考地址]
接下来,笔者为大家呈现本案例的一个实现流程图,如下图所示:
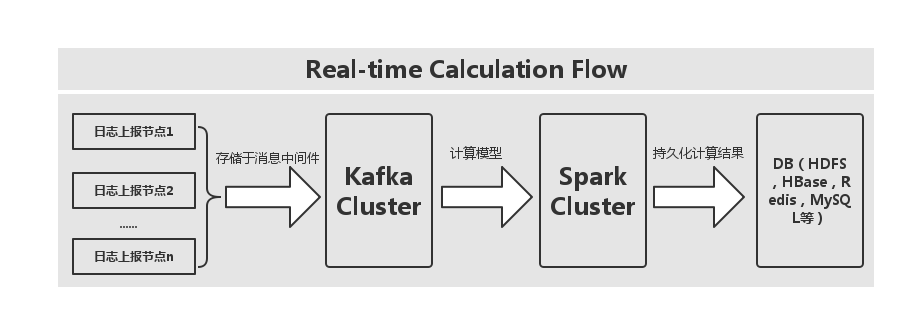
通过上图,我们可以看出,首先是采集上报的日志数据,将其存放于消息中间件,这里消息中间件采用的是 Kafka,然后在使用计算模型按照业务指标实现相应的计算内容,最后是将计算后的结果进行持久化,DB 的选择可以多样化,这里笔者就直接使用了 Redis 来作为演示的存储介质,大家所示在使用中,可以替换该存储介质,比如将结果存放到 HDFS,HBase Cluster,或是 MySQL 等都行。这里,我们使用 Spark SQL 来替换掉 Storm 的业务实现编写。
3.实现
在介绍完上面的内容后,我们接下来就去实现该内容,首先我们要生产数据源,实际的场景下,会有上报好的日志数据,这里,我们就直接写一个模拟数据类,实现代码如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
object KafkaIPLoginProducer { private val uid = Array("123dfe", "234weq","213ssf") private val random = new Random() private var pointer = -1 def getUserID(): String = { pointer = pointer + 1 if (pointer >= users.length) { pointer = 0 uid(pointer) } else { uid(pointer) } } def plat(): String = { random.nextInt(10) + "10" } def ip(): String = { random.nextInt(10) + ".12.1.211" } def country(): String = { "中国" + random.nextInt(10) } def city(): String = { "深圳" + random.nextInt(10) } def location(): JSONArray = { JSON.parseArray("[" + random.nextInt(10) + "," + random.nextInt(10) + "]") } def main(args: Array[String]): Unit = { val topic = "test_data3" val brokers = "dn1:9092,dn2:9092,dn3:9092" val props = new Properties() props.put("metadata.broker.list", brokers) props.put("serializer.class", "kafka.serializer.StringEncoder") val kafkaConfig = new ProducerConfig(props) val producer = new Producer[String, String](kafkaConfig) while (true) { val event = new JSONObject() event .put("_plat", "1001") .put("_uid", "10001") .put("_tm", (System.currentTimeMillis / 1000).toString()) .put("ip", ip) .put("country", country) .put("city", city) .put("location", JSON.parseArray("[0,1]")) println("Message sent: " + event) producer.send(new KeyedMessage[String, String](topic, event.toString)) event .put("_plat", "1001") .put("_uid", "10001") .put("_tm", (System.currentTimeMillis / 1000).toString()) .put("ip", ip) .put("country", country) .put("city", city) .put("location", JSON.parseArray("[0,1]")) println("Message sent: " + event) producer.send(new KeyedMessage[String, String](topic, event.toString)) event .put("_plat", "1001") .put("_uid", "10002") .put("_tm", (System.currentTimeMillis / 1000).toString()) .put("ip", ip) .put("country", country) .put("city", city) .put("location", JSON.parseArray("[0,1]")) println("Message sent: " + event) producer.send(new KeyedMessage[String, String](topic, event.toString)) event .put("_plat", "1002") .put("_uid", "10001") .put("_tm", (System.currentTimeMillis / 1000).toString()) .put("ip", ip) .put("country", country) .put("city", city) .put("location", JSON.parseArray("[0,1]")) println("Message sent: " + event) producer.send(new KeyedMessage[String, String](topic, event.toString)) Thread.sleep(30000) } }} |
上面代码,通过 Thread.sleep() 来控制数据生产的速度。接下来,我们来看看如何实现每个用户在各个区域所分布的情况,它是按照坐标分组,平台和用户ID过滤进行累加次数,逻辑用 SQL 实现较为简单,关键是在实现过程中需要注意的一些问题,比如对象的序列化问题。这里,细节的问题,我们先不讨论,先看下实现的代码,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
object IPLoginAnalytics { def main(args: Array[String]): Unit = { val sdf = new SimpleDateFormat("yyyyMMdd") var masterUrl = "local[2]" if (args.length > 0) { masterUrl = args(0) } // Create a StreamingContext with the given master URL val conf = new SparkConf().setMaster(masterUrl).setAppName("IPLoginCountStat") val ssc = new StreamingContext(conf, Seconds(5)) // Kafka configurations val topics = Set("test_data3") val brokers = "dn1:9092,dn2:9092,dn3:9092" val kafkaParams = Map[String, String]( "metadata.broker.list" -> brokers, "serializer.class" -> "kafka.serializer.StringEncoder") val ipLoginHashKey = "mf::ip::login::" + sdf.format(new Date()) // Create a direct stream val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) val events = kafkaStream.flatMap(line => { val data = JSONObject.fromObject(line._2) Some(data) }) def func(iter: Iterator[(String, String)]): Unit = { while (iter.hasNext) { val item = iter.next() println(item._1 + "," + item._2) } } events.foreachRDD { rdd => // Get the singleton instance of SQLContext val sqlContext = SQLContextSingleton.getInstance(rdd.sparkContext) import sqlContext.implicits._ // Convert RDD[String] to DataFrame val wordsDataFrame = rdd.map(f => Record(f.getString("_plat"), f.getString("_uid"), f.getString("_tm"), f.getString("country"), f.getString("location"))).toDF() // Register as table wordsDataFrame.registerTempTable("events") // Do word count on table using SQL and print it val wordCountsDataFrame = sqlContext.sql("select location,count(distinct plat,uid) as value from events where from_unixtime(tm,'yyyyMMdd') = '" + sdf.format(new Date()) + "' group by location") var results = wordCountsDataFrame.collect().iterator /** * Internal Redis client for managing Redis connection {@link Jedis} based on {@link RedisPool} */ object InternalRedisClient extends Serializable { @transient private var pool: JedisPool = null def makePool(redisHost: String, redisPort: Int, redisTimeout: Int, maxTotal: Int, maxIdle: Int, minIdle: Int): Unit = { makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle, true, false, 10000) } def makePool(redisHost: String, redisPort: Int, redisTimeout: Int, maxTotal: Int, maxIdle: Int, minIdle: Int, testOnBorrow: Boolean, testOnReturn: Boolean, maxWaitMillis: Long): Unit = { if (pool == null) { val poolConfig = new GenericObjectPoolConfig() poolConfig.setMaxTotal(maxTotal) poolConfig.setMaxIdle(maxIdle) poolConfig.setMinIdle(minIdle) poolConfig.setTestOnBorrow(testOnBorrow) poolConfig.setTestOnReturn(testOnReturn) poolConfig.setMaxWaitMillis(maxWaitMillis) pool = new JedisPool(poolConfig, redisHost, redisPort, redisTimeout) val hook = new Thread { override def run = pool.destroy() } sys.addShutdownHook(hook.run) } } def getPool: JedisPool = { assert(pool != null) pool } } // Redis configurations val maxTotal = 10 val maxIdle = 10 val minIdle = 1 val redisHost = "dn1" val redisPort = 6379 val redisTimeout = 30000 InternalRedisClient.makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle) val jedis = InternalRedisClient.getPool.getResource while (results.hasNext) { var item = results.next() var key = item.getString(0) var value = item.getLong(1) jedis.hincrBy(ipLoginHashKey, key, value) } } ssc.start() ssc.awaitTermination() }}/** Case class for converting RDD to DataFrame */case class Record(plat: String, uid: String, tm: String, country: String, location: String)/** Lazily instantiated singleton instance of SQLContext */object SQLContextSingleton { @transient private var instance: SQLContext = _ def getInstance(sparkContext: SparkContext): SQLContext = { if (instance == null) { instance = new SQLContext(sparkContext) } instance }} |
我们在开发环境进行测试的时候,使用 local[k] 部署模式,在本地启动 K 个 Worker 线程来进行计算,而这 K 个 Worker 在同一个 JVM 中,上面的示例,默认使用 local[k] 模式。这里我们需要普及一下 Spark 的架构,架构图来自 Spark 的官网,[链接地址]
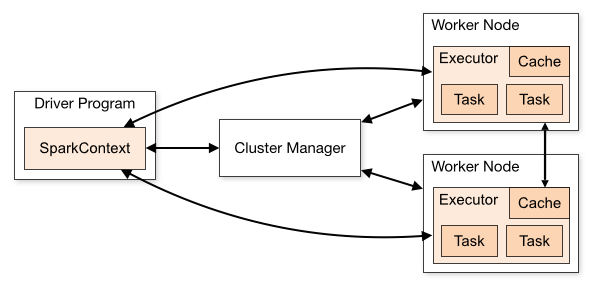
这里,不管是在 local[k] 模式,Standalone 模式,还是 Mesos 或是 YARN 模式,整个 Spark Cluster 的结构都可以用改图来阐述,只是各个组件的运行环境略有不同,从而导致他们可能运行在分布式环境,本地环境,亦或是一个 JVM 实利当中。例如,在 local[k] 模式,上图表示在同一节点上的单个进程上的多个组件,而对于 YARN 模式,驱动程序是在 YARN Cluster 之外的节点上提交 Spark 应用,其他组件都是运行在 YARN Cluster 管理的节点上的。
而对于 Spark Cluster 部署应用后,在进行相关计算的时候会将 RDD 数据集上的函数发送到集群中的 Worker 上的 Executor,然而,这些函数做操作的对象必须是可序列化的。上述代码利用 Scala 的语言特性,解决了这一问题。
4.结果预览
在完成上述代码后,我们执行代码,看看预览结果如下,执行结果,如下所示:
4.1 启动生产线程

4.2 Redis 结果预览

5.总结
整体的实现内容不算太复杂,统计的业务指标,这里我们使用 SQL 来完成这部分工作,对比 Storm 来说,我们专注 SQL 的编写就好,难度不算太大。可操作性较为友好。
Spark实时案例的更多相关文章
- 常见的七种Hadoop和Spark项目案例
常见的七种Hadoop和Spark项目案例 有一句古老的格言是这样说的,如果你向某人提供你的全部支持和金融支持去做一些不同的和创新的事情,他们最终却会做别人正在做的事情.如比较火爆的Hadoop.Sp ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- 【原创 Hadoop&Spark 动手实践 13】Spark综合案例:简易电影推荐系统
[原创 Hadoop&Spark 动手实践 13]Spark综合案例:简易电影推荐系统
- Spark 实时计算整合案例
1.概述 最近有同学问道,除了使用 Storm 充当实时计算的模型外,还有木有其他的方式来实现实时计算的业务.了解到,在使用 Storm 时,需要编写基于编程语言的代码.比如,要实现一个流水指标的统计 ...
- Spark - 经典案例
初识 Spark 大数据处理,目前还只是小白阶段,初步搭建起运行环境,慢慢学习之. 本文熟悉下 Spark 数据处理的几个经典案例. 首先将 Scala SDK 的源码导入 IDEA,方便查看和调试代 ...
- 大数据学习——spark运营案例
iplocation需求 在互联网中,我们经常会见到城市热点图这样的报表数据,例如在百度统计中,会统计今年的热门旅游城市.热门报考学校等,会将这样的信息显示在热点图中. 因此,我们需要通过日志信息(运 ...
- 【spark 算子案例】
package spark_example01; import java.io.File; import java.io.FileWriter; import java.io.IOException; ...
- Hive、Spark优化案例
一.Join原则 将条目少的表/子查询放在Join的左边.原因:在Join的reduce阶段,位于Join左边的表的内容会被加载进内存,条目少的表放在左边,可以减少发生内存溢出的几率. 小表关联大表: ...
- spark实时计算性能优化
1. 计算提供两种模式,一种是jar包本地计算.一种是JSF服务. 2. 第一步是引入spark,因与netty.JDQ均有冲突,解决netty冲突后,隔离计算为单独服务.已在线上,因storm也 ...
随机推荐
- JQuery DataTables Selected Row
获取单行选中的值 $('#MonitoringTypeTable tbody').on('click', 'tr', function () { if ($(this).hasClass('selec ...
- git clone 后误删除了分离出来的文件怎么恢复?
git clone 后,会分离出项目的文件. 误删除了,可以使用以下命令恢复: #先检查一下git状态 git status #通过如下命令重新分离出文件 git checkout -f HEAD
- (原)ffmpeg过滤器开发和理解
最近学习了ffmpeg关于filter过滤器的开发,关于中间的几个相关概念,我们先放在简单介绍一下: AVFilterGraph:几乎完全等同与directShow中的fitlerGraph,代表一串 ...
- 阻止a链接跳转方法总结
总结下a标签阻止默认行为的几种简单方法(1) <a href="javascript:void(0);" > 点我 </a> onclick方法负责执行js ...
- 学习Vue 入门到实战——学习笔记
闲聊: 自从进了现在的公司,小颖就再没怎么接触vue了,最近不太忙,所以想再学习下vue,就看了看vue相关视频,顺便做个笔记嘻嘻. 视频地址:Vue 入门到实战1.Vue 入门到实战2 学习内容: ...
- 在VS中为C/C++源代码文件生成对应的汇编代码文件(.asm)
以VS2017为例 然后重新生成工程,在工程目录中就会有对应的汇编代码文件.
- nfs文件共享服务
文件共享服务端10.100.1.13: yum install -y rpcbind nfs-utils #rpcbind可以给nfs开多个端口 service rpcbind start serv ...
- 23.react-router 路由
箭头函数扩展: 箭头函数: functoin 函数名(参数){ 函数体 } 箭头函数: 1.把function删掉 , 2.参数和{}之间加上 箭头=> 简写: 1.参数的简写:只有一个参 ...
- Java之JVM监控工具分享
Java之JVM监控工具分享 JVM的基本知识常用的也就是类加载机制,内存区域.分配.OOM,GC,JVM参数调优 几个链接自己看: 内存区域&类加载机制 分配策略&垃圾回收算法.收集 ...
- vue中的图标字体引入
网址:https://icomoon.io/app/#/select: 特点:样式多,免费 操作: 1.相中的,随便点,不要钱,generat fonts然后download,得到一个压缩文件,解压, ...