《linux内核设计与实现》第三章
1.进程
进程就是正在执行的程序代码的实时结果,不仅包含可执行代码,还包括其他资源,比如:打开的文件,挂起的信号,内核内部数据结构,处理器状态,一个或多个具有内存映射的内存地址空间及一个或多个执行线程,全局变量数据段等。
内核需要有效而透明的管理所有细节。
线程,每个线程拥有一个独立的程序计数器,进程栈和一组寄存器。内核调度对象是线程而不是进程。
现代操作系统提供两种虚拟机制:虚拟处理器和虚拟内存,线程之间可以共享虚拟内存,但每个都有各自的虚拟处理器。
Linux中,新进程是由fork()来实现的,fork()实际上由clone()系统调用实现,程序通过exit()系统调用退出执行,这个函数会终结进程并释放其占用的资源,父进程可以通过wait4()查询子进程是否终结。进程退出执行后被设置为僵死状态,直到他父进程调用wait()或waitpid()。
2.进程描述符
内核把进程的列表存放在一个叫做任务队列的双向环形链表中,链表中每一项(task_struct类型)都称为进程描述符。
进程描述符包括一个进程的具体所有信息:打开的文件,进程地址空间,挂起的信号,进程状态等。在中定义。
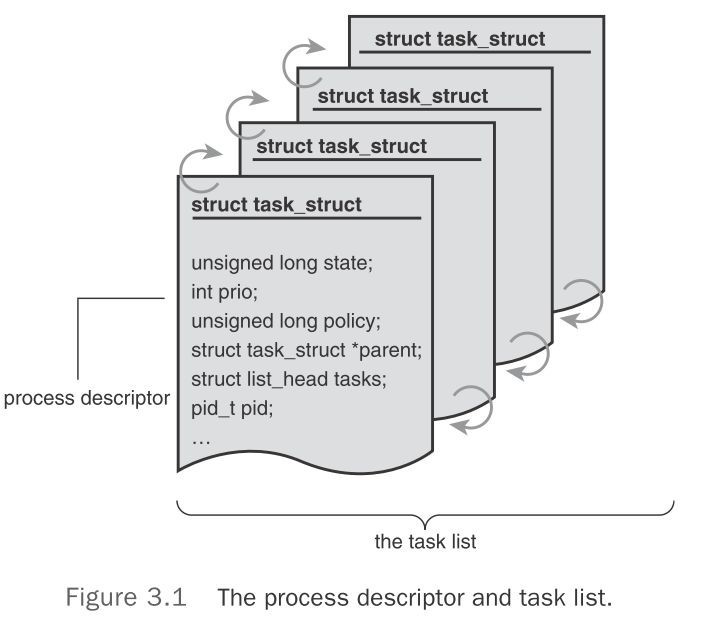
Linux通过slab分配器分配task_struct结构,这样能达到对象复用和缓存目的。
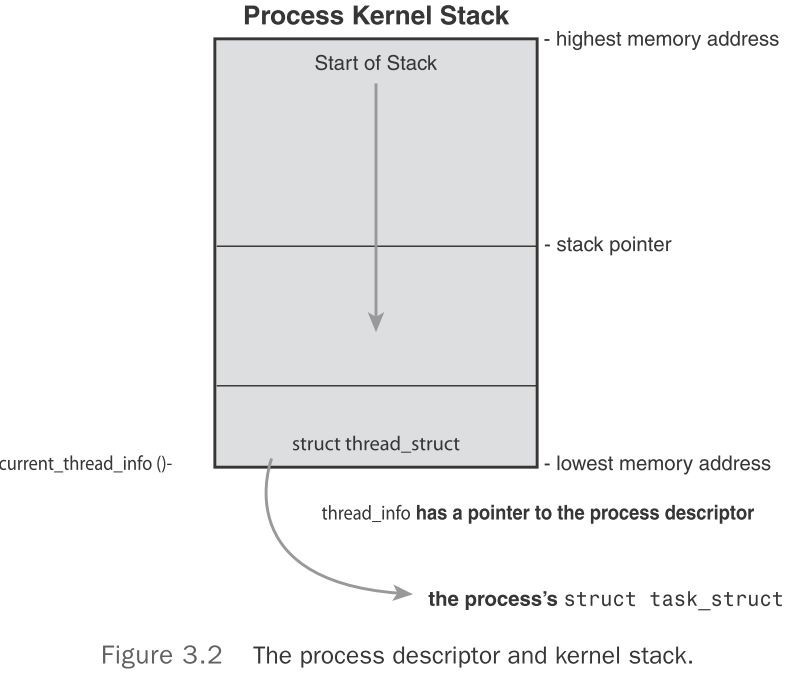
Linux在栈底或栈顶创建一个新的结构struct thread_info来存放task_struct
- struct thread_info {
- struct task_struct *task;
- struct exec_domain *exec_domain;
- __u32 flags;
- __u32 status;
- __u32 cpu;
- int preempt_count;
- mm_segment_t addr_limit;
- struct restart_block restart_block;
- void *sysenter_return;
- int uaccess_err;
- };
3.进程状态
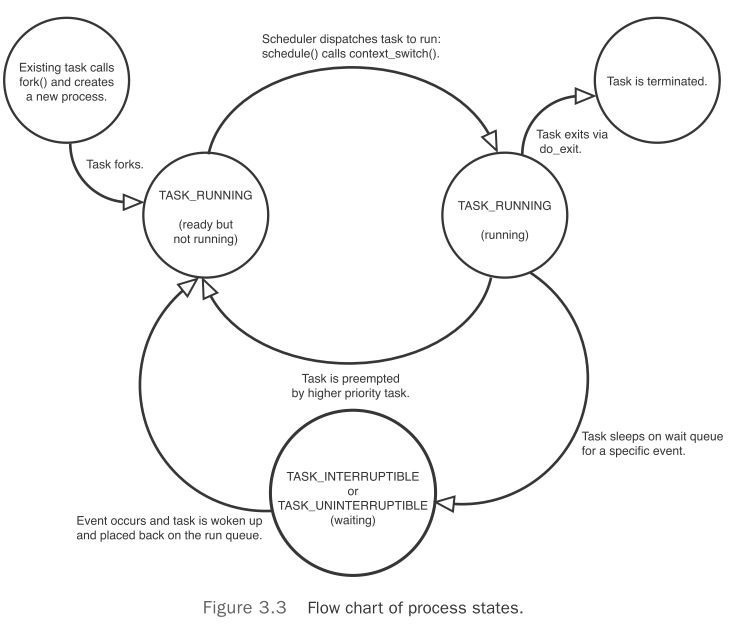
task_struct中的state域描述了进程的当前状态,每个进程必处于以下5个状态之一。
TASK_RUNNING—进程是可执行的,正在执行或者在运行队列中等待执行
TASK_INTERRUPTIBLE—进程正在睡眠(阻塞),等待某个条件达成。该条件一旦到来就进入TASK_RUNNING状态,可以接收信号而提前唤醒。
TASK_UNINTERRUPTIBLE—除了不能响应信号,与TASK_INTERRUPTIBLE一样,这个状态,进程必须在等待时不受干扰或等待事件很快就会发生时出现。
__TASK_TRACED—被其他进程跟踪的进程,比如通过ptrace对调试程序进行跟踪
__TASK_STOPPED—停止。进程没有投入运行,也不能投入运行。这种情况一般发生在进程收到SIGSTOP,SIGTSTP,SIGTTIN,SIGTTOU等信号的时候,此外在调试期间接收到任何信号,都会使进程进入这种状态
设置进程,set_task_state(task,state),必要的时候,它会设置内存屏蔽来强制其他处理器作重新排序(SMP系统中才有必要)
进程上下文:一个程序调用了系统调用,或触发了某个异常,它就陷入了内核空间。此时,内核“代表进程执行”,并处于进程上下文中,这里current宏是有效的;这个过程进程是可以被调度的。
中断上下文:系统不代表进程执行,而是执行一个中断处理函数;不能被调度。
4.进程家族树
所有进程都是init进程的后代,内核在系统启动的最后阶段启动init进程,该进程读取系统初始化脚本并执行其他的相关程序。
每个进程都有自己的父进程,和零个或多个子进程,所有拥有同一个父进程的进程是兄弟进程。
- //访问父进程
- struct task_struct *my_parent = current->parent;
- //依次访问所有子进程
- struct task_struct *task;
- struct list_head *list;
- list_for_each(list, ¤t->children) {
- task = list_entry(list, struct task_struct, sibling);
- /* task now points to one of current\'s children */
- }
- //遍历系统中所有进程
- list_entry(task->tasks.next, struct task_struct, tasks)
- list_entry(task->tasks.prev, struct task_struct, tasks)
5.进程创建
(1)许多操作系统都提供了产生进程的机制,首先在新的地址空间创建进程,读入可执行文件,最后开始执行。Unix吧这个步骤分解到两个单独的函数去执行,fork()和exec()。首先fork()通过拷贝当前进程创建一个子进程,其与父进程区别是PID,PPID,某些资源和统计量(如挂起信号,不用继承),exec负责读取可执行文件并将其载入地址空间开始运行。
(2)写时拷贝
是一种可以推迟甚至免除拷贝数据的技术,内核此时并不复制,而是与父进程共享一个拷贝。只有在需要写入时,才会复制数据。
fork()的实际开销就是,复制父进程的页表以及给子进程创建唯一的进程描述符。
(3)fork创建进程过程
fork(),vfork()和__clone()库函数都根据各自需要的参数标识去调用clone()->调用do_fork()->调用copy_process(),copy_process()完成如下过程
①调用dup_task_struct为新进程创建一个新的内核栈,thread_info结构和task_struct,这些值与当前进程的值相同,进程描述符也相同。
②检查确保创建子进程后,当前用户拥有的进程数没有超出为其分配的资源限制
③进程描述符内的许多成员都被清零或初始化,以与父进程区分开来,统计信息一般不继承,task_struct中的大多数数据依然未修改。
④子进程状态被设置为TASK_UNINTERRUPTIBLE,以保证它不会投入运行。
⑤copy_process调用copy_flags(),更新task_struct的flag成员。
⑥调用alloc_pid()为新进程分配一个有效的PID。
⑦根据传递给clone()的参数标识,拷贝或共享打开的文件,信号处理函数,进程地址空间等。
⑧最后copy_process做收尾工作,返回一个指向子进程的指针。
返回到do_fork(),如果copy_process()成功返回,子进程被唤醒并投入运行,内核有意选择子进程首先执行。(父进程先执行可能会向地址空间写入)
(4)vfork()
除了不拷贝父进程页表项外,vfork()系统调用与fork()功能相同,子进程作为父进程的一个单独的线程在它的地址空间里运行,父进程被阻塞,直到子进程推出或执行exec().
6.线程在Linux中的实现
(1)从内核角度来看,并没有线程这个概念,Linux把所有线程都当作进程来实现,内核并没有准备特别的调度算法或是定义特别的数据结构来表征线程,它仅仅被视为一个与其他进程共享某些资源的进程。每个线程都拥有唯一隶属于自己的task_struct.
对于多个线程并行,Linux只是为每个线程创建普通的task_struct的时候指定他们共享某些资源。
(2)创建线程
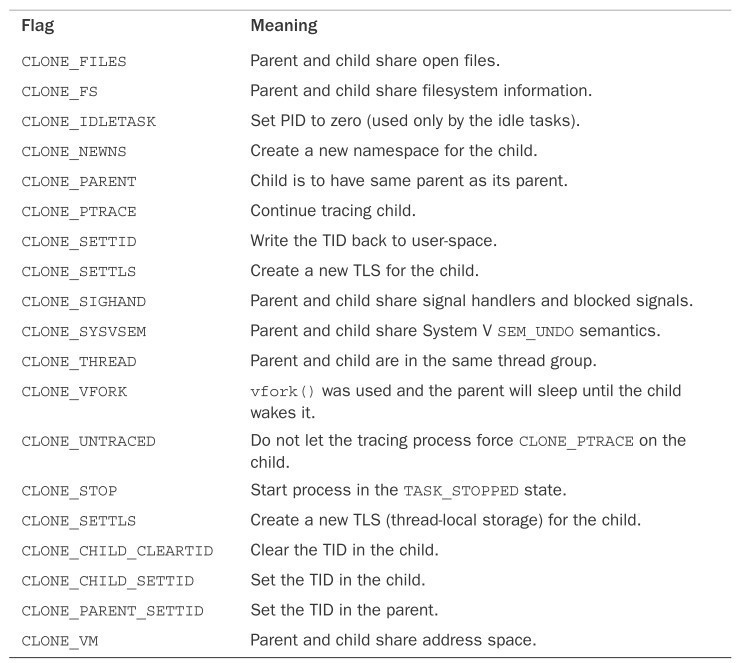
线程创建与普通进程创建类似,只不过在调用clone()的时候需要会传递一些参数标识来指明需要共享的资源
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
普通fork()
clone(SIGCHLD, 0);
vfork()
clone(CLONE_VFORK | CLONE_VM | SIGCHLD, 0);
传递给clone()的参数标志据诶的那个了新创建进程的行为和父子进程之间共享资源种类。
(3)内核线程
内核经常需要在后台执行一些操作,这种任务可以通过内核线程来完成---独立运行在内核空间的标准线程。它和普通线程的区别在于,内核线程没有独立的进程空间(指向地址空间的mm指针为NULL),只在内核运行。跟普通线程一样可以被调度,也可以被抢占。
内核线程只能由其他内核线程创建,Linux是通过从kthread内核进程衍生出所有新的内核线程的。内核创建新内核线程方法:
- struct task_struct *kthread_create(int (*threadfn)(void *data),
- void *data,
- const char namefmt[],
- ...)
新的任务是有kthread进程调用clone()创建的。新进程将运行threafn函数,给其传递参数data,namefmt接受可变参数列表。
新创建的进程处于不可运行状态,需要通过wake_up_process()明确的唤醒它,它不会主动运行。
创建一个进程并让它运行起来,可以调用
- #define kthread_run(threadfn, data, namefmt, ...) \\
- ({ \\
- struct task_struct *__k \\
- = kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \\
- if (!IS_ERR(__k)) \\
- wake_up_process(__k); \\
- __k; \\
- })
实际上就是简单的调用了kthread_create()和wake_up_process()。
内核线程启动后就一直运行直到调用do_exit(),或者内核其他部分调用kthread_stop()退出。传递给kthread_stop()的参数是kthread_create()函数返回的task_struct结构的地址。
int kthread_stop(struct task_struct *k)
7.进程终结
(1)一个进程终结时,内核必须释放它占有的资源并把这告知其父进程。
显示调用exit()(C编译器会在main()函数的返回点后面放置调用exit()的代码),或者当进程接收到它既不能处理也不能忽略的信号或异常时,它还可能被动的终结。
不管以何种方式终结,大部分都要靠do_exit()来完成,它做以下工作:
①将task_struct中的标志成员设置为PF_EXITING。
②调用del_timer_sync()删除任一内核定时器,根据返回结果,确保没有定时器在排队,也没有定时器处理程序在运行。
③如果BSD的进程记账功能开启,do_exit()会调用act_update_integrals()来输出记账信息。
④调用exit_mm()函数释放进程占用的mm_struct,如果没有别的进程使用它们(即该地址空间没有被共享),就彻底释放他们。
⑤调用sem__exit(),如果进程排队等候IPC信号,它则离开队列。
⑥调用exit_files()和exit_fs(),分别递减文件描述符,文件系统数据的引用计数。如果某个引用计数为0,就代表没有进程在使用相应的资源,此时可以释放。
⑦把存放在task_struct的exit_code成员的任务推出代码置为由exit()提供的推出代码,或者去完成其他由内核机制规定的推出动作,退出代码存放在这里供父进程随时检索。
⑧exit_notify()向父进程发信号,给子进程重新找养父,养父为线程组中的其他线程或者为init进程,并把进程状态(task_struct的exit_state中)置为EXIT_ZOBIE.
⑨do_exit()调用schedule()切换到新的进程。处于EXIT_ZOBIE的进程永远不会再被调度,do_exit()永不返回。
至此,进程相关的所有资源都被释放(假设是独享),现在占用的资源就只有内核栈,thread_info结构和task_struct结构,此时进程存在的唯一目的是向它的父进程提供信息。
(2)删除进程描述符
调用do_exit()之后,线程已经僵死,但系统还保留有其进程描述符,这样系统有办法在子进程和终结后仍能获得它的信息。进程终结时所需的清理工作和删除进程描述符分开执行。
wait()函数族都是调用wait4()来实现的,它的标准动作是挂起调用它的进程,直到其中的一个子进程推出,此时函数会返回孩子进程的PID,且调用该函数时提供的指针会包含子函数退出时的代码。
当最终需要释放进程描述符是,会调用release_task()。
①调用__exit_signal()à调用_unhash_process()à调用detach_pid()从pidhash上删除该进程,同时也要从任务队列中删除该进程。
②_exit_signal()释放目前僵尸进程所使用的剩余资源,并进行最终统计和记录。
③如果这个进程是线程组最后一个进程,并且领头进程已经死掉,那么release_task()就要通知僵死的领头进程的父进程。
④release_task()调用put_task_struct()释放进程内核栈和thread_info结构所占的页,并释放task_struct所占的slab高速缓存。
至此,进程描述符和所有进程独享的资源就全部释放掉了。
(3)孤儿进程
如果父进程在子进程之前退出,就必须为子进程找到新父亲,以免进程永远处于僵死状态,耗费内存。解决方法是,给子进程在当前进程组找一个线程作为父亲,如果不行,就让init作为其父进程。
do_exit()会调用exit_notify(),该函数会调用forget_original_parent(),而后会调用find_new_reaper()来执行寻父过程。
- static struct task_struct *find_new_reaper(struct task_struct *father)
- {
- struct pid_namespace *pid_ns = task_active_pid_ns(father);
- struct task_struct *thread;
- thread = father;
- while_each_thread(father, thread) {
- if (thread->flags & PF_EXITING)
- continue;
- if (unlikely(pid_ns->child_reaper == father))
- pid_ns->child_reaper = thread;
- return thread;
- }
- if (unlikely(pid_ns->child_reaper == father)) {
- write_unlock_irq(&tasklist_lock);
- if (unlikely(pid_ns == &init_pid_ns))
- panic(\"Attempted to kill init!\");
- zap_pid_ns_processes(pid_ns);
- write_lock_irq(&tasklist_lock);
- /*
- * We can not clear ->child_reaper or leave it alone.
- * There may by stealth EXIT_DEAD tasks on ->children,
- * forget_original_parent() must move them somewhere.
- */
- pid_ns->child_reaper = init_pid_ns.child_reaper;
- }
- return pid_ns->child_reaper;
- }
- //找到合适父进程后,只要遍历所有子进程并为他们设置新的父进程
- reaper = find_new_reaper(father);
- list_for_each_entry_safe(p, n, &father->children, sibling) {
- p->real_parent = reaper;
- if (p->parent == father) {
- BUG_ON(p->ptrace);
- p->parent = p->real_parent;
- }
- reparent_thread(p, father);
- }
- //然后调用ptrace_exit_finish()同样进行寻父过程,不过是给ptraced的子进程寻父
- void exit_ptrace(struct task_struct *tracer)
- {
- struct task_struct *p, *n;
- LIST_HEAD(ptrace_dead);
- write_lock_irq(&tasklist_lock);
- list_for_each_entry_safe(p, n, &tracer->ptraced, ptrace_entry) {
- if (__ptrace_detach(tracer, p))
- list_add(&p->ptrace_entry, &ptrace_dead);
- }
- write_unlock_irq(&tasklist_lock);
- BUG_ON(!list_empty(&tracer->ptraced));
- list_for_each_entry_safe(p, n, &ptrace_dead, ptrace_entry) {
- list_del_init(&p->ptrace_entry);
- release_task(p);
- }
- }
这段代码遍历两个链表:子进程链表和ptrace子进程链表。
在一个单独的被ptrace跟踪的子进程链表中搜索相关的兄弟进程---用两个相对较小的链表减轻了遍历所有系统进程的消耗。
一旦系统为进程成功找到和设置了新父进程,就不会再出现驻留僵死进程的危险,init进程会例行调用wait()来检查其子进程,清除所有与其相关的僵死进程。
《linux内核设计与实现》第三章的更多相关文章
- Linux内核设计与实现 第三章
1. 进程和线程 进程和线程是程序运行时状态,是动态变化的,进程和线程的管理操作都是由内核来实现的. Linux中的进程于Windows相比是很轻量级的,而且不严格区分进程和线程,线程不过是一种特殊的 ...
- linux及安全《Linux内核设计与实现》第一章——20135227黄晓妍
<linux内核设计与实现>第一章 第一章Linux内核简介: 1.3操作系统和内核简介 操作系统:系统包含了操作系统和所有运行在它之上的应用程序.操作系统是指整个在系统中负责完成最基本功 ...
- LINUX内核设计与实现第三周读书笔记
LINUX内核设计与实现第三周读书笔记 第一章 LINUX内核简介 1.1 Unix的历史 1969年的夏天,贝尔实验室的程序员们在一台PDR-7型机上实现了Unix这个全新的操作系统. 1973年, ...
- 《linux内核设计与实现》第一章
第一章Linux内核简介 一.unix 1.Unix的历史 Unix是现存操作系统中最强大和最优秀的系统. ——1969年由Ken Thompson和Dernis Ritchie的灵感点亮的产物. — ...
- linux及安全《Linux内核设计与实现》第二章——20135227黄晓妍
第二章:从内核出发 2.1获取源代码 2.1.1使用git Git:内核开发者们用来管理Linux内核源代码的控制系统. 我们使用git来下载和管理Linux源代码. 2.1.2安装内核源代码(如果使 ...
- Linux内核设计与实现 第十七章
1. 设备类型 linux中主要由3种类型的设备,分别是: 设备类型 代表设备 特点 访问方式 块设备 硬盘,光盘 随机访问设备中的内容 一般都是把设备挂载为文件系统后再访问 字符设备 键盘,打印机 ...
- Linux内核设计与实现 第五章
1. 什么是系统调用 系统调用就是用户程序和硬件设备之间的桥梁. 用户程序在需要的时候,通过系统调用来使用硬件设备. 系统调用的存在意义: 1)用户程序通过系统调用来使用硬件,而不用关心具体的硬件设备 ...
- 《linux内核设计与实现》第二章
第二章 从内核出发 一.获取内核源码 1.使用Git(linux创造的系统) 使用git来获取最新提交到linux版本树的一个副本: $ git clone git://git.kernel.org/ ...
- 《Linux内核分析》之第三章读书笔记
进程管理 进程是处于执行期的程序以及相关的资源的总称,也称作任务.执行线程,简称线程,是在进程中活动的对象. 可以两个或两个以上的进程执行同一个程序 也可以两个或两个以上并存的进程共享许多资源 内核调 ...
- Linux内核设计与实现 第四章
1. 什么是调度 现在的操作系统都是多任务的,为了能让更多的任务能同时在系统上更好的运行,需要一个管理程序来管理计算机上同时运行的各个任务(也就是进程). 这个管理程序就是调度程序,功能: 决定哪些进 ...
随机推荐
- Linux运维之如何查看目录被哪些进程所占用,lsof命令、fuser命令
之前将一块硬盘挂载到某个目录下,但是现在我想卸载掉这块硬盘,无论如何都umount不了,有些同学可能说需要加上 -f 参数强制卸载,理论上是可以的,但是在我这里依然不起作用,比如: [root@:vg ...
- 5、爬虫系列之scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- flex布局下el-table横向滚动条失效
如下图,是一种常见的页面结构,我们可以有很多方法实现,inline-block,float,flex等等 但是,最近项目中遇到一个怪事,左边是侧边栏导航,右边是一个数据展示table,el-table ...
- python中的轻量级定时任务调度库:schedule
提到定时任务调度的时候,相信很多人会想到芹菜celery,要么就写个脚本塞到crontab中.不过,一个小的定时脚本,要用celery的话太“重”了.所以,我找到了一个轻量级的定时任务调度的库:sch ...
- 【洛谷】【模拟+栈】P4711 「化学」相对分子质量
[题目传送门:] [戳] (https://www.luogu.org/problemnew/show/P4711) [算法分析:] 关于一个分子拆分后的产物,一共有三种情况: 原子 原子团 水合物 ...
- rman 脚本大全
################################################################一个增量备份的例子脚本######################### ...
- 【转】BAT批处理中的字符串处理详解(字符串截取)
下面对这些功能一一进行讲解. 1.截取字符串 截取字符串可以说是字符串处理功能中最常用的一个子功能了,能够实现截取字符串中的特定位置的一个或多个字符.举例说明其基本功能: @echo off set ...
- 20145236《网络攻防》Exp5 MSF基础应用
20145236<网络攻防>Exp5 MSF基础应用 一.基础问题回答 解释exploit,payload,encode是什么: exploit就是负责负载有用代码的交通工具,先通过exp ...
- java开发过程问题及解决
1.junit做测试时候报异常: junit.framework.AssertionFailedError: No tests found in com.mq.original.OriginalMqP ...
- OpenCV——轮廓填充drawContours函数解析
函数的调用形式 void drawContours(InputOutputArray image, InputArrayOfArrays contours, int contourIdx, const ...