【待补充】[HDFS_3] HDFS 工作机制
0. 说明
HDFS 初始化文件系统分析 && HDFS 文件写入流程 && HDFS 文件读取流程分析
有价值的相关文章:
1. HDFS 初始化文件系统分析
- 通过两个配置文件 core-site.xml 和 core-default.xml 初始化 configuration
- 通过配置文件中的 fs.defaultFS 指定的值初始化文件系统
file:/// =====> org.apache.hadoop.hdfs.LocalFileSystem
hdfs://xxxx =====> org.apache.hadoop.hdfs.DistributedFileSystem
2. HDFS 文件写入流程分析一
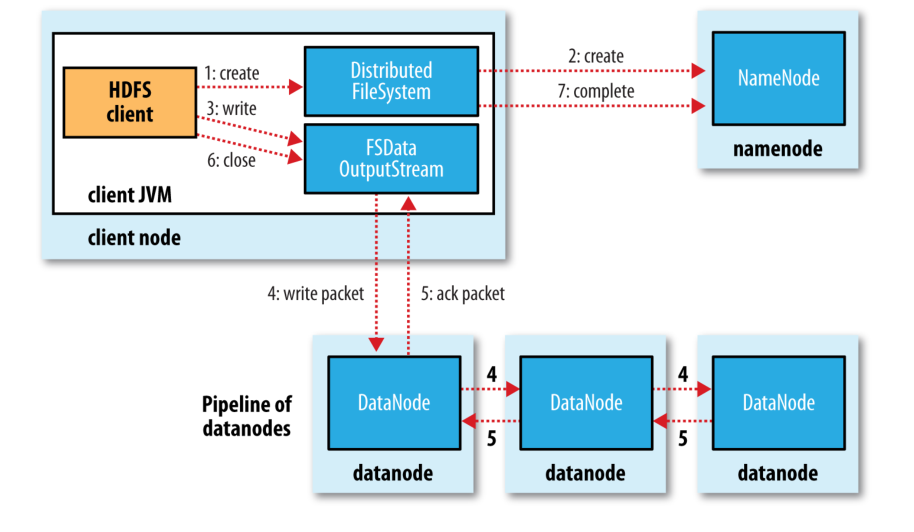
具体过程描述如下:
1. Client 调用 DistributedFileSystem 对象的 create 方法,创建一个文件输出流(FSDataOutputStream)对象
2. 通过 DistributedFileSystem 对象与 Hadoop 集群的 NameNode 进行一次 RPC 远程调用,在 HDFS 的 Namespace 中创建一个文件条目(Entry),该条目没有任何的 Block
3. 通过 FSDataOutputStream 对象,向 DataNode 写入数据,数据首先被写入 FSDataOutputStream 对象内部的 Buffer 中,然后数据被分割成一个个 Packet 数据包
4. 以 Packet 最小单位,基于 Socket 连接发送到按特定算法选择的 HDFS 集群中一组 DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组 DataNode 组成的 Pipeline 上依次传输 Packet
5. 这组 DataNode 组成的 Pipeline 反方向上,发送ack,最终由Pipeline 中第一个 DataNode 节点将 Pipeline ack 发送给 Client
6. 完成向文件写入数据,Client 在文件输出流(FSDataOutputStream)对象上调用 close 方法,关闭流
7. 调用 DistributedFileSystem 对象的 complete 方法,通知 NameNode 文件写入成功
3. HDFS 文件写入流程另一种描述
客户端要向 HDFS 写数据,首先要跟 NameNode 通信以确认可以写文件并获得接收文件 block 的 DataNode,然后,客户端按顺序将文件逐个 block 传递给相应 DataNode ,并由接收到 block 的 DataNode 负责向其他 DataNode 复制 block 的副本
如图:
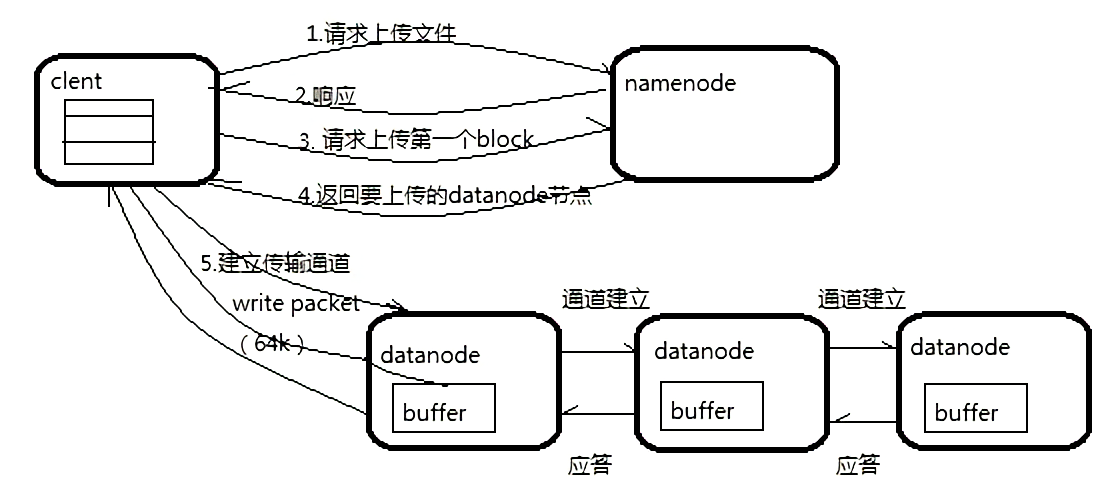
写详细步骤:
1. Client 与 NameNode 通信请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在
2. NameNode 返回是否可以上传
3. Client 会先对文件进行切分,比如一个 block 块 128m,文件有 300m 就会被切分成3个块,一个 128M、一个 128M、一个 44M 请求第一个 block 该传输到哪些 DataNode 服务器上
4. NameNode返回 DataNode 的服务器
5. Client 请求一台 DataNode 上传数据(本质上是一个 RPC 调用,建立 Pipeline),第一个 DataNode 收到请求会继续调用第二个 DataNode,然后第二个调用第三个 DataNode,将整个 Pipeline建立完成,逐级返回客户端
6. Client 开始往A上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(一个 packet 为64kb),当然在写入的时候 DataNode 会进行数据校验,它并不是通过一个 packet 进行一次校验而是以 chunk 为单位进行校验(512byte),第一台 DataNode 收到一个 packet 就会传给第二台,第二台传给第三台;第一台每传一个 packet 会放入一个应答队列等待应答
7. 当一个 block 传输完成之后,Client 再次请求 NameNode 上传第二个 block 的服务器。
4. HDFS 文件写入流程详情图
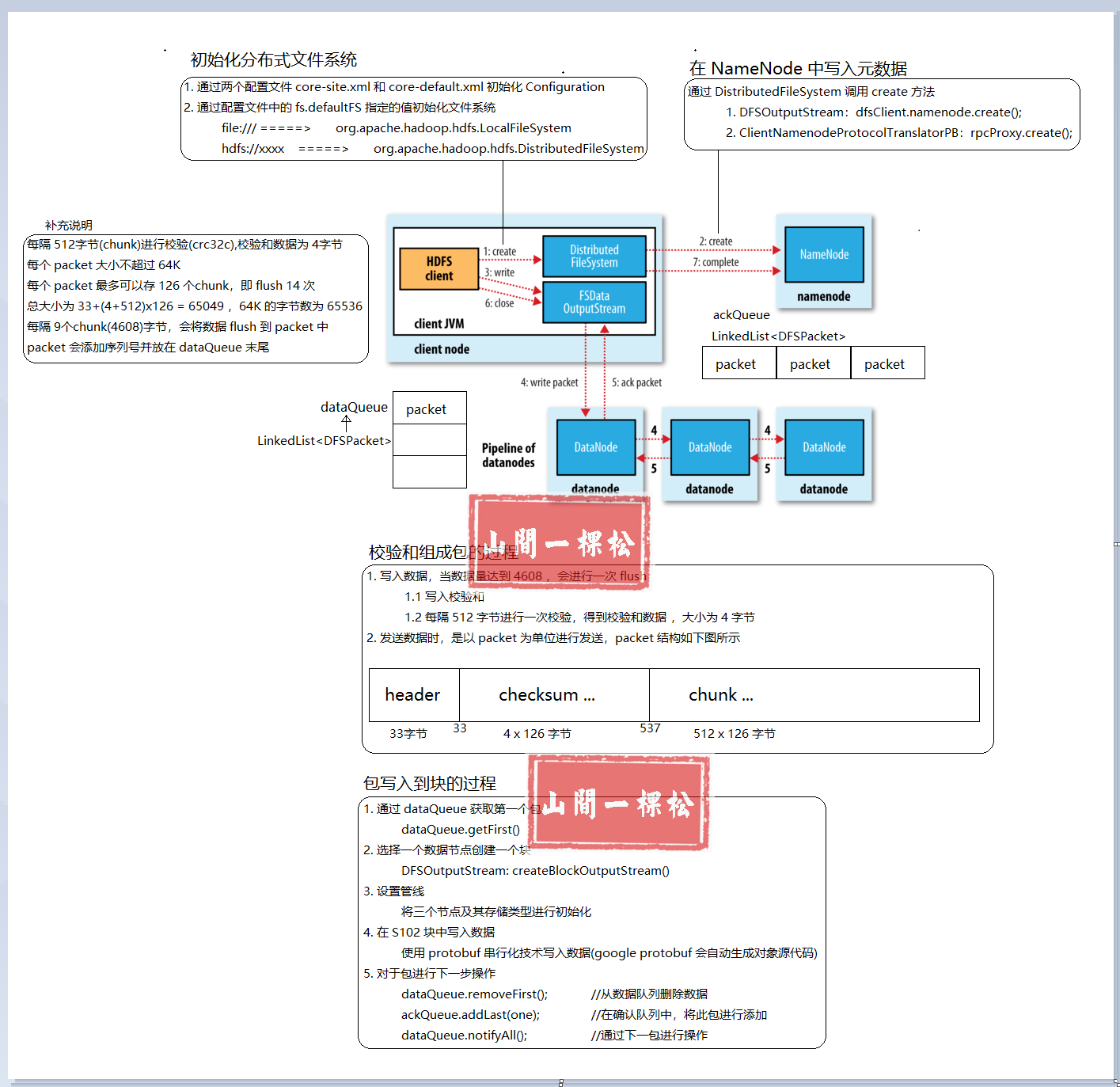
【相关概念】
1. chunk
小块
2. packet
基础数据会分割成很多个 packet 通过数据队列进行数据发送
包 = (小块+校验和)x126
3. HDFS 中 packet 的结构如下

4. checksum
默认校验和是 CRC32C 算法
每隔512字节进行校验,同时产生4字节的校验和
5. HDFS 文件读取流程分析
客户端将要读取的文件路径发送给 NameNode , NameNode 获取文件的元信息(主要是 block 的存放位置信息)返回给客户端,客户端根据返回的信息找到相应 DataNode逐个获取文件的 block 并在客户端本地进行数据追加合并从而获得整个文件
如图:
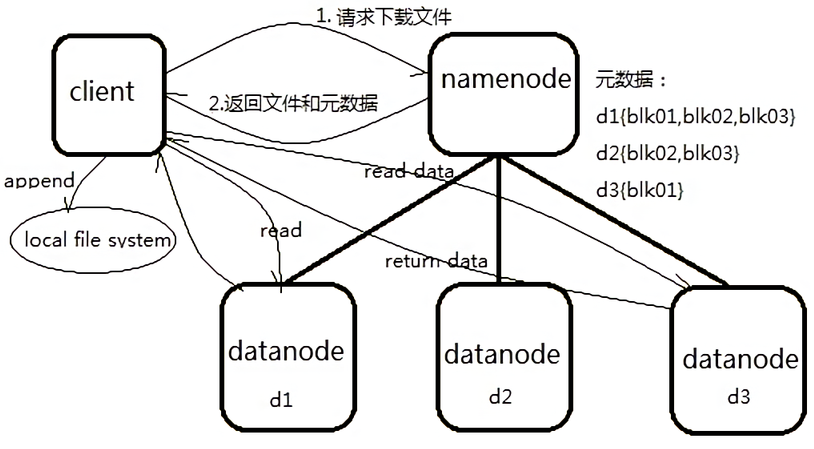
读详细步骤:
1. Client 与 NameNode 通信查询元数据( block 所在的 DataNode 节点),找到文件块所在的 DataNode 服务器
2. 挑选一台 DataNode (就近原则,然后随机)服务器,请求建立socket流
3. DataNode 开始发送数据(从磁盘里面读取数据放入流,以 packet 为单位来做校验)
4. 客户端以 packet 为单位接收,先在本地缓存,然后写入目标文件,后面的 block 块就相当于是 append 到前面的 block 块最后合成最终需要的文件。
【待补充】[HDFS_3] HDFS 工作机制的更多相关文章
- 深刻理解HDFS工作机制
深入理解一个技术的工作机制是灵活运用和快速解决问题的根本方法,也是唯一途径.对于HDFS来说除了要明白它的应用场景和用法以及通用分布式架构之外更重要的是理解关键步骤的原理和实现细节.在看这篇博文之前需 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
- 7.hdfs工作流程及机制
1. hdfs基本工作流程 1. hdfs初始化目录结构 hdfs namenode -format 只是初始化了namenode的工作目录 而datanode的工作目录是在datanode启动后自己 ...
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
- HDFS中DataNode工作机制
1.DataNode工作机制 1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳). 2)DataNod ...
- HDFS中NameNode和Secondary NameNode工作机制
NameNode工作机制 0)启动概述 Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作.一旦在内存中成功建立文件系统元数据的映像,则创建一个 ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
随机推荐
- 微服务架构集大成者—Spring Cloud (转载)
软件是有生命的,你做出来的架构决定了这个软件它这一生是坎坷还是幸福. 本文不是讲解如何使用Spring Cloud的教程,而是探讨Spring Cloud是什么,以及它诞生的背景和意义. 1 背景 2 ...
- Xcode 8.X Command Line Tools
Summary Step 1. Upgrade Your System to macOS Sierra Step 2. Open the Terminal Application Step 3. Is ...
- flask 压缩json
这样返回的json会被压缩
- linux有名管道fifo,进程间通信
命名管道(FIFO)不同于无名管道之处在于它提供了一个路径名与之关联,以 FIFO 的文件形式存在于文件系统中,这样,即使与 FIFO 的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通 ...
- leetcode — regular-expression-matching
/** * Source : https://oj.leetcode.com/problems/regular-expression-matching/ * * Created by lverpeng ...
- this引用逃逸
1.什么是This逃逸? 在构造器构造还未彻底完成前(即实例初始化阶段还未完成),将自身this引用向外抛出并被其他线程复制(访问)了该引用,可能会问到该还未被初始化的变量,甚至可能会造成更大严重的问 ...
- [转]Oracle密码过期, 报:ORA-01017: 用户名/口令无效; 登录被拒绝
本文转自:https://blog.csdn.net/jeff06143132/article/details/25696371 连接Oracle,以Oracle用户登陆: $su - oracl ...
- 将代码从 spark 1.x 移植到 spark 2.x
1. SparkSession sparkSession可以视为sqlContext和hiveContext以及StreamingContext的结合体,这些Context的API都可以通过spark ...
- [PHP] 数据结构-输出链表倒数第k个结点PHP实现
输入一个链表,输出该链表中倒数第k个结点.第一个指针走(k-1)步,到达第k个节点,两个指针同时往后移动,当第一个结点到达末尾的时候,第二个结点所在位置就是倒数第k个节点了 <?php clas ...
- 服务器端事件发送SSE
背景 近期有这么一个需求: 手机端需要展示一个比较大的pdf 基于手机端网络/流量/体验等考虑,希望不通过pdf下载然后展示 而是把pdf转成一张张的图片,然后再在手机上展示. 分析 pdf转图片,肯 ...