DMA(直接存储器存取)
DMA(Direct Memory Access)
DMA(Direct Memory Access)即直接存储器存取,是一种快速传送数据的机制。
工作原理
DMA是指外部设备不通过CPU而直接与系统内存交换数据的接口技术。
要把外设的数据读入内存或把内存的数据传送到外设,一般都要通过CPU控制完成,如CPU程序查询或中断方式。利用中断进行数据传送,可以大大提高CPU的利用率。
但是采用中断传送有它的缺点,对于一个高速I/O设备,以及批量交换数据的情况,只能采用DMA方式,才能解决效率和速度问题。DMA在外设与内存间直接进行数据交换,而不通过CPU,这样数据传送的速度就取决于存储器和外设的工作速度。
通常系统的总线是由CPU管理的。在DMA方式时,就希望CPU把这些总线让出来,即CPU连到这些总线上的线处于第三态–高阻状态,而由DMA控制器接管,控制传送的字节数,判断DMA是否结束,以及发出DMA结束信号。DMA控制器必须有以下功能:
1. 能向CPU发出系统保持(HOLD)信号,提出总线接管请求;
2. 当CPU发出允许接管信号后,负责对总线的控制,进入DMA方式;
3. 能对存储器寻址及能修改地址指针,实现对内存的读写操作;
4. 能决定本次DMA传送的字节数,判断DMA传送是否结束
5. 发出DMA结束信号,使CPU恢复正常工作状态。

计算机发展到今天,DMA已不再用于内存到内存的数据传送,因为CPU速度非常快,做这件事,比用DMA控制还要快,但要在适配卡和内存之间传送数据,仍然是非DMA莫属。要从适配卡到内存传送数据,DMA同时触发从适配卡读数据总线(即I/O读操作)和向内存写数据的总线。激活I/O读操作就是让适配卡把一个数据单位(通常是一个字节或一个字)放到PC数据总线上,因为此时内存写总线也被激活,数据就被同时从PC总线上拷贝到内存中。
DMA工作方式
随着大规模集成电路技术的发展,DMA传送已不局限于存储器与外设间的信息交换,而可以扩展为在存储器的两个区域之间,或两种高速的外设之间进行DMA传送,如图所示。
DMAC是控制存储器和外部设备之间直接高速地传送数据的硬件电路,它应能取代CPU,用硬件完成数据传送的各项功能。
各种DMAC一般都有两种基本的DMA传送方式:
1. 单字节方式:每次DMA请求只传送一个字节数据,每传送完一个字节,都撤除DMA请求信号,释放总线。
2. 多字节方式:每次DMA请求连续传送一个数据块,待规定长度的数据块传送完以后,才撤除DMA请求,释放总线。
在DMA传送中,为了使源和目的间的数据传送取得同步,不同的DMAC在操作时都受到外设的请求信号或准备就绪信号–Ready信号的限制。

DMA与CPU调度
DMA控制器可采用哪几种方式与CPU分时使用内存?
直接内存访问(DMA)方式是一种完全由硬件执行I/O交换的工作方式。DMA控制器从CPU完全接管对总线的控制。数据交换不经过CPU,而直接在内存和I/O设备之间进行。DMA控制器采用以下三种方式:
①停止CPU访问内存:当外设要求传送一批数据时,由DMA控制器发一个信号给CPU。DMA控制器获得总线控制权后,开始进行数据传送。一批数据传送完毕后,DMA控制器通知CPU可以使用内存,并把总线控制权交还给CPU。
②周期挪用:当I/O设备没有 DMA请求时,CPU按程序要求访问内存:一旦 I/O设备有DMA请求,则I/O设备挪用一个或几个周期。
③DMA与CPU交替访内:一个CPU周期可分为2个周期,一个专供DMA控制器访内,另一个专供CPU访内。不需要总线使用权的申请、建立和归还过程。
DMA本来不属于CPU体系架构部分的内容,只因为在开发中经常要用到其相关的知识,所以这里就其基本概念、工作原理、常见问题做一个总结。
DMA概述
DMA的英文拼写是“Direct Memory Access”,汉语的意思就是直接内存访问。DMA既可以指内存和外设直接存取数据这种内存访问的计算机技术,又可以指实现该技术的硬件模块(对于通用计算机PC而言,DMA控制逻辑由CPU和DMA控制接口逻辑芯片共同组成,嵌入式系统的DMA控制器内建在处理器芯片内部,一般称为DMA控制器,DMAC)。
DMA内存访问技术
使用DMA的好处就是它不需要CPU的干预而直接服务外设,这样CPU就可以去处理别的事务,从而提高系统的效率,对于慢速设备,如UART,其作用只是降低CPU的使用率,但对于高速设备,如硬盘,它不只是降低CPU的使用率,而且能大大提高硬件设备的吞吐量。因为对于这种设备,CPU直接供应数据的速度太低。 因CPU只能一个总线周期最多存取一次总线,而且对于ARM,它不能把内存中A地址的值直接搬到B地址。它只能先把A地址的值搬到一个寄存器,然后再从这个寄存器搬到B地址。也就是说,对于ARM,要花费两个总线周期才能将A地址的值送到B地址。而DMA就不同了,一般系统中的DMA都有突发(Burst)传输的能力,在这种模式下,DMA能一次传输几个甚至几十个字节的数据,所以使用DMA能使设备的吞吐能力大为增强。
使用DMA时我们必须要注意如下事实:
- DMA使用物理地址,程序是使用虚拟地址的,所以配置DMA时必须将虚拟地址转化成物理地址。
- 因为程序使用虚拟地址,而且一般使用cache地址,所以Cache中的内容与其物理地址(内存)的内容不一定一致,所以在启动DMA传输前一定要将该地址的cache刷新,即写入内存。
- OS并不能保证每次分配到的内存空间在物理上是连续的。尤其是在系统使用过一段时间而又分配了一块比较大的内存时。所以每次都需要判断地址是不是连续的,如果不连续就需要把这段内存分成几段让DMA完成传输
DMAC的基本配置
DMA用于无需CPU的介入而直接由专用控制器(DMA控制器)建立源与目的传输的应用,因此,在大量数据传输中解放了CPU。PIC32微控制器中的DMA可用于映射到内存空间中的不同外设,如从存储区到SPI,UART或I2C等设备。DMA特性详见器件参考手册,这里仅对一些基本原理与功能做一个简析。
| 地址寄存器 | 存放DMA传输时存储单元地址 |
| 字节计数器 | 存放DMA传输的字节数 |
| 控制寄存器 | 存放由CPU设定的DMA传输方式,控制命令等 |
| 状态寄存器 | 存放DMAC当前的状态,包括有无DMA请求,是否结束等 |
独立DMA控制芯片
在课程《微机原理》中,会讲到X86下一片独立的DMA控制芯片8237A。8237A控制芯片各通道在PC机内的任务:
- CH0:用作动态存储器的刷新控制
- CH1:为用户预留
- CH2:软盘驱动器数据传输用的DMA控制
- CH3:硬盘驱动器数据传输用的DMA控制
嵌入式设备中的DMA
直接存储器存取(DMA)控制器是一种在系统内部转移数据的独特外设,可以将其视为一种能够通过一组专用总线将内部和外部存储器与每个具有DMA能力的外设连接起来的控制器。它之所以属于外设,是因为它是在处理器的编程控制下来执行传输的。值得注意的是,通常只有数据流量较大(kBps或者更高)的外设才需要支持DMA能力,这些应用方面典型的例子包括视频、音频和网络接口。
一般而言,DMA控制器将包括一条地址总线、一条数据总线和控制寄存器。高效率的DMA控制器将具有访问其所需要的任意资源的能力,而无须处理器本身的介入,它必须能产生中断。最后,它必须能在控制器内部计算出地址。
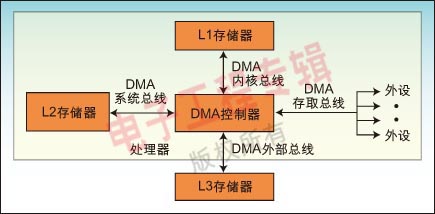
一个处理器可以包含多个DMA控制器。每个控制器有多个DMA通道,以及多条直接与存储器站(memory bank)和外设连接的总线,如图1所示。在很多高性能处理器中集成了两种类型的DMA控制器。第一类通常称为“系统DMA控制器”,可以实现对任何资源(外设和存储器)的访问,对于这种类型的控制器来说,信号周期数是以系统时钟(SCLK)来计数的,以ADI的Blackfin处理器为例,频率最高可达133MHz。第二类称为内部存储器DMA控制器(IMDMA),专门用于内部存储器所处位置之间的相互存取操作。因为存取都发生在内部(L1-L1、L1-L2,或者L2-L2),周期数的计数则以内核时钟(CCLK)为基准来进行,该时钟的速度可以超过600MHz。
每个DMA控制器有一组FIFO,起到DMA子系统和外设或存储器之间的缓冲器的作用。对于MemDMA(Memory DMA)来说,传输的源端和目标端都有一组FIFO存在。当资源紧张而不能完成数据传输的话,则FIFO可以提供数据的暂存区,从而提高性能。
因为通常会在代码初始化过程中对DMA控制器进行配置,内核就只需要在数据传输完成后对中断做出响应即可。你可以对DMA控制进行编程,让其与内核并行地移动数据,而同时让内核执行其基本的处理任务―那些应该让它专注完成的工作。
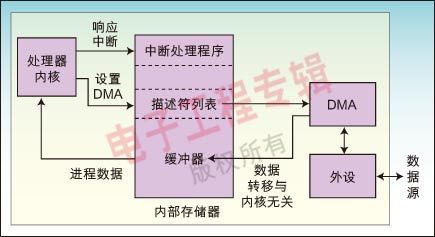
在一个优化的应用中,内核永远不用参与任何数据的移动,而仅仅对L1存储器中的数据进行读写。于是,内核不需要等待数据的到来,因为DMA引擎会在内核准备读取数据之前将数据准备好。图2给出了处理器和DMA控制器间的交互关系。由处理器完成的操作步骤包括:建立传输,启用中断,生成中断时执行代码。返回到处理器的中断输入可以用来指示“数据已经准备好,可进行处理”。
数据除了往来外设之外,还需要从一个存储器空间转移到另一个空间中。例如,视频源可以从一个 视频端口直接流入L3存储器,因为工作缓冲区规模太大,无法放入到存储器中。我们并不希望让处理器在每次需要执行计算时都从外部存储读取像素信息,因此为 了提高存取的效率,可以用一个存储器到存储器的DMA(MemDMA)来将像素转移到L1或者L2存储器中。
到目前为之,我们还仅专注于数据的移动,但是DMA的传送能力并不总是用来移动数据。
在最简单的MemDMA情况中,我们需要告诉DMA控制器源端地址、目标端地址和待传送的字的个数。每次传输的字的大小可以是8、16或者12位。 我们只需要改变数据传输每次的数据大小,就可以简单地增加DMA的灵活性。例如,采用非单一大小的传输方式时,我们以传输数据块的大小的倍数来作为地址增量。也就是说,若规定32位的传输和4个采样的跨度,则每次传输结束后,地址的增量为16字节(4个32位字)。
DMA的设置
目前有两类主要的DMA传输结构:寄存器模式和描述符模式。无论属于哪一类DMA,表1所描述的几类信息都会在DMA控制器中出现。当DMA以寄存器模式工作时,DMA控制器只是简单地利用寄存器中所存储的参数值。在描述符模式中,DMA控制器在存储器中查找自己的配置参数。
基于寄存器的DMA
在基于寄存器的DMA内部,处理器直接对DMA控制寄存器进行编程,来启动传输。基于寄存器的DMA提供了最佳的DMA控制器性能,因为寄存器并不需要不断地从存储器中的描述符上载入数据,而内核也不需要保持描述符。
基于寄存器的DMA由两种子模式组成:自动缓冲(Autobuffer)模式和停止模式。在自动缓冲DMA中,当一个传输块传输完毕,控制寄存器就自动重新载入其最初的设定值,同一个DMA进程重新启动,开销为零。
正如我们在图3中所看到的那样,如果将一个自动缓冲DMA设定为从外设传输一定数量的字到 L1数据存储器的缓冲器上,则DMA控制器将会在最后一个字传输完成的时刻就迅速重新载入初始的参数。这构成了一个“循环缓冲器”,因为当一个量值被写入 到缓冲器的最后一个位置上时,下一个值将被写入到缓冲器的第一个位置上。
自动缓冲DMA特别适合于对性能敏感的、存在持续数据流的应用。DMA控制器可以在独立于处理器其他活动的情况下读入数据流,然后在每次传输结束时,向内核发出中断。
停止模式的工作方式与自动缓冲DMA类似,区别在于各寄存器在DMA结束后不会重新载入,因 此整个DMA传输只发生一次。停止模式对于基于某种事件的一次性传输来说十分有用。例如,非定期地将数据块从一个位置转移到另一个位置。当你需要对事件进 行同步时,这种模式也非常有用。例如,如果一个任务必须在下一次传输前完成的话,则停止模式可以确保各事件发生的先后顺序。此外,停止模式对于缓冲器的初 始化来说非常有用。
描述符模型
基于描述符(descriptor)的DMA要求在存储器中存入一组参数,以 启动DMA的系列操作。该描述符所包含的参数与那些通常通过编程写入DMA控制寄存器组的所有参数相同。不过,描述符还可以容许多个DMA操作序列串在一 起。在基于描述符的DMA操作中,我们可以对一个DMA通道进行编程,在当前的操作序列完成后,自动设置并启动另一次DMA传输。基于描述符的方式为管理 系统中的DMA传输提供了最大的灵活性。
ADI 的Blackfin处理器上有两种主要的描述符方式―描述符阵列和描述符列表,这两种操作方式所要实现的目标是在灵活性和性能之间实现一种折中平衡。
直接内存访问(DMA)
1. 什么是DMA
直接内存访问是一种硬件机制,它允许外围设备和主内存之间直接传输它们的I/O数据,而不需要系统处理器的参与。使用这种机制可以大大提高与设备通信的吞吐量。
2. DMA数据传输
有两种方式引发数据传输:
第一种情况:软件对数据的请求
1. 当进程调用read,驱动程序函数分配一个DMA缓冲区,并让硬件将数据传输到这个缓冲区中。进程处于睡眠状态。
2. 硬件将数据写入到DMA缓冲区中,当写入完毕,产生一个中断
3. 中断处理程序获取输入的数据,应答中断,并唤起进程,该进程现在即可读取数据
第二种情况发生在异步使用DMA时。
1. 硬件产生中断,宣告新数据的到来
2. 中断处理程序分配一个缓冲区,并且告诉硬件向哪里传输数据
3. 外围设备将数据写入数据区,完成后,产生另外一个中断
4.处理程序分发新数据,唤醒任何相关进程,然后执行清理工作
高效的DMA处理依赖于中断报告。
3. 分配DMA缓冲区
使用DMA缓冲区的主要问题是:当大于一页时,它们必须占据连续的物理页,因为设备使用ISA或PCI系统总线传输数据,而这两种方式使用的都是物理地址。
使用get_free_pasges可以分配多大几M字节的内存(MAX_ORDER是11),但是对于较大数量(即使是远小于128KB)的请求,通常会失败,这是因为系统内存充满了内存碎片。
解决方法之一就是在引导时分配内存,或者为缓冲区保留顶部物理内存。
例子:在系统引导时,向内核传递参数“mem=value”的方法保留顶部的RAM。比如系统有256内存,参数“mem=255M”,使内核不能使用顶部的1M字节。随后,模块可以使用下面代码获得该内存的访问权:
dmabuf=ioremap(0XFF00000/**255M/, 0X100000/*1M/*);
解决方法之二是使用GPF_NOFAIL分配标志为缓冲区分配内存,但是该方法为内存管理子系统带来了相当大的压力。
解决方法之三十设备支持分散/聚集I/O,这可以将缓冲区分配成多个小块,设备会很好地处理它们。
4. 通用DMA层
DMA操作最终会分配缓冲区,并将总线地址传递给设备。内核提高了一个与总线——体系结构无关的DMA层。强烈建议在编写驱动程序时,为DMA操作使用该层。使用这些函数的头文件是<linux/dmamapping.h>。
int dma_set_mask(struct device *dev, u64 mask);
该掩码显示该设备能寻址能力对应的位。比如说,设备受限于24位寻址,则mask应该是0x0FFFFFF。
5. DMA映射
IOMMU在设备可访问的地址范围内规划了物理内存,使得物理上分散的缓冲区对设备来说成连续的。对IOMMU的运用需要使用到通用DMA层,而vir_to_bus函数不能完成这个任务。但是,x86平台没有对IOMMU的支持。
解决之道就是建立回弹缓冲区,然后,必要时会将数据写入或者读出回弹缓冲区。缺点是降低系统性能。
根据DMA缓冲区期望保留的时间长短,PCI代码区分两种类型的DMA映射:
一是一致性DMA映射,存在于驱动程序生命周期中,一致性映射的缓冲区必须可同时被CPU和外围设备访问。一致性映射必须保存在一致性缓存中。建立和使用一致性映射的开销是很大的。
二是流式DMA映射,内核开发者建议尽量使用流式映射,原因:一是在支持映射寄存器的系统中,每个DMA映射使用总线上的一个或多个映射寄存器,而一致性映射生命周期很长,长时间占用这些这些寄存器,甚至在不使用他们的时候也不释放所有权;二是在一些硬件中,流式映射可以被优化,但优化的方法对一致性映射无效。
6. 建立一致性映射
驱动程序可调用pci_alloc_consistent函数建立一致性映射:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *dma_handle, int falg);
该函数处理了缓冲区的分配和映射,前两个参数是device结构和所需的缓冲区的大小。函数在两处返回DMA映射的结果:函数的返回值是缓冲区的内核虚拟地址,可以被驱动程序使用;而与其相关的总线地址保存在dma_handle中。
当不再需要缓冲区时,调用下函数:
void dma_free_conherent(struct device *dev, size_t size, void *vaddr, dma_addr_t *dma_handle);
7. DMA池
DMA池是一个生成小型,一致性DMA映射的机制。调用dma_alloc_coherent函数获得的映射,可能其最小大小为单个页。如果设备需要的DMA区域比这还小,就是用DMA池。在<linux/dmapool.h>中定义了DMA池函数:
struct dma_pool *dma_pool_create(const char *name, struct device *dev, size_t size, size_t align, size_t allocation);
void dma_pool_destroy(struct dma_pool *pool);
name是DMA池的名字,dev是device结构,size是从该池中分配的缓冲区的大小,align是该池分配操作所必须遵守的硬件对齐原则(用字节表示),如果allocation不为零,表示内存边界不能超越allocation。比如说传入的allocation是4K,表示从该池分配的缓冲区不能跨越4KB的界限。
在销毁之前必须向DMA池返回所有分配的内存。
void * dma_pool_alloc(sturct dma_pool *pool, int mem_flags, dma_addr_t *handle);
void dma_pool_free(struct dma_pool *pool, void *addr, dma_addr_t addr);
8. 建立流式DMA映射
在某些体系结构中,流式映射也能够拥有多个不连续的页和多个“分散/聚集”缓冲区。建立流式映射时,必须告诉内核数据流动的方向。
DMA_TO_DEVICE
DEVICE_TO_DMA
如果数据被发送到设备,使用DMA_TO_DEVICE;而如果数据被发送到CPU,则使用DEVICE_TO_DMA。
DMA_BIDIRECTTONAL
如果数据可双向移动,则使用该值
DMA_NONE
该符号只是出于调试目的。
当只有一个缓冲区要被传输的时候,使用下函数映射它:
dma_addr_t dma_map_single(struct device *dev, void *buffer, size_t size, enum dma_data_direction direction);
返回值是总线地址,可以把它传递给设备;如果执行错误,返回NULL。
当传输完毕后,使用下函数删除映射:
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size, enum dma-data_direction direction);
使用流式DMA的原则:
一是缓冲区只能用于这样的传送,即其传送方向匹配与映射时给定的方向值;
二是一旦缓冲区被映射,它将属于设备,不是处理器。直到缓冲区被撤销映射前,驱动程序不能以任何方式访问其中的内容。只用当dma_unmap_single函数被调用后,显示刷新处理器缓存中的数据,驱动程序才能安全访问其中的内容。
三是在DMA出于活动期间内,不能撤销对缓冲区的映射,否则会严重破坏系统的稳定性。
如果要映射的缓冲区位于设备不能访问的内存区段(高端内存),怎么办?一些体系结构只产生一个错误,但是其他一些系统结构件创建一个回弹缓冲区。回弹缓冲区就是内存中的独立区域,它可被设备访问。如果使用DMA_TO_DEVICE标志映射缓冲区,并且需要使用回弹缓冲区,则在最初缓冲区中的内容作为映射操作的一部分被拷贝。很明显,在拷贝后,最初缓冲区内容的改变对设备不可见。同样DEVICE_TO_DMA回弹缓冲区被dma_unmap_single函数拷贝回最初的缓冲区中,也就是说,直到拷贝操作完成,来自设备的数据才可用。
有时候,驱动程序需要不经过撤销映射就访问流式DMA缓冲区的内容,为此内核提供了如下调用:
void dma_sync_single_for_cpu(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_directction direction);
应该在处理器访问流式DMA缓冲区前调用该函数。一旦调用了该函数,处理器将“拥有”DMA缓冲区,并可根据需要对它进行访问。然后在设备访问缓冲区前,应该调用下面的函数将所有权交还给设备:
void dma_sync_single_for_device(struct device *dev, dma_handle_t bus_addr, size_t size, enum dma_data_direction direction);
再次强调,处理器在调用该函数后,不能再访问DMA缓冲区了。
DMA(直接存储器存取)的更多相关文章
- 直接存储器存取(Direct Memory Access,DMA)详细讲解
一.理论理解部分. 1.直接存储器存取(DMA)用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输. 2.无须CPU干预,数据可以通过DMA快速移动,这就节省了CPU的资源来做其他操作. ...
- mini2440裸机试炼之——DMA直接存取 实现Uart(串口)通信
这个仅仅能作为自己初步了解MDA的开门篇 实现功能: 将字符串数据通过DMA0通道传递给UTXH0,然后在终端 显示.传输数据完后.DMA0产生中断,beep声, LED亮. DMA基本知识 计算机系 ...
- DMA—直接存储器访问
DMA 简介 DMA(Direct Memory Access)—直接存储器存取,是单片机的一个外设,它的主要功能是用来搬数据,但是不需要占用 CPU,即在传输数据的时候,CPU 可以干其他的事情,好 ...
- DMA 内存存取原理
DMA直接内存存取原理 DMADMA直接内存存取原理是指外部设备不通过CPU而直接与系统内存交换数据的接口技术. 要把外设的数据读入内存或把内存的数据传送到外设,一般都要通过CPU控制完成,如CPU程 ...
- (转)DMA(Direct Memory Access)
DMA(Direct Memory Access) DMA(Direct Memory Access)即直接存储器存取,是一种快速传送数据的机制. 工作原理 DMA是指外部设备不通过CPU而直接与系统 ...
- hello程序的运行过程-从计算机系统角度
hello程序的运行过程-从计算机系统角度 1.gcc编译器驱动程序读取源程序文件hello.c,并将它翻译成一个可执行目标文件hello.翻译过程分为四个阶段:预处理阶段,编译阶段,汇编阶段,链接阶 ...
- STM32之DMA+ADC
借用小甲鱼的经典:各位互联网的广大网友们.大家早上中午晚上好..(打下小广告,因为小甲鱼的视频真的很不错).每次看小甲鱼的视频自学都是比较轻松愉快的..我在想,如果小甲鱼出STM32的视频,我会一集不 ...
- STM32F103之DMA
一.背景: 需要使用STM32的DAC,例程代码中用了DMA,对DMA之前没有实际操作过,也很早就想知道DMA到底是什么,因此,看了一下午手册,代码和网上的资料,便有了此篇文章,做个记录. 二.正文: ...
- STM32 DMA模块的配置与使用
DMA有什么用? 直接存储器存取用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输.无须CPU的干预,通过DMA数据可以快速地移动.这就节省了CPU的资源来做其他操作. 有多少个DMA资源 ...
随机推荐
- Codeforces 1118F1 Tree Cutting (Easy Version) (简单树形DP)
<题目链接> 题目大意: 给定一棵树,树上的点有0,1,2三中情况,0代表该点无色.现在需要你将这棵树割掉一些边,使得割掉每条边分割成的两部分均最多只含有一种颜色的点,即分割后的两部分不能 ...
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- [洛谷P1063][NOIP2006]能量项链
区间DP模板题 题目描述 在Mars星球上,每个Mars人都随身佩带着一串能量项链.在项链上有N颗能量珠.能量珠是一颗有头标记与尾标记的珠子,这些标记对应着某个正整数.并且,对于相邻的两颗珠子,前一颗 ...
- Linux学习笔记10
创建文件 touch touch filenames 创建文件夹 mkdir mkdir dir3 dir4 dir5 建立多个文件夹 mkdir ~/games 在登录用户的本目录之下建立game ...
- SpringBoot多数据源
很多业务场景都需要使用到多数据库,本文介绍springboot对多数据源的使用. 这次先说一下application.properties文件,分别连接了2个数据库test和test1.完整代码如下: ...
- Adams/Car与Simulink联合仿真方法
必须是Assembly装配体才行,并支持仿真设置.这里使用MDI_Demo_Vehicle模型,输出前缀为test1,输出选择files_only.然后OK输出. 生成的文件如下: 在Plant Ex ...
- Django单表操作
一.数据库相关设置 配置ORM的loggers日志: # 配置ORM的loggers日志 LOGGING = { 'version': 1, 'disable_existing_loggers': F ...
- 潭州课堂25班:Ph201805201 django 项目 第二十五课 文章多级评论前后台实现 (课堂笔记)
添加新闻评论功能 1.分析 业务处理流程: 判断前端传的新闻id是否为空,是否为整数.是否不存在 判断评论的内容是否为空 判断是否有父评论,父评论的id是否与新闻id匹配 判断用户是否登录 保存新闻评 ...
- HTML5:在移动端禁用长按选中文本功能
很多时候,我们在写的手机页面需要用户进行长按然后响应一个事件.但是在微信中用户的长按操作被默认为谈出来一个复制的选项.那么这个时候如何去禁止这个东西呢? 其实很简单,方法看下面: 只需要在你需要禁止的 ...
- .net异常机制
异常机制简介 当CPU运行到一些非法的指令,例如除零错误,访问内存页失败等指令,CPU会生成一个硬件异常,不同的异常有固定的异常代码作为标识符,异常产生以后CPU暂时不能继续执行后续的指令—因为后续的 ...