K-临近算法(KNN)
K-临近算法(KNN)
K nearest neighbour
1、k-近邻算法原理
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
- 优点:精度高、对异常值不敏感、无数据输入假定。
- 缺点:时间复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
工作原理
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据 与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
欧几里得距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
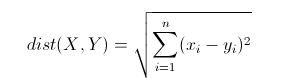
2、在scikit-learn库中使用k-近邻算法
分类问题:from sklearn.neighbors import KNeighborsClassifier
回归问题:from sklearn.neighbors import KNeighborsRegressor
1)用于分类(用鸢尾花作为示例)
导包,机器学习的算法KNN、数据鸢尾花
# scikit-learning 提供数据样本,可以供我们研究机器学习模型
# 可以使用load方法加载datasets中的各种数据
from sklearn import datasets
import matplotlib.pyplot as plt
iris = datasets.load_iris() # load是获取本地的数据集 iris就是鸢尾花数据集
data = iris.data # 特征值
target = iris.target # 目标值
target_names = iris.target_names # 目标的名字
feature_names = iris.feature_names # 特征的名字
df = DataFrame(data,columns=feature_names)
df.plot()

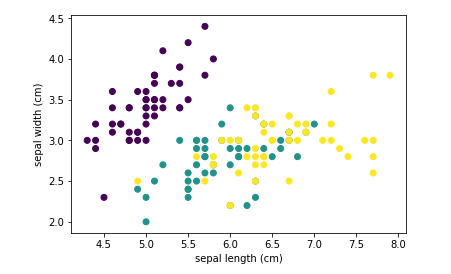
画图研究前两个特征和分类之间的关系(二维散点图只能展示两个维度)
# 取出 前两个特征 特征0 作为横轴 特征1作为纵轴 X_train = data[:,:2]
y_train = target plt.scatter(X_train[:,0],X_train[:,1],c=target) # 特征0作为点的横坐标 特征1作为点的纵坐标 target值作为点的颜色映射
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[1])
定义KNN分类器
真正判断分类的时候 肯定是用所有的4个特征 效果更好
这里只用两个特征来判断分类 也可以 但是效果肯定不如4个的好
这里之所以用两个 是为了画图 给大家展示效果
# 获取模型
from sklearn.neighbors import KNeighborsClassifier
# 使用两个特征来训练模型
# n_neighbors可以自己根据经验给定 一般给的是奇数(偶数容易造成 两种分类一样多的情况)
knn = KNeighborsClassifier(n_neighbors=7)
第一步,训练数据
knn.fit(X_train,y_train)
第二步预测数据:所预测的数据,自己创造,就是上面所显示图片的背景点
生成预测数据
# 要 取遍 平面 上 所有点
# 首先 x的范围内要取遍 y的范围内也要取遍
x = np.arange(X_train[:,0].min()-0.5,X_train[:,0].max()+0.5,0.02) # 取遍x轴 y = np.arange(X_train[:,1].min()-0.5,X_train[:,1].max()+0.5,0.02) # 取遍y轴 # 交叉 取遍 整个平面
X,Y = np.meshgrid(x,y) # 返回两个 ndarray 第一个是 平面上所有点的x座标 第二个是平面上所有点的y座标 # c_函数 可以使行 变列 (我们使用这个函数 就可以 把X,Y里面的值 组合成座标点)
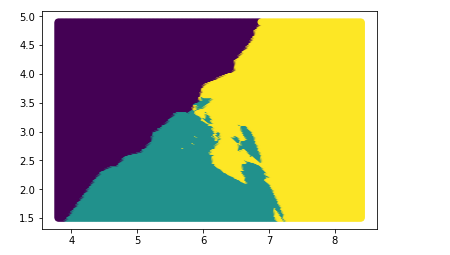
X_test = np.c_[X.flatten(),Y.flatten()] # 使用reshape去变形也可以 plt.scatter(X_test[:,0],X_test[:,1])# 查看是否确定是取遍平面中的所有点 # 模型预测出来的结果 一般叫y_
y_ = knn.predict(X_test)
y_
以图形化的效果展示结果
plt.scatter(X_test[:,0],X_test[:,1],c=y_)
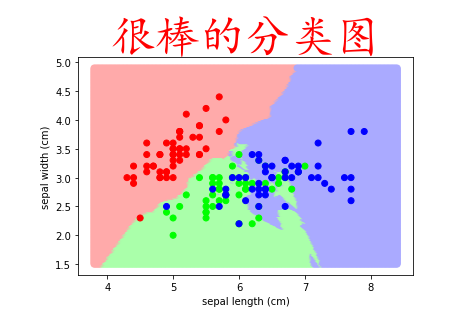
from matplotlib.colors import ListedColormap
# ListedColormap([]) # 创建颜色映射对象
cm1 = ListedColormap(
['#FFAAAA','#AAFFAA','#AAAAFF']
) cm2 = ListedColormap(
['#FF0000','#00FF00','#0000FF']
) plt.scatter(X_test[:,0],X_test[:,1],c=y_,cmap=cm1) # c是color 会根据 传入的不同数值 去填充不同的颜色
plt.scatter(X_train[:,0],X_train[:,1],c=target,cmap=cm2)
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[1])
plt.title('很棒的分类图',fontproperties='KaiTi',fontsize=45,color='r')
K-临近算法(KNN)的更多相关文章
- 秒懂机器学习---k临近算法(KNN)
秒懂机器学习---k临近算法(KNN) 一.总结 一句话总结: 弄懂原理,然后要运行实例,然后多解决问题,然后想出优化,分析优缺点,才算真的懂 1.KNN(K-Nearest Neighbor)算法的 ...
- [Machine-Learning] K临近算法-简单例子
k-临近算法 算法步骤 k 临近算法的伪代码,对位置类别属性的数据集中的每个点依次执行以下操作: 计算已知类别数据集中的每个点与当前点之间的距离: 按照距离递增次序排序: 选取与当前点距离最小的k个点 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- K临近算法
K临近算法原理 K临近算法(K-Nearest Neighbor, KNN)是最简单的监督学习分类算法之一.(有之一吗?) 对于一个应用样本点,K临近算法寻找距它最近的k个训练样本点即K个Neares ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
随机推荐
- tensorboard使用过程错误记录
首先代码如下: def word_vis(self,file,txtname):#生成的模型存放的地址:word_vismodel'+file为新建的文件夹名 txtname是通过word2vec生成 ...
- jQuery学习--Code Organization Concepts
jQuery官方文档: http://learn.jquery.com/code-organization/concepts/ Code Organization Concepts(代码组织概念) ...
- 异常分类VS垃圾分类
异常分类VS垃圾分类 容易快速判断出是什么业务异常,容易对不同的异常进行不同的处理,容易很快找到对应的解决方法
- JMeter-充值-生成随机数
1.随机数,orderId每次需要变化,需要用到随机数 验证生成的随机数:
- tplink路由器DMZ设置
设置完成后,DMZ主机访问不了? 请排查以下方面: 1.确认服务器搭建成功,即内网可以正常访问: 2.确认在DMZ主机中填写的服务器IP地址正确: 3.宽带直接连接服务器并配置上网,确认外网可以正常访 ...
- Python 进程之间共享数据
最近遇到多进程共享数据的问题,到网上查了有几篇博客写的蛮好的,记录下来方便以后查看. 一.Python multiprocessing 跨进程对象共享 在mp库当中,跨进程对象共享有三种方式,第一种 ...
- jquery.autocomplete详解
语法: autocomplete(urlor data, [options] ) 参数: url or data:数组或者url [options]:可选项,选项解释如下: 1) minChars ( ...
- 记账本微信小程序开发六
记账本微信小程序开发六 我的界面 主界面
- 像素与DPI之间的关系
先说像素.像素是电子图像组成的基本单位,将图像放大数倍,会发现图像是由一个个“小色块”紧密排列组成的,每一个“小色块”就是一个像素点. 也就是说,每个图像都是由n多个像素点组成. 再说分辨率.所谓分辨 ...
- java static语句的总结
static 是静态方法,他的引用不需要对象,可以使用类名直接进行引用,当然也不需要this. 由于不需要对象,所以static方法内无法调用非static的方法或对象 至于为什么mai ...