FlumeNG 笔记
环境:CentOS6.6 64位 + FlumeNG 1.6
请参考推荐文档:
Flume-ng的原理和使用 - JunezChen Blog - SegmentFault https://segmentfault.com/a/1190000002532284
已经很全面了,没必要自己写一份文档,更多内容可以参考Flume安装包里doc目录下的自带文档
一、安装
注意:需要预先安装JDK,因为flume是基于Java的;
Flume是没有高可用HA的,但是可以使用拦截器、渠道选择器等高级组件实现负载均衡等功能;
Flume经常和Kafka配合使用。
1、下载并解压FlumeNG
- [root@root ~]# wget http://124.205.69.169/files/A1540000011ED5DB/mirror.bit.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
- [root@root ~]# tar -zxvf apache-flume-1.6.-bin.tar.gz -C /opt/
- [root@root ~]# cd /opt/
- [root@root opt]# mv apache-flume-1.6.-bin apache-flume
2、修改环境变量、启动
- [root@root opt]# cd apache-flume/
- [root@root apache-flume]# cp conf/flume-env.sh.template conf/flume-env.sh
- [root@crxy99 apache-flume]# vim conf/flume-env.sh #修改JAVA_HOME
- 23行: export JAVA_HOME=/opt/jdk1..0_45
- [root@crxy99 apache-flume]# vim conf/example.conf #创建agent模板配置文件
- [root@crxy99 apache-flume]# bin/flume-ng agent --conf conf/ --conf-file conf/example.conf --name a1 -Dflume.monitoring.type=http -Dflume.monitoring.port= -Dflume.root.logger=INFO,console & #启动脚本
补充:
1)、模板example.conf:
- #配置一个agent 名字为a1
- #声明这个agent的三个组件 sources 有一个r1,sinks 包含一个 k1,channels包含一个c1
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1
- # 配置r1 使用netcat的source
- a1.sources.r1.type = netcat
- a1.sources.r1.bind = localhost
- a1.sources.r1.port =
- # 配置k1 使用loggersink
- a1.sinks.k1.type = logger
- # 配置c1 使用内存的channel
- a1.channels.c1.type = memory
- a1.channels.c1.capacity =
- a1.channels.c1.transactionCapacity =
- #连线,将三个组件关联起来
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
2)、启动脚本的含义:
agent 使用agent数据处理方式
- -Dflume.root.logger=INFO,console -D后面的为参数,这里使用打印到控制台的方式,并动态修改log4j的为info级别
3)、关闭服务:
- [root@root apache-flume]# jps
- Jps
- Application
- [root@root apache-flume]# kill - #flume目前没有关闭服务的脚本,只能kill
4)、补充:Telnet
在测试、学习阶段可以使用telnet工具进行模拟,linux下安装方式(Windows下自带了Telnet服务,启用即可,可以百度相关文档)
- # yum -y install telnet
二、实例
实例1:一个需求:实时监听一个文件(如/test/logs/access.log)的数据增加
分析:1、由于agent方式能提供持续传输数据的服务,因此采用agent数据处理方式;
2、agent组件:source --> channel --> sink
3、动态监控文件的数据的增加情况可以使用命令tail -F 命令(注意不是tail -f,后者不会retry),因此可以使用exec sink
4、假设内存情况是充裕的,不予考虑,采用memory channel
5、假设数据发送到本地:file roll sink
如下图所示(开发过程中画图可以很好的理解项目数据采集流程,推荐使用):
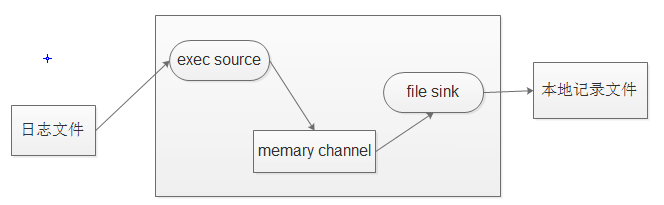
因此:编写agent配置文件:
- #配置一个agent 名字为a1
- #、声明这个agent的三个组件 sources 有一个r1,sinks 包含一个 k1,channels包含一个c1
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1
- #、配置r1 使用exec的source
- a1.sources.r1.type = exec
- a1.sources.r1.command = tail -F /test/logs/access.log
- # 配置c1 使用file的channel
- a1.channels.c1.type = file
- a1.channels.c1.checkpointDir = /test/flume_checkpoint #检查点数据存放目录
- a1.channels.c1.dataDirs = /test/flume_datadir #数据存储目录
- a1.channels.c1.transactionCapacity =
- # 配置k1 使用file rolling sink
- a1.sinks.k1.type = file_roll
- a1.sinks.k1.sink.directory = /test/flumefile #文件存放目录
- a1.sinks.k1.sink.rollInterval = #每天产生一个新文件(单位:s)
- #、连线,将三个组件关联起来
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
启动flume:
- $ nohup bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/execsource_filerollsink.conf &
注:flume进程启动动没有关闭的命令,只能kill掉。:
实战2:若上面的文件在某一时刻出现高并发的情况,flume很容易挂掉,如何处理?
说明:在高并发情况下,若不更改默认配置,flume容易出现内存溢出的错误。这是因为它默认的堆初始内存只有20M,可以编辑环境变量
# vim conf/flume-env.sh,去掉下面一行注释的设置,并根据需要调整初始内存和最大分配内存。
- export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
注:20M源于/bin/flume-ng里的默认设置:JAVA_OPTS="-Xmx20m"
参考:Flume 1.6.0 User Guide — Apache Flume http://flume.apache.org/FlumeUserGuide.html
注:解压后的flume目录下有docs目录,下面的说明文档与该官网的一致,非常人性化!
FlumeNG 笔记的更多相关文章
- Flume-ng+Kafka+storm的学习笔记
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- 即将上线的flume服务器面临的一系列填坑笔记
即将上线的flume服务器面临的一系列填坑笔记 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.flume缺少依赖包导致启动失败! 报错信息如下: 2018-10-17 ...
- Spark Streaming笔记
Spark Streaming学习笔记 liunx系统的习惯创建hadoop用户在hadoop根目录(/home/hadoop)上创建如下目录app 存放所有软件的安装目录 app/tmp 存放临时文 ...
- Kafka笔记整理(一)
Kafka简介 消息队列(Message Queue) 消息 Message 网络中的两台计算机或者两个通讯设备之间传递的数据.例如说:文本.音乐.视频等内容. 队列 Queue 一种特殊的线性表(数 ...
- spark streaming 笔记
spark streaming项目 学习笔记 为什么要flume+kafka? 生成数据有高峰与低峰,如果直接高峰数据过来flume+spark/storm,实时处理容易处理不过来,扛不住压力.而选用 ...
- git-简单流程(学习笔记)
这是阅读廖雪峰的官方网站的笔记,用于自己以后回看 1.进入项目文件夹 初始化一个Git仓库,使用git init命令. 添加文件到Git仓库,分两步: 第一步,使用命令git add <file ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- SQL Server技术内幕笔记合集
SQL Server技术内幕笔记合集 发这一篇文章主要是方便大家找到我的笔记入口,方便大家o(∩_∩)o Microsoft SQL Server 6.5 技术内幕 笔记http://www.cnbl ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
随机推荐
- Sybase_游标
本章将介绍如何在Sybase下使用游标 因业务需要,要批量处理一些数据,sql需要用到循环,所以要使用游标,我写了一个简单的游标,sql如下 DECLARE my_Cursor CURSOR FOR ...
- Yii 开发微信 '您提交的数据无法被验证'
使用Yii开发微信时,出现 [error][yii\web\HttpException:] exception 'yii\web\BadRequestHttpException' with messa ...
- Mac配置PHP
前言 在MacOS中已经内置了PHP和Apache,所以不需要再额外安装它们,只需要简单几步即可运行PHP. 配置Apache 查看Apache版本: $ sudo apachectl -v 终端关闭 ...
- ACM 中 矩阵数据的预处理 && 求子矩阵元素和问题
我们考虑一个$N\times M$的矩阵数据,若要对矩阵中的部分数据进行读取,比如求某个$a\times b$的子矩阵的元素和,通常我们可以想到$O(ab)$的遍历那个子矩阵,对它的各 ...
- Linux进程学习
进程与进程管理: 清屏:system("clear"); //#include <signal.h> 进程环境与进程属性: 什么是进程:简单的说,进程就是程序的一次执行 ...
- [LeetCode] Shortest Word Distance 最短单词距离
Given a list of words and two words word1 and word2, return the shortest distance between these two ...
- Redis初识、设计思想与一些学习资源推荐
一.Redis简介 1.什么是Redis Redis 是一个开源的使用ANSI C 语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value 数据库,并提供多种语言的API.从2010 年 ...
- 使用C#把发表的时间改为几年前,几个月,几天前,几小时前,几分钟前,或几秒前
我们在评论中往往会看到多少天前,多少小时前. 实现原理:现在时间-过去时间 得到的时间差来做比较 下面我定义了一个Helper类,大家直接引用即可,参数就是时间差,注意时间差类型是TimeSpan类型 ...
- setTimeout和setInterval从入门到精通
我们在日常web前端开发中,经常需要用到定时器方法. 前端中的定时器方法是浏览器提供的,并不是ECMAScript规范中的.是window对象的方法. 浏览器中的定时器有两种, 一种是每间隔一定时间执 ...
- Beta版本冲刺计划及安排
经过紧张的Alpha阶段,很多组已经从完全不熟悉语言和环境,到现在能够实现初步的功能.下一阶段即将加快编码进度,完成系统功能.强化软件工程的体会.Beta阶段的冲刺时间为期七天,安排在2016.12. ...